面向多線程應用的片上多核處理器私有LLC優化
2015-06-27 08:26:03吳建宇彭蔓蔓
計算機工程 2015年1期
吳建宇,彭蔓蔓
(湖南大學信息科學與工程學院,長沙410082)
面向多線程應用的片上多核處理器私有LLC優化
吳建宇,彭蔓蔓
(湖南大學信息科學與工程學院,長沙410082)
片上多核處理器已逐漸取代傳統超標量處理器成為集成電路設計的主流結構,但芯片的存儲墻問題依舊是設計的一個難題。CMP通過大容量的末級高速緩存來緩解訪存壓力。在軟件編程模式向多線程并行方式轉變的背景下,針對多線程應用在多核處理器上的Cache訪問特征,提出一種面向私有末級Cache的優化算法,通過硬件緩沖器記錄處理器訪存地址,從而實現共享數據在Cache間的傳遞機制,有效降低Cache失效開銷。實驗結果表明,在硬件開銷不超過Cache部件0.1%的情況下,測試用例平均加速比為1.13。
片上多核處理器;存儲墻;末級Cache;失效開銷;緩沖器
1 概述
隨著集成電路工藝的不斷發展,晶體管的尺寸越來越小,傳統處理器以提高頻率、增加流水線深度和增加功能部件的方式來提高性能將無法持續,片上多核處理器以功耗效率高、復雜度更低和高性價比等優勢,成為學術或工業界的主流處理器體系結構[1-2]。當芯片上集成的處理器核心增多,處理器對存儲器訪問速度、帶寬的要求隨之變高,但受主存訪問周期長和片外引腳數目受限等因素的影響,存儲墻問題日趨嚴重。為了有效緩解處理器片外訪存的壓力,當代處理器設計已經將一半以上的片上晶體管資源用于最后一級高速緩存,Intel Xeon E5-2600[2]處理器僅末級Cache(Last Level Cache,LLC)容量就高達20 MB。
另一方面,軟件開發技術也在發生巨大改變,以往的并行技術只是應用于少數的科學計算、大數據處理等專業應用領域。隨著芯片內集成處理器核數目的飛速發展,計算機編程模型正在由傳統串行編程向并行編程轉變,如任務并行編程模型[3-5]以開發難度低、執行效率高等優點受到廣泛研究和應用。
本文基于LLC為私有架構,針對并行多線程應用的訪存特點,提出一種縮短Cache失效開銷的MAOPL (Multi-threaded Applications-oriented Approach toOptimize Private LLC)算法,其基本思想是在多線程應用程序運行時,如果一個線程需要對共享數據進行訪問,則將相鄰處理器私有Cache體存儲的有效數據通過總線調入數據請求處理器的本地Cache,從而降低Cache失效后的開銷。
2 研究背景
2.1 CMP存儲結構
目前,多核處理器Cache通常具有多級結構(通常為2級至3級),從L1 Cache到LLC結構越來越復雜、速度越來越慢、容量越來越大。絕大多數的L1 Cache是私有的,但LLC存在共享和私有2種基本方式。在共享設計中,LLC統一編址,供所有處理器使用,因此,空間利用率高,但速度受到最大線延遲影響,訪問周期長。在私有設計中,LLC被分成相互獨立的Cache塊,放置在各自處理器附近,供處理器單獨使用。在本文中稱各自處理器私有的LLC為本地Cache體,否則稱為相鄰Cache體。所有私有LLC通過一條高速總線進行通信。因為私有LLC設計簡單,所以具有較快的訪問速度。但當運行的程序集較大時,私有設計可能引發失效率增加。片上多核處理器LLC的優化技術實質上就是汲取2種不同設計的優點,減少各自的不足。
2.2 相關工作
私有LLC由于結構相對簡單,可以與處理器更緊密結合,相對共享方式,具有訪問延遲小、性能隔離等優勢,但私有LLC只能被各個處理器核單獨使用,無法根據應用動態調整,私有LLC結構空間利用率相對較低。有研究表明,對大多數應用而言,私有LLC設計具有更高的性價比[6]。
為了提高空間利用率,文獻[7]提出了合作式Cache(Cooperative Cache,CC)算法,通過增加一個一致性引擎(CCE)將各私有Cache連接,聚合成一個邏輯上的共享體,將本地Cache體中替換出來的塊以一定的概率放入相鄰Cache體中,稱為溢出(spilling),當再次訪問該塊時可以直接訪問,從而降低了Cache的失效率。但CC算法只是簡單地以概率控制溢出流向[8],沒有考慮應用的行為特征,實際上合作機制效率取決于應用的Cache行為特征。文獻[8]提出了一種動態溢出(Dynamic Spill Receive, DSR)算法,通過感知上層應用的效能來決定犧牲塊溢出的流向。文獻[9]認為DSR算法是以單個應用為單位來劃分效能,粗粒度劃分不適用于低層次溢出流向控制,進一步提出了面向 Cache組層次的SNUG(Set-level Non-Uniformity identifier and Grouper)算法,針對Cache組不同的容量要求,實現犧牲塊在Cache組間的溢出機制。
文獻[10]考慮了處理器負載均衡和犧牲塊的可重用性問題,通過Cache總線將重用性高的犧牲塊保存至同層的其他私有LLC中,提高了Cache命中率。文獻[11]提出了基于應用行為識別(BICS)的私有LLC溢出技術,該技術可以在線確定應用的Cache訪問特性,從而決策是否將犧牲塊溢出至同層的其他私有Cache體。
已有工作的重點在于私有LLC的合作或是多道單線程應用的Cache行為研究,本文是針對多線程應用在私有LLC上的行為特點,通過降低Cache失效開銷,實現私有LLC優化機制。
2.3 多線程應用訪存分析
目前并行程序開發常用的方法是調用系統函數(pthread)啟動多線程或利用并行編程語言(MPI, OpenMP,TBB[5],CILK++[4])。不同編程語言面向的環境各不相同,下面分別使用 Pthread和OpenMP環境下實現矩陣相乘算法來分析多線程應用的訪存特征。原始串行實現部分代碼如下,本文將共享數據定義為2個或以上線程對同一地址塊進行讀寫操作。
OpenMP是面向共享內存的多處理器并行編程語言,適用于劃分力度較小的并行開發,主要通過編譯指導語言來指導并行化,代碼如下所示。# program omp parallel for shared為編譯指導語句,通過該語句指導編譯器實現for循環的并行化,shared (A,B,C)表示A,B,C數組為子線程共享數據。

Pthread是由POSIX提出的一套通用線程庫,通常的執行模式采用Fork-Join形式。在開始執行的時候,只有一個主線程存在,主線程在運行過程中,如果碰到需要并行計算的時候,派生出子線程執行并行任務,在并行代碼結束執行后,派生線程退出,并將執行結果傳遞給主線程。代碼如下所示,pthread_creat(),pthread_join()函數分別用于創建和合并函數,func指針函數用于給每個子線程分配任務。數組matrixA,matrix,matrixC作為共享數據劃分給子線程使用。

由上文的分析可知,在多線程應用中存在共享數據用于線程間的通信、同步等操作。圖1選取了PARSEC[12]測試集中部分程序的共享數據分布圖,圖中B16~B128分別表示Cache行Block為16 Byte~128 Byte大小。從圖可知,bodytrack,x264等程序中共享數據的比例高達50%。

圖1 PARSEC部分用例共享數據分布
3 MAOPL算法
在并行應用中,共享數據塊被多個進程進行讀寫操作。基于Cache的工作機制,當任意一個處理器在讀寫共享數據發生Cache失效時,會向下一級存儲器請求缺失數據,每個私有Cache會在本地存儲一份共享數據的拷貝。由于主存與Cache的訪問開銷不在一個數量級,往往LLC失效后需要上百個時鐘周期從主存讀取數據。因此MAOPL算法采用緩沖器的形式,記錄近期處理器訪問的地址。當某個處理器訪問共享數據,但本地Cache體發生失效時,可以在緩存器中查找該數據所在處理器的ID,通過總線將共享數據調入本地Cache體,實現Cache間共享數據傳輸,極大地減少了失效開銷。
3.1 MESI一致性協議
當系統中有多個處理器時,同一份內存可能會被拷貝到多個處理器的本地緩存中。為了防止多個拷貝之間的不一致,必須維護多個緩存的一致性。MESI是一種被廣泛采用的緩存一致性協議,MESI協議為每個Cache行維護2個狀態位,使得每個Cache行處于4個狀態(M,E,S,I)之一,各個狀態的含義如下:
(1)M:被修改的。處于這一狀態的數據只在本CPU中有緩存,且其數據已被修改,沒有更新到內存中。
(2)E:獨占的。處于這一狀態的數據只在本CPU中有緩存,且其數據沒有被修改,與內存一致。
(3)S:共享的。處于這一狀態的數據在多個CPU中有緩存。
(4)I:無效的。本CPU中的這份緩存已經無效了。
處理器對Cache進行讀寫操作時,會觸發總線事務(BusRd:總線讀,BusRdx:總線寫)廣播給其他處理器。處理器對總線進行偵聽,在需要時進行相應Cache行的狀態轉化。圖2為MESI協議狀態轉換圖,例如當CORE0和CORE1分別保存A地址數據時,當CORE0對A地址數據進行修改后,會引起總線事務BusRdX A,CORE1本地Cache將Tag值為 A的 Cache行的狀態由共享態變成無效態。
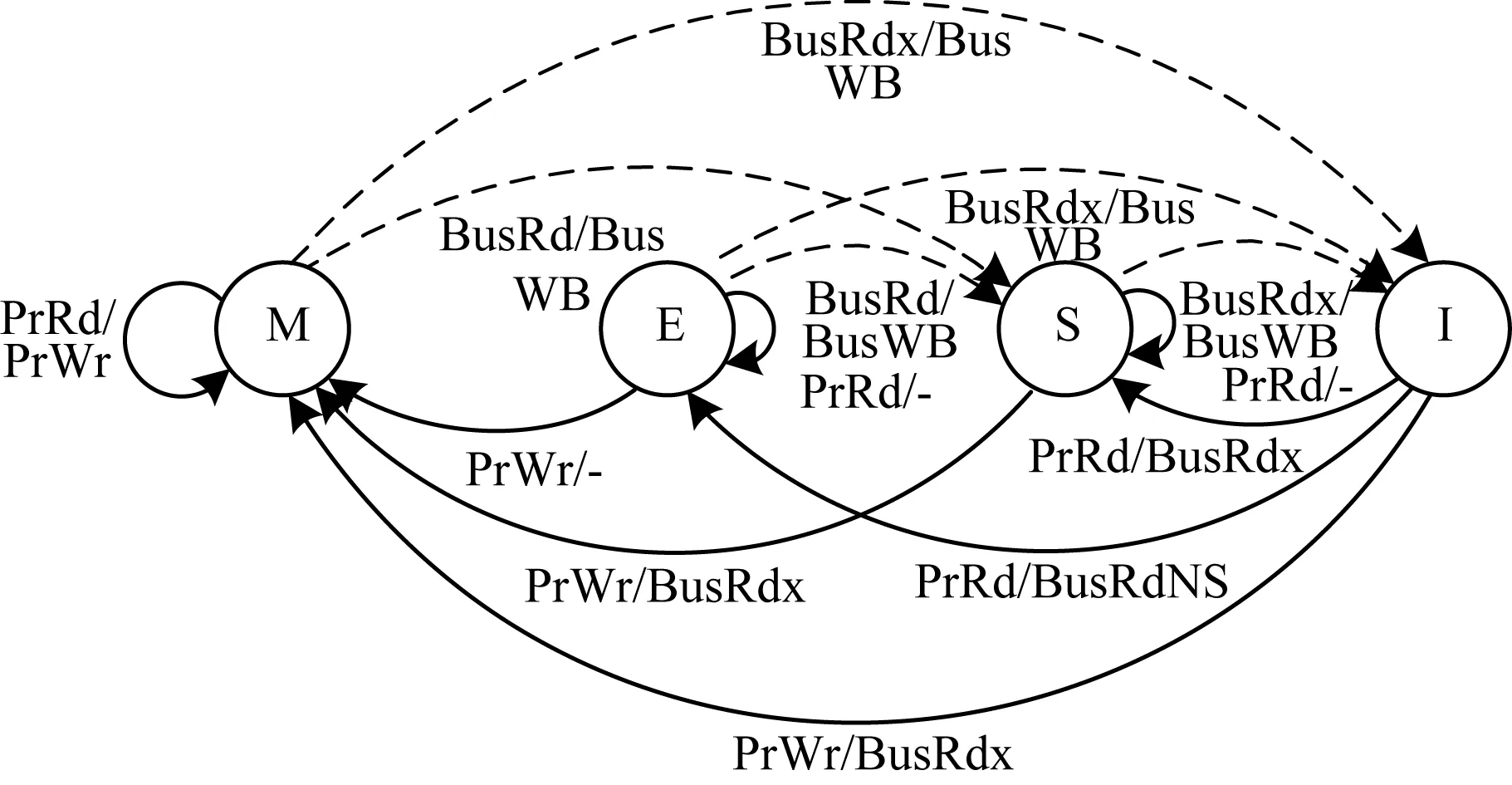
圖2 MESI協議狀態轉換
3.2 MAOPL總體結構
為了記錄處理器近期的訪問地址,本文設計了一個N組的緩沖器(Buffer),與總線相連并實時偵聽總線事務。如當CORE0讀取A地址數據時,引起總線事務BusRd A,緩沖器偵聽到該事件后,分別將數據地址A、處理器ID存入緩沖器中;如果是對A地址數據進行寫,那么在偵聽到BusRdx A后,將最新數據所在處理器ID存入地址項為A的緩沖器中。緩沖器采用Cache中LRU替換算法對N組數據進行插入、提升和替換選擇等操作。在查找緩沖器項時,采用硬件并行的查找方式。以4核CMP結構為例,圖3表示算法的硬件拓撲結構,表1為緩沖器中每一項所包含的數據。
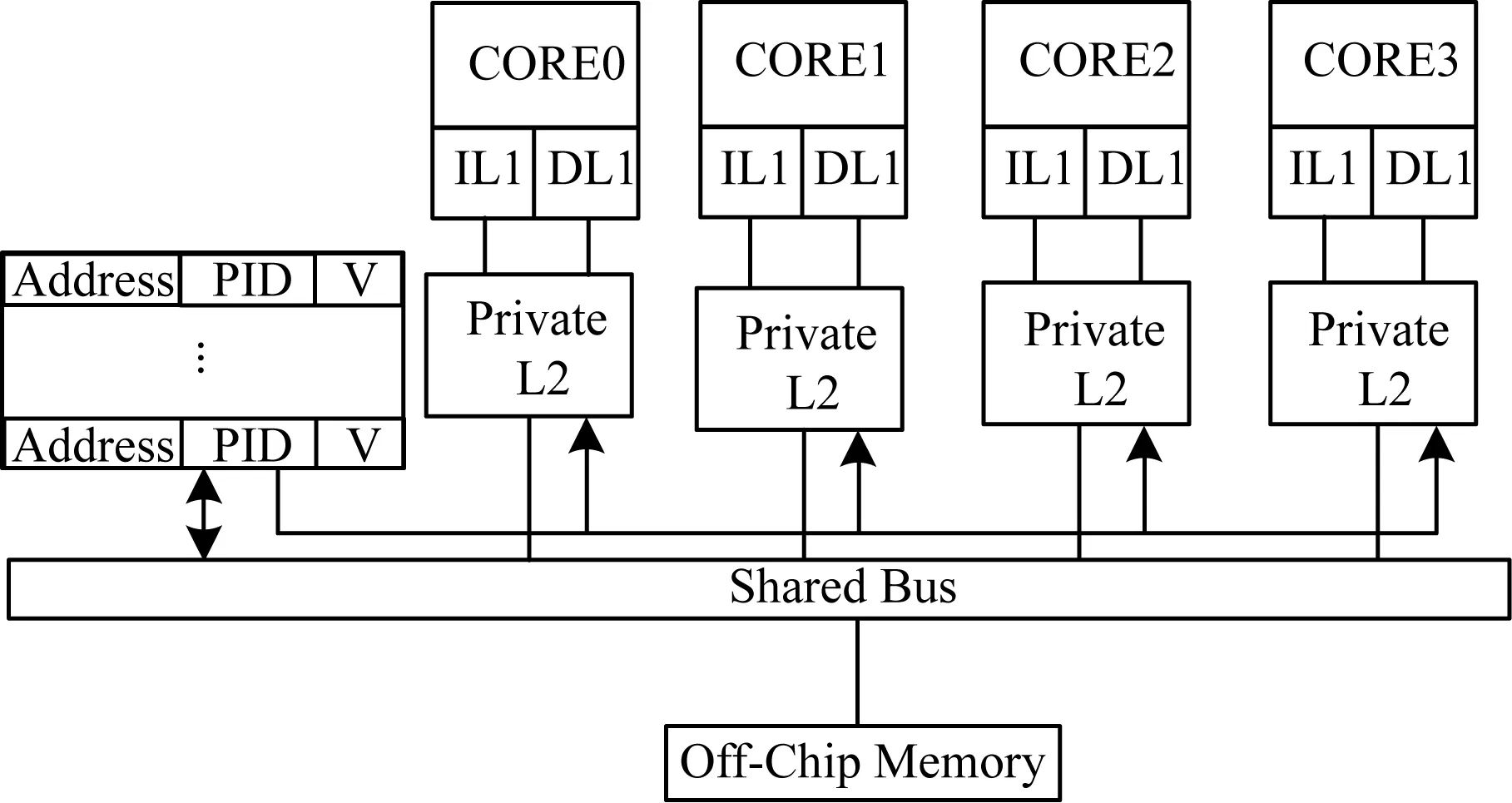
圖3 算法總體結構

表1 緩沖器長度參數說明
3.3 算法處理步驟
MAOPL算法的基本思想是每當發生本地Cache體失效時,盡量從速度更快的相鄰Cache體中調入數據,而不是訪問下一級存儲器。圖4為MAOPL算法流程。

圖4 MAOPL算法流程
處理器訪問LLC,如果命中則返回請求數據;否則,LLC失效后,處理器按照訪問地址首先在緩沖器中查找是否存在該地址項,如果緩沖器命中,命中項PID值(假設為CORE0)指示最新數據所在的處理器。本文引入文獻[7]中提出的Cache總線數據傳輸機制,將CORE0中相應數據調入本地Cache,并將數據返回給處理器;如緩沖器失效,則從下一級存儲器調入數據到本地Cache,并返回給處理器。
下面以處理器COREj對A數據寫命中后引發COREi讀A數據失效的處理過程為例,進一步闡述該算法思想,其余情況處理過程類似。圖5為算法步驟示意圖,步驟中省略了緩沖器硬件并行查找、Cache總線的數據傳輸等細節。

圖5 算法步驟示意圖
算法各模塊說明如下:
(1)Write to A:處理器COREj對A地址數據進行寫操作。
(2)BusRdx A:為了保持數據一致性,MESI協議引發總線BusRdx事件,使其他保存 A數據的Cache行狀態轉為無效態。同時,在本文中,在緩沖器中建立相應信息。
(3)Read miss A:處理器COREi對A地址數據進行讀操作,因為A被COREj修改,導致Cache讀失效。
(4)Detect hit A:當Cache失效時,先在緩沖器中查詢是否存在A的信息。
(5)Transport A:緩沖器命中后,根據PID值及數據的物理地址A,可在相應的Cache塊中迅速找到數據,并傳入本地Cache中。
4 實驗平臺及結果
4.1 實驗平臺及方法
本文所提出的算法是基于片上多核體系,末級Cache為私有結構。實驗采用MARSS[13]模擬器,測試集程序為PARSEC,操作系統為Linux 2.6內核,通過仿真平臺上的運行時間來測試算法性能。MAOPL算法中緩沖器硬件及數據訪問流程通過修改模擬器的存儲部分實現。MARSS是由SUNY大學開發的一款基于X86體系結構的全系統多核精確模擬器,由ptlsim和qemu 2個仿真器耦合而成,可以運行不經修改的操作系統。表2為模擬器具體的參數配置。
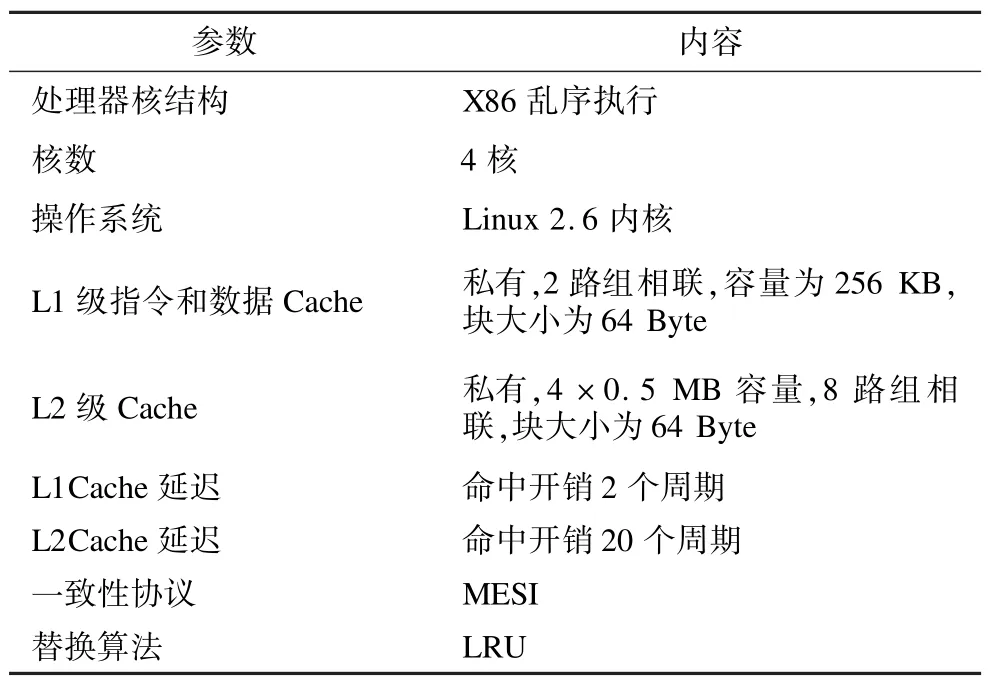
表2 處理器配置
PARSEC(The Princeton Application Repository for Shared-Memory Computers)由普林斯頓大學2008年開發,是一個多線程應用程序組成的測試程序集,代表了未來運行在片上多核系統中的共享內存應用程序的發展趨勢,主要包括視頻編碼技術、金融分析和圖像處理等應用程序。本文從PARSEC測試集中選取了blackschole,bodytrack,dedup,ferret, freqmine,swaptions,vips,x264等8個測試用例,程序運算規模采用輸入中等(simmedium)數據包。
4.2 實驗結果
在實驗中,基于對緩沖器硬件性能的估計,將Cache失效后訪問緩沖器查找時間設置為10個時鐘周期,相鄰Cache體傳輸數據到私有Cache體的時間為20個時鐘周期,即從緩沖器中查找到完成Cache間數據傳輸總開銷時間為30個時鐘周期,緩沖器組間替換策略采用LRU替換算法。考慮到測試程序工作集大小、并發線程數目等多種因素,通過實驗發現,緩沖器數目N取256~512較為適中。實驗中,在緩沖器上設置了訪問和命中計數器,圖6為緩沖器的命中概率百分比。

圖6 緩沖器命中率分布
在測試程序運行完后,取原運行時間與本次運行時間比值為算法的加速比,圖7為不同條件下相對于未修改前的加速比。
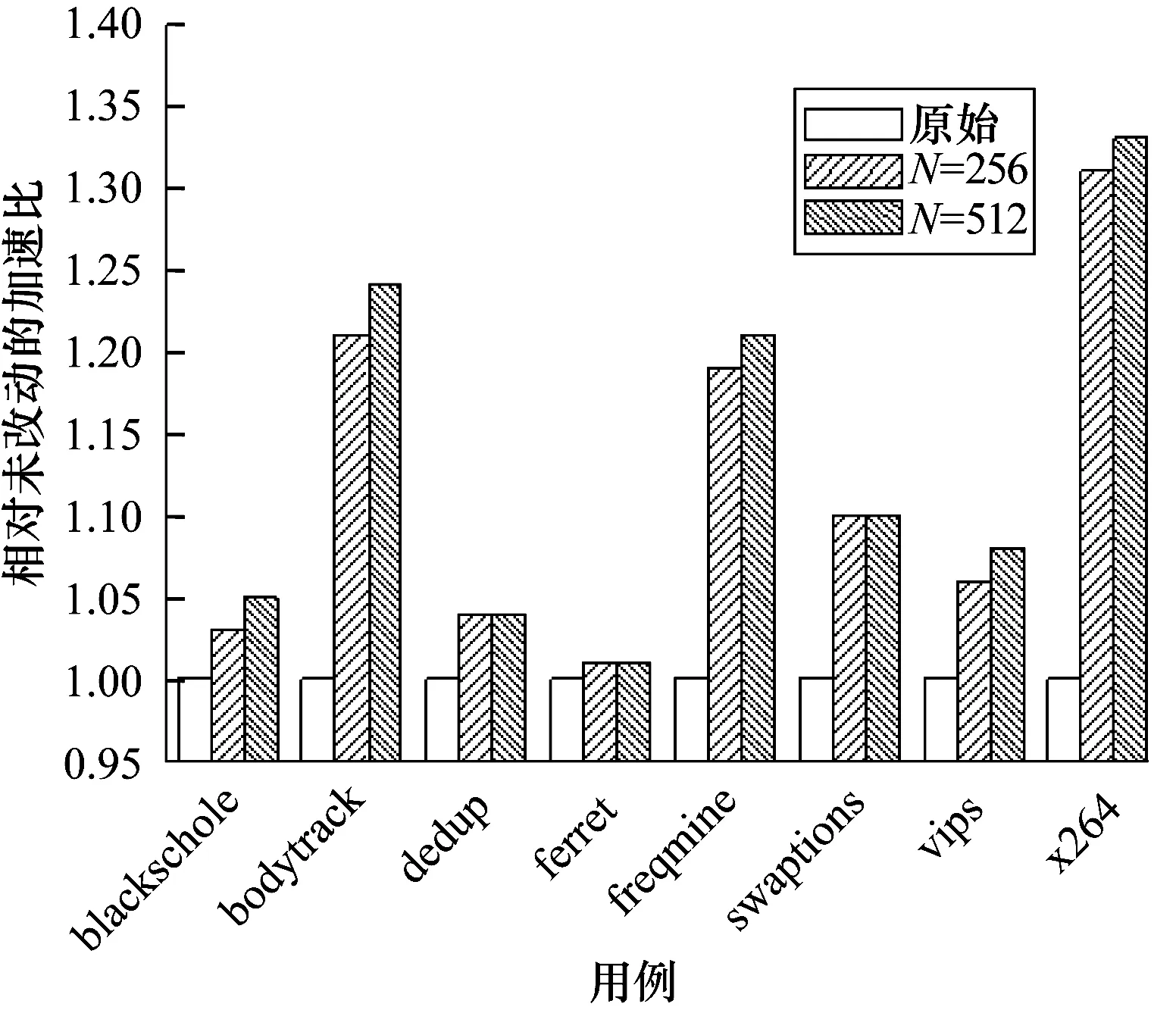
圖7 測試用例性能加速比
4.3 實驗分析
4.3.1 算法性能分析及硬件開銷
有如下公式:

在式(1)中,Ttotal表示每條指令平均執行時間;Tclock表示CPU的時鐘周期;Tmem表示訪問存儲器周期;CPI為平均每條指令執行的周期數。在式(2)中,TL1,TL2分別表示第1級和第2級Cache的命中時間;HL1,HL2分別表示第1級和第2級Cache的命中率;TL2miss表示二級Cache的失效開銷。假設主存平均訪問時間為200個周期,不考慮地址轉換等其他因素,那么TL2miss為200個周期。在本文中引入緩沖器,當L2發生miss時,先查找緩沖器,若緩沖器命中,則從相應的附近Cache讀入數據,否則從主存中讀取數據。緩沖器命中總開銷TBufferHit為30周期;而緩沖器失效開銷TBufferMiss為緩沖器查找時間與訪主存時間之和,即210個周期。

若命中率Hpredict為50%,則二級Cache失效開銷由式(3)可知,TL2miss為120,與原始相比,可以較大地減少訪存時間。
令處理器核數為P個,主存地址為A位,每一個Cache塊大小為B,則緩沖表中每一項大小M=lbP+A+1-lbB,緩沖表硬件總開銷為M×N。設處理器數目P為8,地址為A為32 bit,Cache塊大小B為64 Byte,當緩沖器組數N為256或512,緩沖器硬件開銷分別為960 B和1 920 B,若私有Cache為2 MB大小,則緩沖器硬件開銷比例分別占整個私有
Private LLC Optimization of Chip Multi-processors Oriented to Multi-threaded Application
WU Jianyu,PENG Manman
(College of Information Science and Engineering,Hunan University,Changsha 410082,China)
The design of processors changes from traditional superscalar ones to Chip Multi-processors(CMP).CMP becomes the mainstream of computer architecture.But the memory wall problem is still one of the design challenges.With the help of large volume last level Cache,CMP succeeds to relieve memory pressure.The pattern of software programming changes toward the parallel mode.This paper presents an algorithm about Last Level Cache(LLC)optimization on CMP, based on characteristic of Cache access.By the use of the hardware buffer recording processors’access address,the algorithm enables the transfer mechanism of shared data between Caches,and reduces Cache miss penalty effectively. Experimental results show that,average speedup of test is 1.13 when the cost of hardware is less than 0.1%of Cache.
Chip Multi-processors(CMP);memory wall;Last Level Cache(LLC);failure overhead;buffer
1000-3428(2015)01-0316-06
A
TP303
10.3969/j.issn.1000-3428.2015.01.059
國家自然科學基金資助項目(61173037)。
吳建宇(1987-),男,碩士研究生,主研方向:計算機體系結構;彭蔓蔓,教授、博士生導師。
2013-12-23
2014-02-17 E-mail:jianyu_wu@yeah.net
中文引用格式:吳建宇,彭蔓蔓.面向多線程應用的片上多核處理器私有LLC優化[J].計算機工程,2015,41(1): 316-321.
英文引用格式:Wu Jianyu,Peng Manman.Private LLC Optimization of Chip Multi-processors Oriented to Multi-threaded Application[J].Computer Engineering,2015,41(1):316-321.
