搜索引擎的研究與實現
2015-12-23 00:54:42李水蓮
山東農業工程學院學報 2015年2期
李水蓮
(連云港財經高等職業技術學校,江蘇 連云港222003)
信息時代的爆炸帶來的是海量數據的發展,而搜索引擎帶來了大浪淘沙的功能。 網民們通過搜索引擎都能夠找到自己所需要的網頁,并且通過搜索引擎還能快速找到幫助自己發展的位置。 而搜索引擎的發展從第一代簡單的搜索,到當前復雜的數據挖掘,這其中的過程如下:
第一代引擎出現在1994 年。此代的搜索引起內容簡單、搜索的范圍不廣,而且他們對于搜索到的資訊和時間要求都不很嚴格,導致了在搜索過程中,人們經常需要花費大量的耐心來進行檢索,一般檢索的時間要等到10 秒或者更長。這一代的搜索使用的技術是在線搜索和IR 搜索技術。 根據數據統計,在當時在網絡爬蟲的數據大約每天1500 次查詢左右。
第二代搜索是建立在第一代搜索的基礎之上的。 由于第一代搜索的速度非常緩慢,第二代搜索在采用新技術——分布式響應方案的基礎上,提升了相應規模和相應速度,通過建立起一個大型、分布式的索引數據庫,每天直接對應各種用戶的需求, 并能夠快速的進行反饋。這種索引快速,導致了用戶數量的不斷增加和擴展。
第三代搜索是在獲取用戶數據上的。 通過搜索引擎充分理解用戶的需求,分析用戶對當前數據的安排和內容,并直接響應出用戶檢索的內容,減少用戶的查詢時間和響應時間。 這種檢索方式,需要充分利用用戶與檢索內容的交互,進行數據挖掘和數據分析,方能實現。
我們當前正處于第二代和第三代搜索之間, 在減少響應速度和響應時間之間,著名的搜索公司Google 和國內的百度有著自己的發展方向。
在因特網領域,搜索引擎技術得到了廣泛使用,然而他在國內外的含義卻有所不同。 在美國搜索引擎通常指的是基于因特網的搜索引擎, 他們通過網絡機器人程序收集上千萬到幾億個網頁, 并且每一個詞都被搜索引擎索引,也就是我們說的全文檢索。 在美國,他們通過網絡機器人程序收集上千萬到幾億個網頁, 并且每一個詞都被搜索引擎索引,也就是我們說的全文檢索。著名的因特網搜索引擎包括First Search、Google、HotBot 等。 在中國,搜索引擎通常指基于網站目錄的搜索服務或是特定網站的搜索服務,本人這里研究的是基于因特網的搜索技術。
一、搜索引擎的結構
本文基于瀏覽器/服務器(Browse/Server)結構,使用JSP 作為開發語言,J2EE 作為開發工具,MySQL 作為數據庫,并在Tomcat5.0 上進行發布。 由于JAVA 語言具有可移植、安全性、解釋執行、高性能、動態性,以及稍做修改后就具有跨平臺性的優點, 使得本系統操作方便、快捷。
1、網絡蜘蛛概念
網絡蜘蛛即Web Spider , 是一個很生動的名字。 假如我們把互聯網比喻成一個蜘蛛網, 那么Spider 就是在蜘蛛網上爬來爬去的蜘蛛。 通過網頁的鏈接地址, 網絡蜘蛛從網站某一個頁面( 通常是首頁) 開始, 通過讀取網頁的內容, 找到其他網頁的鏈接地址, 然后再通過這些鏈接地址繼續讀取下一個網頁。 這樣一直循環下去, 直到把這一網站所有的網頁都抓取完為止。 如果把整個互聯網當成一個整體網站, 那么網絡蜘蛛就是通過上述原理抓取Interner 網上的所有網頁。 對于搜索引擎來說, 要抓取互聯網上所有的網頁幾乎是不可能的, 從目前公布的數據來看, 容量最大的搜索引擎也不過是抓取了整個網頁數量的百分之四十左右。 這其中的原因一方面是抓取技術的瓶頸, 無法遍歷所有的網頁, 有許多網頁無法從其它網頁的鏈接中找到; 另一方面是存儲技術和處理技術的問題,如果按照每個頁面的平均大小為20K 計算(包含圖片) , 100 億網頁的容量是100 ×2000G 字節, 即使能夠存儲, 下載也存在問題( 按照一臺機器每秒下載20K 計算, 需要340 臺機器不停的下載一年時間, 才能把所有網頁下載完畢) 。
2、網絡蜘蛛的主要技術
在抓取網頁時, 網絡蜘蛛一般有廣度優先和深度優先兩種策略。 廣度優先其實就是一種并行處理, 網絡蜘蛛通過起始網頁中鏈接的所有網頁, 選擇其中的一個鏈接網頁, 抓取在此網頁中鏈接的所有網頁,依次擴展,從而提高其抓取速度。 深度優先是指網絡蜘蛛會從起始頁開始, 一個鏈接一個鏈接地跟蹤下去, 處理完這條線路之后再轉入下一起始頁, 繼續跟蹤鏈接。 這一方法的優點是網絡蜘蛛在設計時比較容易。 相對于深度優先來說,廣度優先要常用的多。
目前一般的網站都希望有更多的訪問者訪問, 也就是需要有更多的搜索引擎找到訪問的網頁,也即是全面地抓取自己網站的網頁。 為了讓本網站的網頁更全面地被抓取到, 網站管理員可以建立一個網站地圖, 即Site Map。 網絡蜘蛛通過sitemap.htm 這個入口爬取這個網站的網頁,抓取這些文件后,通過讀取其中的文本信息,提取對搜索引擎的搜索準確性有重要幫助的文檔信息, 同時, 這些信息也利用網絡蜘蛛正確跟蹤其它鏈接。 在搜索引擎中網絡蜘蛛占有重要位置, 對搜索引擎的查全、查準都有影響, 決定了搜索引擎數據容量的大小。 同時,它的好壞還直接影響到搜索結果頁中的死鏈接( 即鏈接所指向的網頁已經不存在) 個數。
二、搜索引擎總體設計
現實環境中,有許多用戶都有搜索服務的需求,例如很多網站都渴望有自己的站內搜索,這當然可以通過數據庫來簡單實現,但是在搜索服務器的負載量很大的情況下,數據庫是無力應付的,而且數據庫簡單的基于字符串匹配的方式也顯得過于呆板, 不能提供更多的高級搜索功能。 有的用戶可能會選擇自己組建開發團隊來開發搜索引擎, 也可能會購買商用的搜索服務器軟硬件來搭建搜索平臺。 不過, 筆者認為普通用戶也可以選擇簡單地購買搜索服務,不需要自己的開發團隊,也不需要自己購買搜索服務軟硬件。 也就是說, 用戶只簡單地提出搜索服務要求,其它一切都交給搜索服務提供商,軟硬件和數據維護與更新都交給服務提供商。
在上述情況下, 一個搜索引擎服務器提供商可以為若干個客戶提供搜索,他們需要根據不同用戶的需求去設計數據的索引策略和搜索策略,同時需要在自己的服務器主機上保存和維護不同用戶的數據。 Solr1.3 優秀的多核心性能正好能滿足這樣的需求, 一方面多核心可以實現多庫, 也就可以實現多個服務并行提供; 另一方面Solr1.3 的各個核心之間的獨立性和可配置性,又使得搜索服務提供商可以根據不同用戶的需求來進行個性化的配置。
這一章將基于Solr1.3 來設計一個在同一個服務器對兩個大學(北京大學、中山大學)網站進行搜索的合成搜索引擎。主要目的是要利用Solr1.3 的多核心特性來設計一個多索引庫的應用場景。 本設計無意追求真實場景中的搜索性能,只是提供一種基于Solr1.3 開發多應用搜索引擎的思路。 設計注重管理與普通使用的分離, 將所有管理操作都納入同一個Web 頁面下以提供管理的方便性,同時盡量考慮將來的擴展需求。
1、整體結構與模塊關系
基于Solr1.3 的搜索引擎實現的結構,是常用的一種結構,該結構具有索引更新、索引刪除、查詢、分詞、網絡蜘蛛、索引庫、New API、Solr Core API 八大模塊(由于管理員頁面與普通用戶查詢頁面只是簡單的HTTP 接口調用,所以不將他們算作單獨模塊)。 這八大模塊中除Solr Core API 模塊外,其他模塊都是我們需要實現或配置的。圖中的箭頭表示模塊間的調用關系, 虛箭頭處意在說明這里的調用是通過修改配置文件由Solr1.3 內部實現的,至于其如何去調用,我們不必去理會。
該結構中索引更新、 索引刪除和查詢模塊主要使用Servlet 技術實現,Servlet 一方面通過Java 代碼調用New API 模塊和網絡蜘蛛模塊, 另一方面對外提供HTTP 調用接口。 New API 層存在的原因是:Solr Core API 接口提供高內聚、低耦合的特性的同時,接口的參數類型過于復雜且參數類型不宜普通開發者理解,New API 層對Solr Core API 進行重新包裝使得參數更容易理解, 同時它實現的功能是Solr Core API 的子集也使得接口更加簡化。
2、三大功能模塊
搜索引擎從總體而言, 主要可以分為3 大主要功能模塊:網頁抓取模塊(Web Spider)、信息抽取和索引模塊、查詢頁面和查詢的算法。 這3 大模塊代表著搜索是否能夠快速的滿足用戶的需求,也代表著整個搜索引擎品質。如圖1。
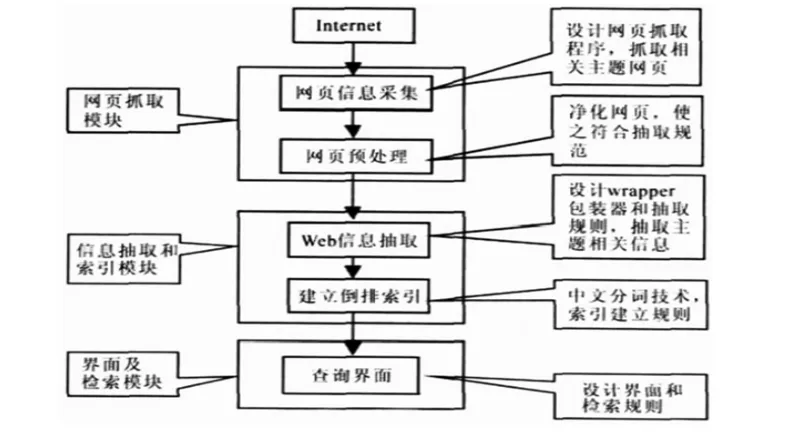
圖1 搜索引擎的流程
(1)網頁抓取模塊(Web Spider)
該模塊是從互聯網的海量信息當中, 找到與搜索主題相關的網頁。 建立起相應的索引, 以便提供給用戶查詢。 此過程中需要進行強大網頁抽取功能。 這需要抓取模塊——網絡蜘蛛、網絡爬蟲具有強大的網頁分析和檢索功能。 通過凈化和抽取, 將符合標準規范的網頁存儲入數據庫當中。
(2)信息抽取和索引模塊。
該模塊是利用已經生成的數據庫進行索引, 以便提升查詢的效率和減少查詢的時間。 本模塊屬于承前啟后的作用,是搜索引擎當中最為重要的模塊,前一步的要求的是對網頁進行數據抽取,后一步的是對已經抽取的數據進行大規模的數據索引。 通過建立起大規模的結構化和非結構化的數據提取相應的數據信息。 并對檢索要求的數據進行分詞、排序等大規模的數據整理工作。
(3)查詢頁面和查詢的算法。
用戶通過第二步的索引建立, 已經建立出一個具有較快速的查詢方案,本步驟的主要要求是如何使用已經建立起的索引模塊,因此提升查詢速度和查詢效率是本步驟中最為關注的重點。 當然, 與用戶之間的界面交互也是查詢頁面的設計內容之一。
三、搜索引擎詳細設計與實現
1、網絡蜘蛛模塊的設計與實現
目前, 互聯網上有許多開源的網絡蜘蛛, 例如Heritrix。 雖然它們功能很強大,但是使用與改造都十分復雜,索引本文不使用這些復雜的網絡蜘蛛工具來實現而選擇自己編寫簡單可用的網絡蜘蛛。 網絡蜘蛛模塊采用廣度優先法實現。實現該爬蟲的類為Spider,對外提供nextPage()方法返回一個獲取的網頁。 底層網頁解析部分功能使用了開源的工具包htmlparser。
爬蟲以網站首頁URL 為構造函數的參數,這決定了爬蟲將以此URL 作為爬行的起始點。 爬蟲的nextPage()方法返回一個Page 對象,它代表一個滿足條件的可以被索引的網頁。 爬蟲nextPage() 方法的工作流程為:從未處理URL 隊列中提取出一個URL –>分析該URL 以提取出新的URL,如果新的URL 未在已處理URL 隊列出現,將新的URL 交給過濾器, 將過濾后的URL 添加到未處理URL 隊列–>將當前處理的URL 添加到已處理URL隊列–>提取出文字與標題, 構造Page 對象并返回該對象。
2、New API 模塊的設計與實現
New API 模塊主要是簡化原有調用結構, 使得參數更加貼近實際需求。 也就是說我們的傳入參數是我們熟悉的(如標題,內容,關鍵字),查詢返回結果也是我們熟悉的類型。 New API 模塊的實現過程中一個重要的部分就是參數類型的轉化, 以使得外層參數與內層參數銜接起來。
New API 通過類DirectAPI 來實現。
MyQueryResult 類型是自定義的返回結果類型,我們通過對XML 結果的解析, 提取出所需信息包裝成MyQueryResult 對象,在生成用戶友好的頁面響應結果的時候,可以方面地通過該對象獲得所需數據。
3、管理模塊的設計與實現
管理模塊是給管理員和開發者使用的, 管理利用該模塊來添加、更新、刪除索引和進行查詢操作。 為提高管理的方便性, 管理模塊提供Web 界面,Web 頁面通過調用Servlet 來達到操作效果。
4、 配置文件的配置
配置文件包括schema.xml、solrcofig.xml、solr.xml。 在本應用中,由于有兩個庫(sysu 和pku),所以需要在solr.xml 中配置兩個庫。 搜索器和索引器相關參數使用默認設置,所以不需要對solrconfig.xml 進行特別設置。
schema.xml 文件需要兩個fieldtype:string 和text。 其中text 指明該類型使用中文分詞類進行分詞;field 有四個:id、url、text、title;類型分別為string、string、text、text。 id字段表示文檔序號,url 表示網頁的連接地址,title 和text為網頁的標題和內容,后兩者是需要分詞和建立索引的。默認的搜索字段為text, 這樣我們就可以搜索某個網頁的文字信息了。
5、分詞模塊的設計與實現
分詞模塊是中文搜索引擎中極其重要的模塊, 搜索的效果很大程度上決定與分詞的效果,但是自主研發中文分詞需要非常雄厚的技術實力,一般開發者是無法自主研發的。 這里我們選擇使用開源的中文庖丁解牛工具包來實現。
分詞模塊實現步驟如下:
1. 下載“庖丁解牛”分詞包,按照配置教程設置好環境變量和用戶詞典。
2. 然后將分詞包添加到工程, 修改中文分詞類org.apache.solr.analysis. ChineseTokenizerFactory,使用用中文庖丁解牛工具包來實現。
3. 最后配置schema.xml 中需要分詞的域類型使用該分詞類即可。
6、 查詢模塊的設計與實現
用戶通過查詢頁面 (search.jsp) 的表單向服務器SearchServlet 發送查詢請求。 服務器收到請求后,獲得查詢的參數, 調用DirectAPI.queryAndReturnMyQueryResult獲得查詢結果MyQueryResult 對象, 然后從該對象獲得結果信息,并重設request 使它包含結果信息。 最后將請求轉向結果顯示頁面(ResultShow.jsp)。
結論
搜索是互聯網發展時代的主題, 也是當前大數據挖掘時代的主要支持對象。 隨著因特網的技術不斷發展和更新,利用網絡來獲取各種資源的信息已經成為了人們生活、 工作中最為常見的活動。 人們利用各種檢索來的信息,分析信息和發展信息,最終達到合理利用資源的手段和方法。 我們可以預計, 在未來人們對于搜索網絡信息的搜索引擎要求越來越高,搜索的內容也越來越復雜,搜索引擎的發展也一定會隨著時代的發展,以用戶為核心的計算不斷延伸和發展。
[1]汪曉平,鐘軍.JSP 網絡開發技術.人民郵電出版社,2003:103-178
[2] 周曉敏.DreamWeaver?MX 應用培訓教程. 電子工業版,2002:55-71
[3]黃日昆.網絡引文搜索引擎CiteSeer 評析.情報雜志.南寧,2004:1-4
[4](美)亨特,(美)羅夫特斯.精通J2EE.清華大學出版社,2004:256-299
[5](美)馬丁.Servlet 與JSP 核心技術.人民郵電出版社,2001:66-89
[6]資訊教育小組.JSP 與SQL 網站數據庫程序設計.科學出版社,2002: 202-297
[7]飛思科技.JSP 應用開發詳解.電子工業出版社,2005:345-358
[8]李博.JSP 應用開發指南.科學出版社,2003:45-123
[9]鄧子云,張賜.JSP 網絡編程從基礎到實踐.電子工業出版社,2006:56-280
[10]宋杰,王大玲,鮑玉斌,申德榮.基于頁面Block 的Web 檔案采集和存儲.電子工業出版社,2008:275-290
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛生(2015年12期)2015-11-10 05:13:38
創業家(2015年5期)2015-02-27 07:53:25
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
電腦愛好者(2011年11期)2011-06-22 08:20:18
