基于模糊推理機的漢語主觀句識別
2015-04-21 10:51:58宋洪偉宋佳穎付國宏
中文信息學報 2015年5期
宋洪偉,宋佳穎,付國宏
(黑龍江大學 計算機科學技術學院,黑龍江 哈爾濱 150080)
?
基于模糊推理機的漢語主觀句識別
宋洪偉,宋佳穎,付國宏
(黑龍江大學 計算機科學技術學院,黑龍江 哈爾濱 150080)
該文提出一種基于詞匯模糊集合的模糊推理機以識別漢語主觀句。首先,根據主、客觀詞概念的模糊性,我們定義了兩個相應的模糊集合,并在模糊統計方法下,利用TF-IDF從訓練語料中獲取隸屬度函數。然后制定了兩個模糊IF-THEN規則,并據此實現了一個模糊推理機以識別漢語主觀句。NTCIR-6中文數據上的實驗結果表明我們的方法具有一定的可行性。
主觀句識別;模糊集合;模糊IF-THEN規則;模糊推理機
1 引言
隨著Web2.0技術的興起與迅猛發展,意見挖掘已經成為自然語言處理的一個研究熱點[1-2]。作為意見挖掘的一個重要子任務,主觀句識別的主要目的是從網絡用戶生成文本中將帶有主觀性信息的意見句從描述客觀事實的客觀句中識別出來。對于意見挖掘系統,主觀句識別能降低系統的復雜度并提高系統的性能,因此具有極其重要的意義。
雖然近年來主觀句識別的相關技術已經得到快速發展,但是對于面向大規模開放性網絡文本的意見挖掘系統來說,主觀句識別問題仍然沒有得到很好的解決。一方面,由于意見挖掘的相關研究工作仍處于早期階段,所以沒有足夠的標注語料用于主觀句識別模型的訓練;另一方面,現階段的研究工作大部分都在概率統計的框架下看待和解決主觀句識別問題,很少有人在模糊集合論的框架下,探索漢語主、客觀性表示模糊界限的本質特性。因此,如果能發現主觀性文本的本質特征并據此提出一種簡潔的模型,對于主觀句識別工作甚至是意見挖掘領域的其他工作都具有重大的意義。
針對以上問題,本文在模糊集合論框架下,提出一種基于詞匯模糊集合的模糊推理機來識別漢語主觀句。首先,為了更好地識別出漢語主、客觀性表示的模糊界限,我們定義了詞匯的主、客觀詞匯模糊集合,并在模糊統計方法下,利用TF-IDF公式計算不同詞匯分別對主、客觀詞匯模糊集合的隸屬度。然后,本文制定了兩條模糊IF-THEN規則,并用模糊推理的方法對其進行解析,以得到句子主、客觀性的置信度。最后,使用重心解模糊法對得到的置信度進行解模糊操作,并利用制定的判別規則得到句子的主客觀類別。
本文接下來的安排如下: 第二節簡要介紹了相關工作及背景。第三節描述我們方法的具體細節。第四節給出了在NTCIR-6[3]中文數據上的實驗結果。最后,第五節給出了本文工作的結論以及未來研究的展望。
2 相關研究
為了完成主觀句識別任務,現階段的研究工作大部分采用基于統計的機器學習方法來訓練分類器。為了從描述性客觀文本中分離出主觀句,Yu和Hatzivassiloglou[4]提出了三個不同的方法,分別叫做基于句子相似度的方法、融合多特征的樸素貝葉斯分類器和多重樸素貝葉斯分類器。其實驗結果顯示多特征和多重分類器的融合對主觀性識別有很大的幫助。與Yu和Hatzivassiloglou不同,Pang和Lee[5]將文檔級別文本和句子級別文本的主觀性識別任務統一起來,并形式化地將它們看作為一個面向圖的最小切割的問題,由此他們實現了一個基于最小切割的主客觀分類器。他們認為通過此方法,不論是傳統的主觀詞線索還是文檔內的上下文信息都能被融合起來完成主觀性識別任務。蒙新泛和王厚峰[6]則研究了基于不同機器學習模型的分類器在利用上下文信息時對漢語主觀句識別的影響,他們的實驗表明在使用上下文信息的簡單特征時,基于條件隨機場模型的分類器就已經能夠獲得比基于支持向量機模型和最大熵模型的分類器更好的效果。近年來,為了解決標注語料稀疏問題,人們開始探索如何使用更加復雜的弱監督機器學習方法。Lin等人[7]提出了一個叫做subjLDA的基于隱含狄利克雷分布的層次貝葉斯模型。與需要大規模標注語料為指導的傳統分類方法不同,他們采用弱監督的生成模型學習方法,這種方法只需要少量領域相關的主觀性線索詞。最近,Jiang[8]則提出了一種融合多主題信息的基于隱含狄利克雷分布的弱監督機器學習模型,他的方法能夠同時考慮多個主題對主觀句識別任務的影響。
主觀句識別任務的另一個關鍵問題是如何發現高質量的主觀性線索。主觀性特征詞作為主觀性線索的最小單位,最先被相關研究工作探索用來完成主觀句識別的任務。首先引起人們注意的主觀性特征詞是形容詞。Hatzivassiloglou和Wiebe[9]在一個簡單的分類器中全面地研究了形容詞的特性,包括形容詞的動態極性、語義傾向及其等級對主觀性識別的影響,其結果表明形容詞對主觀性文本具有很強的指示作用。除了形容詞,Riloff等人[10]還研究了主觀性名詞對主觀句識別任務的影響。他們的研究表明,主觀性名詞雖然十分重要,但是在實際應用中很少被使用。除此之外,Wiebe和Mihalcea[11]的研究表明詞語的詞義與主觀性的關聯非常緊密。為了突破以單個詞作為線索面臨的性能上的瓶頸,一些研究工作開始嘗試探索N元模型在主觀性識別中的作用。葉強等人[12]探索基于2-POS模型的連續雙詞詞類組合模式方法自動判別主觀句。隨后,Wilson和Raaijmakers[13]比較了分別用基于字的N元語法、詞的N元語法和音素的N元語法所訓練的主觀性分類器的表現。除了細粒度的詞匯級別線索,隨后的研究工作進一步地考慮了其他粗粒度的主觀性線索,比如在主觀句識別任務中考慮序列模式[14]。為了自動獲得大規模的序列模式,Jindal和Liu[15]則研究利用序列模式挖掘算法從語料中自動地提取基于類別的序列模式,進而用這些序列模式完成面向產品評論的主觀性比較句識別任務。此外,Karamibekr和Ghorbani[16]以主觀性動詞為關鍵詞,手工建立了一系列啟發式規則,進而從社會焦點評論文本中匹配出能代表主觀句的主觀性三元組,并以此識別主觀句。
在本文中,我們處理漢語句子級別的主觀性分類問題。與現存的主觀性識別系統相比較,我們從模糊集合論的角度出發,提出了一種新的基于詞匯模糊集合的模糊推理機來識別漢語主觀句,初步的實驗結果表明我們的方法能夠更準確地識別出主客觀句之間的細微差別。
3 主觀句識別方法
在本節中,我們會詳細介紹我們提出的漢語主觀句識別方法,包括詞匯模糊集合定義及其隸屬度函數的構造方法、模糊IF-THEN規則和模糊推理機。
3.1 詞匯模糊集合
由于自然語言本身的模糊性,詞匯的主、客觀性之間并沒有明確的劃分,這直接導致句子在主、客觀性之間的模糊性。因此,本文研究利用主、客觀詞匯模糊集合描述詞匯在主客觀性之間的細微差別,進而完成漢語句子的主觀性識別工作。主、客觀詞匯模糊集合定義如下。
定義1 主觀詞匯模糊集合: 設論域X為所有詞匯的集合,則論域X上的主觀詞匯模糊集合SUB是X到 [0,1]的一個映射:
(1)
對于x∈X,μSUB稱為主觀詞匯模糊集合SUB的隸屬度函數,μSUB(x)稱為x屬于主觀詞匯模糊集合SUB的隸屬度。
定義2 客觀詞匯模糊集合: 設論域X為所有詞匯的集合,則論域X上的客觀詞匯模糊集合OBJ是X到 [0,1]的一個映射:
(2)
對于x∈X,μOBJ稱為客觀詞匯模糊集合OBJ的隸屬度函數,μOBJ(x)稱為x屬于客觀性詞匯模糊集合OBJ的隸屬度。
由定義可知,隸屬度函數是描述模糊集合的重要組成部分,如何合理構建隸屬度函數是有效應用模糊集合的關鍵。
3.2 隸屬度函數
目前,構建隸屬度函數最常見的方法有模糊統計法、參考函數法等[17]。為了避免參考函數法等方法受個人主觀影響過大的缺點,本文使用模糊統計法計算每個詞匯分別屬于主/客觀詞匯模糊集合的隸屬度。
模糊統計法是一種客觀方法: 通過N次重復獨立統計實驗來確定所有特征詞中的某個特征詞對主、客觀詞匯模糊集合的隸屬度。在本文中,每次模糊統計實驗主要包含以下四個要素: (1)所有特征詞構成的論域X;(2)X中的一個固定特征詞x;(3)X中一個隨機變動的主/客觀詞匯集合A*(普通集合);(4)X中一個以A*作為彈性疆域的主/客觀詞匯模糊集合A,A制約著A*的變動范圍。
雖然模糊統計法在形式上類似于概率統計法,并且二者均是用確定性手段研究事物的不確定性。但是,模糊統計法與概率統計法分別屬于兩種不同的數學模型,它們有著本質區別。直觀地說,概率統計方法可以理解為考察“變動的點”是否落在“不動的圈內”,而模糊統計方法則可理解為考察“變動的圈”是否覆蓋住“不動的點”。
本文在模糊統計方法下利用TF-IDF公式構建隸屬度函數。TF-IDF公式形式簡潔、實現便捷,并且相對于其他復雜的統計量,在標注語料稀疏的情況下性能更穩定,因此被廣泛用于構建隸屬度函數。首先,我們根據訓練語料構建出一個特征詞的頻率矩陣,如式(3)所示。
(3)
其中,aij是第i個特征詞出現在第j類句子中的次數,aij指示出第i個特征詞與第j類句子的關聯度。M為訓練語料中的特征詞個數,本文選取詞頻數超過三次的詞作為特征詞。N為訓練語料中句子的類別數,在本文的主觀句識別任務中N取2,即1代表主觀句、2代表客觀句。
接著,為了平衡每個特征詞出現在主觀句與客觀句中的分布,我們利用式(4)對頻率矩陣中的每個詞向量進行歸一化處理,歸一化的值用bij表示。
(4)
接著,我們計算了每個特征詞的逆文檔頻率值,如式(5)所示。
(5)
其中|D|代表訓練語料中的所有句子數目,|Sij|代表包含第i個特征詞的第j類句子的數目。
然后,我們將式(4)與式(5)用乘積進行組合,以進一步表示第i個特征詞與第j類句子的關聯度。此時得到的值用cij表示,如式(6)所示。
(6)
最后,為了滿足主、客觀詞匯模糊集合定義中對隸屬度的約束條件,我們對關聯度cij進行歸一化處理,最終得到特征詞xi對主、客觀性詞匯模糊集合Aj的隸屬度μAj(xi)。
(7)
至此,我們定義了主/客觀詞匯模糊集合來描述主/客觀詞匯這兩個模糊概念,并用模糊統計方法得到相應的隸屬度函數。接下來,我們以上述內容為基礎,在模糊推理框架下,制定和解析本文所采用的模糊IF-THEN規則。
3.3 模糊TF-THEN規則
基于模糊IF-THEN規則的分類模型是一種較為常見的分類方法,模糊IF-THEN規則被廣泛地認為是分類知識較好的表示[18]。模糊IF-THEN規則可通過兩種方法產生: 自動產生方法和人工編寫方法。當應用于比較復雜的系統中,基于自動產生模糊IF-THEN規則的方法的模糊分類系統從數據中產生規則,這樣會面臨大量的模糊IF-THEN規則,獲取和優化模糊IF-THEN規則并不是一個很容易的任務。本文為了系統的簡潔和高效,結合漢語表達的特點,選擇采用人工制定的方法編寫如下兩條多維復合模糊IF-THEN規則。
RSUB:IFx1IS主觀詞匯or…orxnIS主觀詞匯,THENsIS主觀句
ROBJ:IFx1IS客觀詞匯or…orxnIS客觀詞匯,THENsIS客觀句
其中,特征詞xi是從訓練語料中抽取得到的,n為句子s所包含的特征詞的數目。本文所討論的模糊IF-THEN規則是一種復合模糊命題,而復合模糊命題的真值可由它所包含的原子模糊命題的真值確定。
當模糊命題P∈U的形式為“P:xISA”時,我們稱P為原子模糊命題[18]。其中,x是變量,A是某個模糊概念對應的模糊集合。當一個模糊命題P是原子模糊命題時,其真值取為變量x對模糊集合A的隸屬度μA(x),即式(8)所示。
(8)
至此,本文制定了具有良好可讀性和解析性的模糊IF-THEN規則。接下來,我們介紹如何利用模糊推理機對模糊IF-THEN規則進行解析。
3.4 模糊推理機
經典的推理模型本質上是一個精確的數學模型。它不僅要求規則是明確的,同時輸入必須是與規則的前件相同,才能得到與后件相同的結論。當推理是從一個或幾個模糊的前提推導出一個模糊的結論時,推理就成為了模糊推理,需要基于模糊數學的理論和方法來演算和處理。
針對漢語主觀句識別任務,我們基于模糊數學的理論設計并實現了一個對上文提出的模糊IF-THEN規則進行解析的系統,本文稱之為模糊推理機。模糊推理機主要有三個模塊: 輸入模糊化模塊、模糊推理模塊和解模糊化模塊。
(1) 輸入模糊化模塊
模糊推理機的第一個階段是對給定輸入句子進行模糊化操作,即選擇主觀句識別系統的輸入變量,并根據輸入變量的隸屬度函數來恰當地確定這些變量所隸屬的模糊集合[17]。輸入模糊化模塊的具體步驟如下:
1. 首先利用查詞典的方法,在輸入句子S中找出在文檔頻率矩陣中出現過的特征詞。
2. 然后,利用最大隸屬度原則來確定特征詞所隸屬的模糊集合,如公式(9)、(10)所示。
(9)
(10)
其中,μk(x)代表特征詞x所具有的最大隸屬度,k代表最大隸屬度對應的模糊集合。

(2) 模糊推理模塊
通常,模糊IF-THEN規則的前件部分具有多個輸入,這時需要運用模糊算子對這些多輸入進行推理,以得到一個確定數值來表示對規則后件部分的置信度。由于模糊算子是由邏輯連接詞決定的,因此我們先給出本文采用的“邏輯或”基本邏輯連接詞的定義。
定義3 設U為模糊IF-THEN規則的集合,P,Q∈U。則P與Q的邏輯連接詞“邏輯或”對應模糊集合的并運算,其真值為式(11)所示。
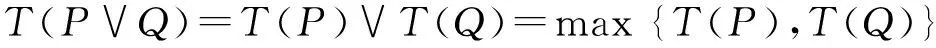
(11)
顯然,“邏輯或”連接詞的真值與模糊集合的并運算結果是等價的。而由于模糊集合的特性,模糊集合的并運算實質上就是簡單的max算子,這使得基于模糊集合的應用系統計算方便、可靠。但是因為客觀世界現象錯綜復雜,簡單的max算子已經無法適應客觀世界現象賦予“邏輯或”的所有涵義。因此需要我們根據不同的任務背景,尋找合理的模糊算子以建立適合的模糊推理模型。
針對漢語主觀句識別任務,本文模仿人腦進行模糊推理過程的特點,選擇模糊集合廣義并運算中的max算子與代數和算子。這兩種模糊算子可以從不同角度解析我們的模糊IF-THEN規則。

(12)
具體地,在當前句子S中,當模糊運算符At取上述模糊算子時,對應的形式分別為:
1. 當At為max算子時,
(13)
2. 當At為代數和操作時,
(14)
至此,在模糊推理框架下,我們得到了模糊IF-THEN規則的輸出值。下面,我們將介紹如何對模糊IF-THEN規則的輸出值進行解模糊化。
(3) 解模糊化模塊
由于經過模糊推理后得到的是句子S對所有模糊IF-THEN規則Rk的置信度,因此必須進行解模糊化,將輸出變為一個確定的值。常用的解模糊化方法有: 重心解模糊法、最大隸屬度法[17]等。本文采用重心解模糊法進行解模糊化操作,其形式如公式(15)[19]所示。
(15)
其中,yk是調節參數,本文通過隨機梯度下降法計算其最優值。
首先,我們在最小偏差模型下,使用如下目標函數:
(16)
然后,對其進行求偏導得到梯度函數:

(17)
最后,使用如下公式迭代地求解yk:
(18)
其中,p為當前的迭代次數,η為學習速率。
最終,式(15)中的Y被映射到[iOBJ-Δ,iSUB+Δ]。在本文中,iOBJ取值為0,iSUB取值1。Δ為系統自身的誤差。為了得到識別結果,本文使用如下判別策略:


其中,Δ1為調節參數,Δ1的值影響系統的健壯性。為了盡可能地提高本文系統的魯棒性,我們設定Δ1取值為0.5。
至此,我們已經全面介紹了本文使用的模糊推理機的理論基礎和實現細節。模糊推理機的執行過程是本文漢語主觀句識別系統的核心部分,下面給出了模糊推理機的具體算法流程。

算法:基于模糊推理機的漢語主觀句識別算法Input:句子sOutput:句子s的主客觀類別:主觀性或者客觀性1:預處理:分詞,詞性標注;2:SD(S)=03:for對s中的每個詞語w4: ifw是特征詞,then5: 通過公式(9)計算μk(w),并加入到集合ASk,k∈{SUB,OBJ}中6: endif7:endfor8:通過模糊運算公式(10)計算句子s分別對主觀句及客觀句的置信度。9:通過公式(11)計算句子s的模糊輸出值Y。10:ifY∈iOBJ-Δ1,iOBJ+Δ1[],then11: s被識別為客觀句12:elseifY∈iSUB-Δ1,iSUB+Δ1[],then13: s被識別為主觀句14:endif
4 實驗結果與分析
4.1 實驗數據及測評方法
為了驗證上述方法的有效性,我們采用 NTCIR-6[3]中文訓練和測試數據,表1給出了數據的基本統計信息。為了評價系統的性能,本文采用 NTCIR-6的LWK-Lenient評價標準給出的精確率(Precision)、 召 回 率(Recall)和F-值(F-score)三個評價指標。
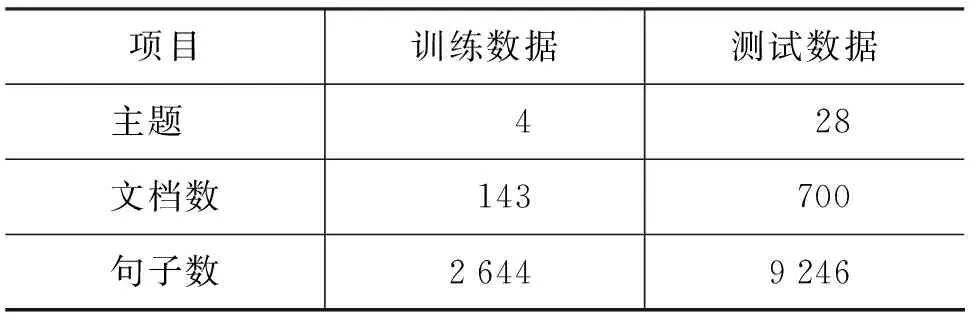
表1 實驗數據的統計信息
4.2 實驗結果與分析
本文第一組對比實驗的目的是驗證基于模糊統計TF-IDF方法的詞匯模糊集合對主觀句識別的有效性,表2是實驗的結果。

表2 不同特征表示法的主觀句識別結果
在本組實驗中,所使用的分類器均為基于代數和算子及重心解模糊器的模糊推理機。不同的是,詞頻統計TF-IDF方法使用傳統的概率統計方法計算每個特征詞的權重;而模糊統計TF-IDF方法則使用本文所提出的模糊統計方法來計算每個特征詞的隸屬度。表2所示的實驗結果顯示,在某種程度上,基于模糊統計的詞匯模糊集合表示法能夠更好地利用模糊推理機來區分漢語句子的主客觀性之間的區別。我們分析認為,由于本文系統的出發點是希望先盡可能地區分出特征詞在主客觀性之間的區別,進而更準確地實現句子在主客觀性之間的比較。而概率統計TF-IDF方法考察的是在某特定類別下所有特征詞的分布情況;模糊統計TF-IDF方法考察的則是某特定特征詞在主客觀類別中的分布情況,二者之間的側重點不同。實驗結果也證明了詞匯模糊集合在區分主客觀的細微差別時的有效性。
為了進一步研究模糊推理機對主觀性識別的有效性,本文的第二組實驗對比驗證了不同模糊算子對模糊推理機的影響,表3是實驗的結果。
在本組實驗中,我們采用本文提出的模糊推理機來實現主觀性識別工作。為了研究不同模糊算子對模糊推理機的影響,本組實驗在模糊推理階段分別采用max算子及代數和算子實現“邏輯或”操作。實驗結果顯示,基于代數和算子的廣義模糊并運算要明顯好于基于max算子的模糊并運算,整體F-值提高了2.7%。我們分析認為,在基于模糊推理的主觀句識別任務中,當執行“邏輯或”推理時,max算子利用當前句子中隸屬于主/客觀詞匯集合程度最大的特征詞來代表句子從屬于主/客觀句的程度。這種明顯的偏置性,忽視了當前句子中的其他主/客觀詞匯。代數和算子則通過累加操作保留了當前句子中的所有主/客觀詞匯的特征,在一定程度上改善了max算子對高隸屬度特征的偏置現象。因此代數和算子能夠更好地利用模糊推理機描述漢語句子在主客觀性之間的不同。

表3 不同模糊算子的主觀句識別結果
為了驗證模糊推理機結合模糊集合分類模型相比于其他常用分類模型的優勢,我們考察了不同分類器對模糊集合的影響。結果如表4所示。

表4 不同分類方法的主觀句識別結果
在本組實驗中,為了驗證模糊推理機結合模糊集合對主觀性識別的有效性,我們以詞匯模糊集合為基礎,研究不同類型的分類器對模糊集合的影響。實驗結果顯示,模糊推理機與模糊集合的組合要明顯好于基于模糊集合的樸素貝葉斯分類器和支持向量機,這在一定程度上說明,相比于樸素貝葉斯分類器和支持向量機,模糊推理機能夠更好地利用模糊集合來區分漢語句子的主客觀性之間的區別。我們分析認為,相比于樸素貝葉斯和模糊推理機,支持向量機模型更加復雜,且性能容易受語料稀疏性的制約。此外,雖然樸素貝葉斯分類器與模糊推理機在形式上非常相似,但是兩者屬于不同的模型: 樸素貝葉斯模型屬于生成模型,而模糊推理機是一種邏輯推理模型。由此可以看出,模糊推理機能夠更好地利用模糊集合來區分漢語句子的主客觀性之間的區別,實驗結果也驗證了模糊推理機的有效性。
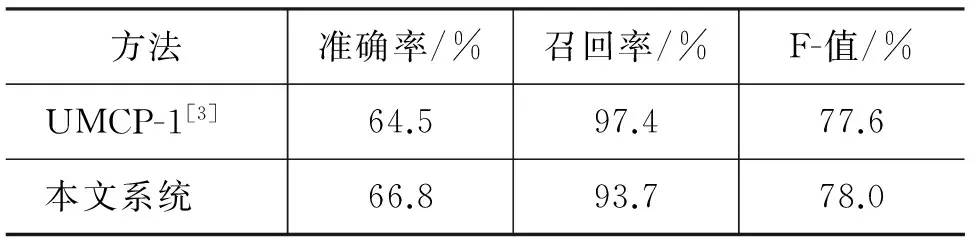
表5 本文系統與NTCIR-6最好系統的比較
表5比較了本文系統的最好結果和NTCIR-6中最好系統的結果。在UMCP-1[3]系統中,他們首先采用自動獲取與人工校對相結合的方法來構建情感詞典,然后利用給定句子中的情感詞數量來判斷該句是否為主觀句。
實驗結果顯示,本文系統的最好結果較UMCP-1[3]系統的F-值提高了0.4%。這在一定程度上說明,在模糊數學理論基礎之上,將模糊集合與模糊推理方法有機融合具有可行性。但是在召回率方面有所下降,我們分析可能是由于訓練語料稀疏使得某些特征詞的隸屬度估計不準確。而與UMCP-1[3]系統相比,本文的系統可以自動地識別主觀句,而無需通過手工校對的方式對情感詞典進行人工維護。因此本文系統的適用性更大,能夠更好地處理大規模開放性網絡文本中各式各樣的主觀句。
5 結論與展望
本文提出了一種基于模糊推理機的漢語主/客觀句分類系統,并采用NTCIR-6數據對系統進行了測試。實驗表明我們的方法有一定的可行性,這在一定程度上說明: 在模糊集合框架下,將模糊集合與模糊推理方法融合能夠很好地區分主客觀句子在概念外沿上的細微區別。雖然在所進行的實驗中,我們系統的準確率和F-值達到最高,但召回率略低。我們分析可能是由于訓練語料太小,這使得某些特征詞的隸屬度估計不準確;同時重心解模糊法的參數也得不到精確的計算。因此,在將來的工作中我們將研究如何提高特征詞的質量,并進一步擴大訓練語料庫。
[1] Liu B. Sentiment analysis and subjectivity[J]. Handbook of natural language processing, 2010, 2: 627-666.
[2] Pang B, Lee L. Opinion mining and sentiment analysis[J]. Foundations and trends in information retrieval, 2008, 2(1-2): 1-135.
[3] Seki Y, Evans D, Ku L, et al. Overview of opinion analysis pilot task at NTCIR-6[C]//Proceedings of NTCIR-6 Workshop Meeting. 2007: 265-278.
[4] Hong Y, Hatzivassiloglou V. Towards answering opinion questions: Separating facts from opinions and identifying the polarity of opinion sentences[C]//Proceedings of EMNLP’03, 2003: 129-136.
[5] Pang B, Lee. A sentimental education: Sentiment
analysis using subjectivity summarization based on minimum cuts[C]//Proceedings of ACL’04, 2004: 271-278.
[6] 蒙新泛, 王厚峰. 主客觀識別中的上下文因素的研究[J]. 中國計算機語言學研究前沿進展 (2007-2009), 2009: 594-599.
[7] Lin C, He Y, Everson R. Sentence Subjectivity Detection with Weakly-Supervised Learning[C]// Proceedings of IJCNLP. 2011: 1153-1161.
[8] Jiang W. Study on Identification of Subjective Sentences in Product Reviews Based on Weekly Supervised Topic Model[J]. Journal of Software, 2014, 9(7): 1952-1959.
[9] Hatzivassiloglou V,Wiebe J. Effects of adjective orientation and gradability on sentence subjectivity[C]//Proceedings of ACL’00, 2000: 299-305.
[10] Riloff E, Wiebe J, Wilson T. Learning subjective nouns using extraction pattern bootstrapping[C]//Proceedings of HLT-NAACL’03, 2003: 25-32.
[11] Wiebe J, Mihalcea R. Word sense and subjectivity[C]//Proceedings of COLING-ACL’06, 2006: 1065-1072.
[12] 葉強, 張紫瓊, 羅振雄. 面向互聯網評論情感分析的中文主觀性自動判別方法研究[J]. 系統信息學報, 2007,1(1): 79-91.
[13] Wilson T, Raaijmakers S. Comparing word, character, and phoneme n-grams for subjective utterance recognition[C]// Proceedings of INTERSPEECH. 2008: 1614-1617.
[14] Riloff E, Wiebe J, Phillips W. Exploiting subjectivity classification to improve information extraction[C]//Proceedings of AAAI’05, 2005: 1106-1111.
[15] Jindal N, Liu B. Identifying comparative sentences in text documents[C]//Proceedings of SIGIR’06, 2006: 244-251.
[16] Karamibekr M, Ghorbani A. Sentence subjectivity analysis in social domains[C]//Proceedings of the 2013 IEEE /ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technologies, 2013: 268-275.
[17] 張小紅, 裴道武, 代建華. 模糊數學與 Rough 集理論[M]. 北京: 清華大學出版社, 2013.
[18] 陽愛民. 模糊分類模型及其集成方法[M]. 北京: 科學出版社, 2008.
[19] Rustamov S. Application of Neuro-Fuzzy Model for Text and Speech Understanding Systems[C]//Proceedings of PCI’12, 2012: 1-4.
Chinese Subjective Sentence Recognition Based on Fuzzy Inference Machine
SONG Hongwei, SONG Jiaying, FU Guohong
(School of Computer Science and Technology, Heilongjiang University, Harbin, Heilongjiang 150080, China)
This paper presents a fuzzy inference machine for Chinese subjectivity identification. We first define two fuzzy sets for lexical subjectivity and objectivity, respectively. Then, we apply TF-IDF to acquire the relevant membership functions from the training data. Finally, we define two fuzzy IF-THEN rules and thus build a fuzzy inference machine for Chinese subjective sentence recognition. We conduct two experiments on the NTCIR-6 Chinese opinion data. The experimental results demonstrate the feasibility of the proposed method.
subjectivity recognition; fuzzy sets; fuzzy IF-THEN rules; fuzzy inference machine

宋洪偉(1989—),碩士研究生,主要研究領域為自然語言處理。E-mail:songhongwei@live.cn宋佳穎(1990—),碩士研究生,主要研究領域為自然語言處理、情感分析。E-mail:jy_song@outlook.com付國宏(1968—),教授,主要研究領域為自然語言處理、文本挖掘。E-mail:ghfu@hotmail.com
1003-0077(2015)05-0160-07
2015-07-30 定稿日期: 2015-09-20
國家自然科學基金(60973081, 61170148);黑龍江省人力資源和社會保障廳留學人員科技活動項目
TP391
A
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
兒童故事畫報(2019年5期)2019-05-26 14:26:14
山東醫藥(2017年35期)2017-10-10 02:45:28
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中華胰腺病雜志(2013年3期)2013-10-19 03:16:56
