基于選擇遷移的bagging文本分類算法
2015-12-23 00:52:54吳陳,湯瑩
計算機工程與設計 2015年7期
吳 陳,湯 瑩
(江蘇科技大學 計算機科學與工程學院,江蘇 鎮江212003)
0 引 言
傳統的數據挖掘是基于訓練集、測試集具有相同的特征空間和數據分布的假設[1],但隨著互聯網的發展,獨立同分布的前提在現實中有許多局限,所以將相似領域知識或過時的數據遷移應用到目標領域逐漸成為研究的熱點,這也是遷移學習的框架。遷移學習中標記的目標訓練樣本過少,易造成數據不平衡,bagging作為一種集成學習的方法,被廣泛應用于不平衡數據分類中[2]。文本分類技術是在預先給定類別標記的文本集合下,根據文本的內容判定它的類別[3]。文獻 [4]在Adaboost算法的基礎上提出了TrAdaboost算法;Toshihiro Kamishima等擴展了bagging算法[5]并應用于書簽遷移;Liu等提出一種動態重構數據集的遷移集成學習算法DRTAT[6]。現實中基于隨機抽樣技術的遷移bagging算法的文章相對較少,且boosting技術基于一定復雜度和有限時效的優勢在面對海量的具有高維、非線性、不平衡特點的文本信息時是有局限的,而集成算法中的bagging技術在任意的學習系統中總能找到一個將弱學習轉化為強學習的算法。因此,本文在文本分類的背景下結合遷移學習和bagging集成學習算法,借鑒集成學習處理高維、不平衡數據的有效性,對應于新領域訓練數據的局限性,在遷移學習的框架下引入集成思想提出一種選擇遷移的bagging算法,可以有效提高分類的效果和泛化能力。
1 文檔分類
數據挖掘中數據集的選擇和采集也是研究的熱點,本文實驗前需要對大量文本進行去噪聲、去缺省、去不一致、去不完整的預處理。必須對文本進行如下操作:分詞、去停用詞、文本表示、特征降維、特征抽取或特征選擇等。其中,常見的一種用于特征加權方法為TF-IDF詞頻-逆向文件頻率。TF表示某個詞在文件中出現的次數,IDF用來度量某詞的重要性,具體公式如下:TF-IDF =tfi,j×idfi。
預處理后的文本,需選定任意一種分類方法來實現分類器的訓練,本文涉及經典的分類算法:樸素貝葉斯分類[7]和支撐向量機[8]。樸素貝葉斯算法根據貝葉斯定理由條件概率推導出式(1),判斷目標分類數據X ={x1,x2…xj…xn}的類別P(Ci|X)最大概率。而支持向量機分為線性和非線性,對文本而言是非線性尋找最優超平面,把樣本xi從低維空間映射到高維線性可分的特征空間F 中的,將式 (2)用二次規劃求解方法得出判別函數式 (3),本文支持向量機采用K(x,y)=-exp(-γ x-y2)徑向基函數

評估使用常見的準確率 (P)、召回率 (R)、以及綜合評價標準F-measure(F)[9],其中F-score是P與R 的加權調和平均值。
2 問題描述
為方便后面算法的表述,這里用數學符號定義一些概念。設存在目標領域的數據集T 和源領域(輔助領域)的數據集Ds,而本文討論情況是只存在少量的已標注的目標領域數據和大量待測的目標領域的數據,因此將目標領域的數據集又分為目標訓練集Dt和待預測的Dtest,Dt的數量要明顯小于Dtest。假設在目標域T 中只有n 個是已標注類別的文本,那么目標訓練集Dt的數量就為n。對應成文本集合表述為:
目標訓練文檔集合Dt={(x1,y1),(x2,y2),(x3,y3)...(xn,yn)};
源域輔助文檔集合Ds={(p1,q1),(p2,q2),(p3,q3)...(pm,qm)};
混合訓練文檔D =Dt∪Ds={vi,c(vi)}={(p1,q1)...(pm,qm),(xm+1,xm+1)...(xm+n,ym+n)}。
其中,vi為任意的訓練文檔,c(vi)為該文檔的所屬類別。混合訓練集D 的前m 個樣本來自具有相似領域的源域,后n個樣本是目標域T 中已標注用來訓練的數據。其中,vi=<vi1,vi2...viz>∈V 特征矢量,V 是文檔向量集合,vi表示文檔集合中第i篇文檔,第i篇文檔中的第z 個特征為viz。設分類器是對應于類別C 的單分類器,c(vi)∈{-1,1},即本文僅討論兩分類問題。若目標領域文本滿足(xt,yt)-Pt(xt,yt)的分布,源領域滿足(ps,qs)-Ps(ps,qs)分布,那么Dt,Dtest目標訓練集和測試集是同分布且滿足Pt(xt,yt),源域與目標異布,Pt≠Ps,它們之間領域相似有共性但相異。本文主要目標是利用Dt和Ds訓練適合Pt(xt,yt)分布的分類器來預測Dtest。
3 基于選擇遷移的bagging文本分類算法
3.1 基于分類的選擇遷移算法ADS算法描述
算法:挑選輔助算法。源輔助數據挑選是為提高目標學習器的分類效果,避免不相似數據干擾,基于分類的選擇遷移算法挑選出輔助數據中符合目標特征的數據成為必然。
輸入:目標訓練數據Dt,輔助數據Ds,參數φ(挑選輔助到目標的一種映射關系)
輸出:根據標記的目標數據訓練,獲得與目標分類一致的輔助訓練集Ds-right
過程:
(1)輸入和輸出參數設定:將目標訓練數據Dt作為學習器的訓練集,輔助數據Ds作為測試集分類;
(2)如果目標訓練集Dt的類別是C1和C2,輔助訓練集Ds的類別是D1和D2,定義一映射關系H(t):Li(x)=D1if Li(x)=C1AND Li(x)=D2if Li(x)=C2基于以上映射給出φ的定義:如果D1→C1,D2→C2,φ=1;否則φ=0;
//D1和D2中噪音數據大部分可以排除,相似領域差的輔助數據被刪除
(3)R=ClassifierbuilderBEST(Dt)&Test(Ds)//Dt訓練Ds,分類器選擇最優分類效果的算法;
(4)For each instance(x″,y″)in Ds
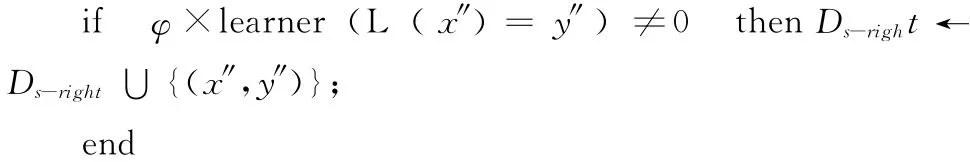
其中,本文實驗數據在步驟 (3)中的ClassifierbuilderBEST經過驗證用基于貝葉斯的個體分類器bagging算法得出的效果最為理想。帶噪音的輔助數據選擇算法 (ADS)中的分類算法需要實驗挑選,但是總準確率經后期實驗證明基于集成的分類算法精度總體優于單分類器,集成算法用于遷移干凈的輔助數據效果更佳。
3.2 基于選擇遷移的bagging的文本分類算法 (A-TTB)
文本遷移集成分類算法 (text transfer bagging),TTB過程及偽代碼:
輸入:目標域訓練集Dt,源輔助域數據集Ds,學習器learner算法C,迭代次數L
輸出:classifier c′(vi)返回結果,如果分類正確返回1,否則返回-1
過程:
(1)D =Dt∪DS
(2)D′=Pretreatement(D) //利用預處理技術獲取新的樣本集D′
(3)for(i=1;i≤L;i++)
(4)D″=bootstrap(D′)
(5)Ci=bagging(algorithim(D″)) //bagging的基分類器使用貝葉斯算法
(6)End for
A-TTB (auxiliary-text transfer bagging)算法描述:
步驟1 目標數據和輔助數據分別做文本數據預處理Pretreatment(data);
步驟2 將預處理后的數據集執行ADS算法,挑選出有利于目標文本分類的輔助數據,將正確分類的輔助數據加入目標訓練數據集;
步驟3 對Ttest執行TTB算法,測試集數量按原始數據樣本的一定比例劃分,最后對集成后的多個分類器投票得出最后預測結果。
4 實驗結果與分析
4.1 實驗平臺與數據
本文的實驗環境為SAMSUNG 筆記本一臺,基本配置如下:Windows XP系統、3GHz CPU、1G 內存、150G硬盤;基于新西蘭懷卡托大學開發的Weka 3.7.10 版本;數據處理使用JAVA eclipse,jdk1.6版本。本文數據來源于20NewsGroup[10](UCI KDD Archive知名的Web網頁預料庫新聞數據組數據),由于要考察噪音與負遷移的關系,因此故意人工引入了噪音域,手動構造了3個數據集用來實驗,這3 組數據分別來自頂層域:rec、talk、comp,異構噪音域來自comp、misc、alt,數據首先從頂層域中選擇不同分布的目標域與輔助,然后添加噪音域到輔助中,構成帶噪音的源輔助,它們之間又是結構相異的。具體實驗數據見表1,顯示了test1、test2、test3這3個數據集的組成與數量。設定程序重復20次,取均值得到結果。集成前基分類器需多次嘗試確認最優參數,對比算法中的SVM(support vector machine)運用LibSvm 工具包,采用高斯徑向基函數:懲罰因子C=10,核函數寬度=0.1。集成分類器中的基分類器個數均為10,隨機抽樣的特征子集數量與初始訓練集特征子集數量比X,X ∈ (0,1],test1和test2中的子集比X=0.8,test3的X=0.5,且目標域數據訓練集占原始集20%,剩余作測試集,但是與test3對比的后一次實驗取1%的數量。
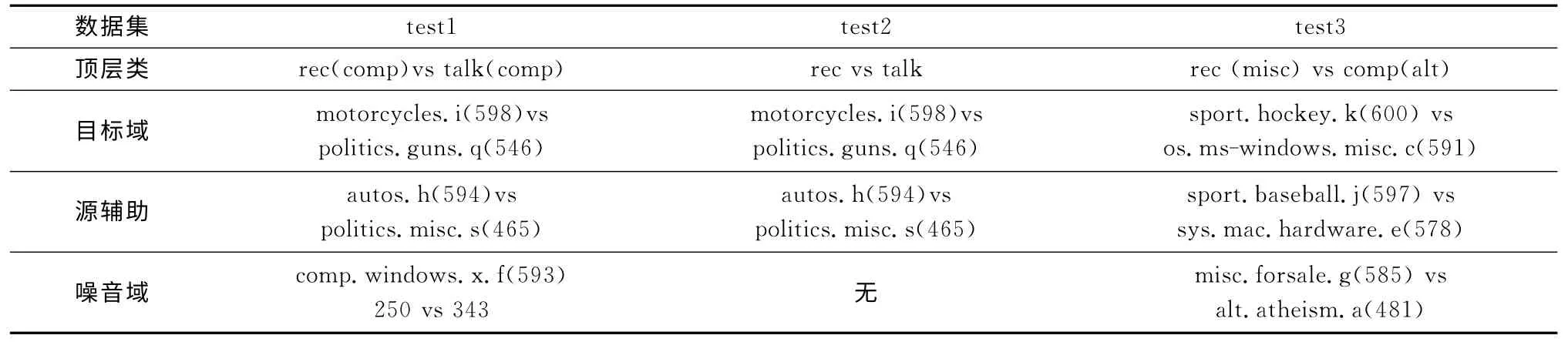
表1 3組實驗數據
4.2 實驗結果與分析
表2列出了選擇遷移算法ADS的3組實驗數據:帶異構噪聲的源輔助數據、無噪音的源輔助數據、多異構噪聲的源輔助數據在單分類器 (支持向量機、樸素貝葉斯、決策樹)和集成分類器 (bagging 和Adaboost兩個算法簇)的P、R、F1結果,集成分類器中分別實驗了支持向量機、樸素貝葉斯、決策樹3種基分類器下的不同集成效果。NB(NaiveBayes)是個體分類器樸素貝葉斯的縮寫,bagging(NB)基于貝葉斯個體分類器的bagging分類模型最適合作為挑選輔助算法的原型。
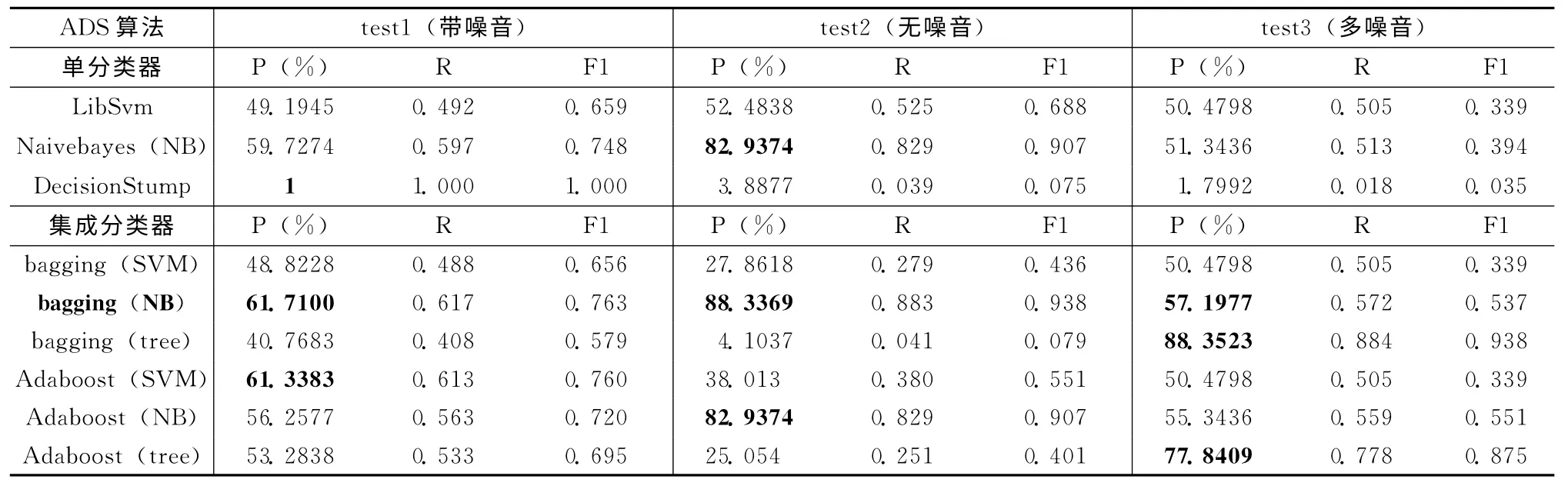
表2 選擇遷移的各分類器結果
由表3不同學習器訓練得出的結果,觀察test1得出以下結論:①總體上運用遷移的思想比直接根據少量目標訓練的分類器性能要好,即在目標領域數據集中加入源輔助(無論有沒有經過挑選)在P、R、F1 上結果都有所提高;②集成bagging的框架下的結果總體性能較高。每4個一組均滿足集成bagging的優越型;③在所有的算法模型中,本文提出的基于選擇遷移的bagging算法得出的精度最高,說明運用ADS算法先從源輔助數據中找出和目標領域最相似的數據,刪除無關數據的必要性,實現跨領域跨分布的數據間的遷移利用,提高學習系統的總體性能;④第二組遷移不挑選數據集合中Transfer LibSvm 精度79.2793%低于第一組不遷移數據訓練的結果84.2843%,利用單分類器遷移出現了負遷移,造成的原因可能是目標與源域的差異過大,但是經過選擇遷移后該狀況就沒有了;⑤和預想有點特殊的是:Naivebayes單分類器的結果比集成Adaboost結果要好,說明該組數據集中各個屬性較獨立,所以Naivebayes精度較高,集成Adaboost是基于迭代,每次結果差異不明顯,所以結果不如預期,也反映了Adaboost的有限性,不如bagging大體上穩定。

表3 不同學習器的結果
對于上述結論,結合test2 無噪音數據對比,test1 中的結論①~③均滿足,即遷移與集成的應用效果明顯,第2組與第3組引入輔助數據后精度基本能達到90%,表明添加輔助是有幫助的,基于選擇遷移的集成bagging算法結果最優,代表本文算法的有效性。集成bagging運用在引入遷移后的混合集中效果明顯,在普通訓練集中效果與不集成的貝葉斯算法相當,說明在目標域數據少量情況下,遷移與集成思想相結合的相輔相成的關系。結論④~⑤不滿足,負遷移現象在無噪音的數據上消失,整體呈現出遷移與選擇遷移的優勢,由于無異構噪音后,在源輔助中的噪音對目標干擾敏感度沒有異構的擾動大,造成不同分布數據的遷移效果好轉。結論⑤中本文可以得出預期的結論:集成的效果要比單分類器好。然而,對test3來說,結論有一些出入。test3中源輔助數據中的人工故意混入的異構噪音和相似領域輔助達到1:1,基本達到噪音的上限,因為當異構噪音比領域相似還要多,就喪失了加入大量相似輔助數據這個前提,即遷移思想引入的初始出發點就不存在了。本文實驗發現此時普通的目標領域訓練的分類模型準確度比加入遷移輔助數據準確率高,此時發生的狀況就是負遷移。但是,第2組遷移實驗和第3組選擇遷移的實驗對比發現,本文提出的選擇遷移后集成的思想優于直接遷移,不刪除噪音數據的源輔助的性能更低,所以除了Transfer LibSvm 算法學習性能上比A-TT LibSvm 高,其它無論是單分類器還是集成分類器都不如挑選后的數據集性能好,一定程度上證明本文的A-TTB算法比傳統的Transfer Bagging的抗負遷移能力強。在test3中普通的目標訓練集訓練反而效果更好,是由于相比較本文選擇20%的原始目標集數據作為訓練集,在數量上還是可以達到幾百到上千篇,這種數據量相對訓練出來的準確率比噪音過大造成干擾要好的多,因此設想當這種訓練集只占1%左右時候,本文的算法優勢應該能突顯出來。
表4列出test3在目標訓練集為1%時的結果,顯示本文A-TTB算法性能最好,突出目標訓練集少量時的穩定性和優越型,適用于目標域訓練集過少和不同分布訓練的條件下。第3組運用遷移、集成框架下的P、R、F1 都比第一組普通目標訓練集集直接訓練的結果要優秀的多,特別是針對LibSvm 算法,準確率從50.381%上升到95.0889%,上升了近50%的精度,說明選擇遷移ADS算法在噪音多的輔助中的重要度和可靠性。而觀察第二組無選擇遷移的情況下,運用集成算法Adaboost反而出現所謂的負遷移,而bagging算法基本和第一組的精度基本一樣,一定程度上說明Adaboost在處理遷移數據集的問題時候對數據集的內部結構有一定的要求,每次結果差異不能太大,只要一次結果偏差過大對后面結果影響較多,訓練的最后結果可能不理想。
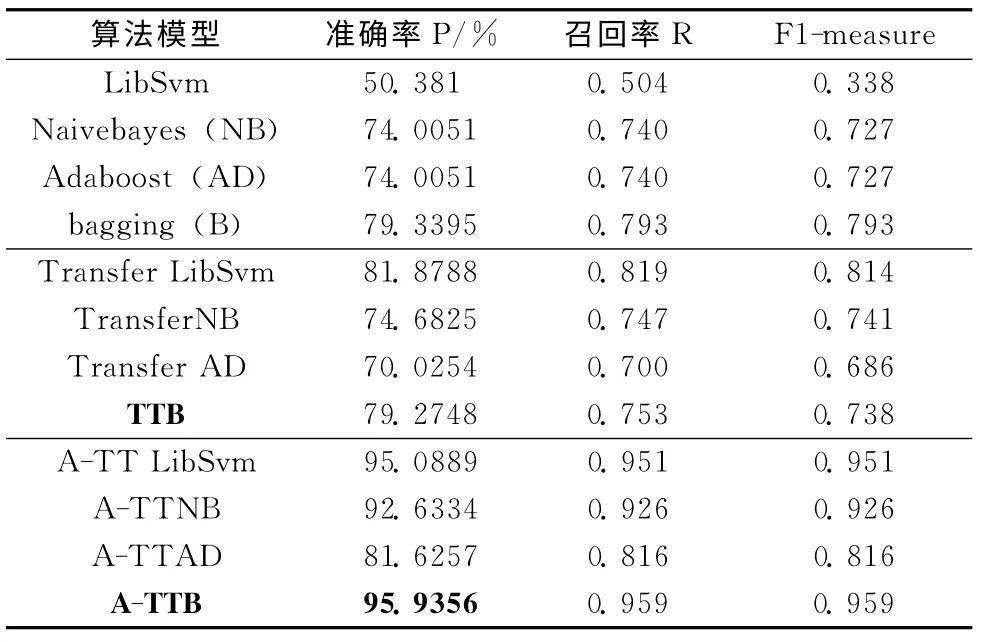
表4 test3目標訓練集為1%時的結果
上述過程已經驗證A-TTB算法的效果,最后簡單討論test1中A-TTB的迭代次數從1~20下的準確率,bootstrap隨機采樣比X=0.8。對20NewsGroup新聞文本政治和摩托車作兩分類,比較20次迭代下的精度和速度,綜合考量迭代次數L 的值。圖1 顯示基分類器個數與精度的關系,當迭代次數為6~19時,準確率達到90%以上,12次時精度下滑但隨后上升并逐步有下滑趨勢。從圖2基分類器個數與效率看出,時間隨迭代次數穩步呈增加趨勢,19次后時間增加很快,在迭代10次時時間有所下降,10~17次穩步增長。因此,本文迭代選擇10次左右較合適。

圖1 test1基分類器個數與精度

圖2 test1基分類器個數與效率
5 結束語
本文提出一種基于選擇遷移的bagging文本分類算法,該方法運用向量空間模型VSM 和tf-idf方法對文本進行預處理,采用合適的分類器根據目標域樣本對源域進行篩選,得出有益的輔助數據加入目標域訓練集中,根據有放回的抽樣bagging集成方法訓練文本分類,由均值投票方式得出最后的模型作為測試集預測的結果。在20新聞組的數據集上的仿真結果表明,該方法能減少噪音數據的干擾,降低分類的復雜度,提高分類的準確率,處理不同分布的數據。日后,研究的重點放在預處理過程中文本的挑選以及投票機制中基分類器的選擇方面。
[1]MEI Canhua,ZHANG Yuhong,HU Xuegang,et al.A weighted algorithm of inductive transfer learning based on maximum entropy model [J].Journal of Computer Research and Development,2011,48 (9):1722-1728(in Chinese). [梅燦華,張玉紅,胡學鋼,等.一種基于最大熵模型的加權歸納遷移學習方法 [J].計算機研究與發展,2011,48 (9):1722-1728.]
[2]QIN Jiaolong,WANG Wei.Imbalanced data classification method for bagging combination [J].Computer Engineering,2011,37 (14):178-179 (in Chinese).[秦姣龍,王蔚.Bagging組合的不平衡數據分類方法 [J].計算機工程,2011,37(14):178-179.]
[3]JIA Yusheng.Research on chinese text categorization technology based on machine learning [J].Computer Knowledge and Technology,2011,7 (21):5194-5196 (in Chinese). [賈昱晟.基于機器學習的中文文本分類技術研究 [J].電腦知識與技術,2011,7 (21):5194-5196.]
[4]HE Ying.Modelling of near-infrared spectroscopy based on semi-supervised learning and transfer learning [D].Qindao:Chinese Marine University,2012 (in Chinese). [賀英.基于半監督和遷移學習的近紅外光譜建模方法研究 [D].青島:中國海洋大學,2012.]
[5]Kamishima T,Hamasaki M,Akaho S.TrBagg:A simple transfer learning method and its application to personalization in collaborative tagging [R].USA:IEEE International Conference on Data Mining,2009:219-228.
[6]LIU Wei,ZHANG Huaxiang.Ensemble transfer learning algorithm based on dynamic dataset regroup [J].Computer Engineering and Applications,2010,46 (12):126-128 (in Chinese). [劉偉,張化祥.數據集動態重構的集成遷移學習[J].計算機工程與應用,2010,46 (12):126-128.]
[7]WANG Shouxuan,YE Bailong,LI Weijian,et al.Comparison of decision tree,native Bayesion and native Bayesion tree[J].Computer Systems &Applications,2012,21 (12):221(in Chinese).[王守選,葉柏龍,李偉健,等.決策樹、樸素貝葉斯和樸素貝葉斯樹的比較 [J].計算機系統應用,2012,21 (12):221.]
[8]DING Shifei,QI Bingjuan,TAN Hongyan.An overview on theory and algorithm of support vector machines [J].Journal of University of Electronic Science and Technology of China,2011,40 (1):2-10 (in Chinese). [丁世飛,齊丙娟,譚紅艷.支持向量機理論與算法研究綜述 [J].電子科技大學學報,2011,40 (1):2-10.]
[9]FENG Guohe.Review of performance evaluation of text classification [J].Journal of Intelligence,2011,30 (8):66-70(in Chinese).[奉國和.文本分類性能評價研究 [J].情報雜志,2011,30 (8):66-70.]
[10]TANG Huanling,YU Liping,LU Mingyu.An enhanced TranCo-Training categorization model with transfer learning[J].Pattern Recognition and Artificial Intelligence,2013,26 (5):432-439 (in Chinese).[唐煥玲,于立萍,魯明羽.融合遷移學習的TranCo-Training分類模型 [J].模式識別與人工智能,2013,26 (5):432-439.]
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
