基于Web日志挖掘的路徑補充算法改進
2015-05-30 20:37:05邵天會
中國新通信 2015年22期
邵天會
【摘要】 由于進行數據挖掘的Web日志來源不同,進行數據預處理時比較復雜,為了提高數據處理效率,結合網絡拓撲結構對用戶訪問路徑進行二叉樹的轉換,提出PFS(Path For Session)算法---消息路徑優化。研究表明該算法解決了Web日志用戶訪問路徑的補充問題,提高了數據預處理效率。
【關鍵詞】 訪問路徑 PFS 消息路徑優化
Web日志挖掘主要是針對用戶瀏覽信息進行分析,因此用戶會話的提取是首要任務。所謂的用戶會話就是某個用戶在某個時間段內請求頁面的集合[1]。在識別用戶會話過程中存在的一個問題是確定訪問日志中是否有重要的請求沒有被記錄。路徑補充保證了用戶訪問日志的完整性,從而保證Web日子挖掘的現實意義。
一、 路徑補充原理
路徑補充就是將由于本地或代理服務器緩存的影響而沒有產生日志記錄的請求頁增加到用戶會話中[2]。
得到用戶會話之后,要根據用戶會話得到訪問路徑。路徑補充涉及定義如下:
定義:用戶會話的路徑集合 PS=
PS 中的記錄是按 Rid 值分組順序排列的;輸出為:PS。
二、消息路徑優化算法
2.1 消息路徑優化算法原理
結合本文的研究目的和Web日志數據源針對路徑補充的問題提出利用網絡拓撲結構從用戶訪問序列獲得用戶訪問事務數據的算法PFS(Path For Session)算法---消息路徑優化,PFS算法是首先把網站的樹形拓撲結構轉換為二叉樹的結構,然后在二叉樹結構上根據用戶的會話序列得到用戶訪問事務序列,PFS算法認為當前用戶的訪問序列中出現不連續的節點時,則用戶可能點擊了瀏覽器上的Back按鈕或重復點擊一個鏈接,當出現這種情況時,表明用戶在點擊Back按鈕或重復點擊鏈接時就結束了上次會話,重新開始了新一輪的會話。
2.2 消息路徑優化算法的實現
當前會話頁面分別為:A,C,D,I,對應的請求頁面分別為F,H,C,J。
這次會話的序列是:A--F--C--H--D--C--I--J使用路徑補充技術:A--B--F--B--A--C--H--C--A--D--A--I--D--J再利用最大向前引用路徑算法得出用戶的訪問事務為A--B--F,A--C--H,A--D--I--J,三個事務。在此過程中,必須對用戶的訪問序列進行補充得到完整的路徑后再應用最大向前應用路徑才能得到訪問事務。利用PFS算法轉換為二叉樹。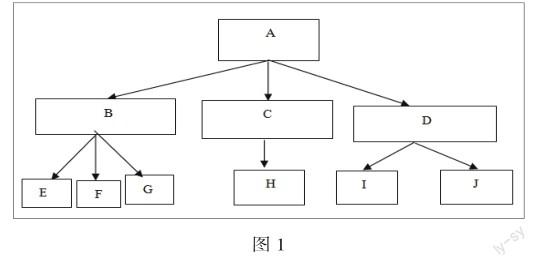
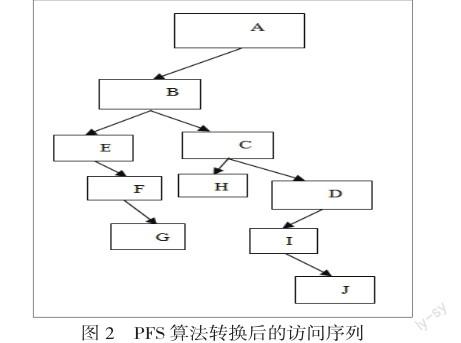
由此,不再需要對訪問序列補充路徑便可由用戶訪問序列直接獲得用戶的訪問事務A--B--F,A--C--H,A--D--I--J。
三、算法改進對比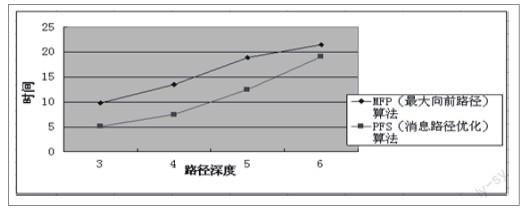
用戶訪問會話使用路徑補充和PFS算法得到用戶訪問事務的時間進行對比,此對比是假設網站的結點鏈接已經由圖結構轉換為樹形結構,且樹形結構的擁有25個葉結點,樹的深度為分別為3,4,5,6時進行的。
實驗證明該算法在相同的路徑深度前提下,減少了Web日志數據預處理的時間,提高了效率。
四、結論
PFS算法改進了數據預處理階段的路徑補充步驟,從整體上提高了數據挖掘效率,但是算法基于網絡拓撲結構,隨著網站的頁面大量增加,網絡拓撲結構也隨之復雜,算法的復雜度同時增大,所以PFS算法對網絡拓撲結構復雜的網站需要更多的研究,以適應復雜的網絡拓撲結構。
參 考 文 獻
[1] 何坤鵬,郭海波.Web 日志挖掘技術及其應用研究[J],中國科技信息,2007-08-15:236-237.
[2] 劉明吉,王秀峰,黃亞樓.數據挖掘中的數據預處理[J]計算機科學,2000-04-15:3-9.
[3] E.F.Codd,S.B.Codd and C.T.Salley.Providing OLAP to User-Analysts:An IT Mandate.IBM Research Lab,Techni cal Report,1993.
[4] J.Qay,S.Chaudhuri,A.Bosworth,A.Layman,D.Reichart,M.Venkatrao,E Pellow,and H.Pirahesh.Data cube:A relational aggregation operatorgeneralizing group-by,cross-tab and sub-totals.Data Mining and Knowledge Discovery,1:29-54,1997.
