大數據平臺基準測試標準化思考*
2015-04-15 08:46:08陳凱中國信息通信研究院通信標準研究所高級工程師
信息通信技術與政策 2015年2期
關鍵詞:標準化
陳凱 中國信息通信研究院通信標準研究所高級工程師
魏凱中國信息通信研究院通信標準研究所高級工程師
周曉敏 中國聯合網絡通信有限公司技術部項目經理
大數據平臺基準測試標準化思考*
陳凱 中國信息通信研究院通信標準研究所高級工程師
魏凱中國信息通信研究院通信標準研究所高級工程師
周曉敏 中國聯合網絡通信有限公司技術部項目經理
大數據基準測試是大數據技術和產品發展中不可或缺的標尺。目前,雖然已經有了很多的測試工具,如何將它們標準化成為業界關注的焦點。本文介紹了大數據基準測試標準化的緊迫性,分析了大數據基準測試標準化現狀和測試工具,指出了大數據基準測試標準化所面臨的挑戰;最后,對大數據基準測試標準化最新進展,以及大數據基準測試標準化下一步的發展方向進行了展望。
大數據 基準測試 Hadoop 標準化
1 引言
大數據是指難以用現有的軟件工具提取、存儲、搜索、共享、分析和處理的海量的、復雜的數據集合。今天越來越多的企業認識到,大數據的分析能力將成為競爭力的核心,企業對大數據的投資也在不斷擴大。Gartner調查顯示,73%的企業計劃在未來兩年內投資大數據。以開源Hadoop、Spark等為基礎的大數據基礎平臺解決方案和云服務如雨后春筍不斷涌現,形成了近200億美元的市場規模。
然而對于很多企業用戶來說,如何評價一個大數據平臺的綜合能力,常常是系統設計、產品和服務選型、平臺建設、系統優化和運維時面臨的一大挑戰。回顧數據庫和服務器產品的發展歷史,一套公平、可重復、便于理解的測試基準,是推動產品和服務快速成熟的重要支撐。今天,大數據平臺正處在發展初期,各種新架構、新產品和新服務不斷涌現,研發、采購、驗收等環節迫切需要統一的衡量標準來牽引。目前來看,國內外還缺乏一套能體現大數據特點,又簡便易行,且被工業界廣泛認可的大數據平臺基準測試標準。
2 大數據基準測試標準化現狀
大數據分析系統具有高性能、高擴展、高可用、高效能、易使用、易管理等特點,其架構設計的復雜性使得系統測試也非常復雜,針對其測試的研究同其設計開發的研究相比則相對薄弱。直到2014年6月,TPC(事務處理性能協會)才發布了基準測試標準TPCx-HS和配套的測試工具。TPC專門為虛擬服務器以及事務處理等機制提供客觀且不受供應商影響的基準測試解決方案。
TPC一直認為在制定行業的標準時,性能、持有成本和能源效率是成功的三大關鍵,因此TPCx-HS的測試重點仍然是性能驗證、性價比、功耗以及可用性。TPCx-HS能夠對硬件及軟件方案加以檢測,其中包括Hadoop運行時、Hadoop文件系統、API兼容系統以及MapReudce層等。TPCx-HS這一名稱中的“x”代表Express,即精簡之意。目前,只有Sort一種測試負載,TPCx-HS委員會認為精簡版本的基準測試能夠滿足企業級基準測試需求,而且不會耗費更多時間及成本資源。TPC協會的成員思科公司已經在其大數據系統上運行TPCx-HS基準測試并公布了最終成績。
而另一個國際標準測試的權威機構SPEC(標準性能評測機構)雖然成立了大數據基準測試研究組,但目前還沒有發布大數據基準測試的標準。
3 大數據基準測試工具
基準測試工具在大數據系統研發中不可或缺。伴隨著各種平臺軟件的出現,特別是開源大數據平臺的發展,多種針對不同框架的基準測試工具也陸續出現。其中,除了ApacheHadoop自帶的基準測試工具外,很多企業和研究機構也發布了自己的大數據基準測試工具。
3.1 Apache Hadoop基準測試工具
Hadoop自帶了若干基準評測程序,安裝開銷小、運行方便。常用的有DFSCIOTest用于測試HDFS的I/O性能;Sort程序評測MapReduce;MRbench檢驗小型作業的快速響應能力;NNBench測試Namenode硬件的加載過程;Gridm ix可以通過模擬Hadoop Cluster中的實際負載來評測Hadoop性能。
Hadoop自帶的基準評測程序相對簡單。例如,Gridm ix所使用的用例并不能代表所有的Hadoop使用場景,缺乏CPU-Bound的用例。而現實應用中,不僅存在很多I/O密集型的應用,也存在很多CPU密集型的應用,如聚類算法、倒排索引等;也不能模擬隨機提交作業(如按泊松分布進行提交)的應用場景。因此,并不完全符合測試的預期。
3.2 TPCx-HSKit
TPC發布基準測試標準TPCx-HS的同時,也發布了配套的測試工具TPCx-HSKit。
TPCx-HS負載包含以下4個模塊:
(1)HSGen:數據生成器,基于TeraGen。
(2)HSDateCheck:檢查數據集和副本的符合性。(3)HSSort:數據排序,基于TeraSort。
(4)HSValidate:排序后的數據校驗,基于Tera Validate。
比例因子(Scale factor,SF)可以從1TB擴展到10000TB。3個主要指標(Metrics):HSph@SF代表每小時的吞吐量、$/HSph@S代表性價比、System Availability Data代表可用性,以及一個代表功率的可選指標Watts/HSph@SF。
3.3 Hibench
Intel在Hadoop基準測試工具基礎上做了許多重要的擴展,提供了一套開源Benchmark Suite-HiBench,來對其Hadoop集群做Benchmark,并通過HiTune進行性能數據采集。HiTune是Hadoop性能分析工具,可以從每個節點上分布收集性能數據,并且可以將這些數據進行匯總,生產圖形化的報告,讓客戶可以迅速明白哪個節點出了問題,進而迅速調整。HiBench選取的計算模型較為全面和綜合,既包含M icro Benchmarks和HDFSBenchmarks,又包含Web Search(網頁搜索)、MachineLearning(機器學習)和DataAnalytics(數據分析)等應用。
3.4 YCSB
YCSB(Yahoo Cloud Serving Benchmark)是雅虎開源的一款通用的性能測試工具,可以對各類NoSQL產品進行相關的性能測試,包括Bigtable、HBase、Azure、CouchDB、MongoDB等。YCSB與HBase自帶的性能測試工具(Performance Evaluation)相比,可以兼容HBase不同的版本,可以選擇進行測試的方式有:Read+W rite和Read+Scan,還可以選擇不同操作的頻度與選取Key的方式,也可以實時顯示測試的進度。
3.5 BigBench
BigBench是第一個基于端到端的大數據分析測試工具,它提供了非常豐富的查詢集合,涵蓋了各種復雜且真實的場景,主要用于測試并行數據庫在SQL-MR環境下的查詢能力。BigBench包含兩個關鍵的組件,即數據模型規范和負載/查詢規范。其中,結構化數據部分主要采用TPC-DS的數據模型。BigBench包含30個查詢/負載,能夠在Hadoop平臺上執行。
3.6 BigDateBench
BigDataBench是由中科院計算所開發的開源軟件,覆蓋了微基準測試(M icro Benchmarks)、Cloud OLTP、關系查詢、搜索引擎、社交網絡和電子商務6種典型的應用場景,包含19種不同類型的負載應用程序和6種不同類型的數據集。
BigDataBench還提供可以保留原始數據特性的,以小規模真實數據生成大規模數據的數據生成工具。包括文本數據、圖數據和(數據庫)表數據在內的數據集都可以通過該生成工具生成。同時,涵蓋了完整的系統軟件棧,覆蓋的應用類型包括實時分析、離線分析和在線服務應用。
4 大數據基準測試標準化面臨的挑戰
大數據基準測試工具為基準測試的實施提供了基礎。然而,要做到可重復、可比較,還需要制定相應的標準,對測試中的預置條件、測試負載參數、測試數據和測試步驟進行詳盡的約束。
4.1 數據生成
數據生成是大數據基準測試首先要解決的問題。由于企業通常不會公開自己的數據,因此真實數據很難獲得。即使可以獲得,其數據也往往是基于特定的應用場景,不具有普適性。而隨機生成的數據,更難以體現應用的特征。因此,目前常用的生成工具會采用二者結合的方式,即通過建模先從真實的數據樣本中提取應用特征,在保持應用特征的前提下再隨機生成測試樣本。合成數據看似很好地解決了問題,但關鍵在于提取和擴展的過程中如何保持應用特征以及生成的速度是否足夠快。
4.2 負載的選擇
負載是大數據需要執行的具體任務,用來處理數據并產生結果,負載將大數據平臺的應用抽象成一些基本操作。由于行業和領域的不同,其應用有很多不同的特點,從系統資源消耗方面負載可分為計算密集型、I/O密集型和混合密集型。例如,運營商的話單查詢需要多次調用數據庫,是典型的I/O密集型任務;而互聯網的聚類過程需要大量的迭代計算,是典型的計算密集型任務;搜索引擎中的PageRank算法既需要數據交換又要不斷地迭代計算,屬于混合型任務。面對各種復雜的應用場景,很難選擇出合適的測試負載。
4.3 集群規模
隨著大數據的迅速發展,集群規模也越來越龐大。例如,TDW(TencentDistributedDataWarehouse,騰訊分布式數據倉庫)單集群規模達到4400臺,CPU總核數達到10萬左右,存儲容量達到100PB;每日作業數100多萬,每日計算量4PB,作業并發數2000左右,TDW已經成為騰訊最大的離線數據處理平臺。
第三方實驗室的集群規模通常是幾百臺,甚至幾十臺,遠遠小于運營商運營的規模,測試的結果可能會與實際情況有很大的差距。為了降低測試的復雜性和成本,通常只能在現網上運行簡單的測試用例,而目前能夠提供大數據在線服務還比較少,主要有微軟HDInsight、UcloudUDDP、百度BMR和阿里ODPS等。
4.4 軟件的兼容性
Hadoop的發行版除了社區的ApacheHadoop外,Cloudera、Hortonworks、MapR、EMC、IBM、Intel和華為等都提供了自己的商業版本。商業版主要是提供了專業的技術支持,這對一些大型企業尤其重要。社區版ApacheHadoop包含兩個版本:Hadoop 1.0和Hadoop 2.0。其中,Hadoop 1.0由一個分布式文件系統HDFS和一個離線計算框架MapReduce組成;而Hadoop2.0則包含一個支持NameNode橫向擴展的HDFS,一個資源管理系統YARN和一個運行在YARN上的離線計算框架MapReduce。隨著大數據軟件逐步被推向市場,被更多的用戶安裝,兼容性問題也會日益凸現。
5 大數據基準測試標準化最新進展
2015年1月29日,數據中心聯盟(www.dca.org.cn)發布了國內第一個大數據產品和服務基準測試規范《大數據平臺基準測試技術要求第一部分技術要求》和《大數據平臺基準測試技術要求第二部分測試方法》。與該規范配套的評測工具源代碼也同期發布,并移交開源社區持續開發。該規范是由中國信息通信研究院(原工業和信息化部電信研究院)牽頭,聯合中科院計算所、華為、中國移動、Intel、微軟、IBM、新浪、百度、阿里、騰訊、浪潮、世紀互聯、UCould等國內外知名公司和科研機構共同制定,囊括了國內外主流大數據產品與服務提供商。
如圖1所示,《大數據平臺基準測試技術要求第一部分技術要求》的評價對象主要包括大數據軟件平臺(如基于開源Hadoop、Spark平臺的商業軟件)、大數據軟硬一體機和云端大數據服務三大類。
(1)大數據軟件平臺
主要由分布式文件系統(如HDFS)、分布式計算系統(如MapReduce)、分布式數據庫(如HBase)、分布式數據倉庫(如Hive)等多個模塊構成,能夠提供大數據的存儲、管理和計算能力。大數據軟件平臺主要包括開源的Hadoop、Spark等及其商業化軟件版本,一般部署在通用硬件平臺上。
(2)大數據軟硬一體機
大數據軟硬一體機集成了服務器、存儲、網絡和大數據軟件平臺,以整機的形式銷售給客戶。對于大數據一體機方案,測試衡量的是軟件和硬件整體的性能。
(3)大數據云服務
大數據云服務由云服務商將大數據軟件平臺部署到云端,以公共云服務的形式向用戶提供大數據存儲、管理和計算能力,按量收費,用戶無需關心集群軟硬件的搭建和運維。
規范根據大數據特點,精選了NoSQL、離線分析和實時交互分析等最具代表性的21個基本負載,能夠考核平臺在計算密集、I/O密集和混合任務等不同場景的表現。標準規定了數據生成、負載選擇、測試指標、用例執行和測試配置。標準還從用戶角度出發定義了多個維度的指標,不僅有基本的吞吐量質保,還有能耗、壓力、擴展性、容錯能力等多方面的指標。
《大數據平臺基準測試技術要求第二部分測試方法》規定了典型測試負載的測試流程,并給出了測試數據規模的要求(見表1)。
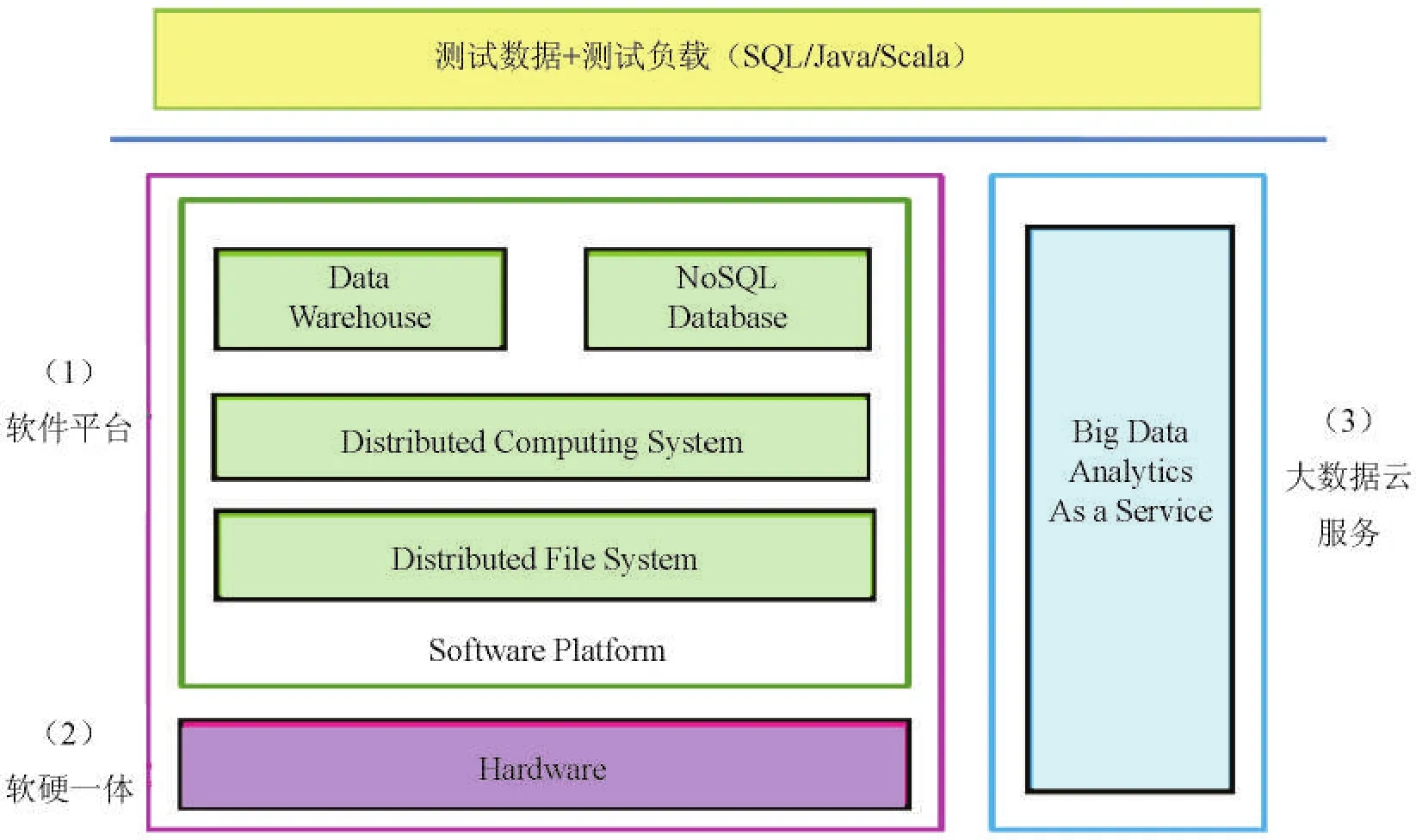
圖1 大數據基準測試標準中定義的測試對象
6 結束語
目前,大數據基準測試標準化工作仍處于起步階段,國內相關工作取得了初步進展,對大數據平臺的基本操作測試進行了規范。但應該看到,這僅僅是大數據基準測試標準化工作的開始,未來還有較長的路要走。下一步大數據基準測試標準的發展重點,一是針對企業對SQLonHadoop數據倉庫方案的需求,細化交互分析基準測試負載的制定;二是面向政務、金融、電信等重點行業,研究制定端到端的負載,推動行業大數據技術與產品的演進。
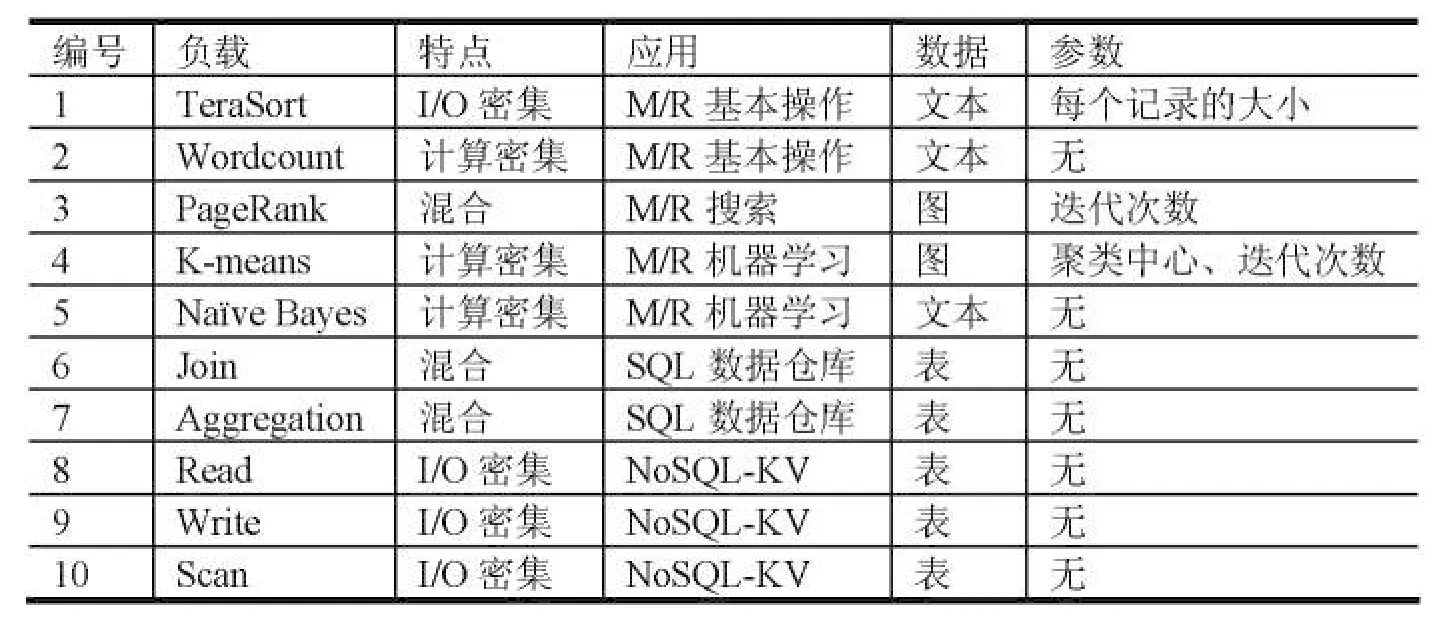
表1 10種典型測試負載、特點、應用、數據類型和負載參數
2015-01-20)
云計算標準與測試驗證北京市重點實驗室項目資助
猜你喜歡
電器工業(2023年1期)2023-02-13 06:31:42
口腔護理用品工業(2021年4期)2021-11-02 08:22:56
機械工業標準化與質量(2018年5期)2018-05-30 09:48:17
中國公路(2017年9期)2017-07-25 13:26:38
水利技術監督(2017年2期)2017-05-17 05:19:25
福建輕紡(2017年12期)2017-04-10 12:56:27
知識經濟·中國直銷(2016年4期)2016-11-07 09:34:05
質量與標準化(2015年7期)2015-07-12 12:21:02
汽車維修與保養(2015年8期)2015-04-17 03:32:51
石家莊理工職業學院學術研究(2014年4期)2014-04-27 14:14:40
