面向中醫藥文獻的語義關系發現方法研究
2015-03-30 11:31:10于彤賈李蓉張竹綠朱玲
中國中醫藥圖書情報 2014年6期
于彤 賈李蓉 張竹綠 朱玲

摘要:從中醫藥文獻中提取語義關系的方法,能充實中醫藥知識庫系統,提升知識獲取效率,改進知識檢索效果。本研究通過搜集中醫藥文獻并從中找出在一起頻繁出現的詞對,基于中醫藥學語言系統判斷語義關系的性質,再將所發現的語義關系交由領域專家進行檢驗。該方法向中醫藥領域專家提供了從文本中發現語義關系的新穎技術手段。
關鍵詞:語義關系;中醫藥學語言系統;知識庫
目前,中醫藥領域實用的知識庫系統顯現出大型化的趨勢,往往包含百萬條語義關系。例如,中醫藥學語言系統(Traditional Chinese MedicineLanguage System,TCMLS)已收錄概念12萬余條,術語30萬余條,語義關系127萬多條。由人工編輯如此大量的語義關系,是一個耗時費力的大工程。若能實現從文獻中自動抽取語義關系,則可大幅提升知識獲取效率。因此,語義關系發現方法對領域知識庫的構建具有很大意義。本文介紹了一項基于TCMLS從文本中發現語義關系的初步嘗試。該研究試圖將文本中蘊含的語義關系挖掘出來,與TCMLS現有的語義關系結合,得到更為全面、準確的語義關系,并明確系統中語義關系的文獻來源,從而擴充TCMLS的數據規模,提升TCMLS中語義關系的準確性和可靠性。
1、研究背景和相關工作
中醫藥學是經過幾千年的發展而形成的,文獻記載是其重要的知識流傳的方式之一。近年來,中醫團體開展了大量的知識工程工作,采用各種文獻中的知識來構建中醫藥領域知識庫,提供知識檢索服務。以TCMLS為例,因缺乏實用的中醫藥文本挖掘方法,在語義關系抽取方面,主要依賴于加工人員的個人知識和手工操作。這種方法與加工人員個人的知識、素養和責任心有很大關系,造成數據準確性良莠不齊,難以對數據質量進行有效管理。隨著系統規模的不斷擴大,人工編輯的復雜性也不斷增大,制約著TCMLS的進一步發展。鑒于此,擬對中醫藥文獻內容進行語義關系提取,得到具體概念之間的語義關系,與TCMLS的語義關系進行比較,并對TCMLS進行進一步擴充。
從自由文本中挖掘語義關系是一個非常困難的問題,因為同一種關系在文本中會有多種表達方式。常見的語義關系發現方法,主要包括如下2大類。
1.1 基于語法分析的語義關系發現
此類方法的主要思路是:基于自然語言處理(NLP)技術,通過對文本進行語法分析,構建出語法樹,再通過語法和詞性的分析得到其中的語義關系。這類方法的優點是對語義關系定位比較準確,并可以通過語法特征得到文本中的隱含信息。但其缺點在于:此類方法的效果嚴重依賴于語法分析的結果,對于一些特殊的領域,現有的語法分析方法往往無法取得令人滿意的結果。因此,基于語法分析的語義關系抽取算法其應用范圍受到了很大的限制,特別是在一些有著獨特語法規則的領域中更是如此,本文中提到的中醫藥領域就是一個例子。
1.2 基于模式匹配的語義關系發現
這種方法是用某種模式對文本進行匹配,根據匹配的情況得到相應的語義關系。根據匹配模式的不同來源,可以分為兩類:基于領域知識的模式匹配和基于學習的模式匹配。基于領域知識的模式是由領域專家將其領域知識總結、升華得到的通用知識模式,然后再使用這些模式作為模板,從文獻中找到相應的關系。基于學習的模式匹配方法,是指使用機器學習方法,通過對文獻特征的分析得到有用的模式。這類方法的目標一般限定為僅挖掘某些特定類別的實體的幾種特定關系,無法勝任中醫藥領域中語義關系種類很多的情況。
綜上所述,這兩類方法都不適合中醫藥領域的需求。本研究提出基于TCMLS的文本語義關系發現方法,該方法以TCMLS中的詞匯為基礎,發現語義關系中的主體和客體;以TCMLS中已有的語義關系為根據,推測從文本中挖出的語義關系的類型。本研究的基本策略,是基于TCMLS從文本中發現更多的關系,經用戶驗證后加入TCMLS之中,從而豐富TCMLS的語義關系;再用豐富后的TCMLS進行新一輪的文本挖掘,進一步豐富TCMLS;以此類推,從而形成一套基于文本語義關系發現來驅動TCMLS加工的技術方案。下面具體介紹基于TCMLS的語義關系發現方法。
2、文本語義關系發現方法
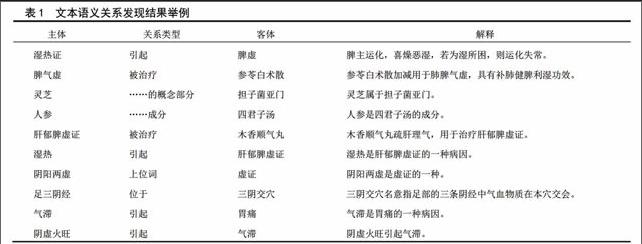
如圖1所示,文本語義關系發現,是指從“……人參有‘補五臟、安精神、定魂魄、止驚悸、除邪氣、明目開心益智的功效……”的文本中,發現“人參補五臟”、“人參安精神”、“人參止驚悸”、“人參除邪氣”這樣的關系。該方法會統計每條關系出現的頻數:如果在文檔D1,D2……Dn中都出現了某條關系R,則R出現的頻數即為n。該方法的基本策略是:以TCMLS作為領域詞庫,從文獻庫中找出在同一文檔中出現的兩個領域術語(如“人參、邪氣”、“人參、五臟”等),構成候選的文本語義關系,并統計每條關系的頻數,以供語言學家進行檢閱和處理。由機器判斷語義關系的謂詞(如“人參”與“邪氣”之間的謂詞為“除”)仍是一個技術難題。本方法會在這兩個詞附近找出一些候選性謂詞(如“補”、“除”等)推薦給用戶;并提供TCMLS中的相關用法,供用戶參考(例如,針對“人參”和“腎陽虛證”,系統會根據TCMLS中的用法向用戶推薦“治療”這一謂詞)。
為實現該策略,首先需要將中醫藥文本分解成一系列獨立的語義單元。中醫藥文獻資源包括書籍、期刊、會議論文集、病歷、報告等,語義單元劃分要針對不同類型的文獻進行具體分析。本研究主要考慮書籍、期刊和會議論文集。這些文獻都可被分為一系列“文章”(在書籍中對應一章或一節,在期刊和會議論文集中對應一篇論文),可對文章進一步細分,將文章分為小節,將小節分為段落,將段落分為句子。
理論上,在一篇文章中出現的任意兩個詞匯之間都可能存在或強或弱、或直接或間接的語義關系。因此也可將“文章”作為語義單元進行語義關系發現。但在語義關系識別階段,關鍵詞組過長會極大增加算法復雜性。為保證算法效率,關鍵詞組內詞匯數量不宜過多,因此本研究未將整篇文章作為語義單元進行挖掘。與全文相比,“句子”是一個相對較小、且有完整語義的單元。“句子”通常描述一個完整的意思,且其中的詞匯之間通常有某種聯系,因此“句子”為中文分詞及后續處理提供了天然的單元。但語義關系的主體和客體也有可能分散在不同的句子中,僅以句子作為語義單元會遺失掉很多的關系。鑒于此,本項目分別以句子和小節作為基本的語義單元,進行語義關系發現,下面介紹其核心思想和設計原則。
第一,在文中距離越近的“名詞、動詞、名詞”,越有可能表達一條語義關系。因此,本方法會記錄語義關系中的詞匯在文中的最短距離,作為反映語義關系真實性的一個參數。
第二,在各種文獻中多次出現的“主語謂語賓語”,更有可能代表一條語義關系。若一條關系頻繁出現于各種文獻中,則其很可能是領域專家認可的。因此,本方法對從各種文獻中發現的關系進行匯總,統計每條關系在文中共現的頻數,將其作為一個參數提供給術語學家。
第三,文獻量越大、越全面,所得到的語義網絡就越具有統計價值。鑒于此,采用TCMLS對萬方文獻庫進行檢索,以期獲得盡可能全面的文獻。
第四,構建在中醫藥領域中常用的動詞列表,以該表為基礎推測語義關系中的謂詞。將主語或賓語附近出現的動詞記錄下來,作為語義關系的候選謂詞,推薦給術語學家。
第五,鑒于文本語義關系發現方法尚不能保證結果的準確性,開發了一個文本語義關系的檢閱系統,對文本語義關系進行檢查、分析和標注等工作,使術語學家了解語義關系與相關文本的關聯。
3、文本語義關系發現和檢閱系統
在本研究中,采用Java語言開發了一套文本語義關系發現程序,以實現文本語義關系發現方法。以TCMLS作為關鍵詞,從萬方數據知識服務平臺檢出了217 667條文獻題錄信息(含摘要),再用文本語義關系發現程序從摘要中挖出了87826條關系,其中部分的關系如表1所示。所得出的關系被存入一個關系型數據庫(MySQL數據庫)中,通過文本語義關系檢閱系統展示出來,供語言學家進行檢閱。
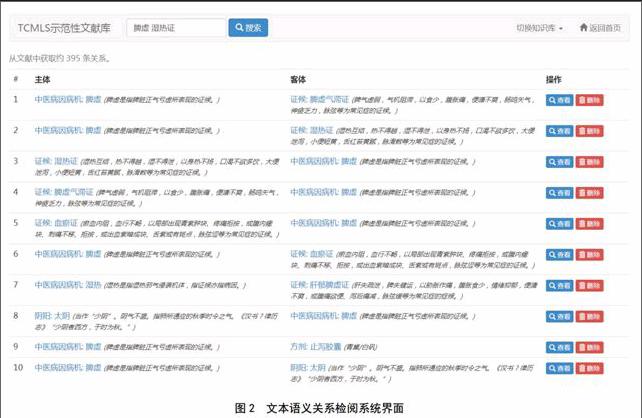
如圖2所示,開發了一套文本語義關系的檢閱系統,支持用戶對文本語義關系進行檢閱、分析和標注,查看文本語義關系的文獻依據和相關網頁,并將文本語義關系正式插入某個術語系統(如TCMLS)。在語義關系檢索界面中,系統會將機器發現的語義關系分頁列出。用戶可輸入關鍵詞(如“陽痿腎陽虛證”)搜索個人關心的語義關系。系統列出了每條關系的主體和客體(如“益腎丸腎陽虛證”),給出每個概念的類型、正名和定義。用戶可點擊查看某個概念,系統會轉到這一概念的信息頁面。當用戶在上文提到的“語義關系檢索界面”中點擊查看某條關系,系統就會跳轉到這條語義關系的展示和處理界面。
在語義關系的展示和處理界面中,用戶可以查看這條關系的主體信息、候選謂詞、客體信息、參考性參數。其中,對于主體和客體,都給出了概念的類型、正名、定義以及概念信息頁面的鏈接。候選謂詞是基于TCMLS中的用法來生成的,例如,若主體為“人參”,客體為“腎陽虛證”,則系統會推薦“治療”作為候選謂詞。用戶可以點擊“文獻資源”,查看該語義關系所出自的文獻。對于每篇文獻,系統都給出了題名和摘要。用戶單擊選擇某篇文獻的題名時,系統會跳轉到該文獻的題錄信息頁面。用戶可以點擊“百度搜索”,查看該語義關系相關的百度搜索結果,也可以點擊“相關陳述”,查看該語義關系在TCMLS中的相關陳述,以供語言學家參考。用戶還可通過系統提供的表單,將這條語義關系加入語言系統中。系統會根據TCMLS中的相關用法,列出一些相關屬性以供用戶選擇。用戶也可以輸入新的屬性,例如,為添加“人參除邪氣”這條關系,用戶可輸入“除”這一新屬性。用戶也可以添加一些注釋信息。另外,當關系被錄入TCMLS后,系統會記錄這條關系的文獻來源。
4、小結
數字化文獻是中醫藥知識密集型數據的基礎。中醫藥語義網若與文獻資源相脫節,則必成為無源之水、無本之木。從文獻中提取語義關系的方法,能有效豐富中醫藥語義網的內容,建立中醫藥語義網和文獻資源的有機聯系,改進中醫藥文獻檢索的效果。本研究開展了中醫藥文獻語義關系發現方法的初步探索:基于TCMLS,搜集中醫藥文獻,對文獻進行分詞處理,從中找出在一起頻繁出現的詞對,判斷語義關系的性質,交由領域專家進行檢驗。本研究所開發的文本語義關系發現和檢閱系統,向術語專家提供從文本中發現新穎語義關系的技術能力。
這項工作尚存在一些局限性。例如,我們尚缺乏判斷文本語義關系準確類型的有效手段,也尚未實現發現新詞的方法。另外,有些中醫藥領域的詞匯尚未收入TCMLS之中,這影響了語義關系發現的效果。在進一步研究中,擬對從文本中獲得的語義關系與TCMLS現有的語義關系進行比較,補充完善TCMLS現有的語義關系網絡。擬對從文本中獲得的語義關系按概念的語義類型進行歸納,得到語義類型間的語義關系,融合成一個基于文獻的頂層語義網絡。對TCMLS的頂層語義網絡和從文獻中實際抽取的語義網絡進行比較,對TCMLS現有的項層語義網絡進行補充和修正,從而指導中醫藥學語言系統實際發展和應用。
