TMS320C66x匯編語言的DSP代碼優化技術
2015-09-12 06:42:50張曉東孔祥輝張雨輪
單片機與嵌入式系統應用 2015年9期
張曉東,孔祥輝,張雨輪
(西安電子工程研究所,西安710100)
張曉東、孔祥輝(工程師)、張雨輪(助理工程師),主要研究方向為SAR 雷達系統設計與信號處理。
引 言
DSP(數字信號處理器)通常作為實時信號處理的核心器件,被廣泛應用于工業控制、通信、航空航天、武器精確制導等領域中。在以DSP 為核心的系統設計過程中,軟件開發的地位顯得尤為重要。雖然器件水平的不斷提高、DSP主頻和運算核的增加,使DSP的運算能力大為提升,但是隨著系統集成度和實時性的不斷提高,為了提高運算速度和執行效率,在進行軟件開發時經常需要用到C 語言和匯編語言的混合編程。
如何使C語言和匯編語言有效地結合在一起,使程序清晰易懂,同時提升運算效率是本文著重討論的問題。TI公司的TMS320C66x 系列是高性能的數字信號處理器,本文以CCS5.0編程環境為例,講述了編譯器的實時運行環境下的匯編編程規則、使用流水線技術對程序的改善,以及在編程中需要注意的問題。
1 TMS320C66xDSP簡介
TMS320C66x高性能DSP 采用VLIW 結構,具有2路數據通道,每個通道包含4個可以并行運行的處理單元(.L、.S、.M 和.D),每個通道有32個32位通用寄存器,每個周期最多可以運行8個32位的指令,數據的加載位寬為每個周期32位或者64位。
其L1/L2 存 儲 包 括 直 接 映 射 的32KB 的L1P 指 令RAM、32KB的2 路L1D 數 據RAM、512 KB 可 配 置 的L2RAM;最高運行頻率為1.25 GHz,每核最高有40GMAC/s定點和20 GFLOP/s運算能力,8 核共享4 MB片上存儲,包含豐富的外圍接口,如DDR3 控制器、PCIe控制器和SRIO 接口等。
TMS320C66xDSP核心框圖如圖1所示。
2 編譯器的實時運行環境
在編譯器的實時運行環境下,編寫匯編代碼時要遵守的規則主要有:寄存器使用規則和參數傳遞規則。
TMS320C66x兩組通用寄存器,每組分別有32 個32位寄存器,分為兩組,分別是A0~A31和B0~B31。編譯器對特定寄存器的使用及如何保護作了規定。占用兩個寄存器的數據(長整型、雙精度浮點數)放在相鄰的兩個寄存器中,且第一個必須是奇數,例如A1:A0,前面存放高位,后面存放低位,成對使用。
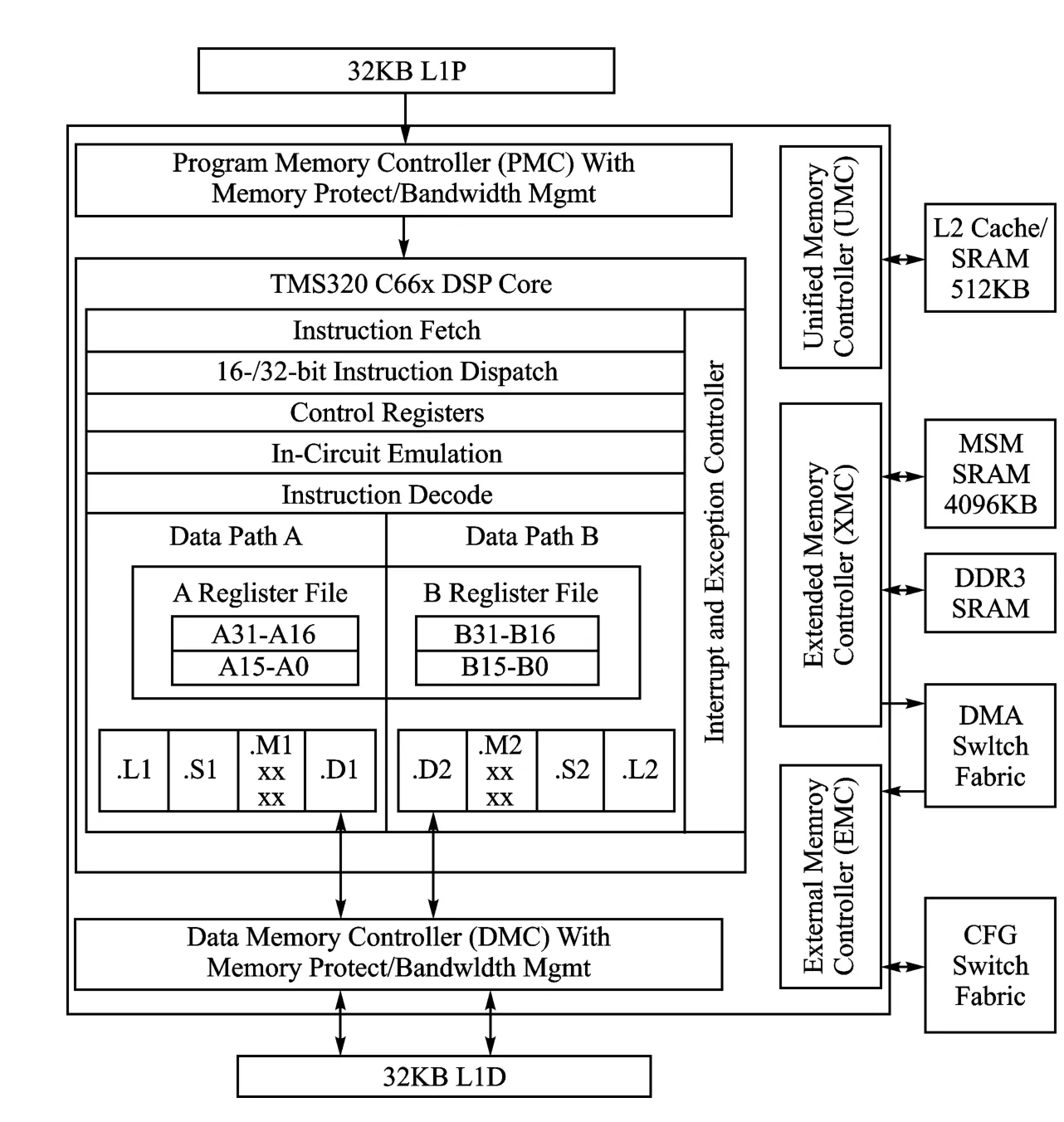
圖1 TMS320C66xDSP核心框圖
TMS320C66x編譯器對匯編函數調用有嚴格的規定,如果在調用中不遵守這些規定,就會破壞實時運行環境,導致程序錯誤。主程序把函數調用需要傳遞的參數放在寄存器或者堆棧里。參數的前10 個依次放在A4、B4、A6、B6、A8、B8、A10、B10、A12和B12里、如果參數是長整型或者浮點型,就占用一個寄存器對,如A5:A4、B5:B4等,依此類推。
剩下的參數放在堆棧里,堆棧指針指向下一個空地址,第11 個參數就是SP+offset,依此類推。參數放在堆棧里需要考慮存儲邊界,一個參數如未聲明類型且長度不超過一個整型,按整型存放,未聲明的浮點數按雙精度浮點數存放。返回值如果是整型,單精度浮點數或者指針,放在A4中,如果是長整型或者雙精度浮點數則放在A5:A4 中。
3 軟件流水線技術的應用
TMS320C66x系列DSP 的高速度、高效率是靠并行處理來實現的,而軟件流水線技術(software pipeline)則是實現并行處理的關鍵。DSP只有在流水線充分發揮作用的情況下,才可能達到最高的執行效率。軟件流水線包含取指、譯碼和執行3個階段,每個階段又分為不同的相位。軟件流水線技術處于不同相位可以并行執行,即取指、譯碼和執行可以并行運行,甚至相同階段不同相位也可以并行運行。
軟件流水線技術是一種循環內的指令,能在一個周期內使用不同功能單元并行處理多個迭代的技術,能更為有效地使用資源,尤其對于VLIW的具有多功能單元的架構,通過減少循環中因為數據相關導致的依賴和功能單元使用沖突挖掘一次循環中指令的并行性,一般都是針對最內層循環進行的優化。
軟件流水線技術可以概括為:從一個循環出發,將一個循環分成可以并行執行的迭代單元,也就是說在一次循環運算結束前,啟動多次后續的循環運算。軟件流水階段分為進入循環核前的prolog、循環核loop kernel、循環核結束后的epilog三個過程。流水線技術示意圖如圖2所示。
軟件流水線編程時,主要使用以下寄存器:
①Loop Buffer是一個能存儲若干條SPLOOP指令的片內存儲空間,最多達14個執行包。
② LBC 執 行 SPLOOP、SPLOOPD、SPLOOPW 時清零,每個運行周期后+1,當運行到功能段(Stage)邊緣時,重置為零,此寄存器用戶不可見。
③ILC 為用于循環計數的專用寄存器,SPLOOP 和SPLOOPD使用向下計數器,每運行一次循環遞減,使用ILC需要4個周期的延遲。
RILC循環嵌套時用于重置ILC。
軟件流水線編程時,主要使用以下指令:
①SPLOOP一般用于告知循環最小運行次數,但不知循環體是否超過4個周期的起始,因為ILC加載和使用需要4個周期的間隔;SPLOOPD 知道循環最小運行次數,以及循環體超過4個周期的起始;SPLOOPW 不知道循環次數的任何信息,表明buffer的起始;SPLOOP的參數表示最小的功能段指令周期數。
②SPKERNEL 和SPKERNELR 表 明 結 束,其 參 數表示循環結束的第幾個功能段內的第幾個周期。
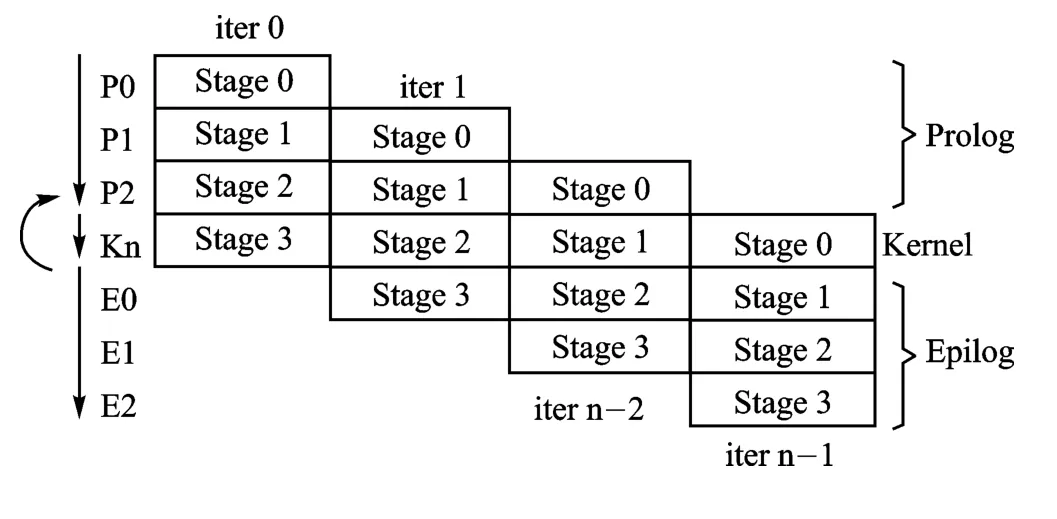
圖2 流水線技術示意圖
而SPMASK 和SPMASKR 用 來 區 分 是SPLOOP 內的存儲還是普通memory內的指令。
軟件流水線技術的限制:同一周期不能使用相同的功能單元;同一個周期不能同時寫入一個目標寄存器;在一個執行程序包內,每個數據通路兩個功能單元可以訪問另一個寄存器堆的相同的操作數。當從另外一側讀取一個剛剛更新的寄存器時,會有一個周期的延遲,即交叉通道的延遲。
4 匯編語言在程序中的應用
在實際應用程序開發過程中,程序通常采用混合編程的方法實現。主函數采用C 程序編寫,而對于那些耗時較多的運算密集的模塊采用匯編編寫。
這樣做的目的比較簡單,因為這樣在主程序中初始化一些初值,既簡單又準確,且匯編程序能提升運算效率。這樣既能保證程序的結構化和可讀性,又能保證應用的實時性。
實驗中主要以浮點復數點乘程序為例,介紹匯編語言對源代碼的優化步驟。
首先將C 源代碼循環展開翻譯成匯編代碼,為了使運算效率最高,應使用相同運算周期內運算量最高的匯編指令。
確定最小迭代間隔規劃使用功能單元,使循環的多次迭代能夠并行執行;為了使程序流水執行,應首先確定最小功能段間隔。
一個循環的最小功能段間隔是這個循環相鄰兩次功能段開始之間必須等待的最小周期數。循環中的相鄰功能段數據相關性和循環核中使用最多的功能單元是最小功能段間隔。
例如,如果在循環核中有3 條相鄰指令都使用.D1 單元,則最小功能段間隔至少是3,因為使用同一功能單元的3條指令不能并行執行,這時需要的最小功能段為3。
規劃使用寄存器。在已知最小功能段間隔以后,可根據程序的數據依賴關系為功能單元分配寄存器,必須保證每個周期內沒有寄存器并行使用。編寫匯編程序如下:
SPLOOPD3
LDDW.D1*A4++,A7:A6
LDDW.D2*+B4[1],B13:B12
LDDW.D2*B4++[2],A13:A12 LDDW.D1*A4++,B7:B6
NOP4
CMPYSP.M1 A7:A6,A13:A12,A11:A10:A9:A8 CMPYSP.M2 B7:B6,B13:B12,B11:B10:B9:B8
NOP3 FADDSP.L1A9,A11,A19 FADDSP.L2B9,B11,B19 FADDSP.L1A8,A10,A17 FADDSP.L2B8,B10,B17 NOP ADD.S1A5,A19,A16 ADD.S2B5,B19,B16 SPKERNEL4,0 STDW.D1A17:A16,*A18++[2]STDW.D2B17:B16,*B18++[2]
程序中使用LDDW、CMPYSP等指令完成數據讀寫和乘法運算等,保證程序運算時間最短。程序中使用最多的單元為D1和D2,每個單元被使用了3次,所以程序的最小功能段為3,循環長度共有15個,被分為5個功能段,在每個周期內保證了沒有相同的功能單元被使用。運行同時最多使用了A、B兩側共6個功能單元,保證了運算效率。使用更多的寄存器可以使數據的前后關聯更小。
使用本程序運行平臺為TMS320C6678,復數8 192點乘其運行周期為33 947,與使用編譯器優化的點乘程序的運行周期42 055相比,大約提升了20%。
結 語
本文提到的軟件利用匯編優化代碼技術,在實際的系統應用中獲得了滿意的代碼效率,為大規模復雜算法運算的執行提供了有效的時間保障。
在程序中采用的匯編語言和軟件流水技術,在實時條件下能夠應用于更為復雜和有效的算法,尤其是在編譯器對于某些程序優化不明顯的情況下,為提升代碼效率提供了一些解決思路。
[1]TI.TMS320C66x DSPCPU and Instruction SetReferenceGuide,2010.
[2]TI.TMS320C6000Optimizing Compiler User's Guide,2014.
[3]TI.TMS320C66xDSP CorePac User's Guide,2011.
[4]任麗香,馬淑芬,李方慧.TMS320C6000 系列DSP的原理與應用[M].北京:電子工業出版社,2000.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中華詩詞(2022年6期)2022-12-31 06:41:24
人大建設(2019年12期)2019-05-21 02:55:44
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
中國科技論壇(2017年7期)2017-07-25 08:49:53
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:55
