利用最佳相似日的光伏電站短期出力預測
2015-10-12 06:40:18郭宇杰袁曉玲李昌明劉皓明
電力需求側管理 2015年6期
關鍵詞:水平
郭宇杰,袁曉玲,李昌明,劉皓明
(1.河海大學 能源與電氣學院,南京 211100;2.中利騰暉光伏科技有限公司,江蘇 常熟 215500)
◆研究與探討◆
利用最佳相似日的光伏電站短期出力預測
郭宇杰1,袁曉玲1,李昌明2,劉皓明1
(1.河海大學 能源與電氣學院,南京211100;2.中利騰暉光伏科技有限公司,江蘇 常熟215500)
光伏發電系統的輸出功率易受輻照、溫度等環境因素影響,其輸出功率具有較大的波動性和隨機性,并網時對電網的調度、保護等方面將產生較大影響,因此光伏發電出力預測研究逐漸發展,尤其是在短期、超短期出力高精度預測方面的研究[1]。光伏電站的出力預測方法主要可歸納為2類:直接預測法和間接預測法。直接預測法是直接對光伏發電系統的輸出功率進行預測;間接預測法首先對地表太陽輻照強度進行預測,然后根據光伏發電系統的出力模型得到系統的輸出功率[2]。直接預測法較間接預測法相對簡單,因此研究更為廣泛。而在采用直接預測法之前,先對樣本數據進行預處理,選出與預測日最為接近的歷史日作為其相似日。文獻[3]運用歐氏距離公式比較預測日與各歷史日的氣象因素的差異度,選取差異度較小的歷史日作為預測日的相似日。文獻[4]利用灰色關聯系數法,綜合各個氣象因素的關聯系數,得到預測日與各歷史日的關聯度,選取相似度最大的歷史日作為預測日的相似日。歐氏距離法反映的是各樣本空間距離的遠近,關聯度反映的是樣本間的線性關系,即曲線形狀的相似性。而實際情況中,若只考慮其中一種關系,對預測日選擇相似日容易造成較大誤差,進而影響光伏發電功率的預測精度。
本文利用加權歐氏距離法和相關系數法分別得到歷史樣本的出力水平相似日集和曲線形狀相似日集,判別預測日分別所屬相似日集,取二者交集得最佳相似日。選取預測日的最佳相似日作為預測模型輸入樣本,采用神經網絡算法實現光伏電站短期出力預測。
1 最佳相似日
所謂相似日是指和預測日的天氣情況最接近的歷史樣本,本文采用2種不同的聚類函數:加權歐氏距離法和相關系數法對光伏電站歷史樣本進行分類,考慮各歷史樣本間出力的距離關系和曲線形狀關系,對樣本進行合理分類,取2種聚類集合的交
1.1出力水平相似日集
出力水平相似日集是指光伏出力曲線距離相距較小的集合,若采用傳統歐氏距離法作為聚類函數,樣本中各對象對樣本的影響程度的差異會被忽略。基于此方面的考慮,本文采用加權歐氏距離以提高聚類精度。
在對歷史樣本進行出力水平相似日聚類時,各樣本對象為經過量化的每日天氣類型、最高溫度和最低溫度的環境因素數據,給定環境樣本集合X={X1,…,Xn,…,XN},其中Xn=[Xn1,…,Xnm,…XnM],N為樣本數量,M為各樣本的對象數,這里M=3。給定光伏電站出力P={P1,…,PN},則自變量Xm對因變量P的偏相關因數rXm→P如式(1)所示[5]式中:-Pn為歷史樣本平均值;-PCk為歷史樣本聚類中心平均值。
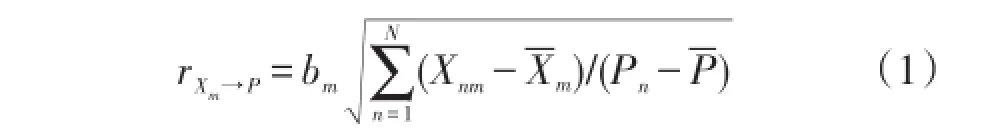
式中:bm為偏回歸系數;-Xm和-P分別為環境因素和光伏電站出力樣本的平均值。
根據各自變量的偏相關因數可得各自變量對因變量的影響權重ωm,如式(2)所示
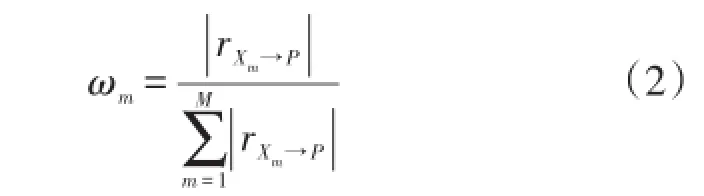
給定聚類中心集合XC={XC1,…,XCk,…,XCK},其中XCk=[XCk1,…,XCkm,…,XCkM],K為聚類中心數量。引入權值ω=[ω1,…,ωm,…,ωM],則聚類中心XCk與各樣本Xn間的距離可表示為
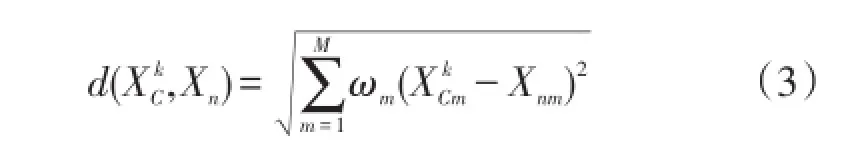
1.2曲線形狀相似日集
樣本曲線形狀相似是指光伏出力曲線變化趨勢相近,采用相關系數法對歷史樣本進行聚類[6]。設某歷史樣本出力為Pn=[Pn1,…,Pnl,…,PnL],歷史樣本聚類中心為PCk=[PCk1,…,PCkl,…,PCkL],l=1,2,…,L,本文中L是指每天光伏電站出力采集點總數,則歷史樣本與聚類中心的相關系數如式(4)所示集為最佳相似日。
1.3最佳相似日的確定
當出力水平相似日集與曲線形狀相似日集確定分類數后,對2個集合中各子集求取對應環境因素聚類中心,根據式(3)求出預測日與2個集合中各子集環境因素聚類中心的距離矩陣分別為D1和D2,按距離最小原則分別確定其所屬兩大集合中的2個子集,二者的交集所對應的歷史樣本作為預測日的最佳相似日。
2 K?means聚類算法
K?means聚類算法是一種基于劃分的經典聚類方法,其核心思想是把數據劃分為相似度最高的K類,而其主要存的問題如下:①隨機選取初始聚類中心易導致選中噪聲數據或孤立點,使得算法迭代次數增多,算法運行時間增長,同時也會使算法陷入局部極值;②算法自身無法判定最優聚類數[7]。針對這2個問題,本文通過密度指標選取K?means聚類算法的初始聚類中心,最終確定最大初始聚類數K0;通過WCBCR值確定出力水平相似日與曲線形狀形似日的最優聚類數K*[10]。
2.1初始聚類中心的選取
為改善K?means聚類算法效果,本文基于密度指標確定K?means聚類算法的初始聚類中心。定義數據X密度指標T1,如式(5)所示[8]
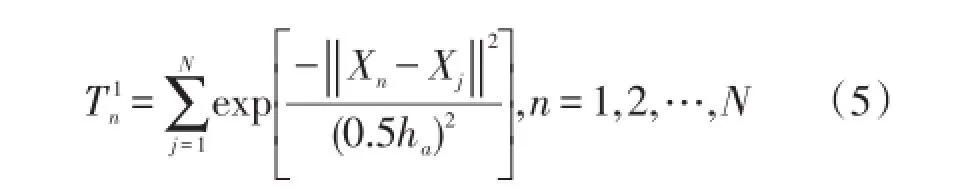
式中:“‖‖·”表示向量的模;ha為一正數,其取值如式(6)所示
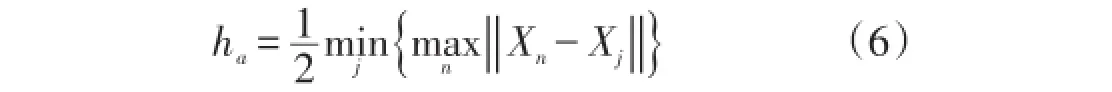
根據最大值原則,將密度指標{Tn
1}(n=1,2,…,N)中最大的數據對應的樣本記為Xn1,并將其作為第1個初始聚類中心,記作XC1,對應的密度指標記為TC1。
第k-1個聚類中心確定后,運用式(7)對余下N-k+1個樣本數據(已去除Xn1,…,Xn,k-1)再進行密度指標計算

式中:為避免距離過近的聚類中心出現,取h=1.5h[8]。
同樣根據最大值原則,從余下的N-k+1個樣本數據中選取第k個聚類中心XCk,對應的密度指標記為TCk。
通過上述?公式計算密?度指標選取對應聚類中心,直到滿足≥δ且<δ時結束。研究表明,δ≥0.5時,可得到合理分類數[9]。通過以上計算可以得到最大初始聚類數為K0,此時對應出力水平相似日和曲線形狀相似日的1×K0維密度指標向量分別記為TC1和TC2。
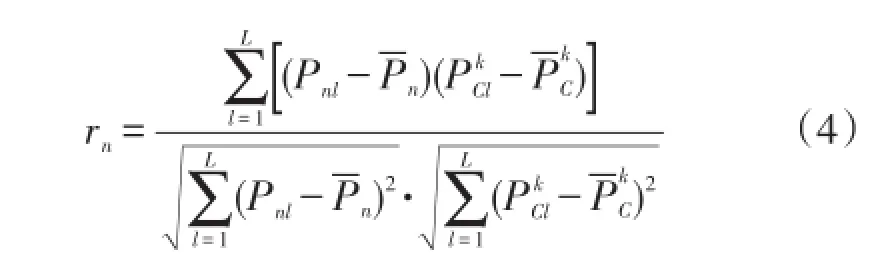
2.2最優聚類數的確定
本文選取預測日的最佳相似日時,選用K?means聚類算法作為基礎,取式(3)和式(4)作為聚類函數,采用WCBCR聚類指標作為評價函數確定最優聚類數。WCBCR值定義為組內距離平方和與組間距離平方和的比值式中:Ωk為第k類數據集。
WCBCR聚類指標值越小,說明聚類效果越好[10],但過小的聚類指標值可能會導致聚類集合為空集的情況,因此,最優聚類數K*對應著不存在空集下的最小WCBCR指標。
3 仿真與分析
3.1實驗數據與計算
為驗證本文的預測方法,收集某光伏電站2014年1月到12月的發電數據和當地氣象站發布的環境數據。其中,發電數據為每天6:00~17:00每間隔15 min的采樣值;環境因素包括:天氣類型、最高溫度和最低溫度。選取天氣類型分別為晴天、雨天和陰轉多云的3個典型日作為預測日,經過篩選最終分別確定為8月1日、8月13日和8月21日。
首先進行出力水平相似日選擇。根據式(1)和式(2)求得每日天氣類型、最高溫度和最低溫度對出力的權值為ω=[0.52,0.43,0.05],然后再根據2.1節得到出力水平相似日和曲線形狀相似日的最大初始聚類數K0都為9,對應出力水平相似日密度指標TC1=[94.60,94.48,94.21,93.42,92.11,89.09,81.93,68.57,48.11],曲線形狀相似日密度指標TC2=[47.67,47.64,47.56,47.31,46.70,44.85,41.35,35.01,24.11]。
將式(3)代入K?means聚類算法中,分類結果如表1所示。比較分類數為2至8的WCBCR值,雖然逐漸減小但減幅不大,而當分類數為9時,WCBCR值出現較大幅度降低,這是因為此時聚類子集中出現空樣本集現象。式(8)中WCBCR計算表達式分母多加1項其值明顯變大,而分子幾乎不變,導致WCBCR值大幅減小。因此,確定出力水平相似日集最優聚類數K*=8。曲線形狀相似日選擇過程與出力水平相似日類似,但K?means聚類算法中聚類函數及樣本變量不同,使用的是式(4)及歷史日各時刻的出力大小。通過WCBCR值判斷,曲線形狀相似日集最優聚類數K*=6。

表1 2種相似日的聚類結果
當出力水平相似日集聚類數為8類時,3個預測日與出力水平相似日集各子集的距離矩陣D1為

同理,當曲線形狀相似日集聚類數為6類時,3個預測日與曲線形狀相似日集各子集的距離矩陣D2為

選取2個矩陣中各行向量最小值對應的子集,各預測日對應2個子集的交集作為最佳相似日。需要說明的是,不同天氣類型的預測日所對應的出力水平相似日與曲線形狀相似日的交集中的樣本數量一般不同,對于天氣環境比較一致的如晴天,一般交集樣本較多,本文在交集中選取日期與預測日最接近的5個樣本作為最佳相似日。
3.2預測模型數據
本文選取3層BP神經網絡[11]作為出力預測模型,輸入量選取最佳相似日中與預測日相似度最大的5日出力和環境數據及預測日的環境數據,輸出量為預測日6:00~17:00每間隔15 min的發電功率。BP神經網絡隱含層為單層,隱含層的節點數根據經驗選為19個[12]。
3.3預測結果與誤差分析
分別使用曲線形狀相似日、出力水平相似日和最佳相似日3種方法選取預測模型的輸入量進行預測,對3種天氣類型的預測日預測結果如圖1—圖3所示。
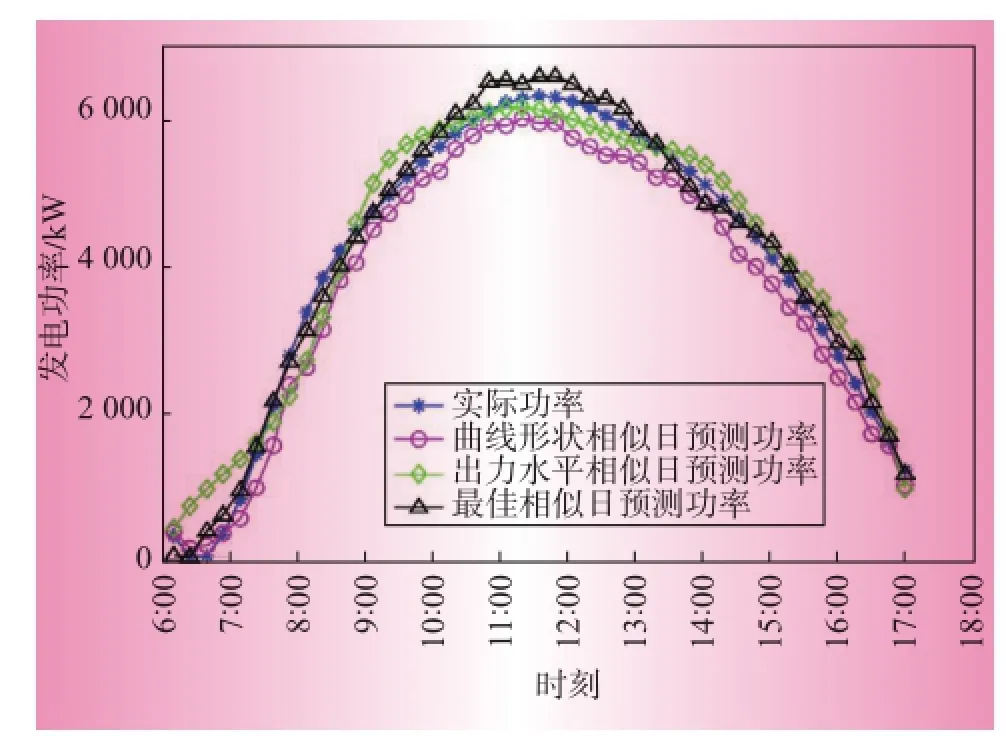
圖1 晴天光伏功率預測結果對比曲線
圖1是晴天的出力對比圖。由于晴天環境因素比較穩定,光伏電站輸出功率相對穩定,3種方法都有較高的預測精度。圖2和圖3分別是雨天和陰轉多云的出力預測對比圖,由于這2種天氣類型下太陽輻照波動較大,光伏電站輸出功率變化較為劇烈且規則性不強,相對而言,最佳相似日選擇法比曲線形狀相似日和出力水平相似日具有更好的精度。為了清晰對比預測效果,采用平均絕對百分誤差(MAPE,mean absolute percentage error)和均方根誤差(RMSE,root mean square error)對預測效果進行分析,結果如表2所示。
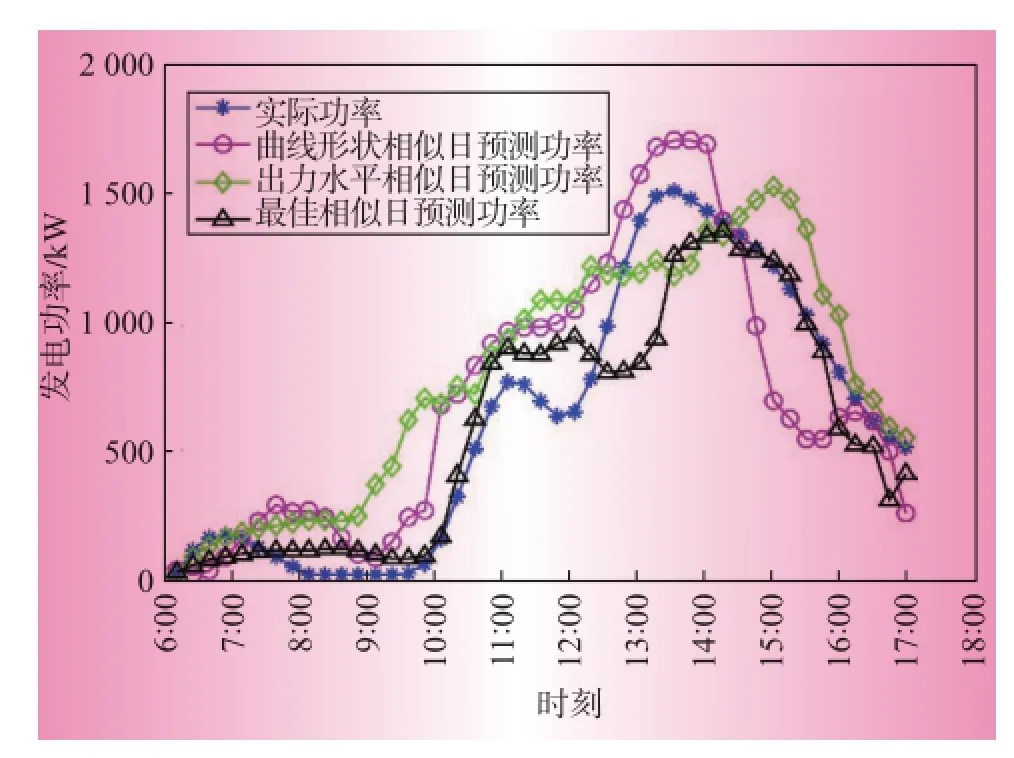
圖2 雨天光伏功率預測結果對比曲線
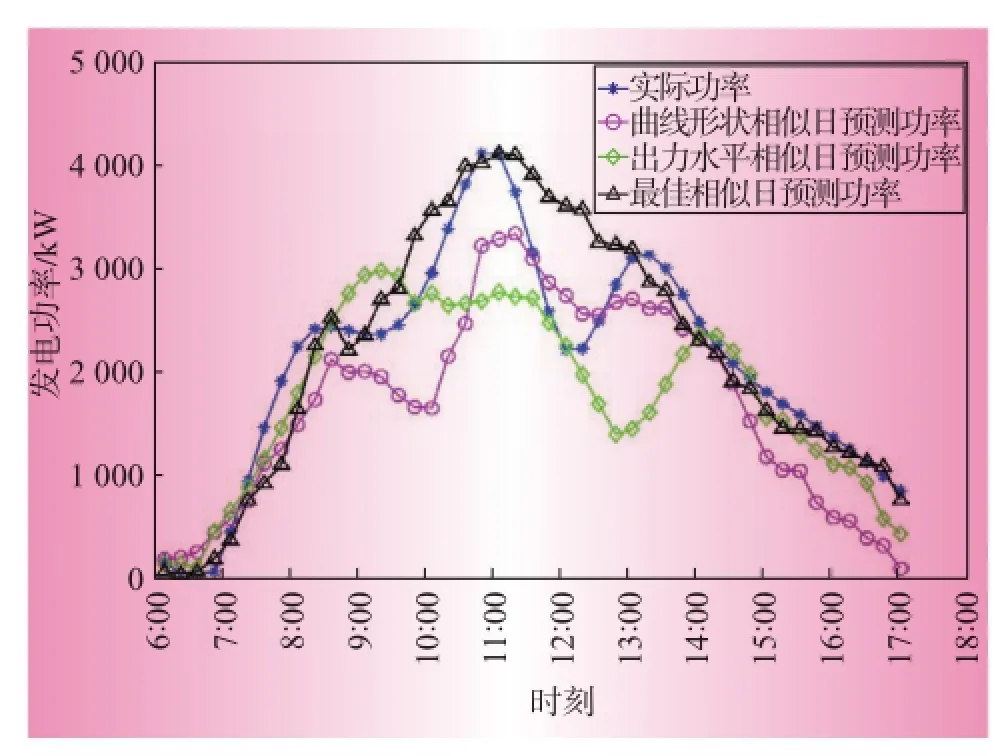
圖3 陰轉多云光伏功率預測結果對比曲線

表2 3種天氣類型的預測日出力預測誤差%
4 結論
為了利用已有數據準確預測光伏電站出力,對各類數據的預處理至關重要。本文結合出力水平相似日選取與曲線形狀相似日選取2種方法,由其交集確定最佳相似日集,保證了相似日在距離大小和形狀關系上的最大相似度。分別將出力水平相似日、曲線形狀相似日和最佳相似日作為神經網絡預測模型的輸入量,通過實測數據仿真對比分析,驗證了所提基于最佳相似日預測方法的優勢。D
[1]Chen Changsong,Duan Shanxu,Cai Tao,et a1.Online 24 h solar power forecasting based on weather type classification using artificial neural network[J].Solar Energy,2011,85(11):2 856-2 870.
[2]Yuehui Huang,Jing Lu,Xiaoyuan Xu,et a1.Comparative study of power forecasting methods for PV stations[C]∥IEEE Conferences on Power System Technology.Hangzhou,China:2010:1-6.
[3] 李建紅,陳國平,葛鵬江,等.基于相似日理論的光伏發電系統輸出功率預測[J].華東電力,2012,40(1):153-157.
[4] 王曉蘭,葛鵬江.基于相似日和徑向基函數神經網絡的光伏陣列輸出功率預測[J].電力自動化設備,2013,33(1):100-103.
[5] 白俊良,梅華威.改進相似度的模糊聚類算法在光伏陣列短期功率預測中的應用[J].電力系統保護與控制,2014,42(6):84-90.
[6] 康重慶,夏清,劉梅.電力系統負荷預測[M].北京:中國電力出版社,2007.
[7] 李飛,薛彬,黃亞樓.初始中心優化的K?means聚類算法[J].計算機科學,2002,29(7):94-96.
[8] 孫謙,姚建剛,趙俊,等.基于最優交集相似日選取的短期母線負荷綜合預測[J].中國電機工程學報,2013,33(4):126-134.
[9]Nikhil R P,Chakraborty D.Mountain and subtractive clustering method:Improvements and generalizations[J].International JournalofIntelligentSystems,2000,15(4):329-341.
[10]George J Tsekouras,Nikos D Hatziargyriou,Evangelos N Dialynas.Two?Stage pattern recognition of load curves for classification of electricity customers[J].IEEE Transactions on Power System,2007,22(3):1 120-1 128.
[11] 陳昌松,段善旭,殷進軍.基于神經網絡的光伏陣列發電預測模型的設計[J].電工技術學報,2009,24(9):153-158.
[12] 袁曉玲,施俊華,徐杰彥.計及天氣類型指數的光伏發電短期出力預測[J].中國電機工程學報,2013,33(34):57-64.
Short?term forecasting for photovoltaic power generation based on optimal similar set
GUO Yu?jie1,YUAN Xiao?ling1,LI Chang?ming2,LIU Hao?ming1
(1.College of Energy and Electrical Engineering,Hohai University,Nanjing 211100,China;2.Zhongli Talesun Science and Technology Co.,Ltd.,Changshu 215500,China)
提出一種基于最佳相似日的光伏電站短期出力預測方法。該方法利用密度指標確定初始聚類中心優化K?means聚類算法,采用加權歐式距離法獲得歷史樣本的出力水平相似日集,采用相關系數法獲得歷史樣本的曲線形狀相似日集,確定預測日出力水平相似日集和曲線形狀相似日集,選取兩集合的交集樣本作為最佳相似日。建立BP神經網絡出力預測模型,采用光伏電站的實測數據訓練預測模型,對比不同類型天氣的預測結果與實測數據,表明論文的預測方法具有較高的預測精度。
光伏發電;短期出力預測;出力水平相似;曲線形狀相似;最佳相似日
This paper proposes a short?term power forecasting method for photovoltaic generation based on optimal similar days. Density index is adopted to choose the initial clustering centers to op?timize K?means algorithm.Weighted Euclidean distance is used to get power generation level set of historical samples.Correlation coeffi?cient is used to get power generation shape set of historical samples. The intersection set of power level and power shape is the optimal similar set.Forecast model of BP neural network is constructed and trained by operation data from photovaltaic power station.Forecast re?sults reveal that the proposed method has high accuracy by compar?ing the forecast results and operation data in different type weathers.
photovoltaic generation;short?term power genera?tion forecasting;similar power generation level;similar power genera?tion shape;optimal similar set
TM615.2
B
2015-06-27;
2015-09-14
國家自然科學基金項目(51207044)
郭宇杰(1990),女,江蘇靖江人,碩士研究生,研究方向為光伏發電出力預測;袁曉玲(1971),女,安徽巢湖人,博士,副教授,從事新能源發電技術的研究及教學工作。李昌明(1983),男,江西萍鄉人,電氣工程師,從事光伏電站研發及運營管理;劉皓明(1977),男,江蘇鹽城人,博士,副教授,研究方向為智能電網、電力系統伏壓運行和電力市場。
猜你喜歡
美與時代·美術學刊(2022年3期)2022-04-27 01:18:15
火花(2019年12期)2019-12-26 01:00:28
人大建設(2019年6期)2019-10-08 08:55:48
人大建設(2019年12期)2019-05-21 02:55:32
雜文月刊(2018年21期)2019-01-05 05:55:28
人大建設(2017年6期)2017-09-26 11:50:44
學苑創造·A版(2015年11期)2016-01-14 09:03:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
中國火炬(2010年12期)2010-07-25 13:26:22
中國火炬(2010年8期)2010-07-25 11:34:30
