高斯加權的重構性K-NN算法研究
2015-04-21 10:51:41劉作國陳笑蓉
中文信息學報 2015年5期
關鍵詞:文本
劉作國,陳笑蓉
(貴州大學 計算機科學與技術學院,貴州 貴陽 550025)
?
高斯加權的重構性K-NN算法研究
劉作國,陳笑蓉
(貴州大學 計算機科學與技術學院,貴州 貴陽 550025)
該文提出基于高斯加權距離以及聚類重構機制的K-NN文本聚類算法。文章提出K-NN近鄰域的概念,通過高斯加權的近鄰域算法實施K-NN聚類。利用高斯函數根據樣本與聚類中心的距離為樣本賦權,計算聚類距離。基于近鄰域權重和聚類密度對形成的聚類實施重構,實現聚類數目的自適應調整。使用拆分算子拆分稀疏聚類并調整異常樣本;使用合并算子合并相似聚類。實驗顯示聚類重構機制能夠有效地提高聚類的準確率及召回率,增加聚類密度,使得形成的聚類結果更加合理。
文本聚類;K-NN算法;高斯加權;近鄰域規則;聚類重構
1 引言
K-NN聚類算法簡潔實用,是一類常見的文本聚類算法。K-NN算法選定樣本子集形成初始聚類分布,根據初始分布將測試樣本劃入最近聚類。K-NN算法初始聚類的選擇直接影響聚類結果,聚類過程缺少對結果的檢測和調整機制,難以實現聚類數目的自適應變更[1]。
本文主要針對K-NN算法的距離判定策略和聚類重構機制進行了研究,通過高斯加權算法實施距離度量,判定樣本歸屬。采用聚類重構機制對不合理聚類實施拆分及合并,實現聚類數目的自適應調整,同時保證形成的聚類更加緊密合理。
2 相關工作
2.1 文本表示
本文主要采用向量空間模型VSM進行文本描述,文本t表示為式(1)。
(1)
同時采用歐式距離描述文本a,b之間的關系,如式(2)所示。
(2)
2.2 聚類密度
本文使用幾何中心來定義聚類的中心,并通過聚類密度描述聚類內樣本的相關性。
定義1(聚類中心) 聚類C的中心定義為其幾何中心:
(3)
定義2(聚類密度) 聚類C的密度定義為式(4)。
(4)
聚類內部樣本與聚類中心越接近,聚類密度就越高,重構的必要性就越小。優先選擇密度較低的聚類實施重構可以提高聚類效率。
2.3 簇間距離
文獻[2]認為樣本的空間分布具有正態分布的性質,靠近聚類中心的樣本權重較高,對聚類間距的影響較大。本文參考其思想,設計了一種高斯加權算法來計算聚類間距,使算法向聚類中心的高密度區域靠近。
定義3(簇間距離) 樣本x相對于聚類C的高斯權重為:
(5)
樣本x與聚類C的距離為:
(6)
聚類Ci與Cj的距離為:
(7)
為便于計算,式(5)取μ=K(C),σ=1。
3 加權K-NN聚類算法
K-NN聚類是一類常用的文本處理算法。算法的思想是: 如果一個樣本S的K個最近鄰更靠近聚類C,就將S劃分入聚類C。
K-NN聚類思想建立在理想假設下,要求初始狀態的聚類劃分合理,并且已經形成的每個聚類內部聯系緊密。但實際情況往往并非如此,即便初始聚類劃分是理想的,隨著大量樣本不斷加入聚類,聚類內部的關聯性可能降低,導致形成的聚類偏離理想狀態[3-4]。
3.1 鄰近域
假設K-NN聚類算法取K=3,圖1中待測樣本x(以圓形表示)被劃分入聚類b(以三角形表示)。但實際上聚類b密度較低,b類樣本之間距離較大,兩個相近樣本距離聚類b中心較遠,因此樣本x距離聚類a(以方形表示)比較近。出現以上問題的原因在于K-NN聚類沒有考慮兩個聚類中的樣本對待測樣本x的影響力,換而言之沒有考慮兩個聚類中各個樣本的權重。

圖1 近鄰域權重的意義
文獻[5]提出一種文本的權重量化思想,指出文本分布越密集的樣本空間區域對聚類劃分的影響越高。文獻[6-7]提出距離聚類中心越近的樣本對聚類的表征能力越強,因此權重也越高。
借鑒經典的K-NN聚類思想,本文提出加權近鄰域的概念來處理待測樣本的劃分問題,并且認為越靠近聚類中心的樣本對聚類的影響力越高,樣本權重也越大[8]。
定義4(近鄰域) 與樣本x距離小于d的全部樣本構成x的d近鄰域,記為式(8)。

(8)
其中d稱為近鄰域的半徑。
定義5(近鄰域權重): 樣本x的d近鄰域為Domain(x,d),聚類Ci與Domain(x,d)交集為Si=Domain(x,d)∩Ci,則:
(9)
稱為x在Ci上的d近鄰域權重,在不引起混淆的情況下簡稱為x的權重。
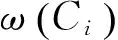
3.2 近鄰域規則
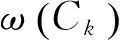
選取近鄰域半徑d內的K個(d為確定值,K為不確定數目)相鄰對象進行聚類判定。采用近鄰域規則判定待測樣本x的類別劃分: 樣本劃分入K個鄰近對象最接近的聚類。其中d為樣本S到最近的聚類的距離。
3.3 聚類重構
為解決初始聚類對聚類結果的影響,采取聚類重構策略對獲得的聚類實施重構。
聚類重構機制根據聚類的密度及各樣本的距離拆分稀疏的聚類,合并相近聚類從而實現聚類的數目及空間分布的自適應調整。重構機制需要考慮以下情形:
1) 異常樣本調整。若聚類內少數樣本與簇內其他樣本聯系較弱,應當將這些“另類”樣本調整到其他聚類中;
2) 稀疏聚類拆分。若聚類密度過低,說明簇內樣本分布稀疏,應當將稀疏聚類拆分為多個密集聚類;
3) 相似聚類合并。若多個聚類聯系緊密,考慮將它們合并為一個聚類,合并后可能需要考慮1)、2)類問題。
1)類問題采用近鄰域算法處理;2)、3)兩類問題分別采用拆分算子和合并算子進行處理。聚類過于稀疏不利于判斷聚類間距,會影響聚類合并,因此聚類重構應當先拆分后合并,并優先處理密度低的聚類[9]。本文參照文獻[10]闡述的聚類改進策略,設置密度閾值來限定拆分算子的作用范圍,聚類拆分的算法如下:
聚類拆分算法
Step1 在密度低于閾值的聚類中選擇密度最低的聚類Ci;
Step2 獲取簇內任意未處理成員t;
Step3 尋找t最近聚類Cj;
Step4 若Ci=Cj轉Step6,否則繼續:
① 若exp[-D(t,Cj)]≥Den(Cj),t歸入Cj;
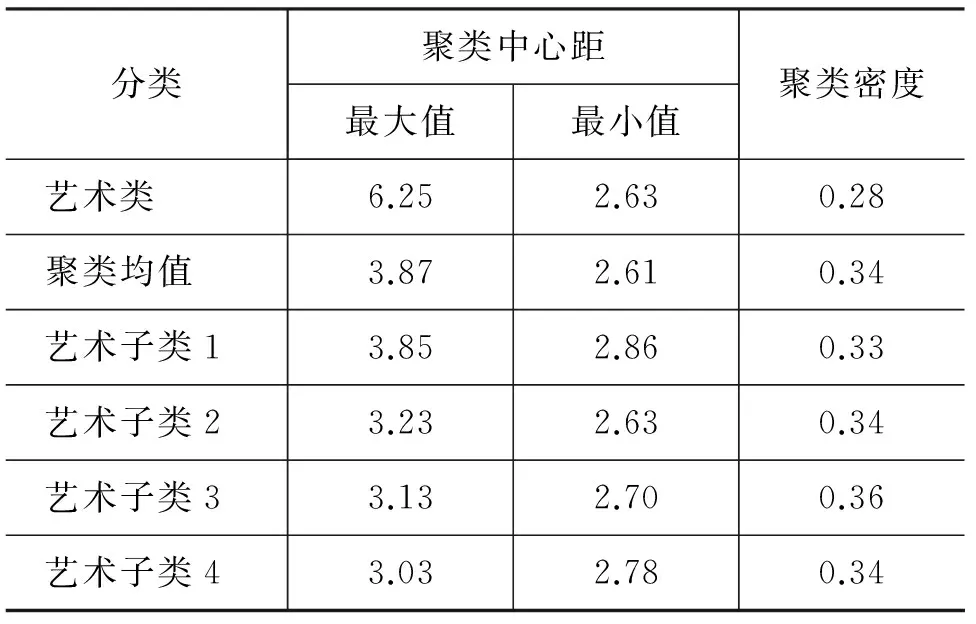
② 若exp[-D(t,Cj)] Step5 更新聚類中心及聚類密度; Step6 迭代處理聚類Ci內所有樣本。 算法Step4中,樣本t最近聚類為Cj,若exp[-D(t,Cj)]≥Den(Cj),說明t比Cj中大多數樣本都更接近聚類中心,允許將t歸入Cj;反之說明t距離Cj中心較遠,進而斷定沒有與t相近的聚類,需要新建聚類來容納樣本t。 設樣本規模為n,理論上拆分算子完成所有計算的平均復雜度為O(n2),由于聚類中心、聚類密度、高斯權重等復雜計算在聚類過程中已經完成,拆分算子實際時間開銷為O(n×logn)。 聚類合并的算法如下: 聚類合并算法 Step1 整個聚類集添加到未處理聚類集合Cu; Step2 獲取任意未處理聚類Ci; Step3 尋找Ci最近聚類Cj; Step4 分析Ci與Cj關系: 若exp[-D(Ci,Cj)]≥Den(Ci)或exp[-D(Ci,Cj)]≥Den(Cj),合并聚類Ci與Cj,更新聚類中心及密度,將新聚類添加到Cu。否則不予以合并; Step5Cu中刪除已處理聚類; Step6 迭代處理Cu中所有聚類。 算法Step4中,若exp[-D(Ci,Cj)]大于等于Ci或Cj任意一個的聚類密度,說明兩個聚類存在較大交集,二者具有包含或較大的重疊關系,考慮將兩個聚類合并。合并產生的新聚類仍作為未處理聚類參與迭代過程。 理論上合并算子復雜度為O(n2),實際為O(n×logn)。 重構機制示例 假設樣本空間共包括三類16個文本,用三種圖形各代表一類文本。初始狀態文本集被分為四類,星形表示各聚類幾何中心,箭頭指向文本的最近聚類。理想狀態重構過程如圖2所示。 圖2 聚類重構示例 經過聚類重構,稀疏聚類得到優化,初始狀態對聚類結果的影響也被削弱。聚類的拆分及合并使得聚類數目動態調整,無需用戶干預,更符合聚類處理的實際應用需求。 本文從復旦大學中文語料庫分別隨機選取500和1 000個樣本進行聚類實驗。采用K-NN算法和加權重構K-NN模型分別進行聚類。統計各類別的準確率、召回率、F-Score值并計算獲得的聚類密度。 實驗結果顯示近鄰域算法和聚類重構機制對文本聚類的處理是有效的。經過重構處理后各類文本準確率、召回率均有顯著提升,聚類密度有所提高,說明重構之后聚類內部樣本關聯性更強。 表1 500樣本K-NN聚類及加權重構K-NN結果對比 表2 1 000樣本K-NN聚類及加權重構結果K-NN對比 從表1及表2可見,藝術類準確率、召回率及聚類密度較低,這是由于語料庫對文本的人工標注不夠細致。語料庫藝術類包括音樂、書畫、舞蹈、美學等多個領域的文章,雖然這些領域都屬于“藝術”范疇,但文本的詞匯特征相差甚遠。通過聚類重構,“藝術”類被劃分為四個子類,如表3所示,每個子類密度仍然是可接受的。 表3 “藝術”子類 表1與表2的對比結果顯示,不同樣本規模下準確率、召回率有一定差別,但重構后聚類密度卻相差無幾,這說明聚類算法對樣本規模是敏感的,但重構機制不受到樣本規模的影響。 本文提出一種高斯加權的K-NN文本聚類算法。采用高斯函數對初始聚類中各個樣本的影響力進行評估。文章引入聚類重構機制調整稀疏聚類,能夠有效提高聚類密度并實現聚類數目的自適應調整。實驗表明,重構機制不受到樣本規模和初始劃分的影響,能夠有效地提高聚類精度,保證聚類的緊密性,其算法時間開銷在可接受范圍。 本文在近鄰域的加權規則和距離度量方面還存在改進和優化的空間。更合理的近鄰域加權規則可以使得K-NN聚類所獲得的聚類更加合理,同時也有助于對稀疏聚類的判定,減小聚類重構的代價。 [1] Hyeong-Il Kim and Jae-Woo Chang. K-Nearest Neighbor Query Processing Algorithms for a Query Region in Road Networks[J]. Journal of Computer Science & Technology, 2013, 28(4): 585-596. [2] 劉金嶺,馮萬利,張亞紅.初始化簇類中心和重構標度函數的文本聚類[J].計算機應用研究,2011,28(11): 4115-4117. [3] 王燦田,孫玉寶,劉青山.基于稀疏重構的超圖譜聚類方法[J].計算機科學,2014,41(2): 145-148,156. [4] 曾依靈,許洪波,吳高巍,等.一種基于空間映射及尺度變換的聚類框架[J].中文信息學報,2010,24(3): 81-88. [5] Amineh Amini, Teh Ying Wah, Mahmoud Reza Saybani, et al. A Study of Density-Grid based Clustering Algorithms on Data Streams[C]//Proceedings of the FSKD 2011. Shanghai China. 2011: 1652-1656. [6] 陳建超,胡桂武,楊志華,等.基于全局性確定聚類中心的文本聚類[J].計算機工程與應用,2011,47(10): 147-150. [7] 季鐸,王智超,蔡東風,等.基于全局性確定聚類中心的文本聚類[J].中文信息學報,2008,22(3): 50-55. [8] 王駿,王士同,鄧趙紅. 特征加權距離與軟子空間學習相結合的文本聚類新方法[J].計算機學報,2012,35(8): 1655-1665. [9] M Shahriar Hossain, Praveen Kumar Reddy Ojili, Cindy Grimm, etal. Scatter/Gather Clustering: Flexibly Incorporating User Feedback to Steer Clustering Results[J]. IEEE Transactions on Visualization and Computer Graphics, 2012, 18(12): 2829-2838. [10] NishaM N, Mohanavalli S, Swathika R. Improving the quality of Clustering using Cluster Ensembles[C]//Proceedings of 2013 IEEE Conference on Information and Communication Technologies. 2013: 88-92. Research on Gauss Weighed Reorganization K-NN LIU Zuoguo, CHEN Xiaorong (College of Computer Science & Technology Guizhou University, Guiyang,Guizhou 550025, China) This paper presents a K-NN text clustering algorithm employing uses Gauss Weighed Distance and Cluster Reorganization Mechanism. The concept of Nearest Domain is proposed and Nearest Domain Rules are elaborated. Then Gauss Weighing Algorithm is designed to Quantification samples’ distance and weights. A text is weighed based on the distance from cluster center via Gauss function in order that distances of clusters can be calculated. Further, Cluster Reorganization Mechanism will make a self-adaption to the amount of clusters. Splitting operator separates sparse clusters and adjusts abnormal texts while consolidating operator combines similar ones. Clustering experiment shows that reorganization process effectively improves the accuracy and recall rate and makes result more reasonable by increasing the inner density of clusters. text clustering; K-NN; Gauss weighing; nearest domain rule; cluster reorganization 劉作國(1987—),博士研究生,主要研究領域為中文信息處理。E-mail:412769371@qq.com陳笑蓉(1954—),教授,主要研究領域為中文信息處理。E-mail:xrchengz@163.com 1003-0077(2015)05-0112-05 2015-07-31 定稿日期: 2015-09-07 國家自然科學基金(61363028) TP391 A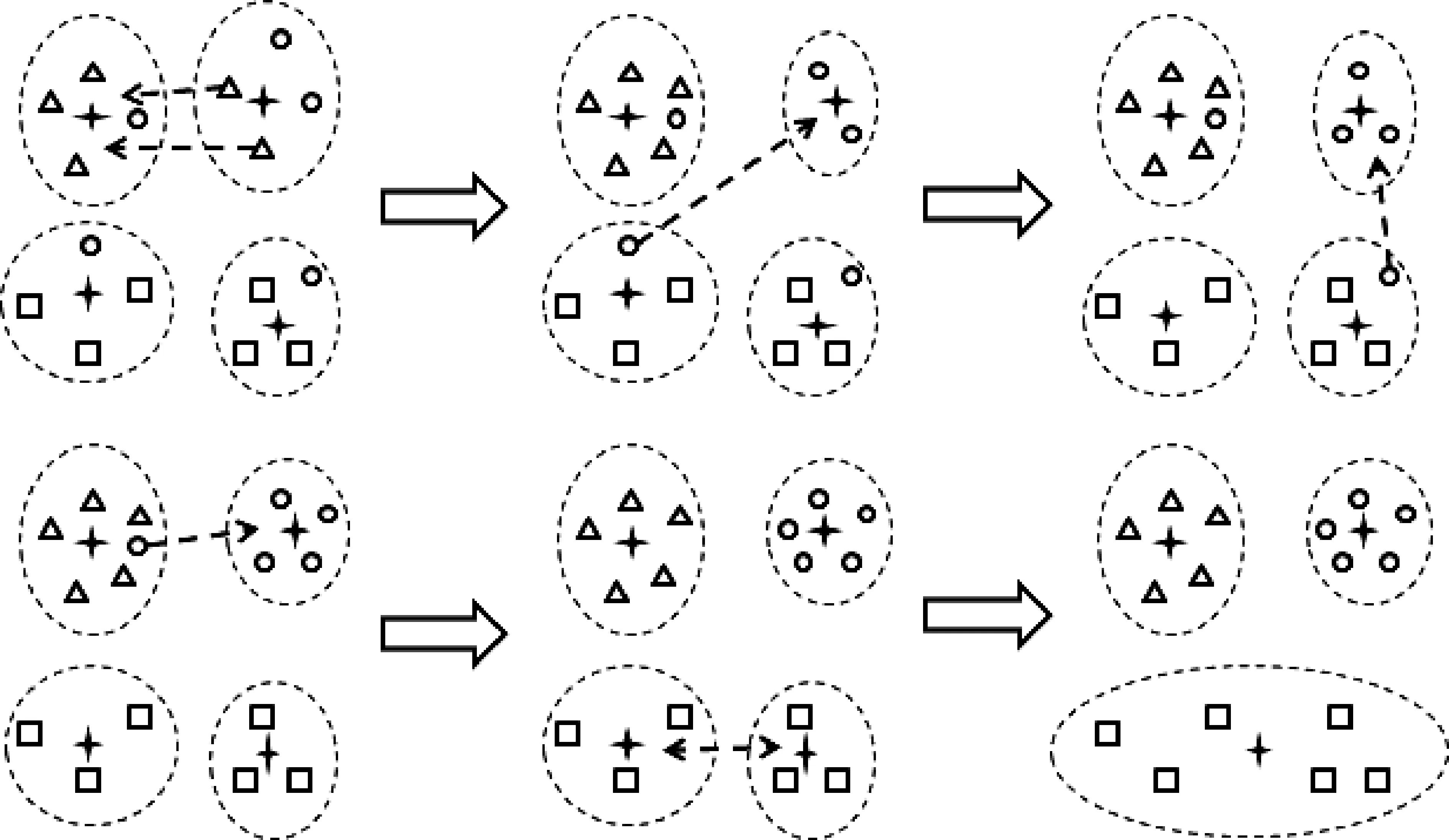
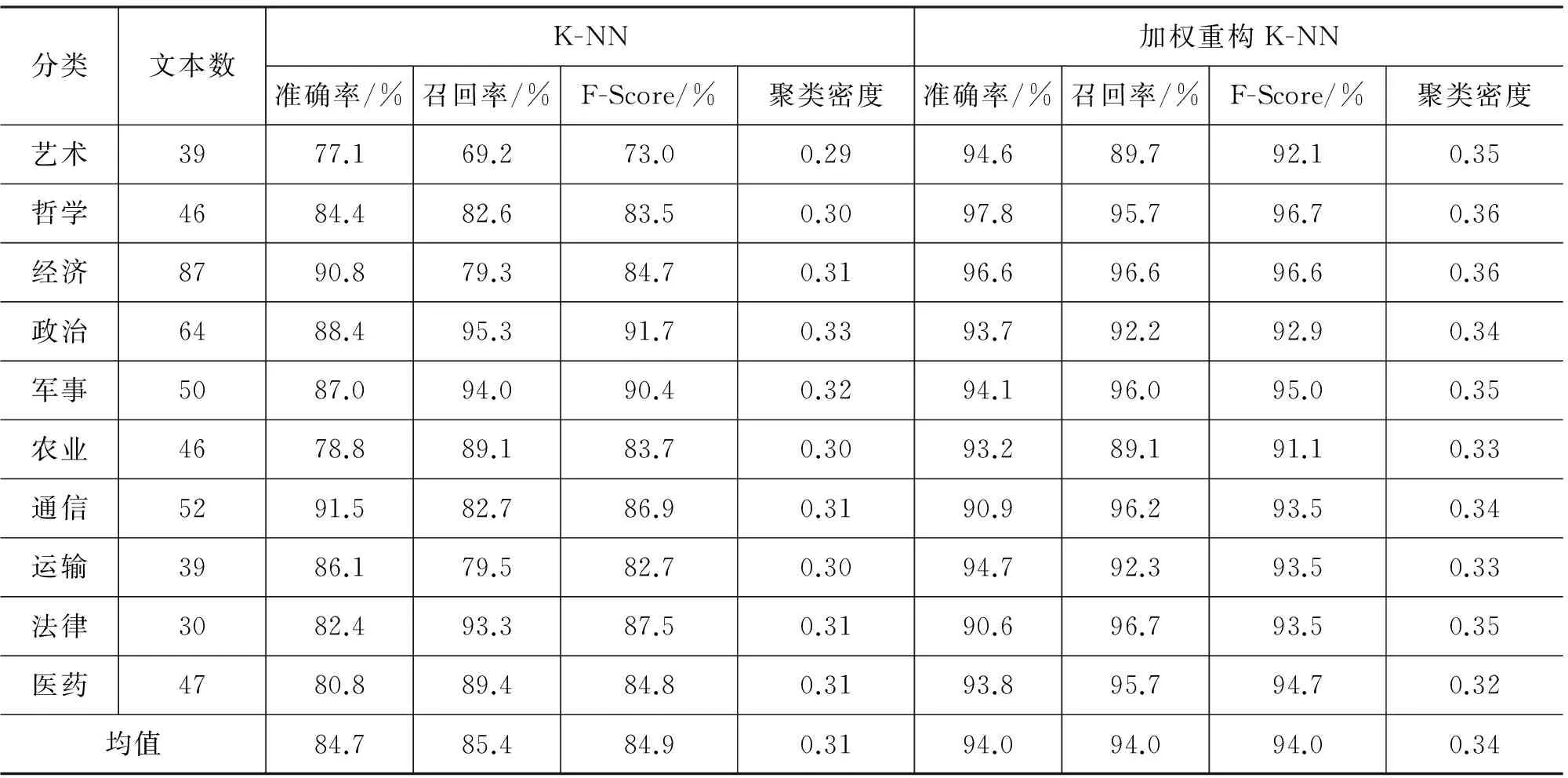
4 實驗分析

5 總結

猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
