基于RSSI的貝葉斯垃圾郵件過濾算法
2015-12-23 00:52:00陳鐵軍靖豐年段誼海
計算機工程與設計 2015年7期
陳鐵軍,靖豐年,段誼海
(鄭州大學 電氣工程學院,河南 鄭州450001)
0 引 言
基于內容的垃圾郵件過濾法比一般白名單與黑名單技術、規則過濾以及基于關鍵詞匹配的內容掃描等智能化程度高,可采用屬于有監督學習的樸素貝葉斯分類器,實踐結果表明分類效果佳。其中,貝葉斯過濾器是基于文本的過濾技術,準確率較高,但是,現有樸素貝葉斯分類器基于一個假設:從郵件中提取的文本特征是相互獨立的。這是一個很強的假設,因為文本特征是相互關聯的,所以現有貝葉斯算法過多的簡化文本特征的相關性,導致判別垃圾郵件的召回率減低。在早期基于貝葉斯分類器的算法中,特征值被簡化為0和1,沒有體現特征出現的概率,為更多利用文本特征的相關性,提出基于多項式模型的貝葉斯分類器[2]。與伯努利模型相對比,多項式模型更精確地描述了特征的重要性,然而,算法時間代價卻激增由O(n)上升到O(n2)。另外,對于那些出現次數較少的對判斷會造成較大的誤差。針對以上情況,本文提出基于RSSI特征選擇器的貝葉斯垃圾郵件過濾算法,剔除無關特征和不穩定特征,有效減少過擬合,提高算法效率。與現有樸素貝葉斯算法 (nave Bayes)和支持向量機 (support vector machine,SVM)等算法相比,RSSI算法能顯著減少分類時間,降低合法郵件被誤判的概率。
1 樸素貝葉斯分類器的構建
樸素貝葉斯分類器是有監督學習的一種,分類器對郵件進行分類時,考慮到時間開支本文選擇文檔頻數[3](document frequency,DF)作為特征來進行建模。通過郵件解析和中文分詞[4]預處理,對出現的詞語生成一個詞典,設郵件的特征向量為X =(x1,x2,…,xi,…,xn)[5],xi表示每一封郵件的特征項。郵件共有兩類:正常的郵件集合G和垃圾郵件集合B,其中G =(G1,G2,…,Gi,…,Gn),B =(B1,B2,…,Bi,…,Bn)。設郵件E 的特征向量為XE=(,,…,…),根據貝葉斯公式,則郵件E 屬于垃圾郵件的概率為
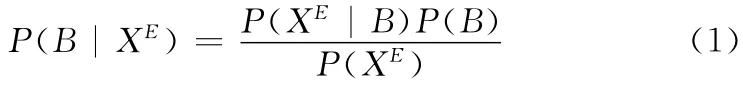
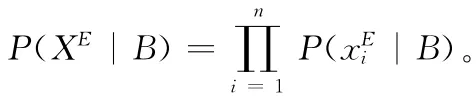
就伯努利模型而言,xi取1或0,設參數=P(xi=1|B)=P(xi=1|G)=P(B),給定一個訓練集合可以得出參數的似然函數
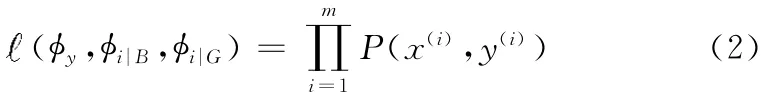
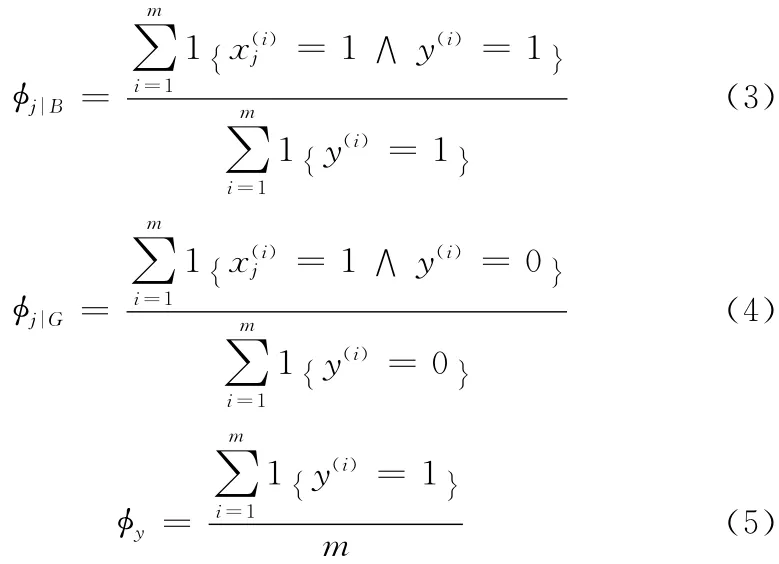
y(i)=1表示第i個訓練樣本屬于B 集合,1 {}表示指示符號,規定1{true}=1,1{fault}=0,進而可以得出給定測試郵件屬于垃圾郵件的概率
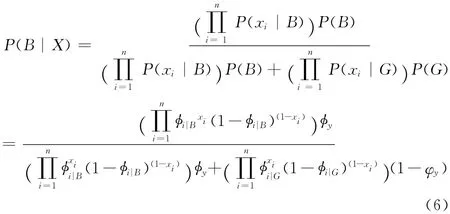
2 貝葉斯多項式模型
伯努利模型貝葉斯分類器可根據特征項的出現與否計算給定測試郵件與正常郵件和垃圾郵件的匹配程度,對郵件分類。由于伯努利模型xi只能取兩個值1和0,為表達更多的特征信息,提出了多項式模型[6],此時對X =(X1,X2,…,Xi,…,Xn),Xi表示郵件經中文分詞后第i 個字符的標識,n表示郵件的長度。給定參數=P(xj=i|B),=P(xj=i|G)=P(B),給定訓練集合{(x(i),y(i));i=1,…,m},這里x(i)=,…,),ni是第i個訓練樣本的郵件長度,可以得到參數,的似然函數
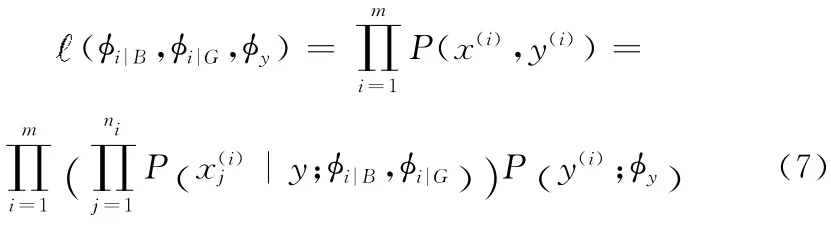
求得參數的極大似然估計

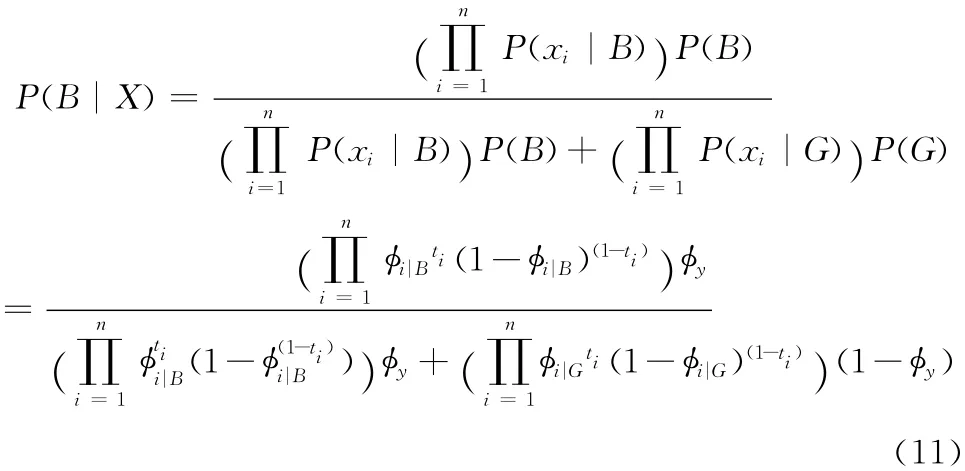
ti取1或0,以上就是多項式模型貝葉斯分類器的數學模型。比較式 (6)和式 (11),發現在計算判別X 屬于垃圾郵件的概率時,計算量差別在上 (注意兩式中|B不同),比較式 (3)和式 (8)發現多項式模型的計算量是O(n2),而伯努利模型中的計算量僅為O(n)。對計算機來說O(n2)的運算量尚可接受,精簡算法結構將大幅減少運算時間,下面將對生成的特征向量X 簡化。
3 RSSI算法過程
對式 (11)剖析發現計算了大量的無關特征項[9],如字典中收納的量詞、語氣詞等,對正常郵件和垃圾郵件建模過程中發現,這些詞的在正常郵件和垃圾郵件出現概率和大致相同,固可以利用這個特征來對生成的字典進行合理的 “瘦身”。
設閾值為T =5%,如果超過了這個范圍,認為此為相關特征項,如果在這個范圍內,則認為是無關特征項,在生成字典中刪除此特征項
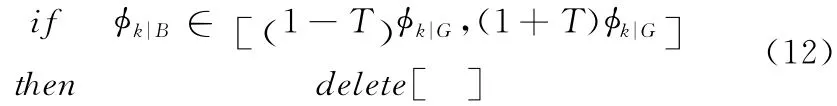
在對一些錯誤分類的郵件研究發現,有些出現頻次很小的特征項是導致分類錯誤的主因,比如特征項xi在集合G 中出現一次,而沒有在集合B 中出現,顯然這存在很大的偶然因素,然而貝葉斯分類器通過對特征項xi的計算后將有極大的傾向把郵件X 分給集合G 。為了克服這個缺點,我們設閾值Tf=5,有關計算公式如下
到此,我們降低了X 維數,降低了算法的運算量,減少了內存空間的消耗,并提高了分類正確率。
4 實驗分析
4.1 實驗環境
在上述基于多項式模型的貝葉斯垃圾郵件分類算法中,采用RSSI方法降低特征維數,本文仿真基于matlab平臺,WEKA Java API和Eclipse開發環境,選用PU 系列英文語料庫和ZH1 中文語料庫,實驗方法采用 “十字交叉驗證法”[10],將每一個語料庫中平均分10份,9份作為訓練集,1份作為測試集,采用原始處理訓練集和測試集txt文本集為一個m×n維的矩陣[11],m 為集合中元素的個數,n為幾何元素的權值,1表示對應特征項出現,0表示不出現。
4.2 評價指標
為了評價算法的好壞,引入正確率 (RPrecision)和召回率 (RRecall)兩個概念
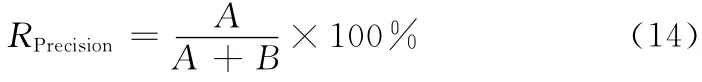
式中:A——垃圾郵件被正確分類的數量,B——被錯誤判定為垃圾郵件的數量。正確率越高,正確分類垃圾郵件和正常郵件的數量越多
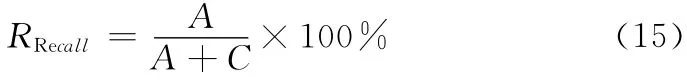
式中:A——正確區分垃圾郵件的數量,C——漏掉的垃圾郵件的數量。召回率越高,檢測到的垃圾郵件越多,漏掉的垃圾郵件越少。
4.3 實驗結果
實驗中,首先對傳統貝葉斯算法和本文改進算法對郵件的分類正確率進行測試,采用 “十字交叉驗證法”,首先選取集合中的70%作為樣本集,利用Weka軟件對其進行訓練,建立特征集。然后對集合中剩下的30%提取特征,進行分類測試,隨著特征數目的不算增加,對分類正確率的影響如圖1所示。
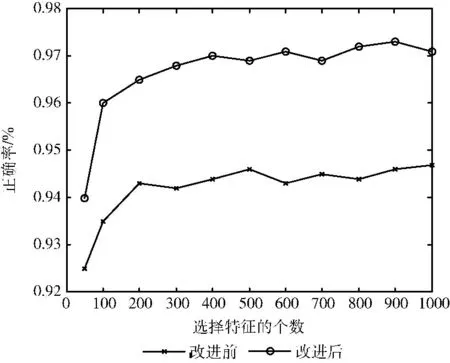
圖1 兩種算法下選擇特征個數對郵件正確率的影響
從圖1可以看出,當特征個數較少時,分類準確率較低,是因為特征項不能完全反映文本特征,導致文本區分度不高,當特征數量大于等于200時,分類準確率趨于穩定,此時出現了大量冗余的特征項。觀察到改進后的方法在特征個數較少時仍有很高的準確率,趨于穩定時特征個數比改進前少,這是因為改進算法剔除了大量的無關特征性,使算法在僅有少量特征個數下就能充分反映文本特征。
研究特征數目對召回率的影響,實驗結果如圖2所示。

圖2 兩種算法下選擇特征個數對郵件召回率的影響
從上圖中可以看出,在特征項個數較少時,郵件召回率較低,這是因為特征個數不能充分描述垃圾郵件文本,導致漏掉的垃圾郵件過多,隨著特征數量的增加,召回率出現極大值,其原因是特征項正好反映文本特征,不同類型的郵件區分度高。隨著特征數量的增多,算法召回率下降趨于平穩,這是因為摻雜與分類無關的特征項,產生分類干擾,使分類效果變壞。兩條曲線比較發現,改進前的極值出現在300左右,而改進后的極值在200 左右,這是因為剔除了無關特征項使極值提前,因為剔除了一部分分類干擾,所以提高了召回率。
測試改進算法的時間代價,對分類器進行訓練后,隨機選取測試集中100份郵件進行測試,得出結果見表1。

表1 傳統貝葉斯算法和本文算法的分類時間
分類時,對測試郵件的特征向量X 分別與垃圾郵件模型和正常郵件模型相匹配,看哪種模型匹配度高。改進后算法分類時間短的原因是去除了無關特征項,在最后計算P(B|X)時特征項數比改進前少,固節省了計算時間。
4.4 與其它垃圾郵件算法的比較
對于時下流行的K 最鄰近算法、支持向量機算法用于垃圾郵件分類,實驗選取了共1089封郵件的實驗集,對比了KNN 算法、SVM 算法和RSSI算法,實驗結果見表2。

表2 RSSI算法、KNN 算法、SVM 算法性能對比
從表2 中可以看出:①從郵件過濾性能上看,基于RSSI的貝葉斯垃圾郵件過濾算法的正確率和召回率與SVM 算法相當,但比KNN 算法要好;②從郵件過濾速度上看,基于RSSI的貝葉斯垃圾郵件過濾算法要比KNN 算法和SVM 算法快一倍以上,這是因RSSI算法有效減少特征項,降低了計算機的工作量。
5 結束語
貝葉斯垃圾郵件分類模型是廣泛使用的一種垃圾郵件分類模型,但是需要使用大量的訓練集合訓練,占用大量網絡資源和系統資源見下方[12]。本文提出了基于RSSI的貝葉斯垃圾郵件過濾算法,與傳統貝葉斯垃圾郵件分類機制相比:①本文算法能去除無關特征,使召回率極大值提前,準確率在取較小值即達到平穩,改進了算法性能;②本文算法由于去除了無關特征的干擾,提高了準確率和召回率,減少了計算時間,提高了效率。
與KNN 算法和SVM 算法相比,性能相當,但由于簡化了算法,執行效率得到了大幅提升。
[1]ZHENG Dongdong,SONG Shunlin.Survey of image spam filtering technology [J].Computer Engineering and Design,2010,31(1):41-44(in Chinese).[鄭冬冬,宋順林.圖片垃圾郵件過濾技術綜述[J].計算機工程與設計,2010,31 (1):41-44.]
[2]EP Sanz JGHJ.Email spam filtering [J].Advances in Computers,2008,74:45-114.
[3]LI Xiao,LUO Junyong,YIN Meijuan.Email filtering based on structural feature analysis and text classification [J].Computer Engineering and Design,2010,31 (21):4555-4558 (in Chinese).[李瀟,羅軍勇,尹美娟.基于結構特征分析與文本分類的郵件篩選 [J].計算機工程與設計,2010,31 (21):4555-4558.]
[4]YANG Kaifeng,ZHANG Yikun,LI Yan.Feature selection method based on document frequency [J].Computer Engineering,2010,36 (17):33-35 (in Chinese). [楊凱峰,張毅坤,李燕.基于文檔頻率的特征選擇方法 [J].計算機工程,2010,36 (17):33-35.]
[5]LIU Hongzhi.Research on Chinese word segmentation techniques[J].Computer Development &Applications,2010,23(3):1-3 (in Chinese).[劉紅芝.中文分詞技術的研究 [J].電腦開發與應用,2010,23 (3):1-3.]
[6]LIANG Zhiwen,YANG Jinmin,LI Yuanqi.A Bayesian spam filtering algorithm based on polynomial model and low risk[J].Journal of Central South University (Science and Technology),2013,44(7):2787-2792(in Chinese). [梁志文,楊金民,李元旗.基于多項式模型和低風險的貝葉斯垃圾郵件過濾算法 [J].中南大學學報(自然科學版),2013,44 (7):2787-2792.]
[7]ZHAO Jing.Research on spam filtering technologies based on content characteristics analysis[D].Shandon:Shandong Normal University,2012:7-15 (in Chinese). [趙靜.基于內容特征分析的垃圾郵件過濾關鍵技術研究 [D].山東:山東師范大學,2012:7-15.]
[8]ZHENG Wei,SHEN Wenzhang,YING Peng.Implementing spam filter by improving naive Bayesian algorithm [J].Journal of Northwestern Polytechnical University,2010,28 (4):623-627 (in Chinese).[鄭煒,沈文張,英鵬.基于改進樸素貝葉斯算法的垃圾郵件過濾器的研究 [J].西北工業大學學報,2010,28 (4):623-627.]
[9]FU Huitao,Kamil Moydin.Study and design of an improved text feature selection method [J].Computer Applications and Software,2011,28 (4):238-241 (in Chinese). [符會濤,木衣丁·卡米力.一種改進的文本特征選擇方法的研究與設計[J].計算機應用與軟件,2011,28 (4):238-241.]
[10]Blanzieri E,Bryl A.A survey of learning-based techniques of email spam filtering [J].Artif Intell Rev,2008,29:63-92.
[11]LUO Qin,LIU Bing,YAN Junhua,et al.Research of a spam filtering algorithm based on naive Bayes and AIS [C]//International Conference on Computational and Information-Sciences.Washington:IEEE,2010:152-155.
[12]Kosmopoulos A,Paliouras G,Androutsopoulos I.Adaptive spam filtering using only naive bayes text classifiers [C]//Fifth Conference on Email and Anti-Spam,2008.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
