基于卡方距離度量的改進KNN算法
2015-05-15 03:14:36謝紅趙洪野
應用科技 2015年1期
關鍵詞:分類
謝紅,趙洪野
哈爾濱工程大學信息與通信工程學院,黑龍江哈爾濱 150001
基于卡方距離度量的改進KNN算法
謝紅,趙洪野
哈爾濱工程大學信息與通信工程學院,黑龍江哈爾濱 150001
K-近鄰算法(K-nearestneighbor,KNN)是一種思路簡單、易于掌握、分類效果顯著的算法。決定K-近鄰算法分類效果關鍵因素之一就是距離的度量,歐氏距離經常作為K-近鄰算法中度量函數,歐式距離將樣本的不同特征量賦予相同的權重,但是不同特征量對分類結果準確性影響是不同的。采用更能體現特征量之間相對關系的卡方距離度量作為KNN算法的度量函數,并且采用靈敏度法進行特征權重計算,克服歐氏距離的不足。分類實驗結果顯示,基于卡方距離的改進算法的各項評價指標優于傳統的KNN算法。
K-近鄰算法;卡方距離;距離度量;二次式距離;歐式距離;靈敏度法
可用于分類的方法有:決策樹、遺傳算法、神經網絡、樸素貝葉斯、支持向量機、基于投票的方法、KNN分類、最大熵[1]等。K-近鄰分類算法[2](K-nearest neighbor,KNN)是Covert和Hart于1968年首次提出并應用于文本分類的非參數的分類算法。KNN算法的思路清晰,容易掌握和實現,省去了創建復雜模型的過程,只需要訓練樣本集和測試樣本集,而當新樣本加入到樣本集時不需要重新訓練。雖然KNN算法有著諸多優點,但也存在著以下不足。首先,分類速度慢、計算復雜度高,需要計算測試樣本與所有的訓練樣本的距離來確定k個近鄰;其次,特征權重對分類精度的影響較大。針對上述缺點,一些學者提出相應的改進方法。為了提高分類速度,降低計算復雜度,Juan L[3]建立了一個有效的搜索樹TKNN,提高了K-近鄰的搜索速度,彭凱等[4]提出基于余弦距離度量學習的偽K近鄰文本分類算法,Lim等[5]用向量夾角的余弦引入權重系數,桑應賓[6]提出一種基于特征加權的K Nearest Neighbor算法,來提高分類準確率。文獻[7-8]對輸入的樣本進行簡單的線性變換映射到新的向量空間,在新的向量空間對樣本進行分類,可以有效提高分類性能。本文主要是對距離度量函數進行改進,用卡方距離度量函數替換歐氏距離度量函數,并在新的度量函數下計算特征量的權重系數,來提高分類的準確率。
1 KNN算法
KNN作為一種基于實例的分類算法,被認為是向量模型下最好的分類算法之一[9]。KNN算法從測試樣本點y開始生長,不斷的擴大區域,直到包含進k個訓練樣本點為止,并把測試樣本點y的類別歸為這最近的k個訓練樣本點出現頻率最大的類別。KNN算法的主要操作過程如下:
1)建立測試樣本集和訓練樣本集。訓練樣本集表示為

4)選擇k個近鄰訓練樣本。對于測試樣本點y按照式(1)找到在訓練樣本集中離測試樣本點y最近的k個訓練樣本點。
5)測試樣本y類別的判別規則。即對步驟4)中得到的k個近鄰訓練樣本點進行統計,計算k個訓練樣本點每個類別所占的個數,把測試樣本的類別歸為所占個數最多的訓練樣本所屬的類別。
2 卡方距離度量
選擇不同的距離計算方式會對KNN算法的分類準確率產生直接的影響,傳統的KNN算法使用歐氏距離作為距離的度量,歐氏距離的度量方式只考慮各個特征量絕對距離,往往忽視各特征量的相對距離。分類中相對距離更加具有實際意義,卡方距離能有效反應各特征量的相對距離變化,同時根據每個特征量對分類貢獻的不同,結合靈敏度法計算卡方距離下的特征量的權重。
2.1 卡方距離模型
卡方距離是根據卡方統計量得出的,卡方距離已經被應用到很多的距離描述問題,并且取得相當好的效果。卡方距離公式為

2.2 卡方距離與二次卡方距離的關系
2個直方圖統計量X、Y是非負值而且有界限的,則2個直方圖距離的二次式距離公式為

如果矩陣A是協方差矩陣的逆,該二次式距離就是馬氏距離。如A是單位矩陣,二次式距離就是歐氏距離。QC代表二次卡方距離。而二次卡方距離[10]公式為

實際上二次卡方距離是二次式距離的標準形式,當m=0.5,W是單位矩陣時,此時的QC距離是卡方距離,其形式為
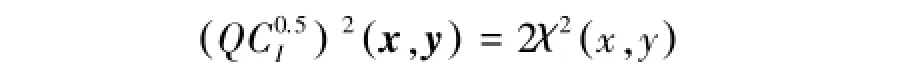
當m=0,二次卡方距離就是二次式距離。由此可見卡方距離和歐氏距離、馬氏距離一樣可以對特征向量進行有效的度量。
2.3 權重調整系數的計算方法
卡方距離體現了特征量之間的相對關系,但是仍然對每個特征量賦予相同的權重,實際情況是不同特征對分類的貢獻不同,因此,本文在卡方距離的基礎上采用靈敏度法對不同的特征賦予不同的權重。特征權重的計算方法如下:
1)用卡方距離代替歐氏距離對測試樣本進行分類,統計分類錯誤的樣本個數n。
4)第q個特征量的權重系數定義為

3 基于卡方距離的改進KNN算法
本文在傳統的KNN的基礎上,采用卡方距離度量學習、應用靈敏度法計算不同特征的權重,應用新的距離度量函數代替歐式距離進行度量,得到基于卡方距離的KNN(CSKNN)算法。
3.1 CSKNN算法基本流程
算法流程圖如圖1所示,基本流程如下。
1)創建測試樣本集和訓練樣本集,訓練樣本集表示為X,測試樣本集表示為Y。
2)給k設定一個初值。
3)計算測試樣本點和每個訓練樣本點的加權卡方距離。公式如下所示:

4)在步驟3)所得的距離按照降序排列,選擇離測試樣本點較近的k個訓練樣本。
5)統計步驟4)中得到的k個近鄰訓練樣本點所屬的類別,把測試樣本的類別歸為k個訓練樣本點中出現次數最多的類別。
6)根據分類結果,評價其查全率R、查準率P、F1宏值以及分類精度,判斷分類效果是否達最好,若是,則結束;若否,返回步驟2)對k值進行調整。

圖1 算法流程圖
3.2 實驗結果及分析
實驗采用MATLAB R2010a軟件進行仿真,在Intel(R)Celeron(R)CPU 2.60GHz,2 GB內存,Windows 7系統的計算機上運行。采用3組數據集進行實驗來驗證算法分類的有效性,3組數據集來自用于機器學習的UCI數據庫,表1給出了3組數據集的基本信息。

表1 實驗用到的UCI數據集
對分類算法進行評價指標分為宏平均指標和微平均指標,宏平均指標體現的是對類平均情況的評價,微平均則更加注重對樣本平均情況的評價。為了對比本文算法和傳統KNN算法的性能,采用分類性能評價指標為宏平均查全率(R)、宏平均查準率(P )和F1測量值,同時分類精度(C)也是評價分類方法的重要指標。
查全率公式為

式中:A表示分類正確的樣本數,B表示測試樣本的總數。
在實驗中本文選擇數據集的1/3作為訓練樣本,數據集的2/3作為測試樣本。在k=5時,實驗結果如表2所示;在k=8時實驗結果如表3所示。

表2 k=5時3組UCI數據集實驗對比結果

表3 k=8時3組UCI數據集實驗對比結果
從表2中可以看出,當k=5時,在Iris數據集上,改進算法的查全率、查準率和F1值都增加約2%。在Haberman數據集上,改進算法的查全率增加了2.3%、但是在查準率和F1值上低于傳統的KNN算法。在Pima-India diabetes數據集上,相比于傳統算法查全率增加了4.3%,查準率增加了7.8%,F1值增加了8%。從表3的實驗對比結果容易得出,當k=8時,在Iris數據集上,改進算法的查全率增加了2.5%、查準率增加了3.1%、F1值增加了3.1%。在Haberman數據集上,改進算法的查全率上增加了9.2%、查準率和F1值分別增加了5.2%和5.9%。在Pima-India diabetes數據集上,相比于傳統算法,查全率增加了2.8%,查準率增加了4.7%,F1值增加了4.5%。
通過分析表2、3可知,當k=5時,除在Haber-man數據集上的查準率和F1值低于傳統KNN算法,在其他數據集上改進的KNN算法的各項指標均高于傳統的KNN算法。而當k=8時,改進的KNN算法的各項指標均明顯優于傳統的KNN算法
分類精度也是評價分類效果的重要指標,k的取值對分類精度的影響非常明顯,k的取值過小,從訓練樣本中得到信息相對較小,分類精度就會下降;但是k也不能過大,這是因為選擇了太多的近鄰樣本,對從訓練樣本中得到的分類信息造成大的干擾。因此在選取k值的時候,就不得不做出某種折中。
為了說明k值對分類精度造成的影響,本文選取k=3、5、8、10、12、15時,在3組UCI數據集上進行測試,得到分類精度隨k值變化曲線。Iris數據集的分類準確度隨k值得變化曲線如圖2所示。Haberman數據集的分類準確度隨k值得變化曲線如圖3所示。Pima-India diabetes數據集的分類準確度隨k值得變化曲線如圖4所示。
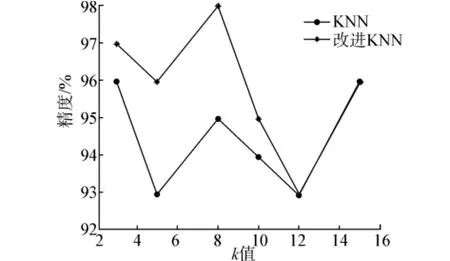
圖2 Iris數據集分類精度隨k值變化曲線

圖3 Haberman數據集分類精度隨k值變化曲線

圖4 Pima-India diabetes數據集分類精度隨k值變化曲線
分析圖2~4可知,分類精度隨著k值的不同而發生變化,改進的算法和傳統的算法在分類精度達到最大時的k值并不相同,對不同的數據集分類精度達到最大時k值也可能不相同,Haberman數據集上在k=3、5時改進的KNN算法分類精度低于傳統的KNN算法,在k取其他值時分類精度明顯高于傳統算法,在Iris和Pima-India diabetes數據集上分類精度明顯得到提高。
4 結束語
介紹了基于卡方距離的改進KNN算法,用特征權重調整系數的卡方距離代替歐氏距離作為距離度量,克服了歐氏距離對每個特征量賦予相同權重的缺點。通過MATLAB仿真分析驗證了改進算法在查全率、查準率、F1值以及分類精度上得到了提高,盡管k值沒有一個統一的確定方法,但是在相同k值的條件下,改進KNN算法的分類效果明顯高于傳統的KNN算法。
[1]奉國和.自動文本分類技術研究[J].情報雜志,2004,2(4):108-111.
[2]COVER TM,HARTP E.Nearest neighbor pattern classifi-cation[J].IEEE Transactions on Information Theory,1967,13(1):21-27.
[3]LI J.TKNN:an improved KNN algorithm based on tree structure[C]//Seventh International IEEE Conference on Computational Intelligence and Security.Sanya,China,2011:1390-1394.
[4]彭凱,汪偉,楊煜普.基于余弦距離度量學習的偽K近鄰文本分類算法[J].計算機工程與設計,2013,34(6):2200-2203.
[5]LIM H.An improve KNN learning based Korean text classifi-er with heuristic information[C]//The 9thInternational Conference on Neural Information Processing.Singapore,2002:731-735
[6]桑應賓.一種基于特征加權的K-Nearest-Neighbor算法[J].海南大學學報,2008,26(4):352-355.
[7]WEINBERGER K Q,SAUL L K.Distancemetric learning for large margin nearest neighbor classification[J].The Journal of Machine Learning Research,2009(10):207-244.
[8]KEDEM D,TYREE S,WEINBERGER K Q,et al.Non-lin-ear metric learning[C]//Neural Information Processing Systems Foundation.Lake Tahoe,USA,2012:2582-2590.
[9]蘇金樹,張博鋒,徐昕.基于機器學習的文本分類技術研究進展[J].軟件學報,2006,17(9):1848-1859.
[10]PELE O,WERMAN M.The quadratic-Chi histogram dis-tance family[C]//The 11thEuropean Conference on Com-puter Vision.Crete,Greece,2010:749-762.
An improved KNN algorithm based on Chi-square distancemeasure
XIE Hong,ZHAO Hongye
College of Information and Communication Engineering,Harbin Engineering University,Harbin 150001,China
The K-nearest neighbor(KNN)algorithm is one of the classification algorithms,and it isobvious in clas-sification effect,is simple and can be grasped easily.One of themost significant factorswhich determine the effect of the K-nearestneighbor classification is distancemeasure.Euclidean distance isusually considered as themeasure function of the K-nearest neighbor algorithm,it assigns the same weight to different characteristics of the samples,but different characteristic parameter has different influence on the accuracy of the classification results.This paper adopts Chi-square distance which canmore reflect the relative relationship between characteristics asmeasure func-tion of KNN algorithm and uses sensitivitymethod to compute the characteristic weight,so as to overcome the short-coming of Euclidean distance.The result of classification test shows evaluation indexes of the improved algorithm based on Chi-square distance are better than the traditional KNN algorithm.
K-nearestneighbor algorithm;Chi-square distance;distancemeasure;quadratic-form distance;Euclid-ean distance;sensitivitymethod
TP391.4
:A
:1009-671X(2015)01-010-05
10.3969/j.issn.1009-671X.201401002
http://www.cnki.net/kcms/detail/23.1191.U.20150112.1433.001.htm l
2014-01-06.
日期:2015-01-12.
黑龍江省自然科學基金資助項目(F201339).
趙洪野(1992-),男,碩士研究生;謝紅(1962-),女,教授,博士生導師.
謝紅,E-mail:xiehong@hrbeu.edu.cn.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
