關于維吾爾語口語語料的三音子選取方法研究
2015-04-21 09:26:46徐寶龍努爾麥麥提尤魯瓦斯吾守爾斯拉木
中文信息學報 2015年2期
徐寶龍,努爾麥麥提·尤魯瓦斯,吾守爾·斯拉木
(新疆大學 信息科學與工程學院,新疆 烏魯木齊 830046)
?
關于維吾爾語口語語料的三音子選取方法研究
徐寶龍,努爾麥麥提·尤魯瓦斯,吾守爾·斯拉木
(新疆大學 信息科學與工程學院,新疆 烏魯木齊 830046)
在大詞匯量連續語音識別應用中,優質的語音訓練語料是所有識別工作的基礎和前提, 能否挑選出覆蓋更多語音現象的語料是提高語音識別性能的關鍵。該文在多種維吾爾文口語化傳播平臺中采集了大量口語句子語料,并考慮協同發音的影響和常用詞的適用性,根據評估函數對語料篩選。經過篩選后的語料包含的三音子更加均衡和高效,囊括的語音現象更加全面,為訓練準確而牢靠的語音模型打下了穩固的根基。
維吾爾語;語音識別;語料庫;三音子
1 引言
從1962年開始,語音識別技術的發展過程由處理孤立詞識別、連接數字識別和連接詞識別到處理連續語音識別和語音交互,詞匯的數量級也由少詞匯量擴展到超大詞匯量,語言的形式也由書面語識別發展到自然對話識別[1]。漢語和英語的語音語料庫正日趨完善,相應的應用也為人們的日常生活與科研活動提供了方便快捷的幫助,然而維吾爾語語料庫資源的質量還沒達到要求,仍不能滿足人們的實際應用需求。這就迫切地需要建設更高質量、更加穩定的維吾爾語語音識別語料庫。此外, 本文的
研究還將推動如哈薩克語、烏茲別克語、柯爾克孜語以及阿拉伯語等相似言語體系的語音研究工作[2]。
由于維吾爾語屬于阿勒泰語系突厥語族,是黏著性語言,在元音和諧、輔音結合等方面有自己特有的規律,語音的多樣性與復雜性較為明顯[2]。同時,選取出更具有代表性的語料,對訓練健壯性強的聲學模型有著不容忽視的作用,因此語音的分析和合成工作也就越來越依賴語音語料的選取質量。為此,本文結合維吾爾語自身特點,參考綁定三音子模型理論,對語料覆蓋三音子的程度進行排序篩選,并考慮常用詞表在句子中權重的影響,挑選出覆蓋較多語音現象的句子,從而緩解數據稀疏問題。
2 維吾爾語連續語音的三音子結構
所謂音子(phone),是語音之間在聲學上連貫的、粘著的音段部分,它對應于聲學上的音段。它跟音位或音素不同,音位是區別性的語音,對應于聽覺上的音段[3-4]。可是在聲學上除了音段以外,在它們之間還存在著由于協同發音(協同發音是指在周圍聲音的影響下,一個語音聲音會發生變化)而產生的過渡音段的音聯,這些在聲學上就叫作音子[4]。雖然音子可以作為描述維吾爾語普通話的最小單位,但在連續語音中,一連串音節緊密連接,發音部位和發音方法不斷改變,音節之間互相影響,偏離原來的位置,導致其聲學表現和孤立音節有很大區別[5]。因此,在維吾爾語連續語音識別系統中,只是用音子還不足以完全表征出維吾爾語語音流的全部語義。我們可以使用三音子(tri-phone)來描述連續語音的音變和過度[4,6]。
三音子(trip-phone)考慮了一個音子和其左右語言環境對其造成的影響,它包括音子本身(中心音子)以及和它左右相鄰的音子之間的過渡段[5]。由于三音子是考慮上下文相關的協同發音影響,所代表的語音現象更加全面,所以使用三音子作為語音的識別單元更合理。
在維吾爾語中,元音音強普遍強于輔音。音長低于輔音中的送氣音及擦音,與半元音、邊音、鼻音音長相近,其中[ü]的音長最短。非爆破輔音中,擦音音強較弱。發音時長與發音人性別,發音習慣,及上下文(音素過渡)有一定關系,故音長離散度較大。由統計結果可知,元音的音強比之輔音的要強,且與半元音、邊音、鼻音相近。維語語音分為音位、音節、重音等結構單位,其中元音8個,輔音24個,其中共有41個音素(其中16個為元音長發音和短發音,24個為輔音,1個為靜音)、5 000多個音節(包括外來詞),這些音節的使用頻率是不平衡的[7-8]。
此外,在建立語言模型時很難獲得充分的大詞匯量。這就更加迫使我們必須挑選出一種簡潔高效的、覆蓋廣的語料。為此本文根據這一實際需求出發,選用三音子作為識別基元,并考慮三音子覆蓋率對其進行優化,目前已經可以較好地實現這個需求。
3 維語語料的預處理選取
我們的目的是從大規模口語語料中挑選一定數量的句子作為語音訓練語料,本文中采用了無需人工干預的全自動挑選方法[9]。而且,使用者可以按照自己的需求挑選任意多的語料,提高了所選語料的穩定性。
3.1 采集口語語料
維吾爾語的文本數據之所以收集比較困難,是因為有的維吾爾語媒體沒有保存網站的歷史數據,有的媒體保存的文本數據不支持Unicode編碼,自動存儲與自動識別不能方便地轉換[10]。本文程序考慮了維吾爾語的語言特性與編碼格式等問題,可自動識別維吾爾語的編碼格式,并進行轉換。
本文針對瀏覽量大、客戶群體多的交互性網站進行數據采集,這些網站包括微博、博客、論壇等。因為這些平臺上的語料更加真實,更加貼近生活,是對語音識別的實用性更加突出。由于上述的維吾爾語交互網站并不完善,網站內部架構里存在許多鏈接地址不同但內容完全相同的帖子。并且由于維吾爾語書寫格式與漢語不同,是從右至左書寫,語言又屬黏著性語言,有些用戶回復格式不正確,很容易在兩個字之間少打或多打空格,這給預處理文本造成了很大的障礙。本文首先根據具體網站的源碼,找到并篩選出多空格與少空格的句子。其次,根據網站的規則去掉地址類似、內容全部相同的文本。本文對15個相關網頁內容進行了過濾,最后得到語句約 2 800萬句。
在維吾爾語方面,進行如此大數據量的采集與預處理,是從未有過的。這也使得此實驗有充足的數據作基礎,使得驗證的算法更準確。
3.2 斷句保存
將原始語料庫根據標點符號與特殊符號分割成句子形式,由于維吾爾語的書寫習慣與漢語不同,所用的符號也不相同,應當把所有可能出現的維吾爾語書寫符號羅列出,以便根據這些符號進行斷句。本文共羅列出了31個特殊符號,據此斷句,丟棄太長或者太短的句子(本實驗選取的句子為6到18個詞之間)。
3.3 統計口語常用詞表
每一種語言通常根據其應用領域不同,常用詞表涉及的內容也不同。比如體育的、生活的、書面語的、官方新聞的和常用語的詞表等等。但是語音識別主要是識別人的語言,那么從常用語作突破,才能更加貼近生活。為了使得到的數據更加準確,用程序實現把40萬個口語文本集整合到100個文本內。然后對每個文本進行分詞,由于第二步得到不含特殊符號的有效句子,因此在這里可以僅根據空格分詞。然后進行詞頻統計,保留不重復的獨立詞,并統計每個詞出現的頻數。最后根據各個詞頻的大小進行排序。抽選出頻率最高的常用詞頻,本文選取出了頻率幅度最高的前2 200個口語常用詞。
3.4 給每個句子打分篩選
打分的目的是使得在同樣語音環境下,包含的常用詞較多的句子可以有優先被選取的機會[11]。
首先定義每個詞的權重,如果該詞存在于常用詞表中,則采用如下計算公式,否則Q值不變。
(1)
其中,s為每個詞的權重賦值,可根據具體實驗需求設置,本文設置為0.5;
Ci為第i個詞在List表中出現的頻數;
List表初始化為空。每讀取句中的一個詞,判斷是否存在List中,如果不存在,則插入List中,否則不操作。
R為限制Ci頻數的閾值,可根據具體實驗需求設置,本文設置為3;
(2)
定義句子權重為權重總和的平均值。
(3)
其中,Word(i)為第i個詞,T為該句中包含的詞的總數。
3.5 設定參數值
一個句子中重復詞出現太多會影響選取結果,設置詞的重復頻數Ct可以避免這種情況的發生。我們可以根據對N值的取值,來設定所取語料的規模。也可以根據得分對句子由高到低降序排序。實驗中的其它參數數值可以根據實驗需求設定。
預處理語料流程圖如圖1所示。
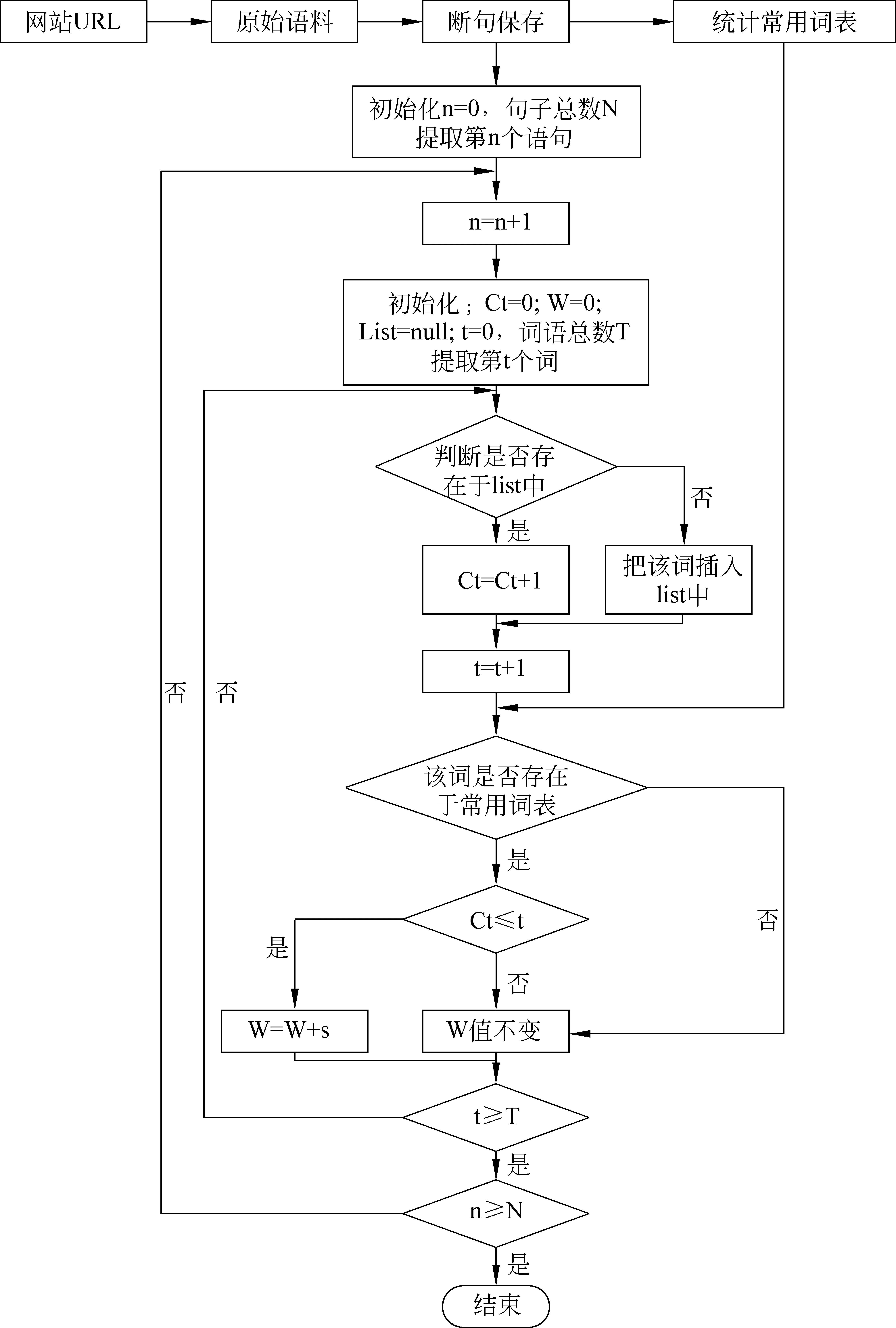
圖1 預處理語料流程圖
在實際抽選過程中,由于原始語料庫的規模可能非常龐大,例如,我們采用的原始語料庫經過預處理后共包括大約2 800萬個句子,遍歷如此龐大的語料庫并按照每個句子的得分順序排序需要花費大量的運算時間。為此我們采用了一種平衡二叉樹結構來保存得分最靠前的N個句子: 在遍歷整個原始語料庫的過程中,依次將每個句子插入到二叉樹的一個節點中,該節點記錄了此句子的ID標識及其評估得分值W,當二叉樹的節點數目達到N時,如果下一個句子的評估分值小于該二叉樹最左子樹節點(即該二叉樹中最小值)的評估分值,則放棄插入,繼續下一個循環;否則首先刪除該二叉樹的最左子樹節點,然后將該句子插入到樹中,對于含有N個樹節點的理想二叉樹,每次插入或刪除運算的復雜度為O(logN)[12]。
4 根據三音子覆蓋率篩選語料
維吾爾語語音識別基元的選取是影響維吾爾語語音識別系統性能的一個關鍵問題,因為它決定了聲學模型的精細程度和可訓練度[11]。本文考慮了協同發音的影響,以上下文相關的三音子模型為語音識別基元。首先把語料拆分成音子形式,其次根據三音子音聯關系進行綁定,最后對三音子形式的句子打分、排序、篩選。
綁定三音子具體步驟如下:
(1) 從句子庫讀取一句,n=n+1;
(2) 將文本代碼轉換成拉丁文的基本區域。
(3) 根據此轉換結果,生成出現的所有單詞的有序詞表;
(4) 對原語料句子注音,并根據發音詞典規則,生成發音詞典;
(5) 利用HTK工具包的命令,根據已生成文件列表和腳本文件,按照字典展開,得到基于單音素的因素列表;
(6) 由單音素文件轉換成等價的三音素級標注文本。
綁定三音子流程圖如圖2所示。

圖2 綁定三音子流程圖
把語料拆分為三音子形式后,采用優先原則,包含語音現象最多的句子將會首先被挑選出來。
首先定義一句話中每個三音子的權重為:
(4)
我們設計了一個三音子表Stable,存放所有已出現的三音子。
m為每個詞的權重賦值, 可根據具體實驗需求設置,本文設置為1;
其中,Ci為第i個詞在Stable三音子表中出現的頻數。
定義句子權重為三音子權重總和的平均值為:
“我只是來告訴你,艾瑞克剛發布了新通知,我們明天去城市圍欄實地訓練,學習無畏派的職責。”艾爾說,“明天八點一刻在火車那里集合,準時出發。”
(5)
triphone(i) 為該句話中的第i個三音子,N為該句中包含的三音子總數。
評估篩選三音子流程圖如圖3所示。
此種算法較傳統算法更加穩定,魯棒性更強。傳統算法需要分批次處理大量語料,如若不然,在處理一定規模數據后, 后面出現的句子得分大部分是0[9,11-12],這使得數據界限不好判定,并且數據的精確度只能模糊限定。而本文中的算法無需這方面的擔憂,用戶可以對所有數據語料進行一次性處理。
5 算法的評測標準和實驗結果
我們所篩選語料的算法是否可靠以及在評估函數中各參數的設置是否恰當,是以已被選中的語料所覆蓋的三音子數目以及數據稀疏度等因素指標來衡量的[9]。很顯然,找到的三音子數目越多,覆蓋率越高,算法就越好。其中,覆蓋率的定義為: 覆蓋率=語料集覆蓋的不重復三音子數/維吾爾語三音子總數。

圖3 評估篩選三音子流程圖
5.1 語料選取
實驗室所用語料主要采集于維吾爾語常用口語交流網站,包括微博、博客、論壇等。根據本文中的第一部分篩選規則,對原始語料進行分句并丟棄過長或者過短的句子。按照所占常用詞表的比重,對原始語料進行篩選排序。
維吾爾語語言中包含的單音素共有34個,理論上互相結合后的三音子數為34×34×34個。但實際上很多音素結合后并不一定生成有效的三音子,這就給我們的工作帶來了很多的冗余信息與冗余操作。本文對所選語料的全部三音子進行統計,并篩掉不規范音子與重復音子,得到23 840個有效的維吾爾語三音子。
5.2 實驗結果
(1) 測試選取算法包含三音子數量的穩定性,從已篩選的前五萬句語料中,分別抽樣選取了兩組A、B,每組都是由6 000句、8 000句、10 000句組成的三份文檔。對比數據如表1所示。

表1 A組與B組數據對比
根據表1可知,所選取的三音子覆蓋率達到了84%。我們分析了上述語料統計中尚未包含的三音子的情況,它們是維吾爾語中出現概率極其微小的情況,分別是“韻尾+韻母+韻頭”和“聲母+韻母+韻頭”的。前者主要是三個零聲母音節相鄰的情況,如“a+a+e”之類的三音子;后者在維吾爾語中為有聲母音節和零聲母音節相鄰的情況,并且此韻頭又可同時單獨作為一個音節,如“o”在實際中這類情況幾乎不會出現[11]。
A、B兩組,重在測試選取算法包含三音子數量的穩定性。在已挑選的語料集中,可能某些實驗不需要那么多的語料。這時,我們隨機抽選出適用于具體實驗規模的語料,得到的結果并沒有差異性。依據上述的分析可知,本文中的算法挑選出的語料是具有代表性和普遍性的。
(2) 等距抽樣選擇語料是將總體中各單位按一定順序排列,根據樣本容量要求確定抽選間隔,然后隨機確定起點,每隔一定的間隔抽取一個單位的一種抽樣方式。本文從原始語料中抽樣選取出C組文檔,同樣是由6 000句、8 000句、10 000句組成的三份文檔。對比數據如表2所示。

表2 A組與C組數據對比
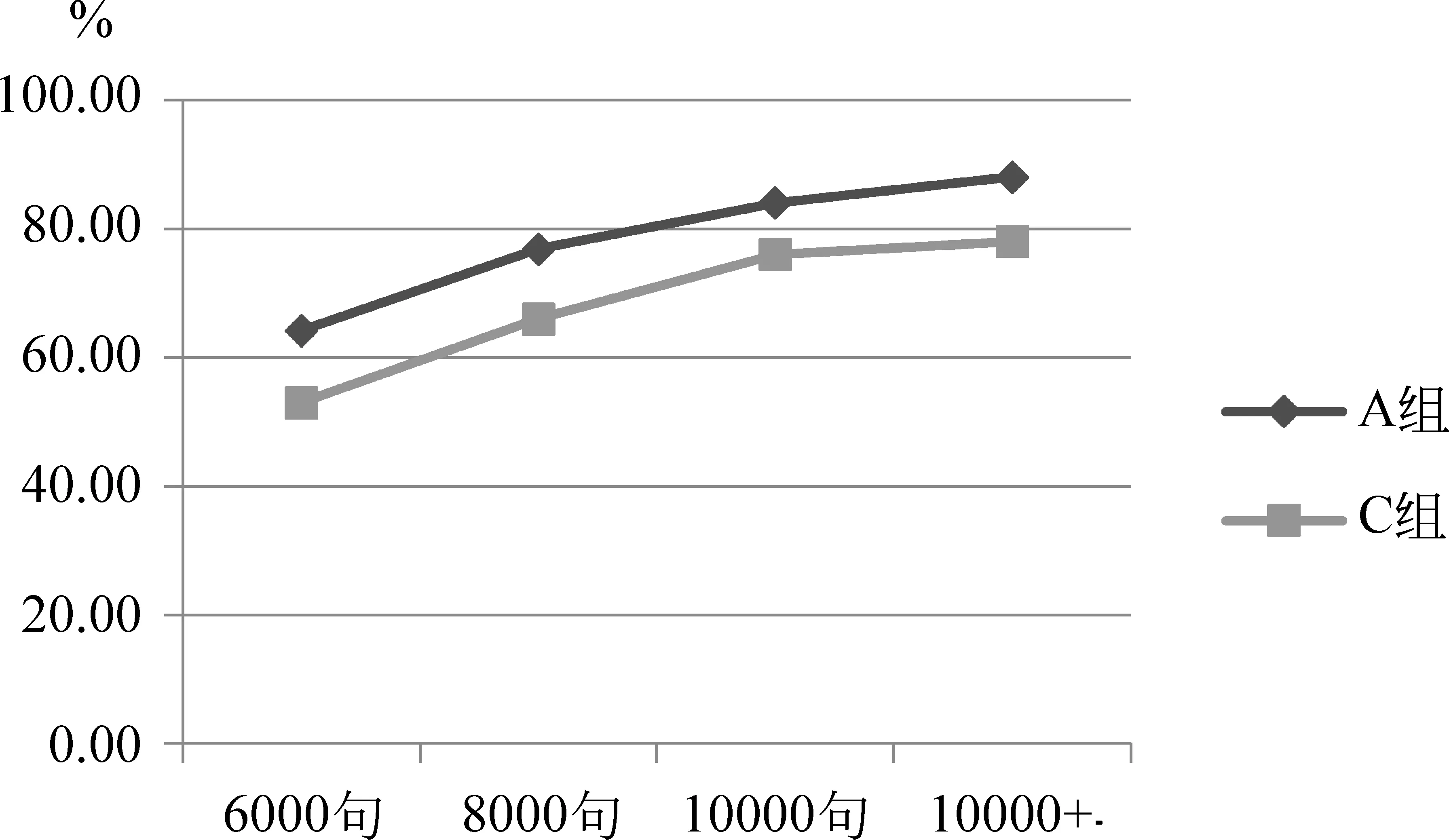
圖4 A組與C組數據走勢對比
表2與圖4是用我們的算法挑選出來的語料和等距抽樣方法挑選出來的語料的比較。等距抽樣方法在抽選10 000句語料后,覆蓋三音子總數的77.01%。即使將數據規模再擴大,等距抽樣蘊含的不重復三音子數也沒有明顯的提升。而本文所得出的每個三音子在語料中出現的次數相對比較平均,并且在挑選10 000句語料后可覆蓋84%的三音子。
在實際情況中,我們不可能訓練足夠多的語句做實驗。我們總是希望使用較少的語句,就可以覆蓋更多的語音現象。本文的選取方法在選取數量達到10 000句時,就可以覆蓋絕大多數的語音現象,而傳統的方法不能做到這。傳統方法中即使選取數萬語句,涵蓋三音子數也達不到本文方法選取出的10 000句,故此方法更適合維吾爾語三音子的選取。
6 總結與展望
本文結合維吾爾語口語的自身特點,提出了一種連續語音口語語料的自動選取方法,這種方法既考慮了常用詞的分布排序,也考慮了上下文相關的三音子音素形式的影響。挑選出的語料既滿足了語音單元覆蓋和詞頻調整方面的需求,又緩解了數據稀疏問題。
本文沒有深入研究維吾爾語的語法結構和發音規律,后續工作可以與之結合展開研究。
[1] Rabiner L R, Juang B H. Fundamentals of speech recognition[M]. Englewood Cliffs: PTR Prentice Hall, 1993.
[2] 那斯爾江·吐爾遜,吾守爾·斯拉木.基于隱馬爾可夫模型的維吾爾語連續語音識別系統[J]. 計算機應用,2009,29(7): 2009-2012.
[3] 劉玉宇, 吳及, 王作英. 漢語三音子模型觀測概率比較[J]. 中文信息學報, 2003, 17(3): 47-52.
[4] 曹劍芬. 普通話語音的環境音變與雙音子和三音子結構[J]. 語言文字應用, 1996, 2: 58-63.
[5] 林燾, 理嘉. 語音學教程[M]. 北京: 北京大學出版社, 1992.
[6] 曹劍芬. 普通話雙音子和三音子結構系統代表語料集[J]. 語言文字應用, 1997, 1: 60-68.
[7] 蔡琴,吾守爾·斯拉木. 基于HTK的維吾爾語連續數字語音識別[J]. 現代計算機: 下半月版, 2007,(4): 14-16.
[8] 那斯爾江·吐爾遜,吾守爾·斯拉木,麥麥提艾力.維吾爾語大詞匯量連續語音識別研究——語音語料庫的建立[C]//第十一屆全國民族語言文字信息學術研討會論文集,2007(2): 379-385.
[9] 吳華, 徐波, 黃泰翼. 基于三音子模型的語料自動選擇算法[J]. 軟件學報, 2000, 11(2): 271-276.
[10] 熱依曼·吐爾遜.維吾爾語語音語料庫管理軟件的研究與實現[J]. 新疆大學學報: 自然科學版, 2011 (2): 242-247.
[11] 康恒, 劉文舉. 基于綜合因素的漢語連續語音庫語料自動選取[J]. 中文信息學報, 2003, 17(4): 27-32.
[12] 寧振江, 杜利民. 面向語音識別聲學模型的漢語語料抽選方法[J]. 聲學技術, 2003 (z2): 356-358.
[13] 庫熱西·馬合木提,阿米娜·立提市,亞熱·阿白都拉.現代維吾爾語[M].烏魯木齊: 新疆人民出版社,2003.
[14] 趙暉, 林成龍, 唐朝京. 基于視頻三音子的漢語雙模態語料庫的建立[J]. 中文信息學報, 2009, 23(5): 98-103.
[15] 陶梅, 吾守爾, 斯拉木. 基于 HTK 的維吾爾語連續語音聲學建模[J]. 中文信息學報, 2008, 22(5): 56-59.
Analysis of Triphone Selection Method in Uyghur Speech Corpus
XU Baolong, Nuermaimaiti Youluwasi, Wushouer Silamu
(College of Information Science and Engineering, Xinjiang University, Urumqi, Xinjiang 830046, China)
A good speech training corpus is essential for the wide application of continuous speech recognition. Therefore, whether more multiple voice phenomena are covered in the corpus is of substantial importance to improve the performance of speech recognition. In this paper, we collect a large number of spoken corpus sentences from a variety of Uighur spoken language communication platforms. Then, we refine the corpus according to the evaluation function considering the effect of co-articulation and applicability of the common words. The final corpus contain mor more balanced and efficient tri-phones, covering more phonetic phenomena, which lays a solid foundation for training a much accurate and reliable acoustic model.
Uighur Language;speech recognition;database;Triphone

徐寶龍(1988—),碩士研究生,主要研究領域為語音識別,自然語言處理.E?mail:xbl_hometown@hotmail.com努爾麥麥提·尤魯瓦斯(1980—),講師,博士,主要研究領域為自然語言處理,語音識別。E?mail:y.nurmemet@gmail.com吾守爾·斯拉木(1942—),中國工程院院士,博士生導師,主要研究領域為多語種信息處理。E?mail:wushour@xju.edu.cn
1003-0077(2015)02-0118-07
2014-04-17 定稿日期: 2014-10-27
國家973重點基礎研究計劃項目(2014CB340506);國家自然科學基金(61363063);新疆維吾爾自治區科技計劃項目(201312104)
TP391
A
