基于最小方差的自適應K-均值初始化方法
2015-10-12 02:19:08肖洋李平王鵬邱寧佳
長春理工大學學報(自然科學版) 2015年5期
關鍵詞:方法
肖洋,李平,王鵬,邱寧佳
(長春理工大學 計算機科學技術學院,長春 130022)
基于最小方差的自適應K-均值初始化方法
肖洋,李平,王鵬,邱寧佳
(長春理工大學計算機科學技術學院,長春130022)
K-均值算法對初始聚類中心敏感,聚類結果隨不同初始聚類中心波動。針對以上問題,提出一種基于最小方差的自適應K-均值初始化方法,使初始聚類中心分布在K個不同樣本密集區域,聚類結果收斂到全局最優。首先,根據樣本空間分布信息,計算樣本方差得到樣本緊密度信息,并基于樣本緊密度選出滿足條件的候選初始聚類中心;然后,對候選初始聚類中心進行處理,篩選出K個初始聚類中心。實驗證明,算法具有較高的聚類性能,對噪聲和孤立點具有較好的魯棒性,且適合對大規模數據集聚類。
聚類;K-均值;方差;初始聚類中心
數據挖掘(Data Mining)就是從大量數據中獲取有效的、新穎的、潛在有用的、最終可理解的模式的非平凡過程。數據挖掘的主要方法有分類、聚類、關聯分析、回歸分析等。其中聚類分析[1-3]在數據挖掘領域的應用最為廣泛。聚類是一種無監督的機器學習算法,通過獲取數據的內在屬性,實現對數據的分類或壓縮,使得同一類中的對象之間具有較高的相似性,不同類中的對象之間具有較高的相異性。聚類分析廣泛應用于許多研究領域,如模式識別、數據挖掘、圖像處理、市場研究、數據分析等。對于不同的問題和用戶,國內外學者研究出許多具有代表性的聚類算法,大致分為基于層次的方法、基于劃分的方法、基于網格的方法、基于密度的方法等。
K-均值是基于劃分方法的代表算法,算法思想簡單,易于實現,其實現版本廣泛應用于數據挖掘工具包中,應用范圍廣泛。可以通過修改初始化、相似性度量、算法終止條件等部分適應新的應用環境。算法使用歐式距離度量數據對象間的相似性,對噪聲和孤立點比較敏感,使得K-均值算法中需要添加去除噪聲的步驟,增加了算法的復雜性。算法對初始聚類中心特別敏感,選取不同的初始聚類中心,會使算法很大程度上收斂到不同的聚類結果。如果選取較好的初始聚類中心,按照Forgy方法進行初始劃分,即根據最近鄰方法把樣本分配到相應的初始聚類中心代表的聚簇中,將會得到全局最優的聚類結果。因此,怎樣確定有效的初始聚類中心,成為研究K-均值聚類算法的重要內容。
本文在分析K-均值算法優化初始聚類中心研究的基礎上,提出一種基于最小方差的自適應K-均值初始化方法。根據方差的定義可知,數據集中方差最小的樣本通常位于數據分布較為密集的區域,而數據較密集的區域常常是聚類中心的潛在區域。本文通過兩個步驟選取初始聚類中心。首先,根據樣本方差判斷樣本是否處于數據密集區域,若是,則把該樣本作為候選初始聚類中心,因此,可以得到一些處于數據密集區域的候選初始聚類中心;然后,對候選初始聚類中心進行篩選,選取K個聚類中心作為最終K-均值算法的初始聚類中心。在數據密集區域選取初始聚類中心,可以避免選擇噪聲或孤立點作為初始聚類中心,增強算法的抗噪性能,且該算法適合于大數據集聚類。
1 基于最小方差的自適應K-均值初始化方法
1.1相關研究
本文僅討論K-均值算法初始聚類中心選擇的方法。選擇初始聚類中心的方法隨著K-均值算法的產生而開始,最早的研究是1965年的Forgy方法。把數據集X中的每個樣本隨機分配給K個聚類,每個聚類的中心作為K個初始聚類中心,該方法缺少理論上的依據。Mac Queen提出兩種初始聚類中心選取方法。一種是把數據集X中前K個樣本作為K個初始聚類中心,該方法現應用在IBM SPSS統計軟件快速聚類的過程中,但選擇的初始聚類中心對數據輸入順序較敏感。另一種是K-均值算法廣泛使用的選取初始聚類中心的方法,即隨機選取數據集中K個樣本作為K個初始聚類中心,該方法可能會選擇噪聲或孤立點作為初始聚類中心,因此需要多次運行算法才能得到較好的聚類結果。Onoda等人[4]通過計算數據集的K個獨立成分,選擇到第i個獨立成分的余弦距離最小的樣本作為第i個初始聚類中心。文獻[5]把數據集平均分成若干等份,在每一等份上運行K-均值算法,在求出的所有聚類中心中選出相距較遠的聚類中心作為整個數據集的初始聚類中心。該方法在一定程度上克服了K-均值算法對初始聚類中心敏感的問題,但時間復雜度大,不適用大數據集聚類。文獻[6-8]根據樣本分布密度確定初始聚類中心。文獻[9]使用密度函數求出數據集的多個聚類中心,結合小類合并運算,避免算法收斂到局部最優值。對于K-均值初始聚類中心選取方法的研究已有大量的研究成果,但是沒有出現公認最好的初始聚類中心選取的方法。當數據集中存在噪聲或孤立點時,已有的方法很難選出正確的初始聚類中心。
1.2K-均值聚類算法
K-均值聚類算法的基本思想是:首先在數據集中隨機選取k個樣本作為K個初始聚類中心,根據最小距離原則,把剩余樣本分配到與其距離最近的聚類中心所代表的聚簇中,計算每個聚簇的質心作為新的聚類中心,反復迭代直到誤差平方準則函數SSE收斂。K-均值聚類算法的具體過程如下:
輸入:數據集X={x1,x2,...,xn},聚類個數K,誤差平方準則函數優化精度ξ,使用歐式距離度量樣本間的相似性。
輸出:聚類中心V,每個樣本對應的類標簽T。
(1)在數據集X中隨機選取K個樣本作為初始聚類中心V={v1,v2,...,vk}。
(2)把樣本xi分配到與其距離最小的聚類中心所代表的聚簇中,設置類別標簽為:
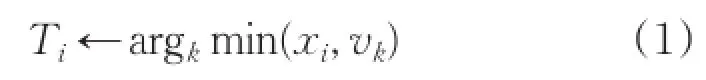
(3)計算每個聚簇的質心作為新的聚類中心;
(4)計算誤差平方準則函數:
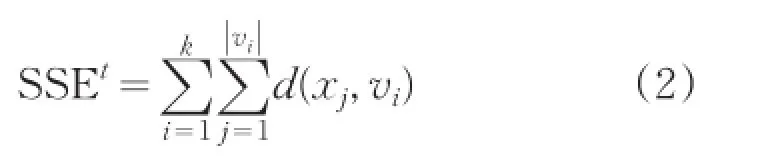
其中t是迭代次數,||vi是簇i中樣本個數。
(5)若|SSEt-1-SSEt|<ξ,算法結束,輸出V 和T,否則,設置t=t+1,轉到(2)。
1.3基于最小方差的K-均值初始化方法
聚類中心應該位于數據集的密集區域,所以能夠代表相應的類簇。但是數據的密集性并沒有一個數學上的定義,而只是一個直觀的概念。本文引入樣本方差的概念,得到樣本緊密度信息,進而發現位于數據密集區域的樣本,然后對數據密集區域的樣本進行處理,選出K個樣本,作為K個初始聚類中心。
定義1:設數據集 X={xi|i=1,2,...,n},其中xi∈Rd,樣本xi的方差定義為:
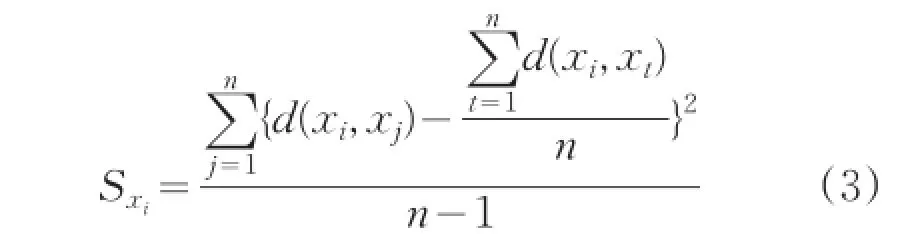
其中d(xi,xj)是xi和xj之間的距離,計算公式為:
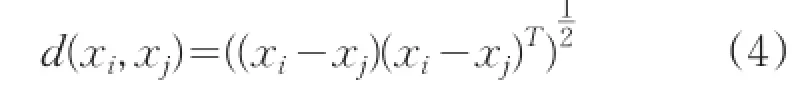
由上述定義可知,如果樣本xi的方差越小,說明xi周圍分布的數據越密集。反之,則說明xi周圍分布的數據越稀疏。這與直觀的數據密度相符。設定一個閾值?,如果樣本xi的方差小于?,則認為樣本xi處于某種程度的數據密集區域,因此,可以把樣本xi作為候選初始聚類中心。這是本文提出基于最小方差的自適應K-均值初始化方法的思想來源。本文提出的選取初始聚類中心的方法分為兩個過程:首先,依據樣本方差的定義,將方差小于閾值?的樣本作為候選初始聚類中心,使用自適應方法,設置合適的閾值,使得候選初始聚類中心Vh的個數M多于給定的聚類個數K;然后,從候選初始聚類中心集Vh中選擇方差最小的樣本作為第一個判斷中心,選擇距離已有判斷中心最遠的樣本作為下一個判斷中心,直到選出K個判斷中心,K個判斷中心代表K個聚簇,按照最小距離原則,把候選初始聚類中心內其余樣本分配到距離最近的K個聚簇中,更新每個簇的質心,重復該過程,直到聚簇中心不再變化,此時的K個聚簇中心就是本文算法得到的K個初始聚類中心。

圖1 算法流程圖
算法流程圖如圖1所示。根據方差的定義可知,計算n個樣本方差的時間復雜度為O(n2),本文算法應用到大數據集時,通過對大數據集進行采樣和降維操作,依然可以選擇合理的初始聚類中心,進而降低時間復雜度。實驗證明本文算法適合于大數據集聚類。數據集中噪聲或孤立點的方差較大,且遠遠大于閾值,引入樣本方差的概念選取候選初始聚類中心,使算法對噪聲和孤立點具有較強的魯棒性。測試數據集如表1所示。
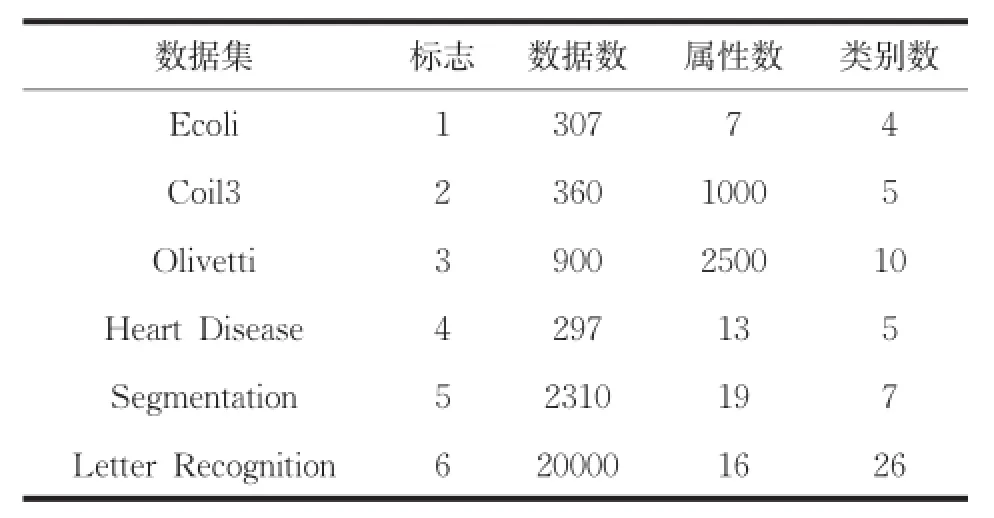
表1 測試數據集
2 實驗結果與分析
硬件運行環境是Intel CPU,2.99G內存,931G硬盤;軟件運行環境是WindowsXP操作系統,Visual Studio 2013開發平臺,算法使用C++作為編程語言。使用UCI中的標準數據作為測試數據,如表1所示。在測試數據上分別100次運行本文算法(A1),傳統K-均值算法(A2),K-Means++算法(A3),比較各個評價指標的均值。使用五個性能評價指標,驗證本文算法的有效性,五個指標分別為:
(1)起始誤差平方和(First SSE):度量選擇的初始聚類中心的有效性,其值等于選出的初始聚類中心對應的誤差平方和,值越小,說明選出的初始聚類中心越接近正確值。
(2)終止誤差平方和(Last SSE):度量選擇的初始聚類中心對整個聚類過程的有效性,其值等于聚類終止時對應的誤差平方和,值越小,說明本文算法有效性越高。如表2所示。
(3)運行時間(Time):度量整個聚類過程所用的時間。
(4)Jaccard系數,使用正確聚類的樣本占屬于同一類簇的樣本的比例評價聚類結果。
(5)Adjusted Rand Index參數,用來衡量聚類結果與數據的外部標準類之間的一致程度。
算法在測試數據集上的起始誤差平方和(First SSE)和終止誤差平方和(Last SSE)比較結果如表2所示。運行總時間如表3所示。圖2是算法聚類結果的Jaccard系數比較。圖3是算法聚類結果的Adjusted Rand Index參數比較。
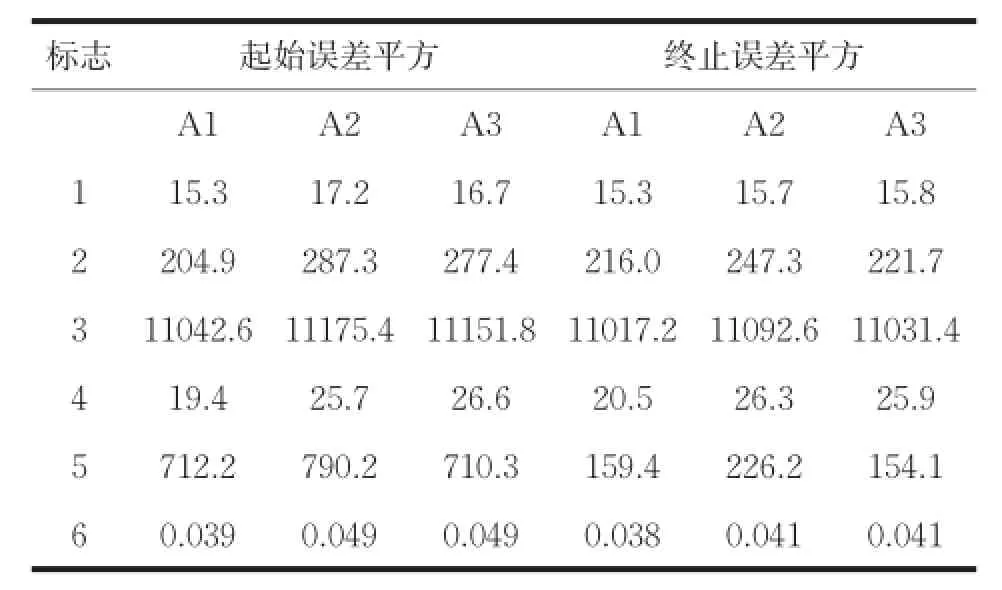
表2 起始誤差平方和終止誤差平方
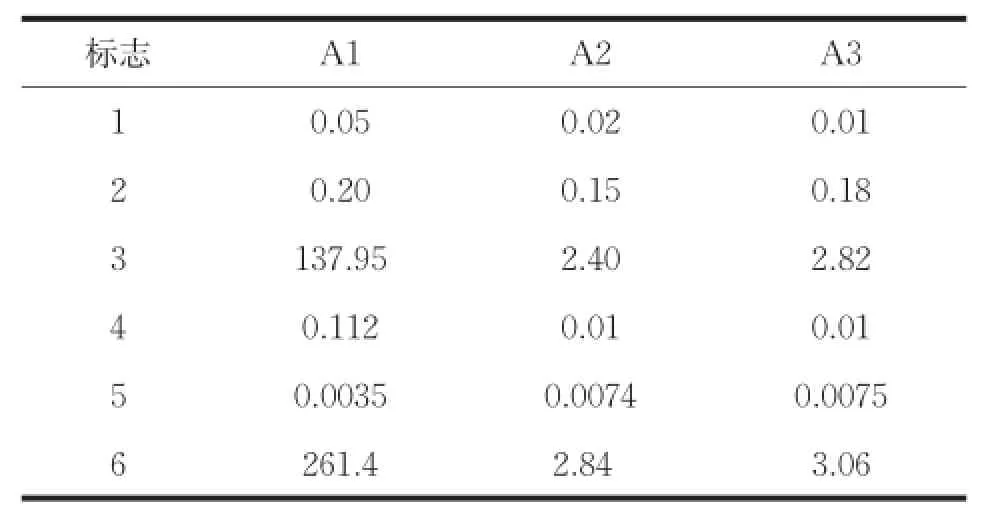
表3 運行時間
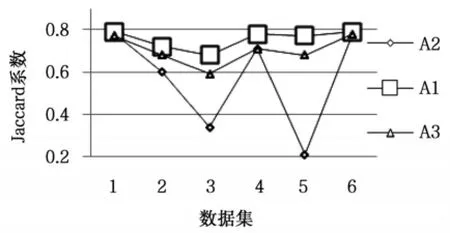
圖2 Adjusted Rand Index參數比較
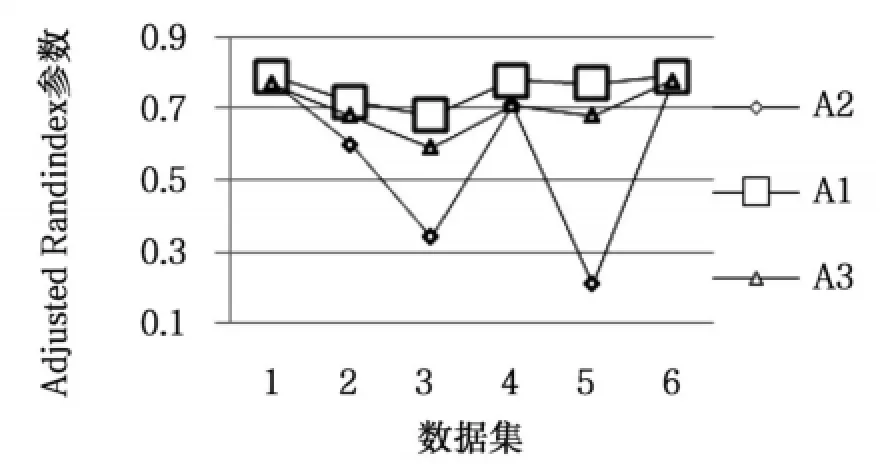
圖3 Jaccard系數比較
從表2可以看出,本文算法在所有數據集上的起始誤差平方和與終止誤差平方和的值最小,選擇的初始聚類中心與K-均值算法聚類之后的聚類中心間的距離最小。由圖2和圖3可知,在所有數據集上,本文算法聚類結果的各評價指標最大,在數據集Ecoli和Letter Recognition上三種算法聚類結果的評價指標比較接近,在數據集Olivetti和Segmentation上,本文算法與K-均值算法聚類結果的評價指標相差最大。其中在數據集Segmentation上,本文算法的聚類誤差平方和高于K-Means++算法,但聚類評價指標均低于K-Means++算法,說明數據集Segmentation的真實分布情況是類內數據間的緊密性較弱。以上對比結果可知,本文算法優于其它兩種算法,對K-均值算法的初始化具有很好的指導意義,提高了K-均值算法的聚類性能。本文算法引入樣本方差的概念選取初始聚類中心,而計算樣本方差是一個O(n2)時間復雜度的過程,由表3可知,本文算法的時間消耗高于其它算法,對大數據集聚類時,通過采樣和降維操作,可以降低本文算法的時間復雜度且不影響算法聚類性能。
本文算法使用歐式距離度量樣本間的相似度,若兩個樣本對應屬性的取值差異較大,則這兩個樣本間的距離較大。即屬性取值差異的大小,直接影響樣本間距離的大小。基于以上思想,對大數據集聚類時,首先對大數據集進行采樣操作,然后排除數據集中取值范圍較小的屬性(降維操作),最后使用本文算法進行初始聚類中心的選取。為了證明對大數據集進行采樣和降維操作,不影響本文算法的有效性。使用不同的采樣率對數據集Olivetti和Letter Recognition進行采樣,采樣之后本文算法的聚類結果如表4所示。其中采樣率為1/2表示隨機選取原數據集的1/2進行初始聚類中心的選取。把數據集Olivetti和Letter Recognition中的屬性按照取值范圍由大到小降序排列,使用不同比例值進行降維。降維之后本文算法的聚類結果如表5所示。其中比例值1/2表示降序排列后選擇前1/2部分屬性進行初始聚類中心的選取。
由表4可知,使用不同采樣率,起始誤差平方和與終止誤差平方和的變化量非常小,但是運行時間卻大幅度減少。由表5可知,數據集3的維數較大,比例值低于1/9時,起始和終止誤差平方和出現略微變化,數據集5的維數較小,比例值低于1/2時,起始和終止誤差平方和出現略微變化。為了減小本文算法對大數據集聚類的時間復雜度,且不影響聚類效果,使用不同的采樣率對數據進行采樣,設置比例值為1/2對數據進行降維,然后使用本文算法選取初始聚類中心,聚類結果如表6所示。由表6可知,同時對大數據集進行采樣和降維,加大了聚類時間減小幅度,且不影響聚類效果。比例值為1/2對數據進行降維,適合數據集3的采樣率為1/5~1/10,適合數據集6的采樣率為1/6~1/2。實驗證明本文算法適合對大數據集聚類。
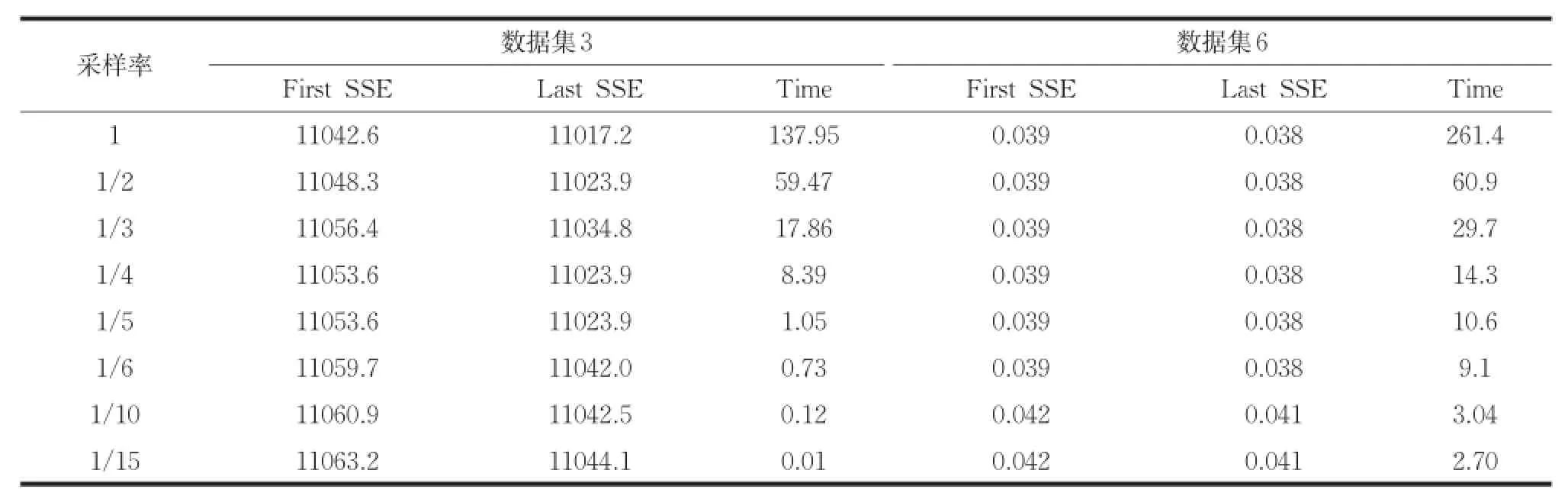
表4 采樣數據的聚類結果

表5 降維數據的聚類結果

表6 采樣和1/2降維數據的聚類結果
3 結論
本文提出基于最小方差的自適應K-均值初始化方法,可以發現數據集中較密集的區域,使選擇的初始聚類中心均分布在數據密集區域,進而保證初始聚類中心的準確性;算法可以避免選取噪聲或孤立點作為初始聚類中心,提升聚類性能;算法思想簡單,容易實現,且適合于大數據集聚類。
[1] Yu H,Li Z,Yao N.Research on optimization method for K-Means clustering algorithm[J].Journal of Chinese Computer Systems,2012,33(10):2273-2277.
[2] 倪巍偉,陳耿,崇志宏,等.面向聚類的數據隱藏發布研究[J].計算機研究與發展,2012,49(5):1095-1104.
[3] 韓忠明,陳妮,張慧,等.一種非對稱距離下的層次聚類算法[J].模式識別與人工智能,2014,27(5):410-416.
[4]OnodaT,SakaiM,YamadaS.CarefulSeeding Method based on Independent Components AnalysisforK-meansClustering[J].JournalofEmerging Technologies in Web Intelligence,2012,4(1):51-59.
[5] 韓曉紅,胡彧.K-means聚類算法研究[J].太原理工大學學報,2009,40(3):236-239.
[6]Lai Yuxia,Liu Jianping.Optimization study on initial centerofK-meansalgorithm[J].ComputerEngineering and Applications,2008,44(10):147-149.
[7] Han Lingbo,Wang Qiang,Jiang Zhengfeng.Improved K-means initial clustering center selection algorithm[J].Computer Engineering and Applications,2010,46 (17):150-152.
[8]汪中,劉貴全,陳恩紅.一種優化初始中心點的K-Means算法[J].模式識別與人工智能,2009,22(2):299-304.
[9] Mao Shaoyang,Li Kenli.Research of optimal K-means initialclusteringcenter[J].ComputerEngineering and Applications,2007,43(22):179-181.
An Adaptive K-means Initialization Method Based on Minimum Deviation
XIAO Yang,LI Ping,WANG Peng,QIU Ningjia
(School of Computer Science and Technology,Changchun University of Science and Technology,Changchun 130022)
K-means algorithm is sensitive to the initial cluster center;fluctuation of clustering results are following with different initial cluster centers.To solve these problems,in this paper,an adaptive K-means initialization method is proposed based on minimum variance;the initial clustering center is distributed in the K different sample density regions,clustering results of convergence to the global optimum.Firstly,according to the information of the space distribution of samples,the information of samples close degree is got by calculation of sample variance.In addition,based on samples close degree the qualified candidate initial cluster centers is selected;Then,the candidate initial cluster centers are dealt with and k initial cluster centers are filtered.The experiment proved that this algorithm has high clustering performance and good robustness for processing of the noise and the isolated point;it is suitable for clustering the large-scale data set.
clustering;K-means;deviation;initialized clustering centers
TP391
A
1672-9870(2015)05-0140-05
2015-03-30
肖洋(1989-),男,碩士研究生,E-mail:978996354@qq.com
李平(1958-),女,教授,E-mail:liping@cust.edu.cn
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
