對數似然相似度算法的MapReduce并行化實現
2015-12-23 00:57:52張明敏張功萱周秀敏
計算機工程與設計 2015年5期
關鍵詞:用戶
張明敏,張功萱,周秀敏
(南京理工大學 計算機科學與工程學院,江蘇 南京210094)
0 引 言
Mahout是Apache軟件基金會 (ASF)旗下的一個開源項目,它是一種機器學習軟件庫,提供了一些包括聚類、分類和協同過濾等機器學習領域經典的算法,旨在幫助開發人員更加方便高效地創建智能應用程序。Mahout還支持Apache社區的Hadoop平臺,并且已經將一部分算法實現MapReduce并行化,以此來作為一種解決機器學習問題的廉價方案[1-4]。
Mahout提供了大量的協同過濾算法的功能,其中比較典型的兩類算法:基于用戶的協同過濾 (user CF)和基于物品的協同過濾 (item CF),都在Mahout中得到了實現。兩種算法都依賴于兩個事物 (用戶或者物品)之間的相似性度量,或者說等同性定義[5]。在協同過濾算法中,相似性的度量是關鍵步驟,也是算法效率的瓶頸所在[6]。然而,Mahout中并沒有提供基于MapReduce的相似度計算方法。在實際應用中,單機的相似度算法受限于內存和效率,無法處理海量的數據。
因此,本文引入了Hadoop集群和MapReduce并行計算模型,研究并實現對數似然相似度算法的并行化。根據算法自身的特點,采用復合鍵對和同現矩陣的思想[7]對MapReduce過程進行優化,然后在Hadoop平臺上運行優化后的算法。
1 MapReduce模型簡介
MapReduce是谷歌公司在2004 年提出的一種軟件架構,主要用來解決大規模數據集在集群上的計算問題,它是一種用于處理和生成大數據集的編程模型[8]。文獻 [9]詳細地描述了MapReduce的核心思想。
MapReduce框架使用兩種類型的組件來控制作業的執行過程。一個是JobTracker,負責作業的分解和狀態的調控。另一個是TaskTracker,負責執行具體的MapReduce程序[10]。根據作業中輸入數據的位置,JobTracker把任務分配給一些TaskTracker,并保證它們協調工作。Task-Tracker運行分配到的任務,同時向Jobtracker匯報任務的進展情況。在執行具體的程序時,每個MapReduce任務又分為map和reduce兩個階段,分別負責分解任務和匯總結果。
在作業開始之前,存儲在Hadoop 分布式文件系統(HDFS)[11]中的數據被切分成很多小的數據集或者碎片(split)。每一個split對應一個map任務,每個map任務又會被分配給靠近該split的節點中的TaskTracker運行。在map階段,map函數接收鍵值對形式的輸入,經過處理產生同樣格式的輸出。然后通過重新洗牌過程[12],將鍵值對分配到各個Reduce節點。在reduce階段,reduce函數將具有相同key值的鍵值對合并,然后對value集合進行處理,產生一個<key,value>形式的輸出。其原理如圖1所示。
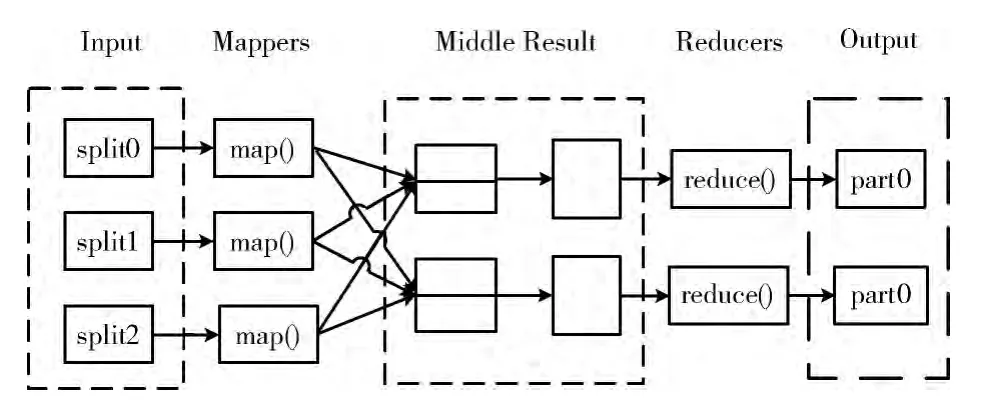
圖1 分布式的MapReduce處理過程
2 對數似然相似度算法的并行化實現
2.1 對數似然相似度算法
Ted Dunnning在1993年提出一種對數似然比的概念,主要應用于自然文本語言庫中兩個詞的搭配關系問題。它是基于這樣一種思想,即統計假設可以確定一個空間的很多子空間,而這個空間是被統計模型的未知參數所描述。似然比檢驗假設模型是已知的,但是模型的參數是未知的。2.1.1 二項分布的對數似然比
對于二項分布的情況,似然函數為
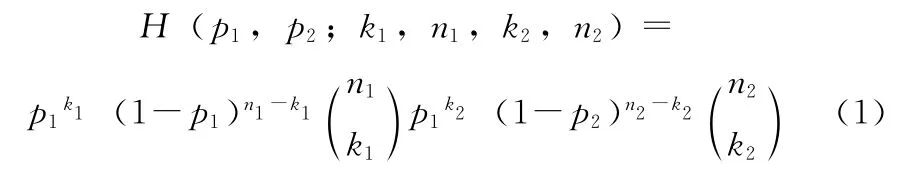
式中:H——給定的統計模型,k1,k2,n1,n2——給定實驗結果的參數。p1,p2——給定模型的參數。
假設二項分布有相同的基本參數集合 {(p1,p2)|p1=p2},那么對數似然比λ就是
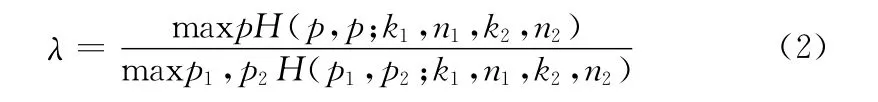
式中:maxpH ——當p取得某值時,統計模型H 的最大值。
當p1=,p2=時,分母取得最大值。當p =時,分子取得最大值。
所以對數似然比簡化為

式中:L——二項分布,n——實驗重復的次數,p——某事件發生的概率,k——該事件發生的次數,L(p,k,n)=pk(1-p)n-k。
兩邊取對數可以將對數似然比的公式變形為,-2logλ=2[logL(p1,k1,n1)+logL(p2,k2,n2)- logL(p,k1,n1)-logL(p,k2,n2)]。
2.1.2 Mahout中對數似然相似度算法的實現
由于二項分布的對數似然比能夠合理地描述兩個事物相似的模型,所以Mahout中利用對數似然比來計算兩個事物(用戶或者物品)的相似度。對數似然相似度基于兩個用戶共同評估過的物品數目,但在給定物品總數和每個用戶評價物品數量的情況下,其最終結果衡量的是兩個用戶有這么多共同物品的 “不可能性”,它是一種不考慮具體偏好值的方法。對數似然相似相似度算法在Mahout中的具體實現為

其中
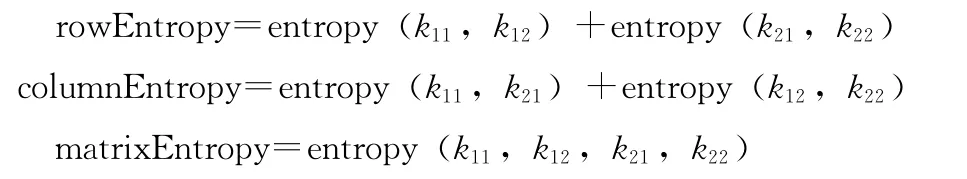
entropy(int...elements)實質上是一種簡單計算熵值的函數。以計算用戶1和用戶2的相似度為例,k11表示兩個用戶共同偏好的item 數量,k12表示用戶1偏好而用戶2不偏好的item 數量,k21表示用戶2偏好而用戶1不偏好的item 數量,k22表示用戶1和用戶2都不偏好的item 數量,可以將這4個變量看成一個二維矩陣),然后計算這個矩陣的行熵 (rowEntropy)、列熵 (columnEntropy)和矩陣的熵(matrixEntropy),從而得出相似度值。
通過上述過程可以發現,相似度的計算最終可以歸結為計算k11,k12,k21和k22的值。進一步分析可以得到,k12=k1-k11,k21=k2-k11,k22=item 總數-k1-k2+k11。其中k1,k2分別為用戶1和用戶2偏好的物品個數。區域具體分布情況如圖2所示。在計算過程中,只需獲得item 總數,用戶1和用戶2分別偏好item 的個數以及他們共同偏好的物品個數,就能得出所需的4個參數值。
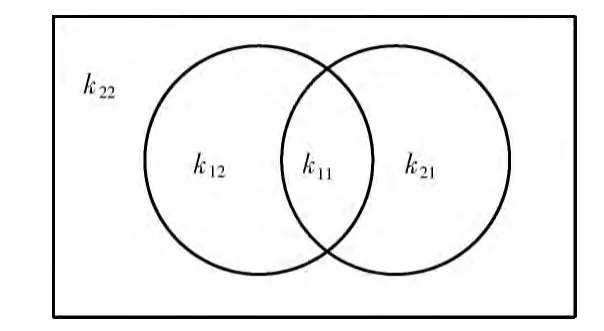
圖2 4個區域的分布
2.2 算法的MapReduce實現
下面以計算用戶之間的相似度為例,具體介紹對數似然相似度算法的并行化過程。以表1中的二維矩陣為例,其中U1,U2,U3為用戶,I1,I2,I3,I4為物品。表格中的數字1表示某個用戶偏好該物品,空白表示用戶不偏好該物品。
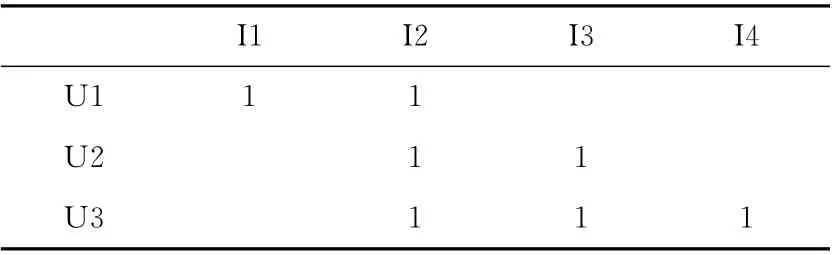
表1 二維偏好矩陣
Loglikelihood相似度并行計算將拆分成4 個MapReduce任務。第1 個MapReduce任務計算每個用戶偏好的物品總數。第2 個MapReduce任務將偏好某個物品的用戶放到一條記錄中,形成以物品為鍵、偏好該物品的所有用戶為值的倒排列表。第3個MapReduce任務計算兩兩用戶共同偏好的物品個數,并且記錄物品的總個數numItems。第4個MapReduce任務計算相似度。具體過程如圖3所示。
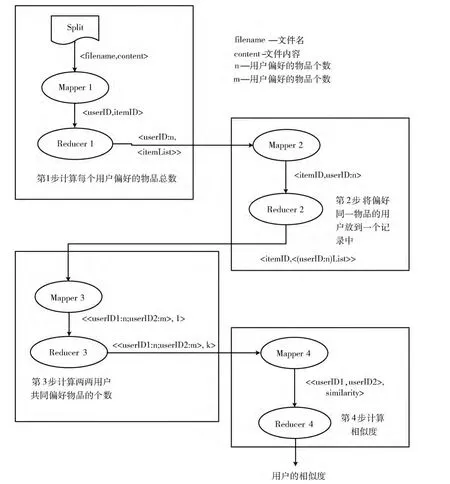
圖3 MapReduce的并行化過程
第1個MapReduce過程稱為倒排索引,其輸入數據在文件中的存儲格式為<用戶,物品,偏好值>。首先將文件分割成splits并按行作為程序的輸入,然后將<每行的偏移量,每行的內容>形式的鍵值對交付給程序中定義好的map函數進行處理。對每個用戶,以用戶和用戶偏好的物品個數為鍵,該用戶偏好的所有物品列表為值,中間用分號隔開,這樣我們就能得到如<U1:2,<I1;I2>>、<U2:2,<I2;I3>>以及<U3:3,<I2;I3;I4>>格式的輸出。這樣做的目的是,能夠統計出每個用戶偏好的物品總數,為下面計算k12和k21打下基礎。
第2個MapReduce過程還是倒排索引,其輸入為第1步MapReduce輸出的結果。map階段以每一個物品為鍵,偏好該物品的用戶和用戶偏好的物品總數為值作為輸出。然后經過重新洗牌過程發送到Reduce節點,reduce函數將具有相同key值 (物品)的所有value組合起來,中間用分號隔開,這樣就能得到如<I1,U1:2>、<I2,<U1:2;U2:2;U3:3>>、<I3,<U2:2;U3:3>>以及<I4,U3:3>格式的輸出。這樣做的好處是,將偏好同一物品的所有用戶都聚集在同一個value下,方便下一步MapReduce任務的處理。
第3個MapReduce過程主要是計算用戶兩兩之間共同偏好物品的個數即k11,以及物品的總個數,其輸入為第2步MapReduce輸出的結果。對每一條記錄,map函數丟棄掉key值,將value中的用戶兩兩配對,并作為鍵值,value值設置為1。同時,map函數通過逐行讀入數據,記錄下總行數,即物品的總個數numItems。Reduce函數將具有相同鍵值的value值相加,得出兩兩用戶共同偏好物品的總個數。最終可以得到以下輸出:<<U1:2;U2:2>,1>,<<U1:2;U3:3>,1>,<<U2:2;U3:3>,2>。
第4個MapReduce過程真正用來計算用戶兩兩之間的相似度。其以上一步MapReduce輸出的結果為輸入,從每一條記錄里面能夠提取到k11,k1,k2以及上一步MapReduce過程計算好的物品總個數numItems。通過k1,k2,numItems能夠分別計算出k12,k21和k22的值,然后調用函數loglikelihoodRatio (k11,k12,k21,k22),最終計算出相似度的數值。
4個MapReduce任務采用順序組合的方式[13],每個MapReduce任務都需要配置自己的運行代碼,并按照前后關系正確的配置輸入/輸出的路徑。程序運行后,會按照MapReduce任務之間的順序逐個運行作業。因為前一個MapReduce任務的輸出要作為后一個MapReduce任務的輸入,所以需要調用job.waitForCompletion (true)來保證前一個子任務執行完成后再執行下一個子任務。
2.3 MapReduce任務的優化
初步分析和運行上述4 步MapReduce任務可以發現,第3步MapReduce任務執行的時間最長,其原因主要是:這一步MapReduce任務產生大量的鍵值對,而且這些鍵值對無法用combiner處理,Hadoop將它們寫到磁盤上時需要耗費大量的時間。針對一條記錄,假設同時對一個物品有偏好的用戶數有n個,那么在第3步map函數將產生n* (n-1)/2個鍵值對,時間復雜度為O(n*n)。當n=10000時,鍵值對數目將達到10億數量級。即使一臺機器處理一條記錄,也會非常耗費資源,達不到預期的效果。而且map階段產生的鍵值對需要傳輸給Reduce節點,不但增加網絡通信的開銷,而且使得reduce階段的copy和sort過程非常緩慢。因此,本文根據Jimmy Lin的單詞同現矩陣的思想,提出一種將大量小的鍵值對合并為較大鍵值對的方法,大幅減少傳送給Reduce節點的鍵值對數量。
如圖4所示,針對第2步MapReduce產生的一條記錄<I2,<U1:2;U2:2;U3:3>>,原先產生的許多小鍵值對可以合并成右側大的鍵值對。然后,在Reduce階段,將具有相同key值的鍵值對進行累加,即可獲得一個用戶同其他用戶共同偏好物品的關系及其具體的個數。還是假設同時對一個物品有偏好的用戶數有n個,那么在這一步map函數將產生n-1 個鍵值對,時間復雜度為O(n),所產生的鍵值對數量遠遠小于原來的步驟。此時的MapReduce相應的偽代碼如圖5所示。
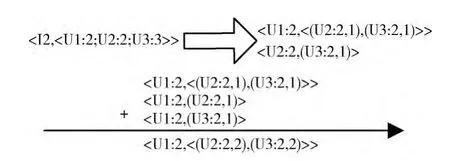
圖4 第3步MapReduce的優化過程

圖5 MapReduce過程的偽代碼
3 實驗和結果分析
3.1 實驗環境
Hadoop集群為建立在openstack云平臺上的6臺虛擬機,其中,1臺為主節點 (master),5臺為從節點(slave)。每臺虛擬機的主要配置如下:兩個虛擬內核,內存為2G,磁盤為10G。Java版本為Java-7-oracle,Linux系統為Ubuntu12.04,Hadoop版本為1.2.1。
3.2 實驗及結果分析
實驗數據:本實驗采用的數據集來自于GroupLens提供的電影評分集。該數據集包含6000 多位用戶對3900 多部電影的一百多萬條評分記錄。評分數據集中包含用戶ID,電影ID,評分和時間戳。用戶ID 的區間為1 到6040,電影ID 的區間為0到3952,評分區間為0到5,每個用戶至少對20部電影的進行評分。因為,對數似然相似度是處理無評分數據的,所以可以將用戶對某部電影評分,視為用戶看過該電影,用戶沒有對某部電影,視為用戶沒有看過該電影。
實驗設置:本實驗采用Eclipse作為集成開發環境。首先,在單機環境中,調用Mahout中計算對數似然相似度的函數,統計運行時間。然后,分別采用1,2,3,4,5 個節點的集群,運行本文所提出的并行化的算法,統計運行時間。最后,將單機運行時間與集群運行時間進行比較。
實驗結果:由圖6可以看出,當節點數為1~2個的時候,集群運行的效率遠低于單機運行效率。其主要原因有兩個:對于集群而言,一是任務的啟動和交互占據一定的時間,尤其當實際的計算量比較小時,集群的優勢無法體現出來;二是數據網絡傳輸的影響。單機版的相似度算法首先會將數據全部讀入內存,然后進行計算,所以處理的速度比較快。而在Hadoop集群中,Map函數先將數據寫到磁盤上,然后Reduce函數再從磁盤上讀取數據,增加了數據傳輸的時間。但是當集群節點數大于3個的時候,集群的優勢就開始逐漸體現出來。由此可知:當節點數達到一定數量時,集群的運行效率要優于單機的運行效率。

圖6 集群和單機運行時間的對比
加速比S=Ts/Tm 是衡量并行系統或程序并行化性能的重要指標。其中,S是加速比,Ts是單機算法的運行時間,Tm 是m 個節點運行的時間。由圖7 可以看出,加速比隨著集群節點數的增加而增大,當節點數大于4時,加速比大于1。這說明,基于Hadoop集群的對數似然相似度算法具有較好的加速比。而且,隨著集群節點數量的增加,這種優勢將會更加明顯。
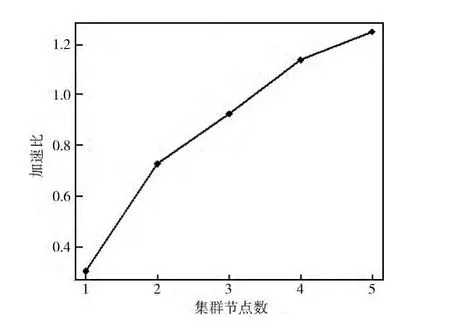
圖7 集群的加速比
4 結束語
Hadoop集群和MapReduce編程模型是當前解決海量數據問題的主要解決方案,Mahout結合Hadoop將使得數據的挖掘和分析更加高效和便捷。本文主要探討了Mahout中對數似然相似度算法的并行化問題,并使用MapReduce編程模型在Hadoop 平臺上實現了該算法,并且優化了其中的MapReduce過程。相關的實驗結果表明,在處理大數據集時,并行算法的運行效率要優于單機算法的運行效率。集群規模越大,算法的執行效率越高,加速比越明顯。
[1]DanEr CHEN.The collaborative filtering recommendation algrorithm based on BP netral networks[J].Computer Society of IEEE,2009,121:234-235.
[2]Apache Mahout.The apache software foundation [EB/OL].[2012-02-06].http://mahout.apache.org.
[3]Apache Hadoop.The apache software foundation [EB/OL].[2012-04-01].http://hadoop.apache.org.
[4]Esteves RM,Rong C.K-means clustering in the cloud-a mahout test [J].Computer Society of IEEE,2011,136:515-516.
[5]Sean Owen,Robin Anil,Ted Dunning,et al.Mahout in action [M].US:Manning Publications,2010:41-42.
[6]MA Ning.Research and implementation of recommendation system based on mahout[D].Lanzhou:Lanzhou University,2012:30 (in Chinese).[馬寧.基于Mahout推薦系統的研究與實現 [D].蘭州:蘭州大學,2012:30.]
[7]Jimmy Lin,Chris Dyer.Data-intensive text processing with MapReduce [M].US:University of Maryland,College Park,2010:39-52.
[8]Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters [J].Communications of ACM,2008,51(1):107-113.
[9]LANG Weimin,YANG Depeng.MapReduce technology on cloud computing [J].Telecommunications Information,2012,3:3-5 (in Chinese).[郎為民,楊德鵬.云計算中的MapReduce技術 [J].電信快報,2012,3:3-5.]
[10]Narayan S,Bailey S,Daga A.Hadoop acceleration in an open flow-based cluster [J].Computer Society of IEEE,2012,76:535-538.
[11]Konstantin Shvachko,Hairong Kuang,SanjayRadia,et al.The Hadoop distributed file system [C]//Mass Storage Systems and Technologies,2010:1-10.
[12]YAN Yonggang,MA Tinghuai,WANG Jian.Parallel implementing KNN classification algorithm using MapReduce programming mode[J].Journal of Nanjing University of Aeronautics and Astronautics,2013,45 (4):551-554 (in Chinese).[閆永剛,馬廷淮,王建.KNN 分類算法的MapReduce并行化實現 [J].南京航空航天大學學報,2013,45(4):551-554.]
[13]LIU Peng.Hadoop in action [M].Beijing:Electronic Industry Press,2011:142-143 (in Chinese). [劉鵬.實戰Ha-doop [M].北京:電子工業出版社,2011:142-143.]
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
