中文維基百科的實體分類研究
2015-04-21 10:40:05徐志浩惠浩添錢龍華朱巧明
中文信息學報 2015年5期
徐志浩,惠浩添,錢龍華,朱巧明
(1. 蘇州大學 自然語言處理實驗室,江蘇 蘇州 215006;2. 蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
?
中文維基百科的實體分類研究
徐志浩1,2,惠浩添1,2,錢龍華1,2,朱巧明1,2
(1. 蘇州大學 自然語言處理實驗室,江蘇 蘇州 215006;2. 蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
維基百科實體分類對自然語言處理和機器學習具有重要的作用。該文采用機器學習的方法對中文維基百科的條目進行實體分類,在利用維基百科頁面中半結構化信息和無結構化文本作為基本特征的基礎上,結合中文的特點使用擴展特征和語義特征來提高實體分類性能。在人工標注的語料庫上的實驗表明,這些額外特征有效地提高了ACE分類體系上的實體分類性能,總體F1值達到96%,同時在擴展實體分類上也取得了較好的效果,總體F1值達95%。
維基百科;實體分類;半結構化信息;信息框
1 引言
維基百科作為一個開放的知識庫系統,其中的條目都是對一個概念或者實體的內容描述,每個條目的頁面中包含了豐富的結構化、半結構化的信息和文本資源。維基百科實體分類是指對維基百科中的條目進行識別和分類,從中提取出各種類型的實體(如人物、組織、地名等)。對于這些實體的分類有助于進一步從維基百科中挖掘出更豐富的信息(如實體關系、語義關系等),同時維基百科中豐富的文本也為自然語言處理和機器學習提供了高質量的語料來源[1-2]。
2 相關工作
對維基百科條目進行實體的識別和分類,目前主要有兩種方法: 基于啟發式規則的方法和基于機器學習的方法。早期的方法主要是基于規則,如Bunescu 和Pasca[3]利用了標題首字母大寫等一系列規則來識別英文維基百科的某個條目是否是一個命名實體。Zirn等[4]進一步利用分類框(Category)中心詞的單復數形式這一規則,他們認為如果類別中心詞是以單數形式出現的,這個中心詞就是一個實體。Toral等[5]則首先提取條目摘要中的第一句(稱為定義句),并找出句中所有名詞在WordNet中的語義層次及類別來幫助確定條目所屬的實體類別。基于規則方法的缺點是缺乏靈活性,需要對不同的實體類型制定不同的規則,并且隨著規則的增多,不同規則之間可能會產生沖突。
利用機器學習來進行實體識別和分類可以克服這一缺點。Bhole[6]在維基百科條目文章的第一段和全文文本上,分別利用詞包(bag-of-words)模型,使用SVM進行條目的實體分類工作。Tardif等[7]將維基百科的摘要文本作為基本特征,并使用了分類框、信息框(Infobox)和模板(Template)等內容作為額外特征。Dakka 和 Cucerzan[8]則將條目中的詞匯、結構化信息(如表格)、摘要等內容作為特征進行組合,來獲得最好的分類效果。在Tardif和Dakka的實驗中,都對比了使用SVM分類器和樸素貝葉斯分類器的實驗結果,他們的實驗結果都表明SVM的分類性能更好。
上述工作都是針對英文維基百科上的實體識別和分類,目前還沒有中文維基百科上的實體分類工作。雖然和英文維基百科相比,中文維基百科的容量要小得多,但它對中文自然語言處理的潛力還沒有被充分挖掘出來,相關的工作也比較少[9-10]。因此,對中文維基百科的條目進行實體識別和分類具有一定的研究價值。本文在傳統特征的基礎上,提出了一系列針對中文特點的有效特征,使用SVM分類器進行中文維基百科的實體分類,取得了較好的結果。
3 維基百科頁面格式
維基百科中每個條目都是對一個概念或實體的描述,條目的內容由網絡志愿者協作編撰,任何使用互聯網的用戶都可以編寫和修改維基百科條目的文章內容。在編寫過程中,用戶須遵循維基百科的格式要求。圖1為一個典型的維基百科頁面格式,它具有豐富的半結構化信息和非結構化文本,其主要內容有:
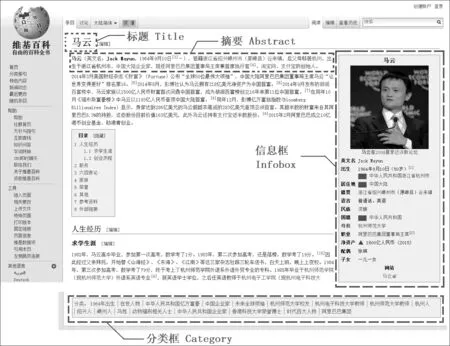
圖1 維基百科頁面格式
1. 信息框(Infobox): 信息框模板是一個總結性的提綱列表,總結了與條目相關的主題,亦或包含圖像、地圖等信息。信息框中內容的格式為標簽(label)與數據(data),例如“馬云”這個人物條目的信息框中有“出生 1964年9月10日”、“國籍 中華人民共和國”、“母校 杭州師范大學”、“職業 阿里巴巴集團董事局主席”等與主題相關的信息。
2. 頁面分類(Category): 頁面分類中列出了條目所屬的類別,以及突出條目事物特征或是主題的相關類別。一個條目可以被分類到多個類別下,需要注意的是,該分類體系并非嚴格的層次體系,具有一定的隨意性。例如,“馬云”這個條目的分類有“1964年出生”、“在世人物”、“中國企業家”、“杭州人”、“阿里巴巴集團”等。
3. 摘要(Abstract): 摘要是指某個維基百科條目文章的第一段,其內容以簡明扼要的文句給出該條目的主要信息內容。摘要中的第一句,往往會有類似“……是……”或“……為……”等句式,我們把這樣的句子稱為顯式定義句,也會有不出現“是”或“為”的隱式定義句。定義句中的中心詞,很有可能反映出條目所屬的類別。例如,“馬云”這個條目的定義句為“馬云(英文名: Jack Ma,1964年9月10日-)中華人民共和國企業家”,其中心詞為“企業家”,可以推斷出,該條目的類別是人物。
4 基于SVM的實體分類
與傳統機器學習的分類方法類似,本文將人工標注類別的維基百科條目分為訓練集和測試集,從中提取各種特征,利用詞包模型,構造相應的特征向量,然后使用SVM分類器從訓練集的特征向量中學習得到分類模型,最后將該分類模型應用到測試集的特征向量上,預測條目的實體類別,并計算分類方法的性能。基于機器學習方法的關鍵在于找出有效的特征來表示維基百科中的條目,本文除了使用維基百科頁面中獲取的基本特征之外,還使用了一些擴展特征和語義特征來幫助提高中文維基百科的實體分類性能,詳見表1。

表1 維基百科中的實體分類特征

續表
4.1 基本特征
本文使用了以下三個類別的基本特征,即信息框、分類框和摘要中的相關內容,具體如下。
1. InfoboxTitle: 信息框中的內容對于實體類型具有很好的識別作用。信息框中的信息形式為“標簽 數據”,我們提取其中的標簽的內容作為一個特征,而不提取數據本身。例如,對于“國籍 中華人民共和國”,取“國籍”作為特征,因為不同的人物,對應的國籍是不同的,而“國籍”這個標簽是共同擁有的。例如,對于“馬云”這個條目,從其信息框中提取到的特征詞為分別為“出生”、“國籍”、“母校”、“職業”、“凈資產”、“配偶”和“子女”,這些特征詞基本都是人物的相關信息。
2. CategoryHead: 分類框中的信息對實體分類同樣具有明顯的識別作用。對于每一個類別,通過分詞處理后,取其中心詞(即最右邊一個詞)作為特征。例如,“1964年出生”,通過分詞取得中心詞“出生”作為一個特征。因此,“馬云”這個條目的分類框中得到的特征詞分別為“出生”、“人物”、“企業家”、“億萬富豪”、“領袖”、“校友”、“教師”、“人”、“姓”、“人士”、“博士”和“集團”等。
3. AbstractHead: 除了上述半結構化信息外,在維基百科的文章中的第一段(即該條目的摘要)也可起到一定的補充作用。對于摘要的處理,我們取其第一句,通過分詞和詞性標注,找出第一句的中心詞(最右邊的名詞)作為特征。特別地,當第一句的句式結構為“……是……”或“……為……”時,更能通過正則匹配輕松獲得該句中心詞。例如,從“馬云”這個條目的摘要中提取到的特征為“企業家”。
4.2 擴展特征
為了更好地對某些類別(特別是人名、地名、組織名等)的實體進行識別,我們加入了下面有關條目標題的擴展特征。前兩個特征是用來幫助提高人物類別的分類性能,而后兩個特征對所有實體類別均有效。
1. IsChineseName: 加入了中文百家姓姓氏列表,將條目名的第一個或前兩個字是否屬于姓氏并且條目標題長度在2到4個字符為一個二元特征。
2. TitleContainsPeriod: 標題是否含有分隔符號。維基百科的外國人名的條目,標題中會使用 “? ”分隔外文姓氏和名字,因此將標題中是否含有分隔符作為一個二元特征。
以上兩個特征的加入,用來幫助提高Person類別的分類性能。
3. TitleLastChar: 考慮到某些命名實體在名稱上的特殊性,例如,地名中“XX省”、“XX市”、“XX縣”,機構名中“XX局”、“XX部”,最后一個字有極高的規律性。因此通過加入條目標題的最后一個字和詞作為兩個特征,來幫助提高ORG、GPE等實體類別的分類性能。
4. TitleLastWord: 某些實體名如“XX協會”、“XX大學”,“XX山脈”等,最后一個詞具有很強的規律性,因此通過加入標題的最后一個詞作為特征,來幫助這類實體的分類。
4.3 語義特征
由于維基百科由網民以共享合作方式撰寫,因此對于同一個或者類似的含義,可能會用不同的詞進行表達,例如,“警察”、“警務人員”、“警官”都表達類似的含義,都指向人物這個類別,導致了特征詞稀疏問題。因此,有必要在基本特征中對表達類似概念的詞匯進行泛化,方法是引入了同義詞詞林,將特征詞匯的語義代碼作為一個特征加入到系統中。
《同義詞詞林》[11]是一部漢語分類詞典,其中每一條詞語都用一個編碼來表示其語義類別。本文所用的《詞林》為《詞林(擴展版)》,是哈工大信息檢索研究室在《同義詞詞林》的基礎上研制的。最終的詞表包含77 492條詞語,共分為12個大類,94個中類,1 428個小類,小類下再以同義原則劃分詞群,最細的級別為原子詞群。不同級別的分類結果可以為自然語言處理提供不同顆粒度的語義類別信息,本文選取詞林語義代碼的第二級和第三級(即語義代碼的前2和前4位)進行實驗。
5 實驗
5.1 數據來源
實驗中所使用的維基百科數據來自于維基百科網站上下載的2014年8月4日中文離線數據包。首先需要將原有數據包文件中的XML標記去除,保留所需要的文本內容。由于維基百科的內容中混合了繁體和簡體中文,為了便于后期處理,需要將所有中文統一轉化為簡體,最后從中提取出每個條目的標題、信息框、分類框和摘要等相關信息。其中,對摘要的首句使用進行分詞和詞性標注。
我們從所有條目中隨機取出8 000個條目作為實驗數據,通過規則匹配去除消歧頁面和列表頁面后,剩下7 612個條目,然后根據ACE的中文命名實體的分類體系對條目進行類別的標注。
實驗所使用的實體分類體系,是在ACE定義的中文命名實體分類基礎上,結合Sekine的擴展命名實體分類體系[12],考慮到實際信息抽取的需要進行設置的。其中,PER、ORG、GPE、LOC和FAC等為ACE定義的五大類實體,其余九類為擴展類別。如非特別指出,下列實驗中的實體分類是指五類ACE實體,其余都為非實體;而擴展實體分類時,14類為實體類別,其余為非實體。
5.2 實驗設置
所有實驗都按照五折交叉驗證方式進行,即實驗數據被隨機分成大小相同的五份,訓練集和測試集的比例為4∶1,使用的分類工具為LibSVM,且SVM的訓練參數均采用默認值。實體分類結果分別使用準確率(P)、召回率(R)和調和平均值(F1)進行評估,最后取五次實驗的平均值作為最終結果。
5.3 實驗結果
5.3.1 各個特征對分類性能的影響
為了考察各個特征對分類性能的影響,本文分別進行了加入和分離實驗,前者以信息框和分類框特征為基準系統,然后單獨加入每個特征,比較它和基準系統之間的性能差異;而后者是以所有特征為基準系統,然后分離出單個特征,比較它和基準系統之間的性能差異。實驗結果如表2所示,其中性能差異用P/R/F1的變化值來表示,每一列中性能變化的最大值用粗體表示,加入實驗的正值表示該特征是有益的,而分離實驗的負值表示該特征是有效的。為便于參考,表格的第1行列出了兩個基準系統的P/R/F1性能。
從表2可以看出,各個特征加入實驗時的性能貢獻比分離實驗時的性能貢獻要大得多,這是由于特征之間往往存在著冗余性, 單獨使用時性能提升很明顯,而同時使用則效果不顯著,此外:
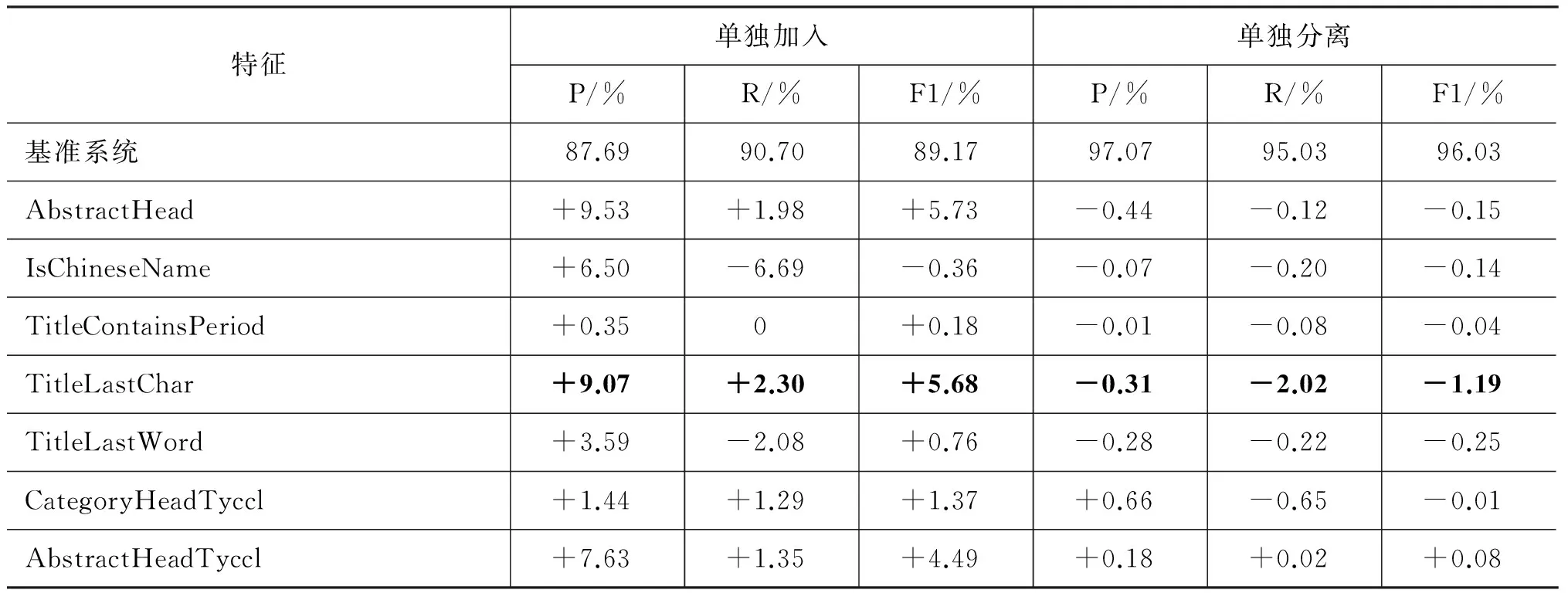
表2 加入和分離實驗中不同特征的性能影響
1. 貢獻最大的特征是TitleLastChar,無論是加入還是分離,都對準確率和召回率有明顯的影響,這主要是由于條目標題的最后一個字對不同類別具有很高的區分性,特別是對于GPE類,如“XX省”,“XX市”等,標題最后一個字具有很強的區分性。同樣TitleLastWord特征的貢獻也很穩定,雖然沒有TitleLastChar特征那么大;
2. 特征AbstractHead在加入實驗中的作用很明顯,但在分離實驗中的變化要小得多,這可能是由于該特征本身很有用,但它和其他特征之間具有一定的冗余性;
3. 兩個人名特征的效果并未達到預期值。特征IsChineseName的加入提高了準確率,但同時召回率也明顯降低。這是由于不少GPE條目的首字母也是中文姓氏,與部分人名產生混淆。不過,雖然它在加入實驗時降低總體性能,但在分離實驗時卻表現出對總體性能略有幫助。同樣,特征TitleContainsPeriod對分類性能也有提高。
4. 兩個語義特征的表現不一致。特征CategoryHeadTyccl的貢獻比較穩定,無論是加入還是分離實驗,都表現出對提高性能的有效性。而特征AbstractHeadTyccl的表現就不一致,盡管在加入實驗中提高了總體性能,但在分離實驗中刪去該特征反而提高了總體性能,可以認為該特征過于泛化。
5.3.2 不同類別的性能比較
根據上述分離實驗中各特征的性能表現,最后確定使用除AbstractHeadTyccl以外所有的其他特征,得到最好的分類性能如表3所示。
從表3可以看到,系統最終取得的分類性能還是較高的,平均F1值超過了96%。其中,性能最高的兩個類別為PER和GPE,這是由于這兩種類型的實例數較多且其條目的特征有較高的一致性, 因此在SVM中得以比較好的訓練;而性能相對較低的三類為ORG、LOC和FAC等,F1值分別約為91%、94%和93%,且是召回率明顯低于準確度,這是因為這三個類別的條目種類形態較多而樣例又較少,無法得到充分的訓練,另外這三個類別下,很多沒召回的條目往往是Category和Abstract中能提取的特征較少或是有噪聲,而標題中提取的特征詞又很稀疏,最后由于沒有提取到有效特征導致無法召回,例如,條目“日本郵政公社”,其摘要和Category中獲取到的特征詞分別為“體”和“郵政”、“事業”,而標題尾詞“公社”在訓練樣例中又屬于稀疏的詞,導致其無法召回為ORG。
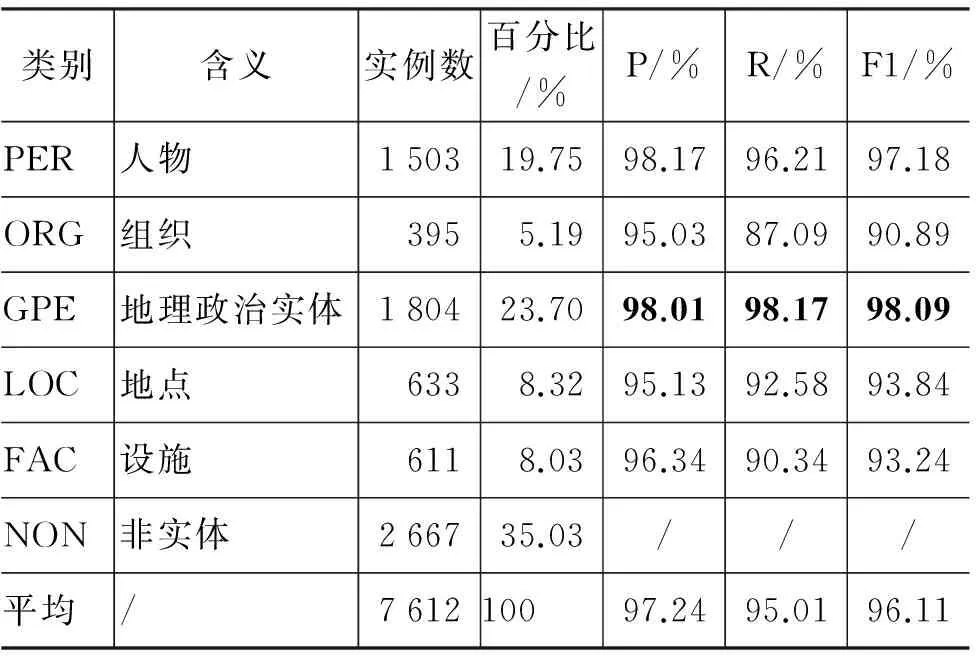
表3 不同類別的分類性能
5.3.3 擴展實體類別的分類性能
表4列出了在14個擴展實體類別上的分類性能(使用的特征集與表3相同)和每個類別的實體數量及所占比例,表中除ACE實體類別外最高的P/R/F1性能用粗體標出。
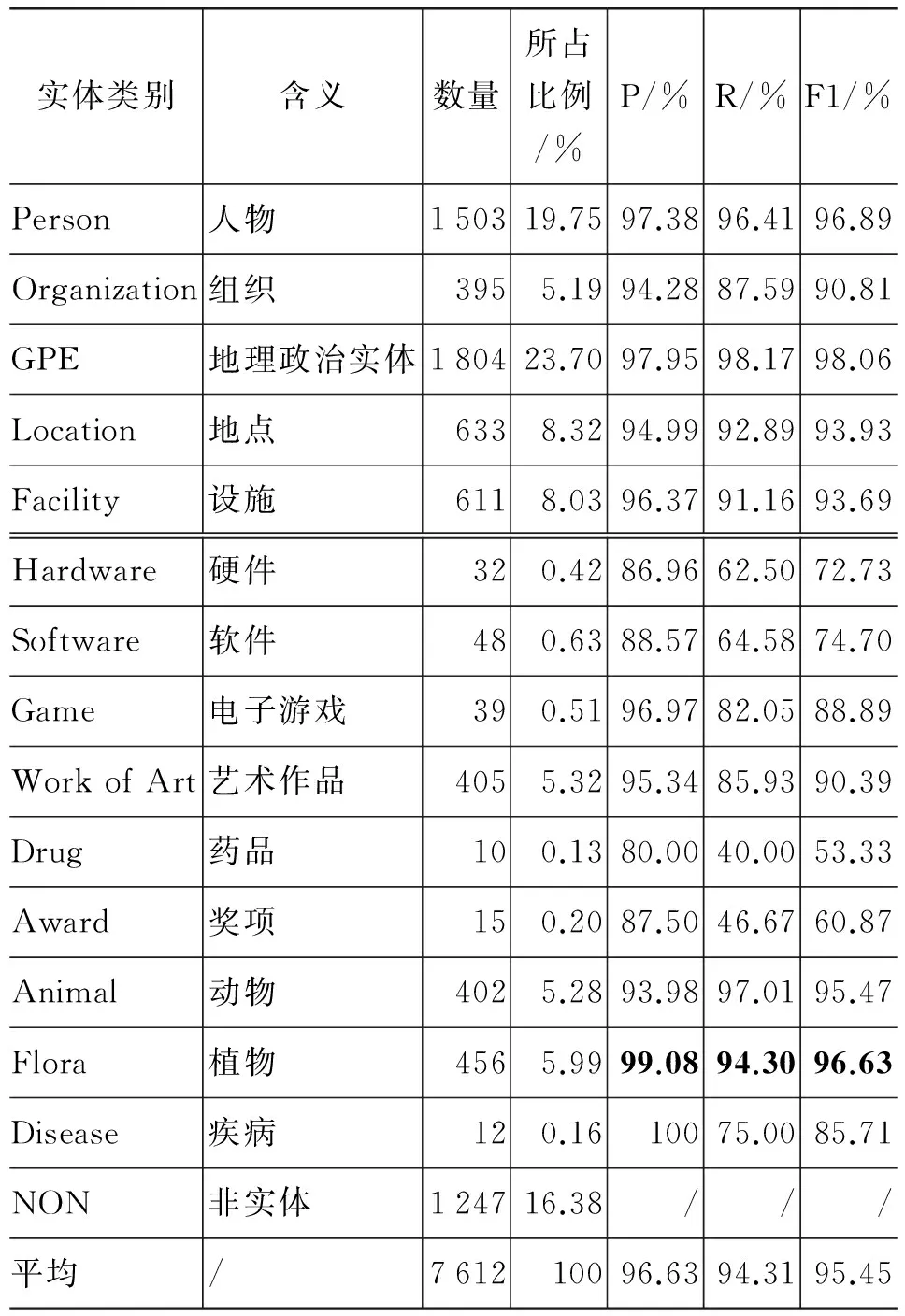
表4 擴展類別上的分類性能
從表4可以看出,擴展至14個實體類別后的P/R/F1平均值為96.63%/94.31%/95.45%,與五個實體大類的分類性能相比雖有降低,但幅度較小,這主要是由于非ACE的實體類別數量較少,占總數比例小于四分之一。對非ACE的九個實體類別,各個類別的F1值和其條目的數量,大致上呈現一個線性關系。即由于訓練樣例太少,從而導致特征稀疏,召回率下降,因此分類性能不盡理想,進一步分析發現:
1. Work of Art、Animal和Flora三個類別與ACE中的ORG實例數量接近,其中Work of Art的性能和ORG相當,因為Work of Art中包括了電影、音樂、書籍等多種藝術形式,因此特征較為多樣化,而相比之下實例數較少,因此無法對特征進行很好的學習,導致召回率較低。Animal和Flora兩類的性能相比ORG明顯高,因為動物和植物的實例在特征上較為一致,都包含“屬”、“種”、“動物”、“植物”等特征詞,但由于這兩類的特征很相似,因此錯分的實例主要集中在這兩類之間互相分錯。
2. Game和Disease這兩個類別盡管數量不多(前者不到40,后者略大于10),但F1性能都在85%以上,這是由于它們的特征雖然數量少但較為一致。例如,Game類實體中均含有“游戲”“開發商”“平臺”等特征詞;而Disease類的Category中都有“疾病”這個特征詞。
5.3.4 與英文維基的實體分類性能比較
為了考察不同語言之間維基實體分類的難度,本文比較了中英文維基實體的分類性能。英文維基的實體分類中比較典型的是Tkatchenko等[13]的研究工作。他們總共劃分了18個實體類別,本文共劃分14個實體類別,兩者共有的類別共有9個,因此本文選取了中英文共有且實例數量較多的類別進行比較,結果如表5所示。
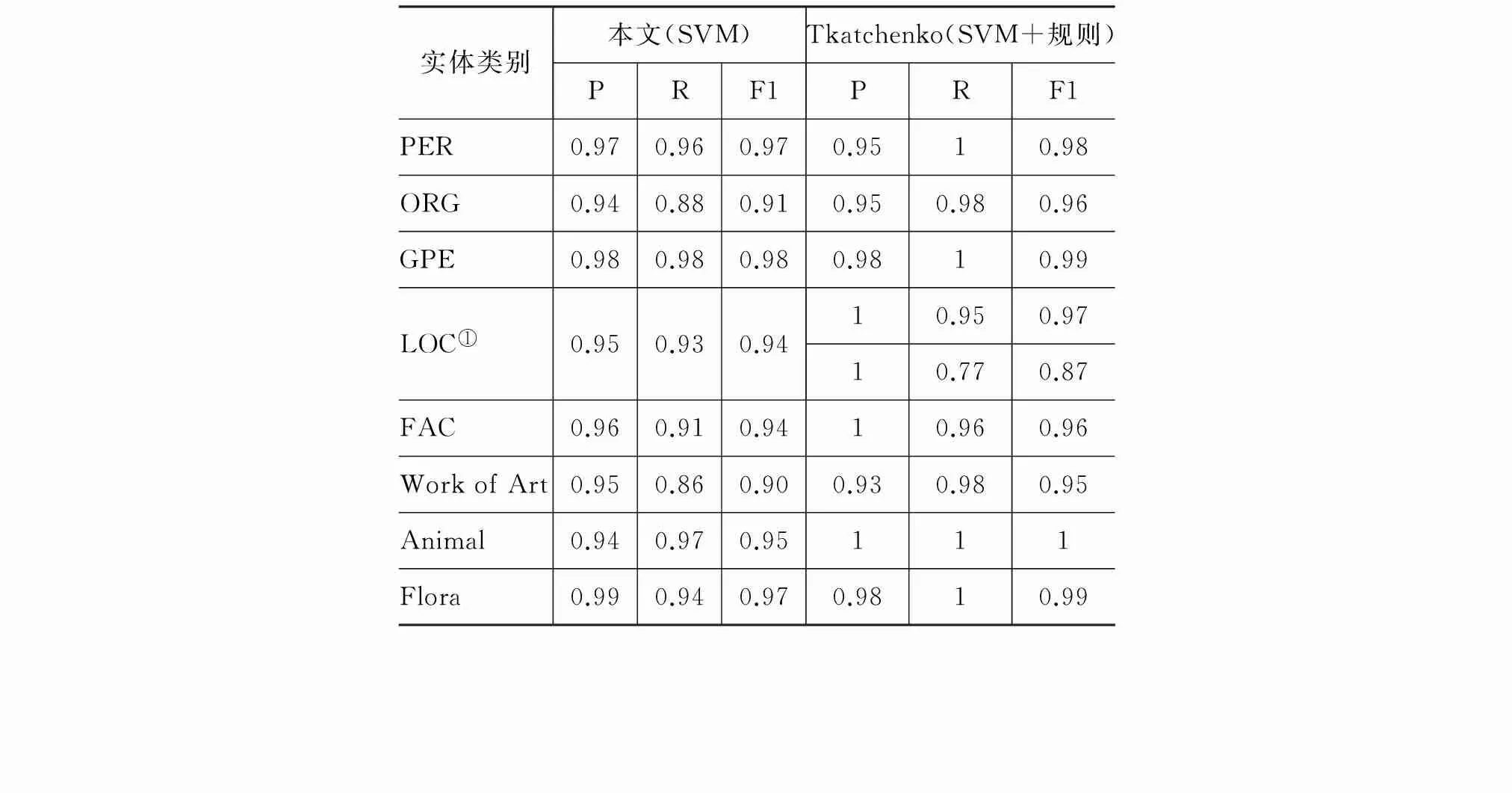
表5 中文和英文維基實體分類性能的比較
①由于本文的使用的實體分類體系和Tkatchenko論文的分類體系有所不同,Tkatchenko論文中ASTRAL_BODY和GEO_REGION兩個類別為本文類別LOC的兩個子類,故在對比時,將本文LOC的性能與其兩類的性能作比較。
需要指出的是,兩者所使用的分類體系和數據集不一樣(英文中使用18個類別,5 294個條目,本文使用14個類別,7 612個條目),不過,我們還是可以看出,英文維基百科的擴展實體分類性能整體上都優于中文。在PER和GPE兩個類別上,中英文的性能旗鼓相當;而在其他類別上,兩者之間的分類性能還有相當差距。可能的原因是中文的PER在Category上的特征一致性較高,GPE在標題特征上一致性較高,另外這兩類的訓練樣例數量相對較多,因此得到了比較理想的分類性能,而相比之下,中文的ORG、LOC和FAC,樣例的形態較為多樣,另外訓練樣例又較少,導致部分特征較為稀疏。
由于中文和英文在形態和語法上的區別,使得在英文中使用的很好的特征和規則,在中文上未必有效。例如,在Bunescu 和Pasca的論文中使用的首字母大寫這一規則來判斷某個條目是否屬于實體就無法在中文中使用;在Tkatchenko的論文中,在對實體分類前,通過使用一系列規則對實體與非實體進行二元分類,精度和召回率都達到了95%。另外由于受到中文分詞技術的限制,在提取Category和Abstract中心詞時會出現一些錯誤和偏差,導致噪聲的引入,影響分類性能,而在英文中,就不存在這樣的分詞問題。
此外,英文維基百科的發展比中文維基百科的發展更好,其在內容的正確性和完整性上都優于中文維基百科。我們觀察到,未能召回的中文條目,很大一部分條目的頁面內容十分少,并缺乏相應的Category和Infobox等半結構化信息,導致無法提取到這些條目的有效特征,從而無法對這一部分條目進行正確分類。
5.4 錯誤分析
為了進一步了解產生分類錯誤的原因,本文隨機選取了100個錯分的維基條目進行分析,發現分類錯誤原因主要有以下幾個類別:
1. 分類框信息不規范。維基條目的分類框內容并非完全都是條目所屬的嚴格意義上的某個類別,還包括與條目相關的類別。例如,條目“世界新聞自由日”的分類框中有“聯合國教科文組織”,得到特征詞“組織”,此特征導致條目被錯分為ORG。這部分錯誤占總數的44%;
2. 標題名稱的不確定性。某些類別的條目標題和其他類別的條目標題特征相似,從而產生誤導。例如,條目“赫爾曼·凱斯滕獎”和“曹洞宗”被錯分為PER類別,但實際上它們只是含有PER類別的某些特征。這類錯誤占總數的30%。
3. 類屬條目和實體條目的相似性。所謂類屬條目是對某一實體類別的描述,因而在特征上與實體條目相似。例如,條目“皇上”、“動作片演員”這類稱謂、職業類條目易被錯分為PER類別。這類錯誤占總數的13%;
4. 其他較為個別或者無法明確歸類的錯誤,約占總數的13%。例如,語言中存在著一詞多義現象,因此多義詞作為一個統一的特征時,容易引起錯誤。例如,“組織”這個詞,可能屬于“機構”這個概念,也可能屬于“生物體”的概念。
6 結論
本文利用維基百科條目中的半結構化信息作為特征,并根據中文實體的特點加入擴展特征和語義特征,從而對中文維基百科條目進行實體分類。實驗表明,這些特征可以有效提高維基實體分類的性能。其中對于ACE實體類別的分類性能F1值超過96%,達到了實用價值;而對于擴展實體類別,則還需要通過標注更多的實例來提高實例數較少的類別的分類性能。
目前的方法都是基于詞匯層面,還未考慮到句法和語義層面,因此今后的工作一方面可考慮挖掘句法和語義特征,以進一步提高分類性能;另一方面,可利用該分類模型對所有的維基百科條目進行實體分類,并將這些識別出的命名實體應用到自然語言處理的其他任務中。
[1] Nothman J, Curran J R, Murphy T. Transforming Wikipedia into named entity training data[C]//Proceedings of the Australian Language Technology Workshop. 2008: 124-132.
[2] Nothman J. Learning named entity recognition from Wikipedia[D]. The University of Sydney Australia 7, 2008.
[3] Bunescu R C, Pasca M. Using Encyclopedic Knowledge for Named entity Disambiguation[C]//Proceedings of the EACL. 2006, 6: 9-16.
[4] Zirn C, Nastase V, Strube M. Distinguishing between instances and classes in the wikipedia taxonomy[M]. Springer Berlin Heidelberg, 2008.
[5] Toral A, Munoz R. A proposal to automatically build and maintain gazetteers for Named Entity Recognition by using Wikipedia[J]. NEW TEXT Wikis and blogs and other dynamic text sources, 2006, 56.
[6] Bhole A, Fortuna B, Grobelnik M, et al. Extracting named entities and relating them over time based on wikipedia[J]. Informatica (Slovenia), 2007, 31(4): 463-468.
[7] Tardif S, Curran J R, Murphy T. Improved text categorisation for Wikipedia named entities[C]//Proceedings of the Australasian Language Technology Association Workshop 2009. 2009: 104.
[8] Dakka W, Cucerzan S. Augmenting Wikipedia withNamed Entity Tags[C]//Proceedings of the IJCNLP. 2008: 545-552.
[9] 諶志群, 高飛, 曾智軍. 基于中文維基百科的詞語相關度計算[J]. 情報學報, 2013, 31(12): 1265-1270.
[10] 張葦如, 孫樂, 韓先培. 基于維基百科和模式聚類的實體關系抽取方法[J]. 中文信息學報, 2012, 26(2): 75-81.
[11] 梅家駒. 同義詞詞林[M]. 上海: 上海辭書出版社, 1983.
[12] Sekine S, Sudo K, Nobata C. Extended Named Entity Hierarchy[C]//Proceedings of the LREC. 2002.
[13] Tkatchenko M, Ulanov A, Simanovsky A. Classifying Wikipedia entities into fine-grained classes[C]//Proceedings of the Data Engineering Workshops (ICDEW), 2011 IEEE 27th International Conference on. IEEE, 2011: 212-217.
Classifying Named Entities on Chinese Wikipedia
XU Zhihao1,2,HUI Haotian1,2,QIAN Longhua1,2,ZHU Qiaoming1,2
(1.Natural Language Processing Lab of Soochow University,Suzhou,Jiangsu 215006,China;2. School of Computer Science & Technology,Soochow University,Suzhou,Jiangsu 215006,China)
Classifying Wikipedia Entities is of great significance to NLP and machine learning. This paper presents a machine learning based method to classify the Chinese Wikipedia articles. Besides using semi-structured data and non-structured text as basic features, we also extend to use Chinese-oriented features and semantic features in order to improve the classification performance. The experimental results on a manually tagged corpus show that the additional features significantly boost the entity classification performance with the overall F1-measure as high as 96% on the ACE entity type hierarchy and 95% on the extended entity type hierarchy.
Wikipedia; named entities classification; semi-structured data; Infobox

徐志浩(1991—),通信作者,碩士研究生,主要研究領域為信息抽取。E-mail:20134227020@stu.suda.edu.cn惠浩添(1991—),碩士研究生,主要研究領域為信息抽取。E-mail:20134227019@stu.suda.edu.cn錢龍華(1966—),副教授,碩士生導師,主要研究領域為自然語言處理。E-mail:qianlonghua@suda.edu.cn
1003-0077(2015)05-0091-07
2015-07-08 定稿日期: 2015-09-08
國家自然科學基金(61373096,90920004),江蘇省高校自然科學研究重大項目(11KJA520003)
TP391
A
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
