基于信息熵的粗糙K-prototypes聚類算法
2015-12-23 01:00:12歐陽浩戴喜生王智文
計算機工程與設計 2015年5期
歐陽浩,戴喜生,王智文,王 萌
(1.廣西科技大學 計算機學院,廣西 柳州545006;2.廣西科技大學 電氣與信息工程學院,廣西 柳州545006)
0 引 言
現實世界中存在的數據對象,通常既具有數值屬性也具有分類屬性。但大多現有的聚類[1-5]算法只能分析數值屬性或者分類屬性[6-7],當它們在分析混合屬性的數據對象時,首先需要完成數據類型的轉化。針對這一問題,Huang提出了K-prototypes算法,該算法是將可分析數值屬性的K-means算法與可分析分類屬性的K-mode算法相結合而設計的算法[6]。K-prototypes算法可以分析混合屬性,但具有一定缺陷:①對初始均值點的選擇敏感;②容易受到噪聲干擾;③樣本間的差異度計算對于分類屬性不明顯[7-10];④不能分析模糊以及不確定性問題等[11-13]。針對問題①-③,文獻 [7]提出了二次聚類的方式,并且對于數值屬性的差異度計算采用比值方式將其映射為區間(0,1]之間的值,但此方法需重復聚類計算分析;文獻 [8]計算新插入樣本的分類屬性值,以在整個簇中此屬性值出現的頻率來判斷二者之間的距離;文獻 [9,10]通過計算簇中樣本與均值點數值屬性的差值之和的倒數,來確定每個數值屬性的權值。針對問題④,文獻 [11-13]對于K-prototypes算法引入了模糊理論的概念,使其具有一定的解決模糊性和不確定性問題的能力;文獻 [14]采用層次聚類的方式實現混合屬性的聚類分析;文獻 [15]采用自組織神經網絡的方式完成聚類分析。以上各文獻的方法均無法確定每個分類屬性對于聚類結果的影響,恰恰在現實生活中,每個分類屬性對于分類或聚類的結果的影響程度是不同的[16]。而且,這些算法缺乏在知識不完備的情況下對于不確定性問題的分析能力。
本文首先引入信息熵理論,聚類分析中,通過計算各分類屬性的信息增益,確定此屬性的權值大小。然后,通過粗糙的分析方式[17],使得此算法在數據存在噪聲、不夠精確、不夠完整的情況下,也能做出較好的分析。實驗結果表明,本文提出的基于信息熵的粗糙K-prototypes 聚類算法 (entropy rough K-prototypes,ER-K-prototypes)有效。
1 K-prototypes算法
K-prototypes算法是將K-means算法與K-mode相結合而設計的一種新的算法,此算法可以處理混合屬性的數據集[3]。令U ={x1,x2,…,xn}表示由n個樣本構成的集合。其中,xi={xi1,xi2,…,xip,xi(p+1),…,xm}表示第i個樣本,其具有m 個屬性,其中前p個屬性為數值屬性,而p+1至m 個屬性為分類屬性。與K-prototypes算法相關的定義如下描述。
定義1 樣本間數值屬性距離。本文數值屬性的距離采用歐氏距離,給定任一兩個樣本xi和xj,其數值屬性的距離d1定義為
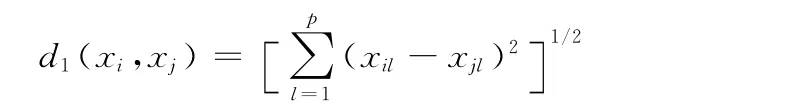
定義2 樣本間分類屬性距離。給定任一兩個樣本xi和xj,其分類屬性的距離d2定義為
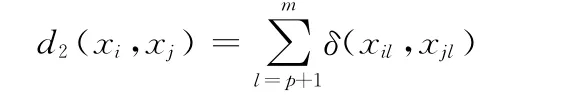
其中

定義3 樣本間相異度。給定任一兩個樣本xi和xj,樣本間的相異度為數值屬性距離d1和分類屬性距離d2之和,其定義為

其中,γ為分類屬性的權重。
定義4 模。令vi表示為類Ci的模,其中類Ci由h 個樣本對象構成,即Ci={x1,x2,…,xh}。則,模vi的數值屬性取類Ci中各個樣本的數據屬性的平均值,而分類屬性取類Ci中各個分類屬性中出現頻率最高的值。
定義5 平均誤差函數。設p為樣本對象,vi為類Ci的模,則聚類的平均誤差函數定義為

K-prototypes算法的算法描述如下:
輸入:n 個樣本對象;類的數目k;分類屬性的權重γ;停止閾值ε。
輸出:聚類結果。
步驟如下:
(1)隨機選擇k個樣本作為初始類的模;
(2)按照定義3的公式計算各個樣本對象與各個模之間的距離,并且將此樣本對象劃分到與之距離最近的模所代表的類中;
(3)對于每個類按照定義4重新計算出類的模。
按照定義5計算出聚類的平均誤差E。Epre表示上一次計算的平均誤差,當|E-Epre|<ε時停止算法。否則,跳轉到步驟 (2)。
2 基于信息熵的分類屬性相異度
K-prototypes算法在計算分類屬性時,并未區分各個分類屬性對于聚類結果的影響程度。在現實生活中,不同的分類屬性對于聚類結果的影響程度是不同的,如在分析客戶信息時,其中電話號碼,姓名等分類屬性,它們并不能有助于聚類的計算。經典的決策樹ID3算法中,在分類過程中,引入了信息熵的相關概念[13]。本文也將使用信息熵的概念來確定各個分類屬性的重要程度,并且根據其重要性重新定義樣本間的相異度。基于信息熵的分類屬性相異度相關的定義如下。
定義6 信息熵。設S是n 個數據樣本的集合,將樣本集劃分為c個不同的類Ci(i=1,2,…,c),每個類Ci含有的樣本數目為ni,則S 劃分為c 個類的信息熵為
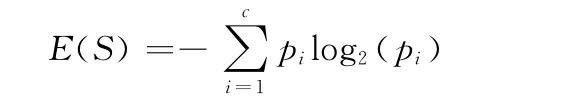
其中,pi為S 中的樣本屬于第i類Ci的概率,即pi=ni/n。
定義7 期望熵。假設屬性A 的所有不同值的集合為Value(A),Sv是屬性A 的值為v 的樣本子集,即Sv={s∈S|A(s)=v}。屬性A 對樣本集Sv分類的熵為E(Sv),而屬性A 的期望熵為

定義8 信息增益。屬性A 相對樣本集合S 的信息增益Gain(S,A)定義為
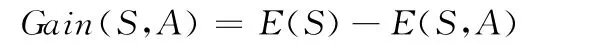
基于信息熵的分類屬性相異度計算,對于經典的Kprototypes算法中分類屬性距離的計算做了相應的調整,其變化如定義9所示。樣本間相異度的調整見定義10。
定義9 基于信息熵的樣本間分類屬性距離。給定任一兩個樣本xi和xj,它們的分類屬性包括Al(l=p+1,…,m),則基于信息熵的樣本間分類屬性距離dEntropy2定義為

定義10 基于信息熵的樣本間相異度。給定任一兩個樣本xi和xj,樣本間的相異度為數值屬性距離d1和基于信息熵的分類屬性距離dEntropy2之和,其定義為

其中,γ為分類屬性的權值。
3 ER-K-prototypes算法
3.1 ER-K-prototypes的粗糙性
經典的K-prototypes聚類算法對于孤立點敏感,且初始類中心的選取將影響聚類結果。為解決這些問題。模糊K-prototypes從集合的含混性的角度來完成混合型數據的聚類分析。本文將從知識表達的不精確性[2]的角度,將粗糙集的概念引入K-prototypes聚類算法中。
文獻 [18]中提出了基于粗糙集理論的聚類算法需要遵循的三條原則:
(1)一個樣本只能屬于一個類的下近似。
(2)若樣本屬于某個類的下近似,那么它也屬于這個類的上近似。
(3)若樣本不屬于任何類的下近似,那么它屬于兩個或兩個以上類的上近似。
定義11 粗糙模。U ={x1,x2,…,xn}表示由n個樣本構成的集合。其中,xj={xj1,xj2,…,xjp,xj(p+1),…,xm}表示第j個樣本,其具有m 個屬性,其中前p 個屬性為數值屬性,而p+1至m 個屬性為分類屬性。引入粗糙集理論后,用表示類Ci的上近似,C-i表示類Ci的下近似,表示Ci的邊界,并且=-。類Ci的粗糙模vi的數值屬性的計算公式如下


以上計算中,c表示模的數目;wl,wbn則分別表示模的下近似和邊界的權值,而且在分析中wbn表示了模的粗糙性,一般則表示類Ci的下近似和邊界中樣本的數量。
而對于vi的分類屬性,則取各個分類屬性中出現頻率最高的值

基于信息熵的粗糙K-prototypes聚類算法將計算各樣本xj與各個粗糙模v 的距離,其中(xj,vi)表示最小距離,(xj,vk)表示次小距離,當二者的差值小于一定粗糙距離閾值η時,即|(xj,vi)-(xj,vk)|<η,則認為該樣本屬于這兩個模的上近似,否則將此樣本劃分到最近模的下近似中,從而完成聚類分析。
3.2 ER-K-prototypes算法描述
根據以上的理論描述,以下給出基于信息熵粗糙Kprototypes的算法描述。
輸入:n 個樣本對象;類的數目k;分類屬性的權值γ;下近似權值wl,邊界權值wbn;粗糙距離閾值η;停止閾值ε。
輸出:聚類結果。
步驟如下:
(1)隨機選擇k個樣本作為初始的類的粗糙模;
(2)按照定義10的公式計算任意樣本對象xj與各個粗糙模v之間的距離;
(4)對于每個類,按照定義11 重新計算出類的粗糙模;
(5)按照定義5計算出聚類的平均誤差E,此處的模為步驟 (3)計算所得的粗糙模。Epre表示上一次計算的平均誤差,當|E-Epre|<ε時停止算法。否則,跳轉到步驟 (2)。
4 算法驗證
4.1 正確率評價函數
為比較各算法分析中的正確率,本文引用文獻 [4]中的聚類正確率的定義,其描述如下。
定義12 聚類正確率。聚類算法f 將樣本集合U ,劃分為k個類,用corr_ci表示第i個類中被正確聚類樣本的個數,|U |表示集合中樣本個數。則聚類的正確率ac_rate(D/f)為
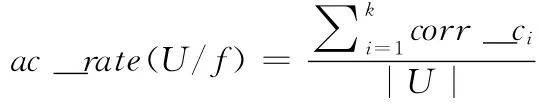
4.2 實驗驗證
本文采用Visual C++編寫實驗程序分析算法的有效性,運行環境為:Intel(R)Core(Tm)2Duo CPU ET500@2.93GHz 2.93GHz,2.0GB內存,Window 7系統。實驗數據為UCI機器學習庫[19]中的Heart Disease (簡稱Heart),Acute Inflammations (簡稱Acute),Credit Approval(簡稱Credit),Zoo這4個混合型數據集。數據集描述見表1。

表1 數據集描述
與本文提出的ER-K-prototypes相比較的算法為同樣對混合型數據具有分析能力的K-prototypes算法以及Fuzzy-K-prototypes算法。在分析前,需要對各數據集進行歸一化處理,以消除各數據屬性因為取值范圍的不同而帶來的干擾。分類屬性的權值γ取值為:分類屬性數/數值屬性數;下近似權值wl=0.9;邊界權值wbn=0.1;粗糙距離閾值η取值為:屬性總數×0.1;停止閾值ε 取值為:0.001;樣本數n與類別數目k 根據表1中的實際情況設定。其它參數以及最終的聚類的正確率見表2。
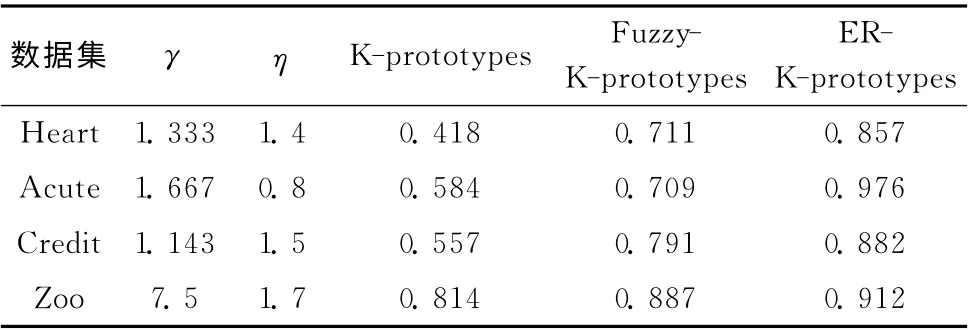
表2 部分參數及聚類正確率比較
從表2可以看出,ER-K-prototypes正確率明顯優于Kprototypes和Fuzzy-K-prototypes,從而驗證此算法是有效的。從定性上分析,其有效性來自于兩個方面。
一方面,ER-K-prototypes在計算分類屬性距離時,通過計算各個分類屬性的信息熵來確定其在計算過程中的權值,從而確保對于有效的聚類起關鍵影響的屬性,其權值更大,從而有利于聚類分析逐漸趨于正確。此更符合現實中事物的屬性特征。
另一方面,ER-K-prototypes引入了粗糙集的概念,從而具備一定的處理非確定性問題的能力。在背景知識不確定、不完整,或者存在噪聲時,不需要引入先驗知識的前提下,也能做出比較正確的分析。
5 結束語
傳統的K-prototypes,在對混合型數據進行聚類分析時,將屬性分為兩大類:數值屬性和分類屬性。在聚類計算時,并未考慮各個屬性對于聚類結果的影響程度。Fuzzy-K-prototypes雖然引入了模糊性的概念,但對分類屬性的分析同樣存在此問題。本文提出的ER-K-prototypes引入了信息熵的概念,分析時需確定各分類屬性的信息增益,此更符合現實中的分類問題。同時,ER-K-prototypes引入的粗糙集概念,能處理非確定性問題,可以在一定程度上避免噪聲的干擾。實驗驗證此方法更有效。
ER-K-prototypes對于數值屬性的分析還不完善,需要今后做進一步的研究。同時在以后的研究中,需要將粗糙理論與模糊理論相結合,應用于混合數據的聚類分析中。
[1]Han Jiawei,Micheline Kamber,Pei Jian.Data mining:Concept and techniques [M].3rd Edition.Beijing:China Machine Press,2012.
[2]Saeed Aghabozorgi,Ying Wah Teh.Stock market co-movement assessment using a three-phase clustering method [J].Expert Systems with Applications,2014,41 (4):1301-1314.
[3]Donatella Vicari,Marco Alfó.Model based clustering of customer choice data[J].Computational Statistics &Data Analysis,2014,71:3-13.
[4]Dhiah Al-Shammary,Ibrahim Khalil,Zahir Tari,et al.Fractal self-similarity measurements based clustering technique for SOAP Web messages [J].Journal of Parallel and Distributed Computing,2013,73 (5):664-676.
[5]Michael Hackenberg,Antonio Rueda,Pedro Carpena,et al.Clustering of DNA words and biological function:A proof of principle [J].Journal of Theoretical Biology,2012,297(21):127-136.
[6]Huang Z.Clustering large data sets with mixed numeric and categorical values [C]//Proceedings of the First Pacific Asia Knowledge Discovery and Data Mining Confenence,Singapore:World Scintific,1997:21-34.
[7]SUN Haojun,SHAN Guanghui,GAO Yulong,et al.Algo-rithm for clustering of high-dimensional data mixed with numeric and categorical attributes [OL]. [2013-11-14].http://d.g.wanfangdata.com.cn/Periodical _pre _849c8593-e9c8-4664-aa16-c3e122d74bc8.aspx (in Chinese). [孫 浩軍,閃光輝,高玉龍,等.一種高維混合屬性數據聚類算法 [OL].[2013-11-14].http://d.g.wanfangdata.com.cn/Periodical_pre_849c8593-e9c8-4664-aa16-c3e122d74bc8.aspx.]
[8]CHEN Wei,WANG Lei,JIANG Ziyun.K-prototypes based clustering algorithm for data mixed with numeric and categorical values [J].Journal of Computer Applications,2010,30 (8):2003-2005 (in Chinese). [陳韡,王雷,蔣子云.基于K-prototypes的混合屬性數據聚類算法 [J].計算機應用,2010,30 (8):2003-2005.]
[9]Ji Jinchao,Bai Tian,Zhou Chunguang,et al.An improved K-prototypes clustering algorithm for mixed numeric and categorical data[J].Neurocomputing,2013,120:590-596.
[10]Huang ZX,Ng MK,Rong HQ,et al.Automated variable weighting in k-means type clustering [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27 (5):657-668.
[11]CHEN Ning,CHEN An,ZHOU Longxiang.Fuzzy K-prototypes algorithm for clustering mixed numeric and categorical valued data[J].Journal of Software,2001,12 (8):1107-1119 (in Chinese).[陳寧,陳安,周龍驤.數值型和分類型混合數據的模糊K-prototypes 聚類算法 [J].軟件學報,2001,12 (8):1107-1119.]
[12]ZHOU Caiying,HUANG Longjun.Improvement of the method to choosing the initial value of fuzzy K-prototype clustering algorithm [J].Computer Science,2010,37 (7A):69-70 (in Chinese).[周才英,黃龍軍.模糊K-prototype聚類算法初始點選取方法的改進 [J].計算機科學,2010,37(7A):69-70.]
[13]Ji Jinchao,Pang Wei,Zhou Chunguang,et al.A fuzzy Kprototype clustering algorithm for mixed numeric and categorical data[J].Knowledge-Based Systems,2012,30:129-135.
[14]Chung-Chian Hsu,Chen Chinlong,Su Yuwei.Hierarchical clustering of mixed data based on distance hierarchy [J].Information Sciences,2007,177 (20):4474-4492.
[15]Tai Weishen,Chung-Chian Hsu.Growing self-organizing map with cross insert for mixed-type data clustering [J].Applied Soft Computing,2012,12 (9):2856-2866.
[16]Quinlan JR.Induction of decision tree [J].Machine Learning,1986 (1):81-106.
[17]HU Qinghua,YU Daren.Application rough computation[M].Beijing:Science Press,2012 (in Chinese). [胡清華,于達仁.應用粗糙計算 [M].北京:科學出版社,2012.]
[18]GUO Jinhua,MIAO Duoqian,ZHOU Jie.Shadowed sets based threshold selection in rough clustering [J].Computer Science,2011,38 (10):209-210 (in Chinese). [郭晉華,苗奪謙,周杰.基于陰影集的粗糙聚類閾值選擇 [J].計算機科學,2011,38 (10):209-210.]
[19]UCI database [EB/OL].http://archive.ics.uci.edu/ml/datasets.html,2013.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
山東青年(2016年1期)2016-02-28 14:25:25
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
當代修辭學(2014年3期)2014-01-21 02:30:44
