基于分布式的關聯規則算法在醫療數據挖掘中的應用
2015-09-28 06:10:57李曉楠馬元吉肖川
現代計算機 2015年8期
李曉楠,馬元吉,肖川
(1.四川大學計算機學院,成都 610065;2.四川大學華西醫院,成都 610041;3.四川大學華西公共衛生學院,成都 610041)
基于分布式的關聯規則算法在醫療數據挖掘中的應用
李曉楠1,馬元吉2,肖川3
(1.四川大學計算機學院,成都610065;2.四川大學華西醫院,成都610041;3.四川大學華西公共衛生學院,成都610041)
0 引言
隨著大數據時代的到來,醫院的信息化建設逐步完善,電子病歷大量積累、醫療設備和儀器的信息逐漸增多,病人病史、診斷、檢驗和治療的信息等大量醫療信息已經積累在醫院數據庫中,并且數據信息的結構呈現多樣化的特征。當數據量急速增長時,利用計算機對醫療數據做信息挖掘,提取恰當的數據進行處理,利用聚類、分類等各種數據挖掘方法構建醫療數據分析模型,對病人資料庫中的大量數據進行分析,提煉出其中有價值的信息,發現不同疾病之間的關聯,尋找傳染病的傳染特征,預測疾病發展趨勢,已成為醫療信息化中進一步研究的課題。其中,對影響我國居民健康的三大傳染病:乙肝、結核、艾滋的相關研究也是醫學科學研究中一個重要的方向。文中依托“十二五”科技重大專項——國家重大傳染病綜合防治綿陽示范區項目中獲取的體檢信息數據,對信息系統中獲取到的醫療數據的乙肝部分進行挖掘研究,對乙肝的并發癥、乙肝發病情況和生活習慣之間的關聯關系進行了探索。
1 Apriori算法及其分布式化
1.1Apriori算法
Apriori算法是一種挖掘關聯規則的頻繁項集算法,最早由R.Agrawal等人提出,目的是從大量數據中發現事物的相關聯系,Apriori算法應用廣泛,可用于消費市場價格分析、網絡安全中的入侵檢測、獲取顧客的購物習慣等。Apriori算法逐層搜索,迭代多次從k項集中尋找(k+1)項集,即先找出所有的頻繁1項集L1,隨后利用L1找到頻繁2項集的集合L2,再用頻繁2項集L2找L3,反復進行,直到找不到頻繁k項集。所有的頻繁集中找出符合一定置信度的規則,即產生用戶感興趣的關聯規則。將Ck設為候選k項集,算法的具體過程描述如下:
(1)以集合I作為候選集C1,通過對數據集掃描,得到候選集C1的支持度,將大于設置的最小支持度的元素提出,即頻繁1項集L1;
(2)掃描數據集,計算候選集Ck的支持度,找出大于最小支持度min_sup的元素作為頻繁k項集Lk;
(3)通過頻繁k(k大于1)項集Lk產生k+1項候選集Ck+1;
(4)迭代執行步驟(2)、(3),不能找出k+1項候選集時算法結束。
Apriori算法每次迭代都要對全部數據做一次讀取,并做一些復雜的邏輯運算,是相當耗費時間的,如果將算法并行處理,在多節點同時執行,將會大大地減少算法過程中的資源消耗。
1.2Hadoop的MapReduce編程模型
MapReduce是一種處理大量數據的并行編程模型和計算框架,將一個復雜的計算過程劃分到多個節點上執行,將大任務分而治之,匯總每個節點上的運算結果得到最后的計算結果。主要包括Map和Reduce兩個過程:Map過程,數據被分成M個獨立的數據塊,M個mapper函數,每個map得到一個數據塊,按照一定的計算過程進行計算,將計算結果以Key-Value的形式輸出,中間結果中的Key-Value按照Key的值分組排序,形成N個Key-ValueList。Reduce過程,將中間結果Key-ValueList作為輸入,分配給N個Reduce函數,計算并輸出最終結果。MapReduce工作流程如圖1所示。
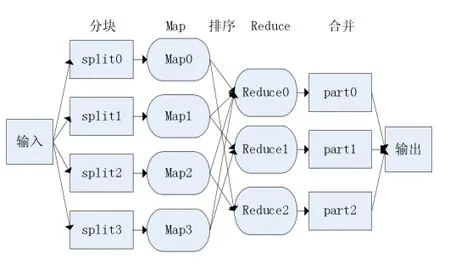
圖1
在這一過程中,Map函數和Reduce函數的具體執行過程都可以由用戶編程實現。
1.3Apriori算法的分布式化
將Apriori算法應用到Hadoop中,主要目標是對算法中每一次迭代求頻繁項集的過程執行一次mapreduce過程。計算過程設計如下:
(1)數據分塊。首先將數據提交到分布式文件系統,Map-Reduce將數據劃分為n個大小相同的數據塊,發送到集群中的m個節點。
(2)數據格式化。n個數據塊被格式化為鍵值對<key,value>。以num為每個屬性的標識,list為每個屬性對應的列表值,格式化為<num,list>。
(3)Map過程。Map函數對輸入的數據記錄進行掃描,處理后生成<key,value>對,先產生該數據塊的頻繁1項集,然后找出該數據塊的頻繁k項集。頻繁1項集的產生過程與詞頻統計方法類似,局部頻繁k項集的計算過程與傳統的Apriori算法一致。
(4)Combine函數。Combine函數起一個協助Reduce函數的功能,在Map函數完成后,將Map函數本地輸出做一個合并,并生成局部的頻繁項集,然后再將合并后的鍵值對散列劃分到幾個不同的分區,每個分區對應Reduce函數進行執行。因為當原始數據量很大時,每個Map函數產生成千上萬條記錄,數據通過網絡發送到Reduce函數,將消耗相當大的網絡資源,產生數據延遲。
(5)Reduce函數。將Map函數的輸出作為Reduce的輸入,合并所有的局部頻繁項集,生成全部數據的候選頻繁項集。
(6)掃描原始數據。對原始數據中的每條記錄進行掃描,如果該記錄在全局候選頻繁項集中存在,則類似統計過程,將其寫入上下文對象Context中,傳遞給Reduce函數匯總。
(7)合并輸出結果。對Reduce函數的輸出進行合并計算,將所有大于用戶設置的最小支持度的值輸出,寫入分布式文件系統的輸出文件,即得到所求的頻繁項集。根據置信度對頻繁項集進行篩選,即可找到相應的關聯規則。
流程如圖2所示。
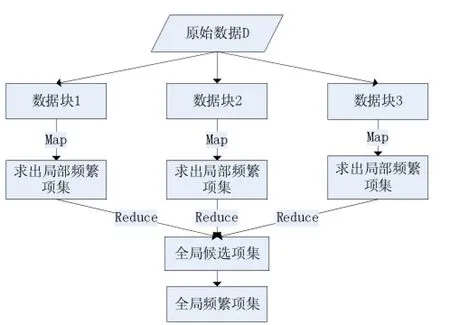
圖2
相比傳統單機模式下的數據挖掘,分布式化后的數據挖掘算法有如下幾個特點:
(1)掃描原始數據的次數減少,頻繁項集計算過程只需要對原始數據進行兩次掃描,降低了時間消耗和計算開銷。
(2)頻繁項集的查找可以在多節點并行執行,并且,Map過程的執行時間僅與輸入文件的大小成正比。
2 乙肝數據的挖掘實現
2.1數據預處理
利用項目中獲取的30萬居民的體檢數據,篩選出乙肝抗原hbsag為陽性的患者15000條,即乙肝患者數據,進行嘗試性的數據挖掘。提取了病人年齡(age)、性別(gender)、職業(career)、是否高血壓(hypertension)、是否糖尿病(diabetes)、乙肝家族史(family_history_hb)、乙肝疫苗接種史(hb_vaccination)、吸煙史(smoke_habit)、飲酒史(drink_habit)、BMI指數(bmi)、肝部B超情況(bultrasound_liver)等30個字段作為每條數據的屬性,對這些數據做結構化的統一,然后上傳到Hadoop集群,通過已完成的數據挖掘算法對數據進行分析,建立乙肝抗原陽性這一屬性值與其他屬性間的關系。具體實現步驟如下:
(1)搭建Hadoop集群,設置完全分布式模式,4個節點的配置如下:運行環境:Ubuntu、Hadoop版本:Hadoop0.20.2,JDK版本:JDK1.6.,處理器:Core duo e6700雙核處理器,主頻:3.2GHz,內存:2GB。
(2)對數據進行預處理,如字符串格式的替換,屬性值的統一等,將預處理后的數據上傳到Hadoop集群的分布式文件系統中。
(3)將預先完成的分布式化后的Apriori算法移植到到Hadoop集群中的一個客戶端,指定要處理的數據路徑,運行客戶端數據挖掘程序,將任務提交到Hadoop集群。
(4)生成挖掘結果。
2.2挖掘結果分析
使用Hadoop集群結合分布式化的關聯規則算法,本例中處理數據條數約15000,設置最低支持為1000,置信度0.7,這兩項值可根據實際情況進行調整,挖掘算法挖掘出來的結果選取了代表性部分,如下所示:
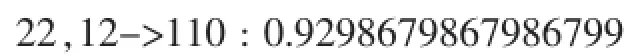

其中,不同的整數值代表不同的屬性的不同值域,如22代表職業是農民、96代表年齡段46~50等。根據關聯的重要度和概率強度,結合實際中的情況我們選取了以下幾條規則:
本次居民健康體檢范圍內,乙肝患者職業多為農民,且有吸煙的生活習慣,有飲酒史生活習慣的患病概率更高。乙肝患者年齡多集中在41~60歲,且BMI指數顯示體重超重的人患乙肝的概率更高;乙肝患者有一定概率出現肝硬化、脂肪肝;乙肝與心率、血壓無明顯聯系。
由于項目中得到的數據具有一定的地域局限性,因此得到的結果僅作為一個參考,當數據量規模足夠大,各個年齡段、各種職業類別的樣本足夠多時,挖掘結果將更加具有醫學研究價值。
分布式化后的關聯規則運行在集群上和運行在單機上的傳統情況相比,執行效率有明顯提升,隨著集群節點的增加,針對相同數據量的計算,分布式系統中實現的算法加速比顯著上升,如圖3所示:
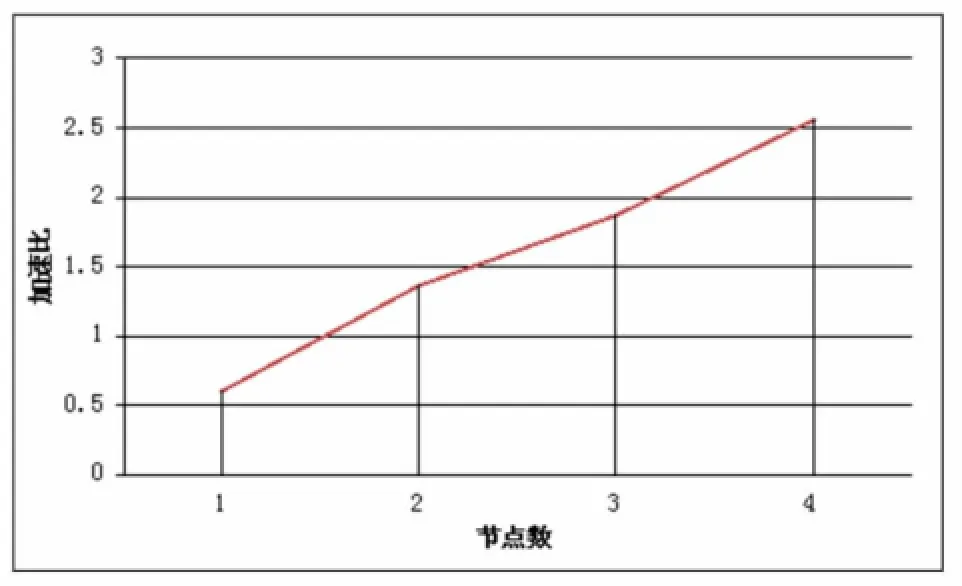
圖3
同時,針對不同的數據量大小,也在分布式Apriori算法下進行了測試,4個節點環境下執行時間對比如表1所示:
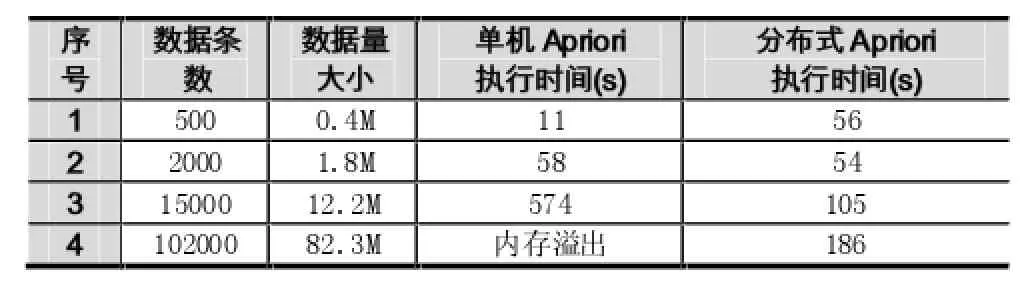
表1
傳統模式下,運行在單機上的Apriori算法瓶頸在于候選集的生成,需要占用很大的空間和時間,當算法移植到分布式平臺中,算法執行上的開銷會大大減少,并且集群中每個節點中的挖掘過程是不依賴的,減少節點間通信,使算法的效率得到了提高。當數據量龐大時,傳統單機模式的執行效率只能依賴于硬件的提升,且效果不顯著,此時,分布式平臺的高效性將更加明顯。
3 結語
通過研究Hadoop分布式平臺的技術特點,結合數據挖掘技術,給出了基于分布式的Apriori算法設計思想,并將算法實現運用在居民體檢中的乙肝患者數據,對乙肝的并發癥等進行了數據分析。實驗表明,基于分布式的數據挖掘技術在醫療數據分析領域的應用是有價值的。隨著醫院醫療數據的增加,居民對醫療健康的關注,基于分布式的數據分析能夠更大地發揮其高效性,分布式數據挖掘技術在醫療信息中的疾病診斷、治療、預測等諸多方面的研究將會被更加廣泛地應用。
[1]趙虎.云計算環境下的關聯數據挖掘算法實現[D].成都:電子科技大學,2011
[2]朱安柱.基于Hadoop的Apriori算法改進與移植的研究[D].武漢:華中科技大學,2012
[3]鄭丹青.基于數據挖掘的臨床醫療數據分析系統[J].長春工業大學學報(自然科學版),2011
[4]周云輝,王嬌.數據挖掘技術在醫療領域中的應用研究[J].機械工程與自動化,2013
[5]鄭啟龍,房明,汪勝,王向前,吳曉偉.基于MapReduce模型的并行科學計算[J].微電子學與計算機
Distributed;Apriori Algorithm;Medical Data;Data Mining
Application of Association Rules Algorithm Based on Distributed in Medical Data Mining
LI Xiao-nan1,MA Yuan-ji2,XIAO Chuan3
(1.College of Computer Science,Sichuan University,Chengdu 610065;2.West China Hospital of Sichuan University,Chengdu 610041;3.West China School of Public Health,Sichuan University,Chengdu 610041)
1007-1423(2015)08-0047-04
10.3969/j.issn.1007-1423.2015.08.011
李曉楠(1989-),女,山西應縣人,在讀碩士研究生,研究方向這計算機網絡與信息系統、醫療信息化
馬元吉(1981-),男,四川新都人,碩士研究生,講師,研究方向為病毒性肝病的基礎與臨床
肖川(1990-),女,湖南長沙人,在讀碩士研究生,研究方向為流行病學
2015-01-20
通過研究基于Hadoop平臺的map/reduce思想,針對關聯規則算法Apriori算法提出其在分布式平臺下的改進算法,利用分布式化的Apriori算法對居民體檢中發現的乙肝患者疾病數據進行分析挖掘,主要建立乙肝陽性和其他健康指標間的關聯規則。實驗結果證明關聯規則算法Apriori在醫療數據挖掘中的有效性和高效性。
分布式;Apriori算法;醫療數據;數據挖掘
國家重大科技專項(No.2012ZX10004-901)、四川省科技支撐計劃項目(No.2013SZ0002、No.2014SZ0109)
By researching on the map/reduce theory based on Hadoop distributed system,for Apriori algorithm,which is a kind of association rules algorithm,puts forward the improved algorithm in a distributed platform.Uses distributed data Apriori algorithm to analyze data of disease patients with hepatitis B which is found in healthy examination.The purpose is to establish association rules between HBV-positive and other health indicators.The results prove that the association rule mining algorithms on medical data is effectiveness and efficiency.
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
當代陜西(2019年15期)2019-09-02 01:52:00
學苑創造·A版(2018年11期)2018-02-01 06:29:20
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
