以主觀線索為特征的主觀性文本識別
2015-12-20 06:51:38劉勇華李愛萍段利國王鴻翔
計算機工程與設計 2015年9期
劉勇華,李愛萍,段利國,邸 鵬,王鴻翔
(太原理工大學 計算機科學與技術學院,山西 太原030024)
0 引 言
文本情感分析的前提是對文本中主觀成分的識別和提取。例如:在文本情感分析中[1],處理的文本類型就是主觀性文本。事先對文本進行主觀性判別是很有必要的,不僅可以有效地減少分析的范圍,還可以提高分析的速度和精確度。主觀文本識別主要有兩種方法,基于詞典和基于統計。基于詞典的方法利用事先建立的情感詞典 (可以人工標注或是機器統計),統計文本中的詞語是否含有情感,再進一步判別文本主客觀性[2],這種方法非常依賴情感詞典。基于統計的方法利用訓練好的數據模型,采用機器學習的方法,對待測文本進行判別[3]。常用的機器學習方法有:樸素貝葉斯 (NB)、支持向量機 (SVM)、決策樹、K最近鄰、最大熵模型等。這種方法在訓練數據的標注、特征選取、分類器的選取等方面具有一定的局限性。目前,學者們為了得到更高的準確率和更快的分類效率,大多數采用基于詞典和基于統計相結合的方法進行文本主觀識別[4-6,9-11]。針 對 包 含 豐 富 情 感 信 息 的 主 觀 線 索 研 究 還 較 少,比如復雜句式的關聯詞特征研究較為缺乏。因此,本文將關聯詞、情感詞以及指示性動詞、感嘆詞、程度副詞、帶有情感色彩的標點符號等6種主觀線索成分作為分類特征,建立主觀線索特征詞表,用樸素貝葉斯分類器對文本的主客觀性進行判別。
1 相關知識
1.1 主客觀文本定義
(1)主觀性文本是指作者對于非事實的描述的文本,通常帶有一定的個人情感色彩。主觀性文本主要分為兩類:評價和推測[4]。
目前,主客觀文本分類方面,主要是針對評價型的文本進行研究。例如:“我認為iPhone挺好,值得擁有。”。
(2)客 觀 性 文 本 定 義 請 參 見 文 獻 [5]。例 如:“iPhone4永遠是一部經典,無法超越。”。
中文主觀性文本和客觀性文本之間存在很大的區別,主觀性文本一般表達人們的情感、看法或是態度,表達的形式也是多樣化,不是規范型的文本,時常出現不規范的詞語和結構等。主觀性文本識別主要以情感詞為主,利用各種文本特征表示方法和分類器 (一般采用樸素貝葉斯分類器)進行分類識別[7]。
1.2 文本分類過程
文本分類過程如圖1所示。

圖1 文本分類過程
其中預處理環節包含中文分詞、分句、去停用詞等過程。特征表示包括特征選擇、特征提取及特征值計算。
1.3 樸素貝葉斯
樸素貝葉斯(Naive Bayes,NB)定義請參見文獻[4]。
對需測試文本D= {T1,T2,…,Tn},由于NB是基于特征相互獨立的假設下,判別其屬于主觀、客觀類別C={CS,CO},分類算法如式 (1)所示

其中,P(Cj)表示類別Cj的先驗概率,P(Ti,Cj)表示特征Ti出現在類別Cj中的后驗概率。
先驗概率P(Cj)的計算公式如式 (2)所示
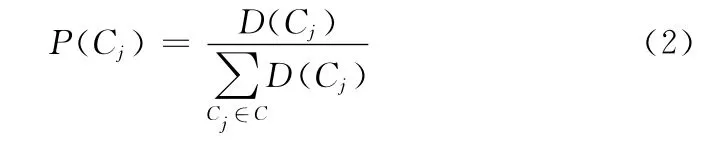
式中:D(Cj)——類別Cj中的文本數。
后驗概率P(Ti,Cj)是特征Ti出現在類別Cj中的概率,并且為防止0概率的出現進行平滑調整,計算公式如式 (3)所示
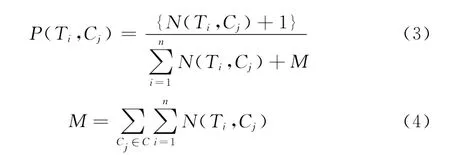
其中,P(Ti,Cj)為特征項Ti在類別Cj的文本中出現的次數,式 (4)中M 為特征項Ti在所有類別的文本中出現的次數總和。
2 主觀線索特征
主觀線索特征包括情感詞、第一或第二人稱代詞、不規范的標點符號、帶有情感色彩的標點符號、感嘆詞、程度副詞、發表看法或意見的動詞 (指示性動詞)、不精確的數字或日期、關聯詞等9種特征。本文選取關聯詞、情感詞以及與指示性動詞、感嘆詞、程度副詞、帶有情感色彩的標點符號等6種主觀線索特征作為主觀性文本識別依據。下面具體介紹每種特征以及特征提取算法。
2.1 情感詞
具有情感的詞的統稱為情感詞,以帶有情感的動詞和形容詞居多。當人們陳述的句子中出現正、負面的情感詞語或評價詞語時,這個句子是主觀句的可能性很大。例如:“我喜歡iPhone。”、“iPhone外觀好看。”。本文所用的情感詞是HowNet情感分析用詞語集中中文正負面情感詞語和正負面評價詞語,其分布情況見表1。

表1 情感詞分布情況
算法1:情感詞提取算法
輸入:給定的文本D
輸出:情感詞集合q
步驟1 對給定的文本分句、分詞并進行詞性標注處理后得到文本特征詞序列集合
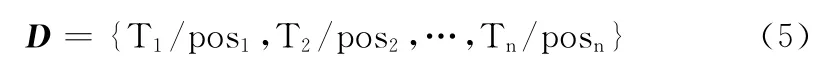
步驟2 利用HowNet情感分析用詞語集中中文正負面情感詞語和正負面評價詞語建立情感詞表Q,Q 可用如式(6)表示
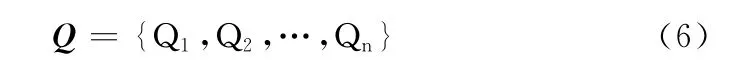
步驟3 利用建立好的情感詞表Q 統計給定的文本D中的情感詞,得到情感詞集合q
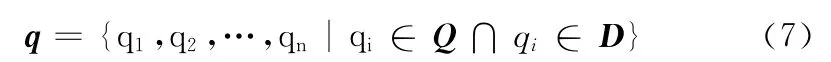
2.2 指示性動詞
當人們對于某種事物表述自己的觀點或態度時,往往會采用一些諸如 “感覺”、 “認為”等一類的主張詞語,并且這些主張詞語往往會伴隨第一、第二和第三人稱代詞一起出現,那么這一類的句子是主觀句的可能性很大。例如:“我感覺iPhone真心不錯,你值得擁有。”。本文使用的指示性動詞是HowNet情感分析用詞語集中中文主張詞語,其分布情況見表2。

表2 指示性動詞分布情況
算法2:指示性動詞提取算法輸入:給定的文本D
輸出:指示性動詞集合z
步驟1 與算法1的步驟1相同;
步驟2 利用HowNet情感分析用詞語集中中文主張詞語建立指示性動詞表Z,Z 可用如式 (8)表示
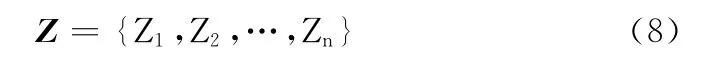
步驟3 利用建立好的指示性動詞表Z 統計給定的文本D 中的指示性動詞,得到指示性動詞集合z
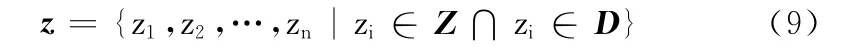
2.3 感嘆詞
感嘆詞是用于表達各種感情的詞,它與后面句子的其余成分沒有語法聯系,并且能更好地幫助人們表達自身的情感傾向。當某個句子中出現 “啊”、“哎呀”、“天呀”等的感嘆詞時,這個句子很可能是主觀句。例如:“哎呀,我把iPhone落家了。”。本文通過對訓練語料中大量主觀性文本的觀察與研究,統計出適合主觀性文本識別的感嘆詞,具體分布情況見表3。
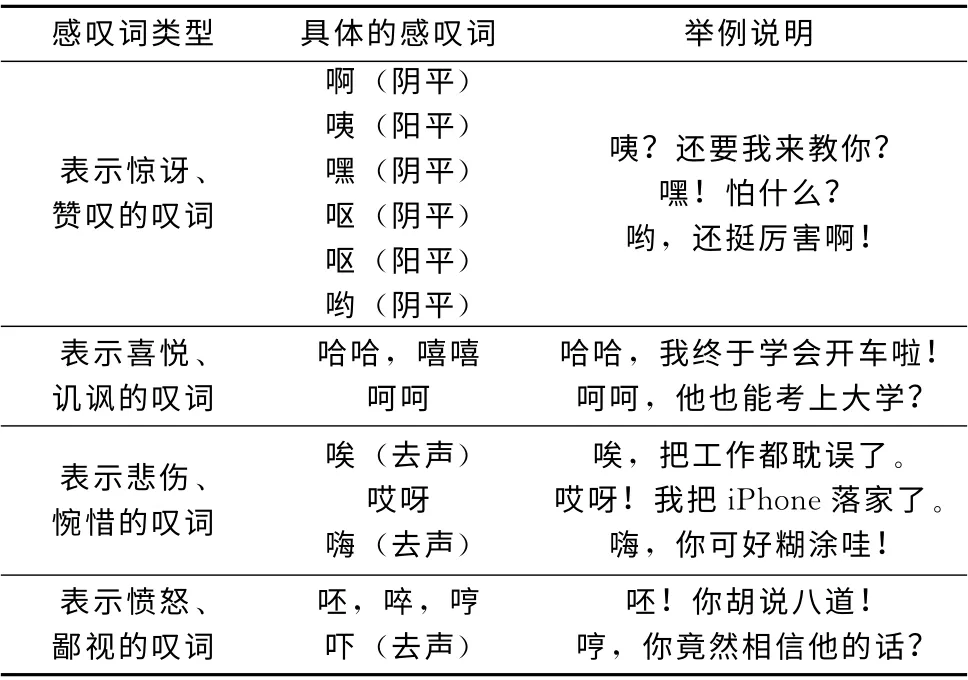
表3 感嘆詞分布情況
算法3:感嘆詞提取算法
輸入:給定的文本D
輸出:感嘆詞集合g
步驟1 與算法1的步驟1相同;
步驟2 通過對訓練語料中大量主觀性文本的觀察與研究,統計出適合主觀性文本識別的感嘆詞,建立感嘆詞表G,G 可用如式 (10)表示
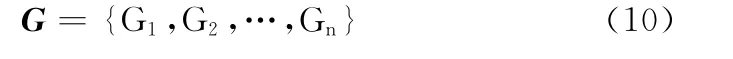
步驟3 利用建立好的感嘆詞表G 統計給定的文本D中的感嘆詞,得到感嘆詞集合g
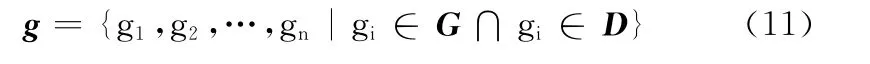
2.4 程度副詞
通常,人們為了增強自己表達的情感,往往會使用一些程度副詞加以修飾。當某個句子中含有如 “非常”、“很”、“相當”等之類的程度副詞時,這個句子是主觀句的可能性很大。例如: “iPhone性能相當好,我非常喜歡。”。本文使用的程度副詞是HowNet情感分析用詞語集中中文程度級別詞語,具體的分布情況見表4。
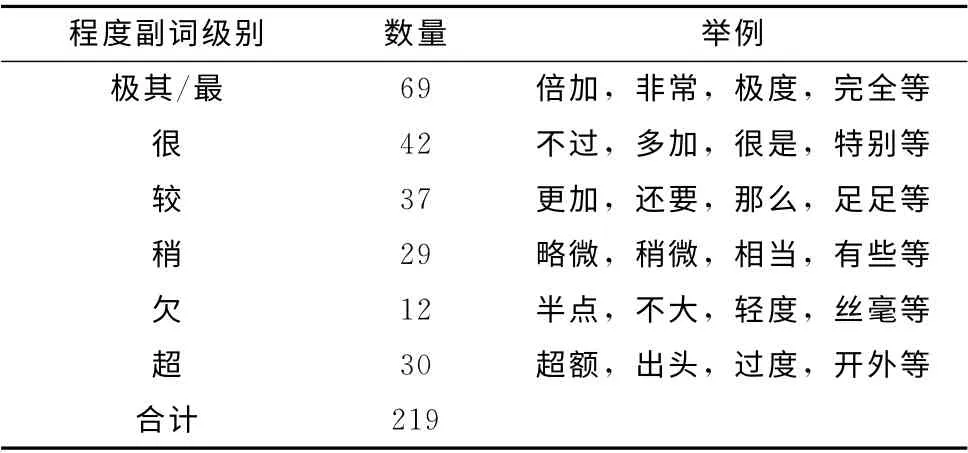
表4 程度副詞分布情況
算法4:程度副詞提取算法
輸入:給定的文本D
輸出:程度副詞集合cd
步驟1 與算法1的步驟1相同
步驟2 利用HowNet情感分析用詞語集中中文程度級別詞語建立程度副詞表CD,CD 可用如式 (12)表示
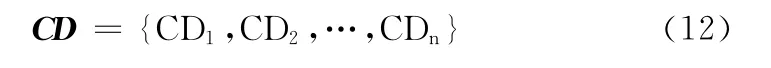
步驟3 利用建立好的程度副詞表CD 統計給定的文本D 中的程度副詞,得到程度副詞集合cd
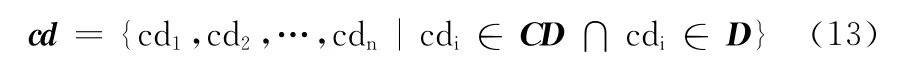
2.5 帶有情感色彩的標點符號
句子中問號的出現表示人們在質疑某事物,帶有不確定性;而感嘆號的出現則表示人們對事物吃驚、喜悅、嘆息等的態度,帶有一定的情感。這兩種標點符號都能表達人們內心的情感。由于這兩者在主觀性文本中出現頻率居多,很少在客觀性文本中出現,因此,本文將帶有情感色彩的標點符號作為識別主觀性文本的一種特征。例如:“iPhone各個方面都挺好,難道你不想擁有一部嗎?”、“iPhone音質真好!”。而在有些句子中經常會出現問號、感嘆號連用的現象,表達更為強烈的情感,例如:“iPhone各個方面都挺好,難道你不想擁有一部嗎???”、“iPhone音質真好!!!”。本文通過對訓練語料中大量主觀性文本的觀察與研究,統計出適合主觀性文本識別的帶有情感色彩的標點符號,具體分布見表5。
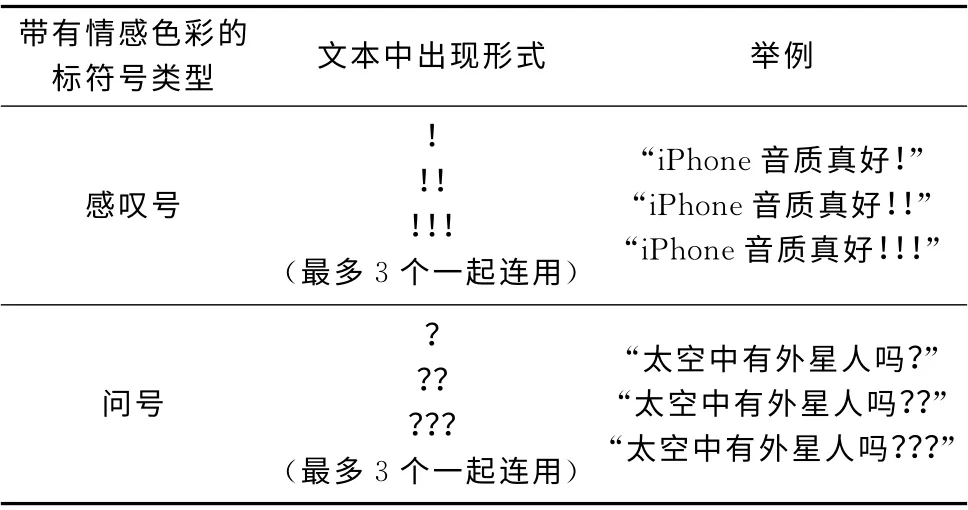
表5 帶有情感色彩的標點符號分布情況
算法5:帶有情感色彩的標點符號提取算法
輸入:給定的文本D
輸出:帶有情感色彩的標點符號集合bd
步驟1 與算法1的步驟1相同
步驟2 通過對訓練語料中大量主觀性文本的觀察與研究,統計出適合主觀性文本識別的帶有情感色彩的標點符號,建立帶有情感色彩的標點符號表BD,BD 可用如式(14)表示
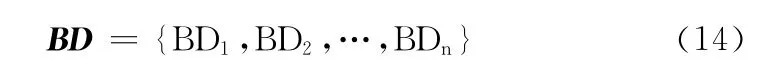
步驟3 利用建立好的帶有情感色彩的標點符號表BD統計給定的文本D 中的帶有情感色彩的標點符號,得到帶有情感色彩的標點符號集合bd
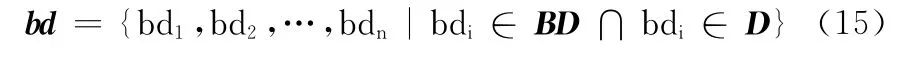
2.6 關聯詞
復句、分句的定義請參見文獻 [8]。本文研究的是以關聯詞所表示的復句類型,關聯詞表達人的邏輯認知,具有一定的主觀性。人們對于客觀事實根據自己所要表達的意思來選擇用或不用關聯詞、用哪一種關聯詞,這種選擇性表達就是一種主觀性。
本文從以下兩個方面來分析關聯詞語的主觀性:
(1)文章中關聯詞的使用率:本文選擇中國經濟網的時政新聞 《外交部:越南沖擊我警戒區及船只1416艘次》、九九文章網的影評書評 《〈水煮三國〉讀后感》兩篇文章為代表分析關聯詞的主觀性。通過對文章中的句子總數、復句數、關聯詞組數進行統計,分析關聯詞對主觀句的影響,結果見表6。
由表6的統計結果可知,在新聞體裁的文章中復句的使用率很高,而關聯詞的使用率較低;在書評體裁的文章中,復句的使用率相對比較低,而關聯詞的使用率卻很高。新聞體裁的文章講述的是客觀事實,一般比較客觀;書評體裁的文章是評價型的文章,一般帶有作者的觀點、態度或是意見,主觀性比較強。從上述兩種體裁關聯詞的使用來看,比較客觀的文體關聯詞的使用率低,主觀性強的文本關聯詞的使用率較高。由此可得,關聯詞對主觀性的表達具有一定的影響。
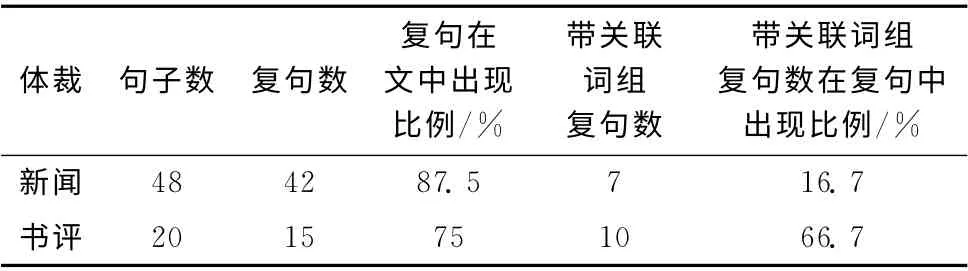
表6 兩文章中復句和關聯詞組使用比例
(2)對同一客觀事實使用不同的關聯詞:對于同一個客觀事實,表達的方式可以使用單句,還可以使用復句,其中復句可以是關聯詞的復句,也可以不使用關聯詞。對于同一個客觀事實,想要表達不同的主觀認知,就會使用不同的關聯詞。比如對于客觀事實 “天陰了,要下雨”,沒有關聯詞的連接就是一個表達客觀事實的復句,而使用不同的關聯詞將其連接就構成了不同類型的復句:
因為天陰了,所以要下雨。
不僅天陰了,而且要下雨。
只有天陰了,才要下雨。
如果天陰了,就要下雨。
上述例句涉及4 種類型的復句,分別是因果、遞進、條件、假設關系的復句。利用關聯詞,可以使分句間的意義關系明確地表達出來。換句話說,句子中本來就包含分句間的意義關系,而使用關聯詞之后使分句間的邏輯關系更加凸顯出來。對于同一客觀事實來說,理論上只存在一種意義關系,在使用不同的關聯詞連接后卻表達了不同的意義。由此可以說明關聯詞帶有一定的主觀性。
綜上所述,關聯詞的使用一般會帶有使用者的主觀邏輯認知,對主觀句的識別具有一定的作用。本文通過對訓練語料中大量主觀性文本的觀察與研究,統計出適合主觀性文本識別的關聯詞。一般來說,文本中的關聯詞都是成對出現,常用的關聯詞分布情況見表7。
算法6:關聯詞提取算法
輸入:給定的文本D
輸出:關聯詞集合gl
步驟1 與算法1的步驟1相同
步驟2 通過對訓練語料中大量主觀性文本的觀察與研究,統計出適合主觀性文本識別的關聯詞,建立關聯詞表GL,GL 可用如式 (16)表示
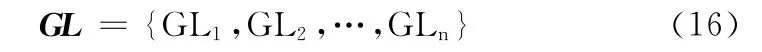
步驟3 利用建立好的關聯詞表GL 統計給定的文本D中的關聯詞,得到關聯詞集合gl

表7 常用關聯詞分布情況
上述論述特征對主觀句具有一定的識別作用,本文利用這6種特征建立一個主觀線索特征詞表ZG,如式 (18)所示,將主觀線索特征詞表ZG 中包含的各個特征作為識別主觀性文本的特征,再利用樸素貝葉斯分類器進行主觀性文本識別
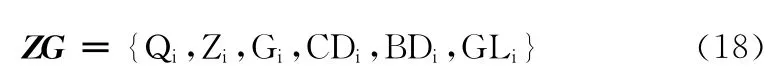
3 實驗及實驗結果分析
3.1 實驗語料庫
本文實驗數據采用了2008年中文傾向性分析評測提供的 中 文 語 料 集COAE2008。COAE2008 (Chinese opinion analysis evaluation,COAE2008)語料集是第一屆中文傾向性分析評測的訓練語料,由中科院計算所和洛陽外國語學院共同整理和標注完成,近40000 篇文本,其中具有觀點傾向性文本數量超過4000 篇,語料涉及的領域有影視娛樂、財經、教育、房產、電腦、手機等領域的網頁,提取后整理成txt純文本形式,文章從幾個句子到上百個句子不等。
本文利用主觀線索特征詞表中包含的各個特征作為主觀文本識別特征,通過人工標注篩選的方法,從COAE2008語料集中選取主觀性和客觀性明確的文本各500個,其中300個主觀文本和300個客觀文本作為訓練數據,另外的200個主觀文本和200 個客觀文本作為測試數據。表8為訓練和測試數據的分布情況。

表8 訓練和測試數據分布情況
3.2 實驗步驟
(1)數據預處理:本文利用哈工大社會計算與信息檢索研究中心編制的語言技術平臺 (LTP)分句工具對數據進行分句,中科院計算機所編制的中文分詞 (ICTCLAS)工具對數據進行分詞,再借助停用詞表去停用詞。
(2)特征表示:特征表示包括特征選擇、提取及其值的計算,常用的特征提取算法有信息增益、文檔頻率、CHI統計、相對熵和互信息等。本文利用文檔頻率的方法對主觀性文本進行特征提取,將文本向量化表示,具體步驟如下:
步驟1 對給定的文本分句、分詞并進行詞性標注處理后,得到文本特征詞序列集合,形式如式 (19)所示
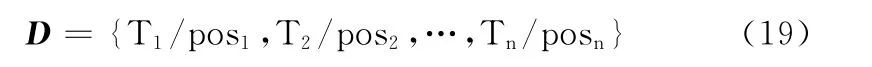
其中,Ti為特征詞,posi為特征詞的詞性。
步驟2 利用主觀線索詞表ZG 統計文本中各個特征出現的次數,得到主管線索特征集合X
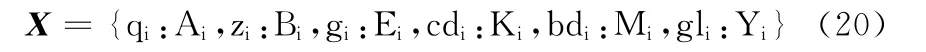
其中,i=1,2,…,n,Ai,Bi,Ei,Ki,Mi,Yi分別表示特征qi,zi,gi,cdi,bdi,gli出現的次數。
步驟3 利用文檔頻率的方法分別計算P(qi),P(zi),P(gi),P(cdi),P(bdi),P(gli)計算公式如式 (21)所示

其中,N 為文本中所有特征數總和,由于P(qi),P(zi),P(gi),P(cdi),P(bdi),P(gli)計算方法一樣,計算時只需將式 (21)的分子替換成其它主觀線索特征出現的次數。步驟4 將文本向量化表示成式 (22)所示的形式
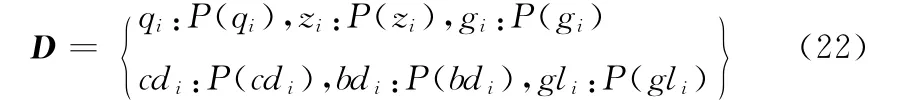
(3)訓練分類器:利用向量化的訓練數據訓練樸素貝葉斯分類器,生成分類模型。
(4)測試數據:利用上述分類模型對測試數據進行分類。
3.3 實驗結果分析
實驗環境是使用MyEclipse 8.5進行實驗,實驗時所用的機器型號是聯想Y480,機器的主要配置為intel酷睿i5 3210 M 處理器,4G 內存,2.5GHz主頻。實驗所采用的評價指標是準確率P
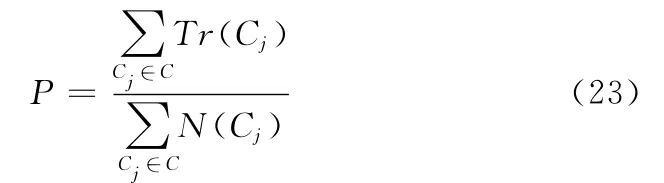
式中:Tr(Cj)——分類正確的文本數,N(Cj)——屬于類別Cj的文本數。
本文總共做了3組實驗,分別為采用傳統樸素貝葉斯進行實驗、用樸素貝葉斯+主觀線索 (不含關聯詞)進行實驗、本文提出的方法進行實驗。表9 為3 組實驗統計結果。

表9 實驗統計結果
最后,本文對3組實驗進行對比,得出3組實驗對比結果見表10。
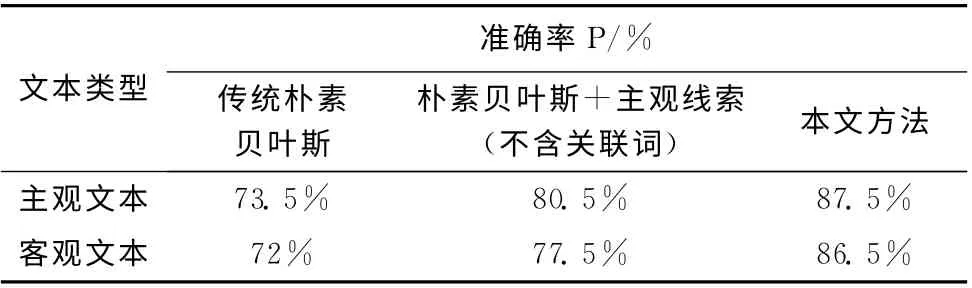
表10 3組實驗對比結果
由表10的3組實驗對比結果可以看出,主觀線索特征的加入對分類性能有一定的提升,而含有關聯詞的主觀線索特征的加入對分類性能的提升更加明顯。實驗表明,主觀線索對主觀性文本識別有一定的幫助,含有關聯詞的主觀線索特征比不含有關聯詞的主觀線索特征識別性能要好些。
4 結束語
本文分析了關聯詞對主觀性文本識別的作用,并將關聯詞加入到主觀線索特征中,作為主觀性文本識別的特征。實驗結果表明,主觀線索對主觀性文本識別有一定的幫助,含有關聯詞的主觀線索特征比不含有關聯詞的主觀線索特征分類性能要好些。本文主要針對主觀性文本識別進行研究,對如何準確有效識別出主觀性文本進行分析,提出關聯詞、情感詞以及與指示性動詞、感嘆詞、程度副詞、帶有情感色彩的標點符號等6種主觀線索成分作為主觀性文本識別依據,建立主觀線索特征詞表,用樸素貝葉斯分類器對主觀性文本進行識別,為解決主觀性文本識別提供可行的方法。
今后的研究工作從兩個方面展開:①提高分詞和分句的準確率,現有的分詞和分句工具準確率不高,這對主觀線索的判別有很大影響。②繼續探討其它的可以作為主觀性文本識別的主觀線索特征。
[1]ZHAO Yanyan,QIN Bing,LIU Ting.Sentiment analysis[J].Journal of Software,2010,21 (8):1834-1848 (in Chinese). [趙妍妍,秦兵,劉挺.文本情感分析 [J].軟件學報,2010,21 (8):1834-1848.]
[2]YANG Jiang,HOU Min,WANG Ning.Sentiment polarity analysis of reviews based on shallow text structure[J].Journal of Chinese Information Processing,2011,25 (2):83-88 (in Chinese).[楊江,侯敏,王寧.基于淺層篇章結構的評論文傾向性分析 [J].中文信息學報,2011,25 (2):83-88.]
[3]LIAO Xiangwen,LI Yihong.Identification of chinese opinion sentences based on n-gram hyperkernel function [J].Journal of Chinese Information Processing,2011,25 (5):89-93 (in Chinese).[廖祥文,李藝紅.基于N-gram 超核的中文傾向性句子識別 [J].中文信息學報,2011,25 (5):89-93.]
[4]YANG Wu,SONG Jingjing,TANG Jiqiang.A study on the classification approach for Chinese MicroBlog subjective and objective sentences [J].Journal of Chongqing University of Technology (Natural Science),2013,27 (1):51-56 (in Chinese).[楊武,宋靜靜,唐繼強.中文微博情感分析中主客觀句分類方法 [J].重慶理工大學學報 (自然科學),2013,27(1):51-56.]
[5]YAO Tianfang,PENG Siwei.A study of the classification approach for Chinese subjective and objective texts [C]//The Third National Information Retrieval and Content Security Conference Proceedings,2007 (in Chinese). [姚天昉,彭思崴.漢語主客觀文本分類方法的研究 [C]//第三屆全國信息檢索與內容安全學術會議論文集,2007.]
[6]GUO Yunlong,PAN Yubin,ZHANG Zeyu,et al.Multipleclassifiers opinion sentence recognition in Chinese micro-blog based on D-S theory [J].Computer Engineering,2014,40(4):159-163 (in Chinese).[郭云龍,潘玉斌,張澤宇,等.基于證據理論的多分類器中文微博觀點句識別 [J].計算機工程,2014,40 (4):159-163.]
[7]LI Xiaojun,DAI Lin,SHI Hanxiao,et al.Survey on sentiment orientation analysis of texts[J].Journal of Zhejiang University (Engineering Science),2011,45 (7):1165-1173 (in Chinese).[厲小軍,戴霖,施寒瀟,等.文本傾向性分析綜述 [J]. 浙 江 大 學 學 報 (工 學 版),2011,45 (7):1165-1173.]
[8]WANG Wenqi.The subjectivity of connectives of chinese complex sentences[J].Journal of Shanxi Datong University (Social Science),2012,26 (2):80-83 (in Chinese). [王文琦.復句中關聯詞語的主觀性考察 [J].山西大同大學學報 (社會科學版),2012,26 (2):80-83.]
[9]WEI Xiangfeng,ZHANG Quan,MIAO Jianming,et al.Event sentiment analysis based on semantic chunks[J].Journal of Chinese Information Processing,2012,26 (3):44-48 (in Chinese).[韋向峰,張全,繆建明,等.基于語義塊的事件傾向性分析研究[J].中文信息學報,2012,26 (3):44-48.]
[10]DANG Lei,ZHANG Lei.Method of discriminant for Chinese sentence sentiment orientation based on HowNet[J].Applica-tion Research of Computers,2010,27 (4):1370-1372 (in Chinese).[黨蕾,張蕾.一種基于知網的中文句子情感傾向判別方法[J].計算機應用研究,2010,27 (4):1370-1372.]
[11]SUN Jianwang,LV Xueqiang,ZHANG Leihan.Short text classification based on semantics and maximum matching degree[J].Computer Engineering and Design,2013,34 (10):3613-3618 (in Chinese).[孫建旺,呂學強,張雷瀚.基于語義與最大匹配度的短文本分類研究 [J].計算機工程與設計,2013,34 (10):3613-3618.]
[12]Taboada M,Brooke J,Tofiloski M,et al.Lexicon-based methods for sentiment analysis [J].Computational linguistics,2011,37 (2):267-307.
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
