
面向云存儲的非結構化數據存儲研究
2015-05-30 10:48:04王存宇等
計算機時代 2015年5期
王存宇等
摘 要: 云存儲是網格、并行和分布式計算等眾多技術發展和延伸,云存儲實現了存儲的完全虛擬化,提供更強大的存儲及共享功能[1]。非機構化數據包括文本、圖像、音頻、視頻、PDF、電子表格等。非結構化數據的存儲通常有兩種方式,一種是使用文件系統以文件的方式存儲,將文件的路徑或者鏈接存儲在關系型數據庫表中;另一種是將這些數據存儲在傳統的數據庫表的大對象字段中。文章主要研究非結構化數據的存儲方式,結合非結構化數據的特點,云存儲的優勢以及MongoDB的數據存儲特性,提出非結構化數據云存儲的必要性。
關鍵詞: 云存儲; 非結構化數據; MongoDB
中圖分類號:TP399 文獻標志碼:A 文章編號:1006-8228(2015)05-13-03
Abstract: Cloud storage is the development and extension of a number of technologies, such as grid, parallel and distributed computing. The storage virtualization has been completely realized to provide more powerful storage and sharing functions. Unstructured data is including text, image, audio, video, PDF, spreadsheet, etc. Typically, there are two ways to store unstructured data, the first way is to store it as a file, and store the path or the link to the file in the table of relational database, and the other way is to store it in the Blob field in table of traditional relational database. This paper mainly studies the ways to store unstructured data, combined with the characteristics of unstructured data, the advantages of cloud storage and the storage characteristics of MongoDB, proposes the necessity of storing unstructured data in cloud.
Key words: cloud storage; unstructureddata; MongoDB
0 引言
隨著社會信息化進程的不斷加快,網絡中的數據量變得龐大,原有的數據處理方式已經不能滿足現階段人們對于數據處理的高要求。所以云計算和云存儲在這種環境下應運而生,這加快了大規模數據的處理速度,增加了大規模數據的存儲量。而現階段由于數據結構化過于受限于人工處理,非結構化數據的增長速度遠遠大于結構化數據。所以對于非結構化數據的存儲研究將非常有意義。
1 分布式存儲技術介紹
1.1 什么是分布式存儲技術
分布式存儲系統是大量普通PC服務器通過Internet互聯,對外作為一個整體提供存儲服務。
1.2 分布式存儲系統中數據如何分布
分布式系統要解決的主要問題是數據分布。如何將數據均勻分布到多個存儲服務器節點中,這些分布的數據要保證可靠性和可用性,需要將數據復制到多個副本。我們要做的就是要保證多個副本之間的數據一致性。
一般來說,分布式存儲系統會保存多份數據在不同的服務器上,當其中一份數據在服務器上發生故障時,能通過其他的副本繼續提供服務。其中一個副本為主副本,其他副本為備份副本,通常操作方法為:數據寫入到主副本,由主副本確定操作順序并復制到其他副本。主要的操作方法有兩種:強同步復制副本和異步復制副本。
1.2.1 強同步復制副本
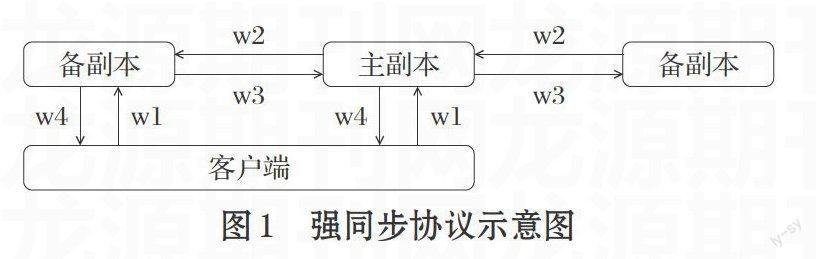
客戶端將寫請求發送給主副本,主副本將寫請求復制到其他備份副本中和,常見的做法是同步操作日志。主副本首先將操作日志同步到備份副本,備份副本回放操作日志,完成后通知主副本。接著,主副本修改本服務器,等到所有的操作都完成后通知客戶端寫成功。這種要求主、備同步成功才可以返回給客戶端寫成功的協議稱作強同步協議。如圖1所示:W1寫請求發給主副本;W2主副本將寫請求同步給副本;W3備份副本通知主副本同步成功;W4主副本返回客戶端寫成功。
實現強同步復制時,主副本可以將操作日志并發的發給所有備份副本并等待回復,只要有一個備份副本返回成功就可以回復客戶端操作成功。其優點為:如果主副本出現故障,至少有一個備份副本擁有完整的數據,分布式存儲系統可以自動地將服務切換到最新的備份副本,不用擔心數據的丟失。
1.2.2 異步復制副本
與強同步對應的復制方式就是異步復制。在這種復制模式下,主副本不需要等待備份副本的回應,只需要本地修改成功就可以告知客戶端操作成功。其優點在于系統的可用性較好,但是一致性較差,如果主副本發生不可恢復性故障,可能丟失最后一部分更新操作[1]。
2 非結構化數據存儲方式
非結構化數據具有如下五個特點:第一,存儲方式不統一,通常情況下,用戶各自管理自己的非結構化數據,包括結構化的數據管理、FTP以及傳統的紙質資料管理等多種方式;第二,非結構化數據格式多樣化,如Word、Excel、PDF、JPEG圖等等;第三,業務流程多樣,非結構數據處理涉及的流程主要有上傳下載、打印掃描、系統內部流傳等;第四,非結構化數據難以標準化,相對結構化數據,也更難理解,所以在存儲、檢索、發布以及利用上需要更加智能的IT技術,比如內容保護、知識挖掘、智能檢索、海量存儲等;第五,非結構化數據遍布于異構系統中,信息量非常大,尤其是多媒體數據,從信息整合的角度分析,信息需要集成。基于上述五點,存儲非結構化數據在技術上是一項巨大的挑戰。目前對非結構化數據的存儲方式主要有如下三種:文件系統存儲、數據庫存儲以及數據庫與文件系統結合存儲的方式。
2.1 文件系統存儲方式
文件系統存儲方式通過文件系統直接把數據存儲在文件服務器中。數據資源以文件的形式存放在計算機的特定目錄下,僅僅通過人工對文件夾進行簡單的分類,所以數據的存儲通常是無序的。需要訪問數據時,應用程序直接通過文件存儲路徑讀取文件。早啟的計算機對數據存儲要求簡單,文件系統可以滿足數據的管理要求。
隨著計算機技術的發展,計算機的應用領域擴展,數據不僅類型變的多樣,數據量也迅速積累、增長,文件系統提供的數據存儲能力已經無法滿足應用的需求。文件系統存儲方式無法更好的解決根據屬性對數據進行索引、查找、排序的問題,通常需要程序進行定制[3]。
2.2 數據庫存儲方式
關系數據庫自出現以來,功能不斷發展。目前大多數應用系統中的非結構化數據都是以二進制的格式存儲在關系型數據庫的BLOB字段中。用戶直接向數據庫發送請求進行數據操作。但是存儲在BLOB字段中有一些缺點:一是非結構化數據文件大,隨著數據量的不斷增大,會導致關系型數據庫存儲量迅速膨脹,影響數據庫性能,進而使得整個應用系統的性能下降;二是各應用系統之間相對封閉和獨立,其他應用無法共享相關文檔資料。
關系型數據庫是針對結構化數據的處理而產生的,無法很好地滿足現在網絡環境下對于非結構化數據的處理要求,例如數據的全文檢索就顯得力不從心。
多媒體數據包含多種信息類型,數據格式的特殊性帶來了數據存儲結構和存取處理的差別。多媒體數據庫隨需要應運而生。多媒體數據庫結合了數據庫技術和多媒體技術,繼承了傳統關系數據庫的優點,其作為一種全新的數據系統,可有效實現多媒體數據的存儲檢索。
非結構化數據庫是基于網絡應用的新型數據庫,作為結構化數據庫的補充,可以表達復雜的嵌套,支持更多的數據類型。關系數據庫限制了數據長度且改寫不方便,而非結構化數據庫支持重復字段,變長記錄可由若干重復的字段組成,每個字段又可由若干可重復的子字段組成。非結構化數據庫概括而言,就是字段數和字段長度可變的數據庫,在處理非結構化信息方面有著傳統關系型數據庫無法與之相比的優勢。
2.3 數據庫與文件系統結合存儲方式
數據庫與文件系統相結合的模式是將非結構化數據以文件的形式存放在計算機中,數據文件的存儲路徑存放在數據庫中。此種方式下非結構化數據源文件存放在的文件系統中,便于數據的瀏覽、傳遞和更改。而非結構化數據文件的屬性則采用數據庫中的數據表字段進行表述,方便數據的檢索、分類、查找,有序地存儲了數據文件。內容管理系統便是數據庫與文件系統相結合模式的典型應用。內容的含義比數據更為廣泛,“內容”強調對象,可以是任何結構的數據類型,不僅包含了結構化數據、非結構化信息,還涉及到知識。可以說,內容是一個比數據、文檔和信息更加全面的概念,是對所有結構化數據、非結構化數據及信息的聚合。內容管理側重于管理半結構化和非結構化數據。在研究數據存儲方式的基礎上,內容管理還致力于對象的處理過程,例如收集、存儲、檢索、分析、更新、傳遞等,以便將內容能夠及時準確的傳遞到正確的地點和用戶。內容管理是數據管理新的發展方向。
非結構化數據存儲技術與數據庫的發展密切相關,更與文件系統及其存儲技術的的發展密不可分。設計無限大的存儲空間、無限制的I/O帶寬和更高的性價比的理想存儲系統是緩解存儲壓力的總體目標。云存儲技術發展結合各種存儲技術應用的特點,在吞吐量、冗余、容錯、讀寫分布、數據劃分、負載均衡等特性方面進行技術提升,并綜合多種存儲技術適應復雜的不同種類的數據存儲需求[4]。
3 MongoDB
MongoDB是lOgen公司研發的面向文檔 開源的NoSQL數據庫系統,用C++語言編寫,是當前最流行的NoSQL數據庫。它提供一種強大、靈活、可擴展的數據存儲方式。
3.1 MongoDB數據模型
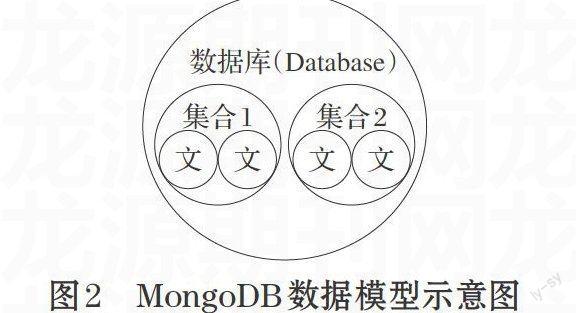
一個MongoDB系統由多個數據庫組成,每個數據庫由一組集合組成,每個集合由任意個文檔組成,而文檔由一系列字段組成,每個字段是一個鍵值對,其中鍵是字段名稱,值為對應的屬性值,數據模型如圖2所示。MongoDB的集合類似關系型數據庫中的表,用戶不用預先定義一個集合的字段結構,可以存儲不同結構的文檔在同一個集合,在數據庫運行時,可以隨時動態地添加或刪除文檔的字段。MongoDB的文檔使用BSON結構,一個文檔對應一個BSON對象,包含多個鍵值對,BSON是一種二進制序列化的類JSON數據交換語言。它以二進制字節的形式存儲鍵值對,鍵為字符串格式,值可以為任意數據類型,除了基本的整數、浮點數、字符串、日期等,還可以是數組或鍵值對。
MongoDB的文檔采用BSON的二進制結構,可以節省存儲空間,BSON格式的存儲效率在最壞的情況下也比JSON做好情況下的高。除此之外,BSON還支持鍵值對、數組這類的復雜數據結構,使得MongoDB的文檔可以嵌套子文檔或者數組,如此,MongoDB就不用像關系型數據庫那樣需要依靠外鍵關聯其他的集合,而只需要設計一個集合,提高了數據庫的性能。在某些情況下,BSON會犧牲額外的存儲空間換取更高的傳輸速度。下面代碼為一個典型的BSON對象。
{
Name:”Jack”,
Address:{city:”Hangzhou”,state:”China”},
Likes:[‘Bascketball,Music,Football],
Grade:[{lesson:”Computer”,score:99},{lesson:”math”,score:88}]
}
3.2 MongoDB特性分析
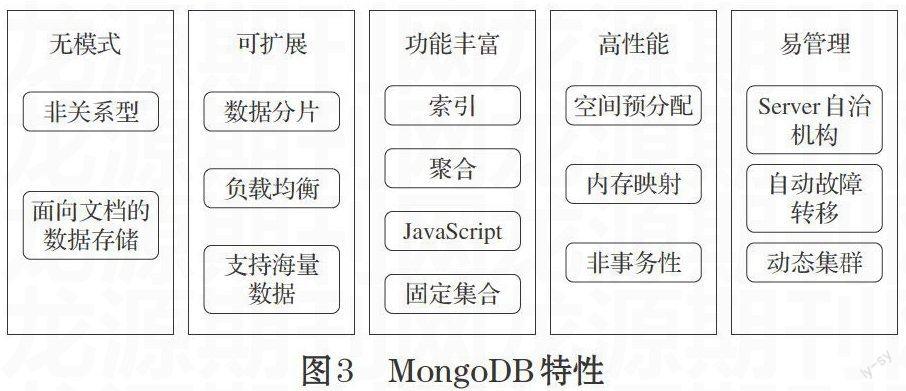
MongoDB擴展了關系型數據庫的眾多功能,如輔助索引、分片、復制等。與其他NoSQL數據庫不同的是,MongoDB還具有建立索引、使用聚合等功能,在完成這些功能的同時,MongoDB并未犧牲速度。MongoDB的主要特性如圖3所示。
[無模式][非關系型][面向文檔的數據存儲] [可擴展][數據分片][負載均衡][支持海量
數據] [功能豐富][索引][聚合][JavaScript][固定集合] [高性能][空間預分配][內存映射][非事務性] [易管理][動態集群][Server自治機構][自動故障
轉移]
圖3 MongoDB特性
⑴ 豐富的數據類:MongoDB是面向文檔的數據庫,為了獲得更加靈活的橫向擴展性,MongoDB拋棄關系存儲模型。它是無模式的,文檔中的字段不用事先定義,也不是一成不變的,應用層可以很容易地向文檔中添加字段,更改數據模型。
⑵ 容易擴展:MongoDB在設計之初就考慮到數據庫擴展的問題,無模式的數據模型可實現服務器之間的自動分割。通過MongoDB的自動分片機制,可以動態實現集群中數據的均衡負載。
⑶ 功能豐富:支持輔助索引、存儲JavaScript和MapReduce等其他獨特功能。
⑷ 卓越的性能:MongoDB中文檔記錄是可以動態擴充,預先分配數據文件,用空間換取穩定的性能。默認情況下,存儲引擎配置了內存映射文件,管理內存的工作交由操作系統處理。
⑸ 管理簡便:MongoDB采用復制集機制提升系統的可靠性,盡可能讓服務器進行自動配置。MongoDB的核心是文檔,每個文檔中的字段名和值有序地存放在一起,文檔可以比喻成關系型數據庫中的元組。集合類似于關系數據庫中的表,一個集合中包含若干個文檔,多個集合構成一個數據庫,一個MongoDB的實例創建多個相互獨立的數據庫[5-6]。
3.3 MongoDB分布式存儲架構
MongoDB復雜數據的存儲、管理和出錯處理,它是一個高度容錯的分布式存儲系統,適合用于大規模非結構化數據的存儲,部署在大規模的集群上,系統擴展能力強。
⑴ 分片
在MongoDB中,每個分片(shard)由一個或多個服務器構成,其上運行mongod進程來存儲數據。在實際的生產環境中,為了提高系統的可靠性和實現自動故障恢復,每個shard就是一個replica set。replica set支持兩個以上節點的自動故障恢復,其結構如圖5所示。replica set實質上是一種異步的主從復制機制,每個replica set只能有一個primary節點,負責數據的寫入;secondary節點只能讀數據,并不能進行寫操作。兩類節點之間的一致性通過oplog來保證,所有的操作及其對應的時間戳都會被寫入oplog,因其大小固定,所以新數據的寫入會覆蓋舊數據。所有的secondary節點監聽oplog的變化情況,以實現與primary節點的同步。
⑵ 配置服務
配置服務(config servers)用于存儲MongoDB集群的元數據信息,這些元數據包括兩部分:一是shard server上的chunks信息;二是chunk上的集合信息和文檔信息。每一個config server都包括了 MongoDB中所有chunk的信息,使用一個兩階段提交協議來保證config server中配置信息的一致性。config server擁有自己的復制模型,并不使用replica set的復制方式。當任何一個config server發生宕機時,集群中的元數據就變為只讀狀態,這樣處理方式避免了系統在不穩定的情況下,冒然改動元數據信息,導致config servers節點間中出現元數據不一致的情形。但這并不影響集群的正常工作,仍然可以向集群中寫入數據或從集群中讀取數據。
⑶ 路由進程
路由進程(mongos),可以當作一個路由和協調進程,它使集群中的多個組件形如一個單一的系統。mongos接收到用戶請求時,首先查詢config server,找到存放相應數據的shard servers,然后把用戶請求轉發給對應shard servers。當所有的shard servers完成操作后,把結果分別發送給mongos。當mongos匯總了所有的結果后,再把最終結果返回給用戶。mongos的每次啟動,都要到config servers中讀取元數據,并緩存在本地。每當config server中的元數據有改動,它都會通知所有的mongos。mongos可以運行在任何服務器上,同時啟動的mongos進程數量也沒有限制[7]。
4 結論
本文介紹了分布式存儲技術,重點介紹了強同步復制副本,它比較穩定。比較了非結構化數據的三種存儲方式。其中數據庫與文件系統結合存儲方式更適合非結構化數據的存儲。研究了非關系型數據庫MongoDB的數據模型和它的一些特性,分析了MongoDB的分布式存儲架構、工作原理以及它在非結構性數據存儲上所起的作用。
參考文獻:
[1] 中國互聯網絡信息中心.中國互聯網絡發展狀況統計報告[R].CNNIC,2014.
[2] Mell P,Grance T. The NIST definition of cloud computing (draft)[J]. NIST specialpublication,2011.800(145):7
[3] 陳康,鄭緯民.云計算:系統實例與研究現狀[J].軟件學報,2009.20(5):1337-1348
[4] 謝華成,陳向東.面向云存儲的非結構化數據存取[J].計算機應用,2012.32(7):1924-1928
[5] 劉正偉,文中領,張海濤.云計算和云數據管理技術[J].計算機研究與發展,2012.49(1):26-31
[6] 倪永軍,謝長生.網絡存儲技術現狀,存在的問題及對策研究[J].計算機工程與應用,2003.39(10):159-161
[7] 張薇,馬建峰.LPCA分布式存儲中的數據分離方法[J].系統工程與電子技術,2007.29(3):20-22
