油松林分斷面積生長預估模型研究
2015-03-21 07:30:27高東啟鄧華鋒程志楚
西南林業大學學報 2015年1期
高東啟 鄧華鋒 蔣 益 程志楚
(1.北京林業大學林學院,北京 100083;2.國家林業局調查規劃設計院,北京 100714)
?
油松林分斷面積生長預估模型研究
高東啟1鄧華鋒1蔣 益1程志楚2
(1.北京林業大學林學院,北京 100083;2.國家林業局調查規劃設計院,北京 100714)
在森林經營中,間伐林分、未間伐林分分開單獨建模存在不相容的問題,有必要對其進行研究,并建立統一的模型。利用森林資源一類清查數據,以Schumacher模型為基礎,通過引入啞變量、間伐指標分別建立北京市油松林分斷面積生長預估模型,使得間伐林分和未間伐林分能夠整合在一起建立統一的模型。經檢驗,引入啞變量模型對油松林分斷面積的預測精度最低,為87.99%;其次是引入間伐指標模型,預估精度為88.36%;綜合引入啞變量和間伐指標模型預估精度最高,為88.61%。所建模型對間伐林分和未間伐林分均適用,更方便于在實踐中應用。
林分斷面積;啞變量;間伐指標;油松
油松(Pinustabulaeformis)是北京市主要的綠化樹種,多為人工林,天然林較少,在保護首都生態環境安全方面發揮著重要作用。據第七次全國森林資源清查統計[1],油松占北京市森林面積總量的18.7%,占蓄積總量的11.9%。為了提高林分的質量和效益、科學合理的經營管理森林資源,有必要通過生長模擬來掌握林分的生長狀況。現實林分由于受間伐措施的影響,使得間伐林分的生長規律、空間結構和生態環境相對未間伐林分都可能發生變化[2-4]。從理論上講,同一樹種的間伐林分與未間伐林分需要分開單獨建立模型,而間伐林分與未間伐林分之間是存在一定聯系的,因此如何將這兩種類型的林分整合在一起建立統一的模型是當前急需解決的問題,同時也使得間伐林分與未間伐林分生長模型能夠緊密聯系形成一個有機的整體。關于間伐林分的研究,國外的Bailey等[5]在建立林分斷面積生長預估模型時加入了一個表示間伐的自變量,Murray等[6]考慮用分布函數來表示間伐對林分斷面積生長的影響,Pienaar等[7]提出了由未間伐林分預估間伐林分的新思路;國內的杜紀山、李春明等研究了間伐對杉木(Cunninghamialarceolata)、落葉松(Larixgmelini)人工林生長的影響[8-10]。
本研究以油松人工林為例,從相容的角度出發,以Schumacher模型為基礎,分別引入啞變量[11-12]、間伐指標[7],建立間伐林分和未間伐林分相容的、統一的油松林分斷面積生長預估模型,并對模型的預測能力進行分析比較。
1 研究區概況
北京市位于北緯39°28′~41°05′,東經115°25′~117°30′,地處華北平原北端,北以燕山山地與內蒙古高原接壤,西以太行山與河北省相連,東北與松遼平原相通,南與黃淮海平原連片;屬于暖溫帶半濕潤大陸性季風型氣候,四季分明,夏季炎熱多雨,冬季寒冷干燥,夏季降水量占全年降水量的74%。
2 研究方法
2.1 樣地調查及數據整理
本研究所采用的數據為北京市一類清查數據,每個樣地的面積為 0.066 7 hm2。樣地調查因子有:林木胸徑、林分年齡、林分平均高、林分蓄積、采伐蓄積等。所使用的數據分別調查于1996、2001、2006年,3期數據共計組成99個樣本,其中,間伐林分56個,未間伐林分43個,部分樣地在調查間隔期內進行了間伐,間伐強度不固定,間伐間隔期5 a。間伐林分與未間伐林分樣地的基本情況見表1。主要統計了林分的平均年齡、平均胸徑、平均樹高、單位面積株數、單位面積斷面積和單位面積蓄積量。

表1 間伐林分和未間伐林分主要因子統計
從表1中可以看出,油松間伐林分的平均年齡、平均胸徑、平均樹高、單位面積斷面積和單位面積蓄積量要明顯大于未間伐林分,而單位面積株數又小于未間伐林分,說明間伐效果明顯。
對99個樣本進行隨機抽樣,其中50個樣本用于建模,包含間伐林分31個、未間伐林分19個;49個樣本用于檢驗,包含間伐林分25個、未間伐林分24個,樣地分布情況見表2。

表2 隨機抽樣樣地分布情況
2.2 林分優勢木平均高計算
林分優勢木平均高與林分平均高呈線性關系,由于所用資料中沒有油松林分優勢木平均高的相關記錄,參考賀姍姍[13]的研究結果,其通過解析優勢木的方法,得到油松人工林優勢木平均高與林分平均高的相關關系:
H=1.115h+0.429 3
(1)
式中:H為林分優勢木平均高;h為林分平均樹高;相關系數為0.952 1。
通過(1)式計算出各樣地的林分優勢木平均高,作為評價林分立地質量的指標。
2.3 基于啞變量的方法
通過引入啞變量[11]將油松間伐林分和未間伐林分2個類型的林分用定性代碼來表示,具體過程是將第i個類型的林分編號為Ki,將定性數據Ki轉化為(0,1):
式中:i=1,2;K1、K2分別為間伐林分和未間伐林分的定性代碼。
為了和下面的方法進行對比,選用Schumacher模型建立林分斷面積生長預估模型,其基本形式為[7]:
G=exp(a1+a2/t)Na3+a5/tHa4+a6/t
(2)
為了減小建模時所產生的異方差,可采用對數回歸的方法[14],對Schumacher模型兩邊取對數變為如下形式:
lnG=a1+a2/t+a3ln(N)a4ln(H)+a5ln(N)/t+a6ln(H)/t
(3)
參考李忠國等建立啞變量模型的方法[12],將啞變量引入到模型(3)式的參數中。經過初步嘗試,發現在參數a0~a6中分別引入啞變量時模型的決定系數是不同的。其中,在a4中引入啞變量時模型的決定系數最高,說明表示油松間伐、未間伐林分的啞變量對參數a4的影響最大,既將啞變量引入到模型(3)式的a4中最為合理,則確定啞變量模型的最終形式如下:
lnG=a1+a2/t+a3ln(N)+(a4K1+a5K2) ln(H)+a6ln(N)/t+a7ln(H)/t
(4)
式(2)、(3)、(4)中:G為單位面積林分斷面積;lnG為林分斷面積的對數形式;H為林分優勢木平均高;N為林分單位面積株數;t為林分平均年齡;a1~a7為待定參數;K1、K2分別為間伐林分和未間伐林分的定性代碼。
采用含有啞變量的模型(4)式建立油松間伐林分和未間伐林分相容的林分斷面積生長預估模型,并估計各個參數值。
2.4 引入間伐指標的方法
有學者研究發現[7],間伐林分與未間伐林分斷面積差異的大小取決于間伐時的年齡和間伐強度,并且得到間伐林分和未間伐林分相容的斷面積預估方程:
lnG=a1+a2/t+a3ln(N)+a4ln(N)+a5ln(H)/t+a6ln(H)/t+a7Nftf/(Nat)
(5)
式中:G為單位面積林分斷面積;lnG為斷面積的對數形式;N為林分單位面積株數;H為林分優勢木平均高;t為林分現在的平均年齡;Nf為最近一次間伐中伐去林木株數;tf為林分最近一次間伐時的年齡;Na為最近一次間伐后保留林木株數;a1~a7為待定參數。
模型(5)式相對于對數形式的Schumacher模型(3)式而言,實際上是在(3)式的基礎上引入了一些表示間伐林分特征的相關指標,有表示間伐強度的Nf和Na,還有表示間伐年齡的tf。直接用(5)式去預估林分的斷面積,由于引入了間伐指標,也使得間伐林分與未間伐林分在建模時具有相容性。
2.5 綜合引入啞變量和間伐指標的方法
在上述引入啞變量或間伐指標的2種方法的基礎上,在Schumacher模型(3)式中同時引入啞變量和間伐指標,作為預估間伐林分與未間伐林分斷面積的第3種方法,其形式如下:
lnG=a1+a2/t+a3ln(N)+(a4K1+a5K2)ln(H)+a6ln(N)/t+a7ln(H)/t+a8Nftf/(Nat)
(6)
式中:G為單位面積林分斷面積;lnG為林分斷面積的對數形式;N為林分單位面積株數;H為林分優勢木平均高;t為林分現在的平均年齡;Nf為最近一次間伐中伐去林木株數;tf為林分最近一次間伐時的年齡;Na為最近一次間伐后保留林木株數;a1~a8為待定參數;K1、K2分別為間伐林分和未間伐林分的定性代碼。
2.6 參數估計與模型檢驗
綜合應用ForStat、Excel、SPSS進行數據處理和參數估計,計算均方根誤差(RMSE)、總相對誤差(TRE)、平均系統誤差(MSE)、預估精度(P)等指標來檢驗模型的預測能力,同時對所建模型進行成對t檢驗。
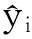
3 結果與分析
統計各模型的參數估計結果見表3。啞變量模型(4)式的擬合效果最差,決定系數R2為 0.845 0;其次是引入間伐指標的模型(5)式,決定系數R2為 0.846 2;綜合引入了啞變量和間伐指標的模型(6)式擬合效果最好,決定系數R2為 0.846 9,平均絕對偏差(MAD)和均方根誤差(RMSE)最小。

表3 模型參數統計
利用檢驗數據對模型(4)、(5)、(6)式進行檢驗,統計結果見表4。在表4中,啞變量模型(4)式的各項誤差最大,預估精度最低,為87.99%;引入間伐指標的模型(5)式居中,預估精度為88.36%;綜合引入啞變量和間伐指標的模型(6)式預估精度最高為88.61%,各項誤差均較小。進行成對t檢驗,結果為Sig.<0.05,說明在0.05顯著水平上模型的回歸效果顯著,實測值與預測值無顯著差異,所建的林分斷面積模型比較合理。
進一步檢驗模型對間伐林分、未間伐林分斷面積的預測能力,統計結果見表5。從表5中可以看出:對于間伐林分而言,模型(4)、(5)、(6)式的預測精度分別為91.86%、91.90%、91.96%,預測效果較好,預測誤差以(4)式最大,(6)式最小;對于未間伐林分而言,模型(4)、(5)、(6)式的預測精度分別為83.17%、84.47%、85.23%,以(6)式誤差最小,這說明綜合引入啞變量和間伐指標的模型(6)式要優于模型(4)、(5)式,而引入間伐指標的模型(5)式對間伐、未間伐林分的預測效果又要好于引入啞變量的模型(4)式。

表4 模型檢驗

表5 模型對間伐、未間伐林分的預測效果檢驗
4 結論與討論
以Schumacher模型為基礎,采用3種方法將間伐林分與未間伐林分整合在一起分別建立北京市油松人工林的斷面積生長預估模型,經檢驗,模型對油松林分斷面積的預估效果都較好,預估精度在87%以上。無論是引入啞變量或間伐指標,還是綜合引入啞變量和間伐指標,都能使得間伐林分和未間伐林分整合在一起建立統一的模型,從而使2種不同類型的林分生長模型形成一個有機聯系的整體,既適用于間伐林分,也適用于未間伐林分,便于在實踐中應用。
3種方法由于引入的因子不同,其預估效果也不相同。引入啞變量的模型對油松林分斷面積的預測精度最低,為87.99%;其次是引入間伐指標的模型,預估精度為88.36%;綜合引入啞變量和間伐指標的模型預估精度最高,為88.61%。可能的原因是引入間伐指標增加了林分狀況的有效信息,使模型的預測效果更好;而引入啞變量并不能增加林分信息因子,只是調整了模型結構建立了間伐林分和未間伐林分相統一的模型;綜合引入啞變量和間伐指標不僅提高了模型對林分信息的利用程度,同時還優化了模型結構,使其預測效果最好。
由于本研究所用數據有限,且時間間隔較短,下一步對于油松間伐林分的研究可進一步收據信息更加豐富、內容更加全面的長期觀測數據,考慮區域效應、樣地效應、時間效應等隨機因素和其他經營管理措施對模擬林分生長的影響。
[1] 賈忠奎,馬履一,徐程揚,等.北京市森林資源動態及可持續經營對策[J].干旱區資源與環境,2006,20(3):30-36.
[2] 李春明,杜紀山,張會儒.撫育間伐對森林生長的影響及其模型研究[J].林業科學研究,2003,16(5):636-641.
[3] 杜紀山,唐守正.撫育間伐對林分生長的效應及其模型研究[J].北京林業大學學報,1996,16(1):80-84.
[4] 岳永杰,余新曉,李鋼鐵,等.北京松山自然保護區蒙古櫟林的空間結構特征[J].應用生態學報,2009,20(8):1811-1816.
[5] Bailey R L, Ware K D. Compatible basal area growth and yield model for thinned and unthinned stands[J]. Canadian Journal Forest Research, 1983(13): 563-571.
[6] Murray D M, Von G K. Relationships between the diameter distributions before and after thinning[J]. Forest Science, 1991, 37(2): 552-559.
[7] Pienaar L V, Shiver B D. Basal area prediction and projection equations for pine plantations[J]. Forest Science, 1986, 32(3): 626-633.
[8] 杜紀山,唐守正.杉木林分斷面積生長預估模型及其應用[J].北京林業大學學報,1998,20(4):4-8.
[9] 李春明,杜紀山,張會儒.間伐林分的斷面積生長模型研究[J].林業資源管理,2004(3):52-55.
[10] 李春明,杜紀山,張會儒.撫育間伐對人工落葉松斷面積和蓄積生長的影響[J].林業資源管理,2007(3):90-93.
[11] 唐守正,郎奎建,李海奎.統計與生物數學模型計算(ForStat教程) [M].北京:科學出版社,2009.
[12] 李忠國,孫曉梅,陳東升,等.基于啞變量的日本落葉松生長模型研究[J].西北農林科技大學學報:自然科學版,2011,39(8):69-74.
[13] 賀姍姍.北京山區油松人工林林分結構與生長模擬研究[D].北京:北京林業大學,2009.
[14] 曾偉生,唐守正.非線性模型對數回歸的偏差校正及與加權回歸的對比分析[J].林業科學研究,2011,24(2):137-143.
(責任編輯 趙粉俠)
Forecast Models Research of Stands Basal Area Growth forPinustabulaeformis
GAO Dong-qi1,DENG Hua-feng1,JIANG Yi1,CHENG Zhi-chu2
(1.College of Forestry, Beijing Forestry University, Beijing 100083, China; 2.Academy of Forest Inventory and Planning, State Forestry Administration, Beijing 100714, China)
It was incompatible to model thinned stands and unthinned stands separately, so it was necessary to study and establish the unified models. Using forest inventory data, based on Schumacher model, through introducing the dummy variables and thinning indexes to establish the stands basal area growth forecast models ofPinustabulaeformisin Beijing respectively, and made the thinned stands and unthinned stands together to establish unified models.After inspection,on the forecast effect for stands basal area ofPinustabulaeformis, forecast accuracy of model with dummy variables was 87.99% as a minimum; followed by the model with thinning indexes, forecast accuracy was 88.36%;forecast effect of model with dummy variables and thinning indexes was the best, forecast accuracy was as high as 88.61%.The models was applicable for thinned stands and unthinned stands, it was more convenient for application in practice.
stands basal area;dummy variables;thinning indexes;Pinustabulaeformis
2014-04-29
林業公益性行業科研專項(201204510)資助。
鄧華鋒(1966—),男,博士,教授。研究方向:森林可持續經營。Email:denghuafeng@bjfu.edu.cn。
10.11929/j.issn.2095-1914.2015.01.009
S758.5
A
2095-1914(2015)01-0042-05
第1作者:高東啟(1986—),男,碩士生。研究方向:森林可持續經營。Email:511602746@qq.com。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小讀者(2021年2期)2021-03-29 05:03:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新悅讀(2019年11期)2019-12-18 05:14:16
華人時刊(2019年13期)2019-11-17 14:59:54
NBA特刊(2018年21期)2018-11-24 02:48:04
文苑(2018年22期)2018-11-19 02:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
紅領巾·萌芽(2016年1期)2016-09-10 07:22:44
