日語文本語料庫的開發(fā)與利用
2015-11-21 11:38:00耿治萌鐘春琳劉玉琴
中國教育信息化 2015年1期
關(guān)鍵詞:數(shù)據(jù)庫文本
耿治萌,鐘春琳,劉玉琴
(大連理工大學(xué) 軟件學(xué)院,遼寧 大連116621)
日語文本語料庫的開發(fā)與利用
耿治萌,鐘春琳,劉玉琴
(大連理工大學(xué) 軟件學(xué)院,遼寧 大連116621)
大連理工大學(xué)軟件學(xué)院日語實驗室創(chuàng)建的日語文本語料庫JTCH(Japanese TextCorpusHandler)利用sen日語分詞技術(shù),以NHK、朝日新聞為主要文章數(shù)據(jù)來源,通過一系列搜索算法,對文章進行句子分析、數(shù)據(jù)分析和統(tǒng)計處理。為日語學(xué)習(xí)、教學(xué)以及科研提供了具有例句查找、數(shù)據(jù)統(tǒng)計和語句分析等多種功能的學(xué)習(xí)平臺。
文本語料庫;數(shù)據(jù)分析;日語分詞;日語搜索
一、引言
隨著日語學(xué)習(xí)者的增多以及ICT(Information Communication Technology)技術(shù)的飛速發(fā)展,計算機網(wǎng)絡(luò)技術(shù)對外語學(xué)習(xí)的輔助作用受到高度重視。傳統(tǒng)的依靠人工積累進行例句分析,已經(jīng)不能滿足學(xué)習(xí)者對句子的質(zhì)與量的要求,其準(zhǔn)確性及真實性無法得到保障。
語料庫是指在隨機采樣基礎(chǔ)上收集的有代表性的真實語言材料的集合,是語言運用的樣本 (楊慧中,2002)。如果樣本具有代表性,采樣具有隨機性,且樣本的量又足夠大,則可以認為,樣本就是總體的真實代表;樣本具有總體的統(tǒng)計特征,研究真正實際使用的語言材料更能體現(xiàn)日本文化和了解標(biāo)準(zhǔn)日本語。日語本族語料庫具有代表性的是日本國立研究所(http://nlb.ninjal.ac.jp/)。其中包含句子104,805,763條,涵蓋了經(jīng)濟、文化、政治等多個方面,有各類書籍;提供前后搭配詞頻統(tǒng)計的查詢方法。雖然數(shù)據(jù)庫數(shù)據(jù)龐大,但是因為功能較少,造成數(shù)據(jù)并沒有被充分利用;現(xiàn)代日語書面語均衡語料庫(BCCWJ)的目標(biāo)是構(gòu)筑一個均衡語料庫,為使用者提供覆蓋面廣、代表性強、數(shù)量充足、能夠全面反映現(xiàn)代日語書面語使用狀況的語言樣本(毛文偉,2011)。BCCWJ包含17萬余本各類日本書籍(文學(xué)類書籍偏多),提供了兩款網(wǎng)上檢索工具,分別為“少納言”和“中納言”。前者不需注冊,但僅提供了字符串檢索功能;后者功能更加齊備,不過需要用戶注冊。“中納言”提供三種語料檢索方式,分別有短單位、長單位和以無長度限制字符串為單位。但是,由于BCCWJ功能較少,不能為日語學(xué)習(xí)者提供更高的查詢要求。
綜上,目前日本文本語料庫的建設(shè)與應(yīng)用,僅有日本本土的日本國立研究所和日本中納言 (https://chunagon. ninjal.ac.jp)。由于地域原因以及文化差異,中國的日語學(xué)習(xí)者在使用過程中總是無法得心應(yīng)手。
大連理工大學(xué)軟件學(xué)院日語實驗室創(chuàng)建的日語文本語料庫(以下簡稱JTCH),作為日語學(xué)習(xí)、教學(xué)以及日語研究的平臺,提供各種搜索模式,輔助日語學(xué)習(xí)者通過大量的、原汁原味的日語例句習(xí)得日語語法、詞匯,并通過各種統(tǒng)計功能了解日語語言的邏輯思維模式。
JTCH加載和存儲NHK和朝日新聞的文章 (2012-2014),包括32萬個例句、4萬篇文章的解析。
二、日語文本語料庫建設(shè)
1.系統(tǒng)概述
(1)文本語料庫創(chuàng)建模塊
網(wǎng)絡(luò)爬蟲將NHK各地的新聞按照地域,將朝日新聞按照類別下載到本地數(shù)據(jù)庫,同時自動生成標(biāo)簽、分句。
(2)功能模塊
主要提供單一查詢(單一精確詞匯查詢、模糊查詢、多詞查詢)、搭配查詢(指定位置、前后搭配、前后詞性)兩大模塊查詢。此外還有句子分析和接續(xù)詞統(tǒng)計模塊。詳見圖1。
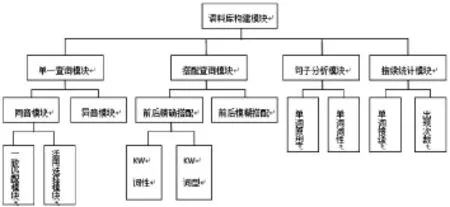
圖1 功能模塊
單一查詢中單一精確詞匯查詢是指用戶輸入關(guān)鍵詞是什么,便查詢出含有該關(guān)鍵詞的句子。例如 「ある」:28日午後2時半ごろ、愛知県犬山市の日本モンキーパークの遊園地にある「スカイダンボ」という空中ゴンドラの1臺が、地上から5mほどの高さで突然動かなくなり、後続のゴンドラも次々に停まりました。
模糊查詢是指根據(jù)關(guān)鍵詞,用戶自己選擇關(guān)鍵詞的活用類型,或者全部活用,查詢出含有該關(guān)鍵詞所有活用的句子。例如「ある」則查詢出包含ある所有變型使用例句。
多詞查詢是特別針對一些一種詞有多種寫法的情況,從而根據(jù)用戶輸入多個關(guān)鍵詞,查詢出含有每個關(guān)鍵詞的句子,例如「茶||お茶」。
搭配查詢中的指定位置是指用戶自己限定關(guān)鍵詞的前三或者后三個詞匯位置的詞語或者詞性,來滿足更高的搜索要求。例如「食べる」我們可以指定該關(guān)鍵詞前兩個位置為名詞,從而得到“リンゴを食べていいです”等例句。
前后搭配和前后詞性是指用戶僅限定某個詞語或者詞性在關(guān)鍵詞的前邊或者后邊,而不去關(guān)注在前幾后幾,從而查出想要的結(jié)果。例如「食べる」我們限定它前邊有「リンゴ」,則所有關(guān)于「食べる」前邊帶有「リンゴ」的句子都會出現(xiàn)。如:①戀なんて卒業(yè)毒リンゴ 食べてみたい。②リンゴをおいしそうに食べている。③リンゴを食べていいです。
詞頻統(tǒng)計是指根據(jù)用戶輸入的關(guān)鍵詞,我們經(jīng)過算法分析接續(xù)詞的出現(xiàn)頻率最高的前10個詞匯,例如「ある」「ある」+「た」出現(xiàn)的次數(shù)最多,為14次;「ある」+「よう」頻率為10次,依次類推,顯示排名前10的結(jié)果。
2.開發(fā)相關(guān)技術(shù)
(1)創(chuàng)建,處理模塊
為了使數(shù)據(jù)庫管理更加方便,以Mysql數(shù)據(jù)庫作為數(shù)據(jù)管理工具,基于Navicat formysql的輔助以日本信賴度很高的NHK(http://www.nhk.or.jp/lnews/)和朝日新聞(http://www.asahi.com)為數(shù)據(jù)來源。因為這兩個主流網(wǎng)站包含的數(shù)據(jù)量龐大(每天每個網(wǎng)站更新200篇文章左右),并且具有實時性和準(zhǔn)確性。
創(chuàng)建語料庫利用了java的多線程編程;httpclient、jsoup、ibatis實現(xiàn)了網(wǎng)站到j(luò)ava代碼到數(shù)據(jù)庫的連接。具體創(chuàng)建過程如下:
①通過httpclient的API調(diào)用實現(xiàn)主頁加載,對加載獲得的主頁進行分析,獲取關(guān)于文章的URL。
②通過URL,再次訪問網(wǎng)絡(luò),將加載每篇文章,這里我們使用線程池技術(shù)避免了大量的資源占用,同時減輕CPU的負擔(dān)。
③通過jsoup提供的解析功能對得到的每一個文章頁面進行解析。得到我們希望得到的相關(guān)數(shù)據(jù),例如文章title、content、url、type、author等信息。這些信息我們用article的類進行封裝。
④使用iBATIS工具進一步處理。將數(shù)據(jù)庫中的id設(shè)置為自增長型,將文章分解為一個個的sentence存到數(shù)據(jù)庫中,每個sentence中都保留了文章的id和在文章中的位置。
⑤文章分類問題
語料庫的類別在對語料庫的研究中也起著關(guān)鍵性的作用,我們對朝日新聞和NHK的文章分類如下。朝日新聞:スポーツ、社會、國際、経済、政治、サイエンス、カルチャー、教育テック&サイエンス等;NHK由于主要使各個地方的新聞匯聚在一起,所以它是按照地域分類的,由于地方較多,不一一列舉,我們選擇在搜索的時候?qū)⒌赜蛘故窘o讀者,以方便了解地域文化和地域差異。
⑥定時器
每天晚上12點網(wǎng)絡(luò)爬蟲開始工作,下載數(shù)據(jù)。
(2)各檢索模塊功能實現(xiàn)
為了提高搜索速度,第一版文本語料庫采用的是Lucene作為一個全文檢索引擎,雖然lucene檢索引擎具有很多優(yōu)點,但是由于要和數(shù)據(jù)庫進行連接,數(shù)據(jù)庫是在傳統(tǒng)硬盤中進行存儲,硬盤檢索速度和內(nèi)存檢索速度相比,仍然有著幾千倍的速度差,所以我們考慮將數(shù)據(jù)讀入內(nèi)存來提高檢索速度。傳統(tǒng)的數(shù)據(jù)庫只是用來進行文本存儲,更新和備份使用。
通過序列化形式將文章和句子加載到內(nèi)存中,直接在內(nèi)存中對文章和句子進行檢索,檢索并不是每一條挨著查找,而是創(chuàng)建合適的索引,在我們的文本語料庫中選擇以每個日語詞匯的基本型為key,value表示詞匯出現(xiàn)句子的id,在檢索時首先通過對索引的檢索,來減少檢索次數(shù),提高速率。
依靠sen工具將一個句子分成發(fā)音、原型、分詞以及變形,實現(xiàn)對日語句子或者文章進行分析。首先把句子的每個詞分解出來,然后對每個詞進行詞性(屬于哪一類詞、哪種變形等)、基本型、發(fā)音、平假名寫法、在句子中的位置等做出解析,同時也能統(tǒng)計出句子長度。
日語文本語料庫正是在sen工具包(簡稱sen)的基礎(chǔ)上,通過對sen的二次開發(fā),實現(xiàn)對日語文本語料庫進行分析和查詢。
在大量數(shù)據(jù)的基礎(chǔ)上,通過sen進行數(shù)據(jù)解析,然后對數(shù)據(jù)再分析,從而查詢到需要的結(jié)果。
(3)句子分析和語料分析
通過sen分詞技術(shù)對用戶輸入的語料(短語、句子、文章)進行詞法、語法、詞頻等方面的分析和統(tǒng)計。詞頻統(tǒng)計是針對關(guān)鍵詞的各種后續(xù)搭配出現(xiàn)的頻率及數(shù)目進行統(tǒng)計,并顯示具體例句。算法主要是利用排序算法和sen本身帶有的數(shù)據(jù)統(tǒng)計功能。
(4)界面部分功能展示(見圖2)

圖2 界面功能圖
三、今后的課題
我們所開發(fā)的文本語料庫還只是日語語料庫中的冰山一角,伴隨算法的進一步完善,如何使查詢速度有更大的提高,面對將來可能的數(shù)千萬計的數(shù)據(jù)又該如何處理,這些都將是我們今后研究的課題。
(1)召集一些有想法有能力并且熱衷于研究的學(xué)生參與到我們的項目中,增加和完善文本語料庫的功能,美化界面,簡化操作。
(2)增加語料庫內(nèi)容的豐富性,使語料包含更多的信息。
(3)對語料庫數(shù)據(jù)進行整體分析,而不是局限于某個詞語,從而分析出日本當(dāng)前關(guān)注點在哪里,了解日本各方面的發(fā)展趨勢。
(4)在學(xué)習(xí)和研究的過程中,及時對使用者的使用情況進行反饋,不斷改進系統(tǒng)的不足,使系統(tǒng)愈加完善,盡可能滿足用戶的使用。
四、結(jié)束語
系統(tǒng)開發(fā)的過程是艱難而又充滿挑戰(zhàn)的,經(jīng)過7個月的研究開發(fā),目前文本語料庫已經(jīng)基本成型,需求分析的所有功能基本實現(xiàn),并且在算法優(yōu)化、數(shù)據(jù)穩(wěn)定以及網(wǎng)絡(luò)支持方面都有較好的突破。
良好的平臺設(shè)計和技術(shù)支持,為更大數(shù)據(jù)量的語料提供了堅實的基礎(chǔ)。截至發(fā)稿日,日語語料庫已有文章41026篇,語料庫的語料容量大、代表性強,為日語學(xué)習(xí)者提供了強有力的支持。
[1]楊慧中.語料庫語言學(xué)導(dǎo)論[M].上海:上海外語教育出版社,2002.
[2]譚晶華,毛文偉.中國日語學(xué)習(xí)者語料庫CLJC建設(shè)及應(yīng)用綜述[J].日語學(xué)習(xí)與研究,2011(4):23-29.
(編輯:王天鵬)
TP311
A
1673-8454(2015)01-0058-03
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
財經(jīng)(2017年15期)2017-07-03 22:40:49
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
