基于鏈接和螢火蟲算法聚類博文發現熱點話題
2015-12-23 01:02:04王雅琳陸向艷
計算機工程與設計 2015年6期
王雅琳,陸向艷,鐘 誠
(廣西大學 計算機與電子信息學院,廣西 南寧530004)
0 引 言
基于純文本的熱點話題發現方法未考慮網頁文本的特殊性,獲得的結果準確度不高[1-3],為此,研究者開始關注網頁特征,在文本挖掘的基礎上加入鏈接分析。文獻 [4]在內容計算網頁相似度的基礎之上,引入鏈接分析,提高了話題相關性度量的準確度;文獻 [5]通過頁面鏈接來估計信息的傳播性質,并對信息的熱度進行度量;文獻 [6]運用復雜網絡理論構建文本的加權復雜網絡模型,從而形成更準確的文本特征值。文獻 [4-6]在基于文本挖掘的基礎上與鏈接分析相結合,一定程度上提高了話題發現的準確度,但未能避免文本向量化及特征提取等耗時的文本處理,因此計算復雜度較高。為處理大規模Web數據挖掘以實時發現輿情熱點,基于鏈接分析的熱點發現方法被提出。HITS算法[7]以及PageRank算法[8]利用鏈接分析的方法來獲得網頁排名。這些方法僅以網頁之間的鏈接為研究對象,通過分析鏈接關系找到熱點話題。文獻 [9]將HITS算法和PageRank算法相結合,給出一種基于鏈接分析的網絡輿情熱點發現方法,該方法計算復雜度較低,但該方法的頁面權重完全依賴與之有鏈接關系的頁面的質量,而頁面的質量僅靠鏈入鏈出數量來決定,這種頁面權重計量方法易受作弊鏈接的影響,即為了提高的網頁排名,作弊者自行加入許多指向權威頁面的鏈接,且其未考慮頁面的時效性,相對發布時間較早的網頁易獲得更高的網頁權重,其對鏈接未加以選擇,且對所有的鏈接均賦予相同的權重。因此,該方法仍然未能解決HITS算法和PageRank算法存在的抵抗作弊鏈接能力較弱的缺陷以及主題漂移問題。
本文的主要貢獻是:利用復雜網絡簇結構高度主題相關的特點,以頁面為節點,將清洗后的鏈接作為邊,并考慮了時間因素對頁面權重的影響,頁面權重由博文及博主的相關屬性綜合評定,從而建立博客話題模型;采用螢火蟲算法對形成的無向有權圖進行聚類獲得聚類中心,將聚類中心按頁面權重從大到小排序,最終形成熱點的話題熱度排行;設計實現一種有效避免作弊鏈接不良影響、克服主題漂移現象、可挖掘出精度更高且數量更多的博客熱點話題算法。
1 博客話題模型
1.1 模型結構
文獻 [10]闡述了因特網屬于復雜網絡,網絡簇結構具有同簇節點連接密集、異簇節點連接稀疏的自組織特點,并且證實了自組織方式形成的Web 簇具有高度主題相關性。相較于因特網上的其它信息,博客領域的話題更加分散且觀點呈現個性化特征,表述也更規范,并且通常代表一種相對單一的觀點。
為了從博主所發的博文中高效準確地挖掘出熱點話題,本文在文獻 [11]給出的網絡社區話題結構的基礎上設計了一個博客話題模型,該模型由博文層、事件層和話題層組成,如圖1所示。最底層是博文層,即原始網絡,主要是由博主發出的博文以及相關鏈接組成。中間層為事件層,該層是將博文層中不同博主發出的關于某一事件的博文聚在一起,形成對該事件較為全面的描述。頂層是話題層,它將事件層中的同類事件聚合在一起,形成一個話題。該話題的核心即是影響力最大的博文,博文的博主即為該話題的精神領袖。在博文層,博文由博文熱度、鏈接以及鏈接權重組成,第m 個博文的表示方式為Articlem= {Articlehotnessm,Linkm,Linkweightm};事件層的事件由博文組成,Eventp表示博文集中的第p 個事件,Eventp= {Article1,…,Articles};話題層中的話題由事件組成,Topicq表示博文集中的第q 個話題,Topicq= {Event1,…,Eventr}。
1.2 博文熱度
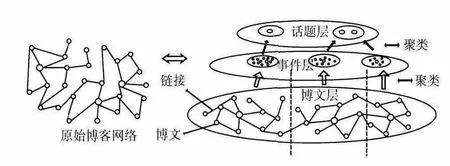
圖1 博客話題模型的三層結構
在博客領域,博主被關注的人數越多,所發出的博文被評閱以及收藏轉發的可能性就越大;博文的閱讀量越大,表明該博文受到的關注度越高;評論數及收藏量越大,表明該博文獲得的認可度越高博文被轉發的可能性就越大;博文的轉發量表明該博文獲得的推薦度。因此,博主的感召力以 “關注人氣”的人數來體現,博文熱度則以博文的“閱讀量”、 “收藏量”、 “評論數”以及 “轉發量”來綜合體現。
為充分體現博文的熱度,本文綜合考慮了博主及博文兩類屬性。為消除因發布時間不同而造成博文熱度存在的差異,本文提取博文 “發布時間”作為平衡熱度的因子。博文頁面Xm的熱度計算公式為
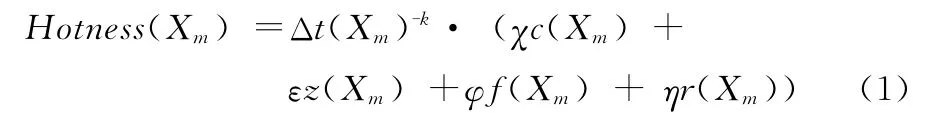
式中:Δt(Xm)——博文Xm發布時間與當前時間之間的時間間隔,k——衰減系數,依據關注人氣a(Xm)取值,k初值為0,a(Xm)每增加5000則k增加0.1[12],c(Xm)為博文Xm的閱讀量,z(Xm)為博文Xm的收藏量,f(Xm)為博文Xm的評論數,r(Xm)為博文Xm的轉載量,m=1,2,…,n,n為博文頁面數,χ、ε、φ和η分別為相關系數,χ調節數量級,ε、φ和η滿足ε+φ+η=1。
1.3 鏈接選擇
已有的基于鏈接分析的熱點發現方法對鏈接未加以選擇,且對所有的鏈接均賦予相同的權重,經多輪迭代后,將會使密集鏈接區域中主題不相關但鏈接數很多的頁面具有過高的權重,即形成了主題漂移現象。為克服此現象,本文通過鏈接清洗來摒棄主題無關的鏈接,且通過博主以及博文的相關屬性來直接評價博文熱度,從而避免了因只依賴鏈接而賦予頁面權重引起的網頁排名不準確的問題。
博文頁面鏈接主要有兩種:一是博文到博主的鏈接,博主每閱讀、評論、收藏一篇博文,均在該頁面形成一條指向該博主的博客鏈接,這種鏈接表達了博主之間的關系;二是博文到博文的鏈接,包括博文的轉發鏈接、相似博文的鏈接以及博主的其它博文鏈接。為了最大限度地減少作弊鏈接對計算頁面熱度的影響,本文方法對相關鏈接進行清洗后,僅抽取轉發鏈接以及相似博文鏈接來進行鏈接分析。這兩種鏈接關系能夠將相似主題聯系起來,經聚類后形成同一話題。
利用已抽取的鏈接關系建立博文的鄰接矩陣E

其中,eij取0或1,eij=1表示頁面i與頁面j 之間有直接鏈接,eij=0表示頁面i與頁面j 之間沒有直接鏈接。
2 運用螢火蟲算法聚類博文
為了獲得權威的博客頁面,要進行相似主題聚類。螢火蟲算法具有自動識別簇、不依賴初始值且不預設聚類中心的特點,優于其它群智能優化算法[12,13]。因此,本文運用螢火蟲算法[14]對博文聚類。
在運用螢火蟲算法對博文進行聚類時,前期適當擴大搜索空間,將能有效地避免陷入局部最優,后期適當縮小搜索空間,將能快速確定最優值。本文利用混沌理論[15]控制搜索范圍的參數α 在既定范圍內獲得較大的隨機性,以使算法的聚類精度達到最優。
螢火蟲算法中的參數與博客話題模型中的參數存在一一映射關系。螢火蟲種群規模n映射博文頁面集規模n,螢火蟲個體m 映射博文頁面Xm,螢火蟲的最大吸引度β0 映射頁面鏈接的權重eij,i,j=1,2,…,n。
螢火蟲的最大熒光亮度I0映射博文頁面Xm的熱度Hotness(Xm)

螢火蟲的相對熒光亮度I 映射個體m 的適應度向量F(Xm)
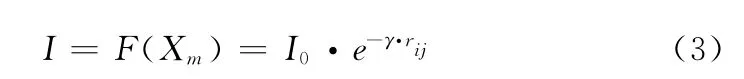
式中:rij——螢火蟲Xi與Xj之間的空間距離,γ——光強吸收系數。為了均衡I0與rij對相對熒光亮度I的調節力度,本文將個體m 的適應度向量F(Xm)的計算公式改進為
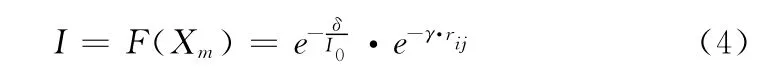
式中:δ——調節系數。
若F(Xi)<F(Xj),則螢火蟲Xi被吸引向螢火蟲Xj移動,其位置更新公式為
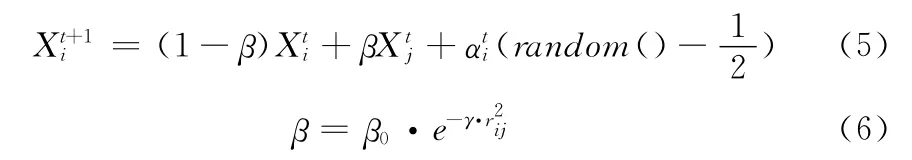
式中:t——種群的代數,其初值為1,Xti、Xtj為螢火蟲個體Xi和Xj所處的空間位置,random()為 [0,1]上服從均勻分布的隨機因子;擾動項為αti(random()-1/2)。
螢火蟲個體m (博文頁面Xm)在第t輪迭代計算更新個體m 的位置 (更新頁面鏈接權值)時,取值范圍為 [0,1]的混沌參數為

式中:Dtm——個體m 在第t 輪迭代時的混沌變量。采用Logistic映射獲得混沌序列[15]
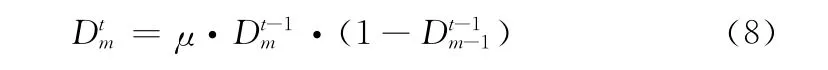
3 博客熱點話題發現算法
3.1 博客熱點話題發現方法
融合運用鏈接分析與螢火蟲算法聚類博文的熱點話題發現方法如圖2所示。具體步驟是:①解析域名,與目標網絡建立TCP連接。②利用URL 模板來匹配獲取的URL地址,若相符,則存入本地文檔,否則丟棄。③根據頁面模板抽取的相關屬性值計算博文熱度值,利用抽取的相關鏈接形成鄰接矩陣。運用螢火蟲算法對博文進行聚類后,提取各個話題簇的權威頁面形成熱點,然后將博文標題按照博文熱度值排序,形成熱點的話題熱度排行。
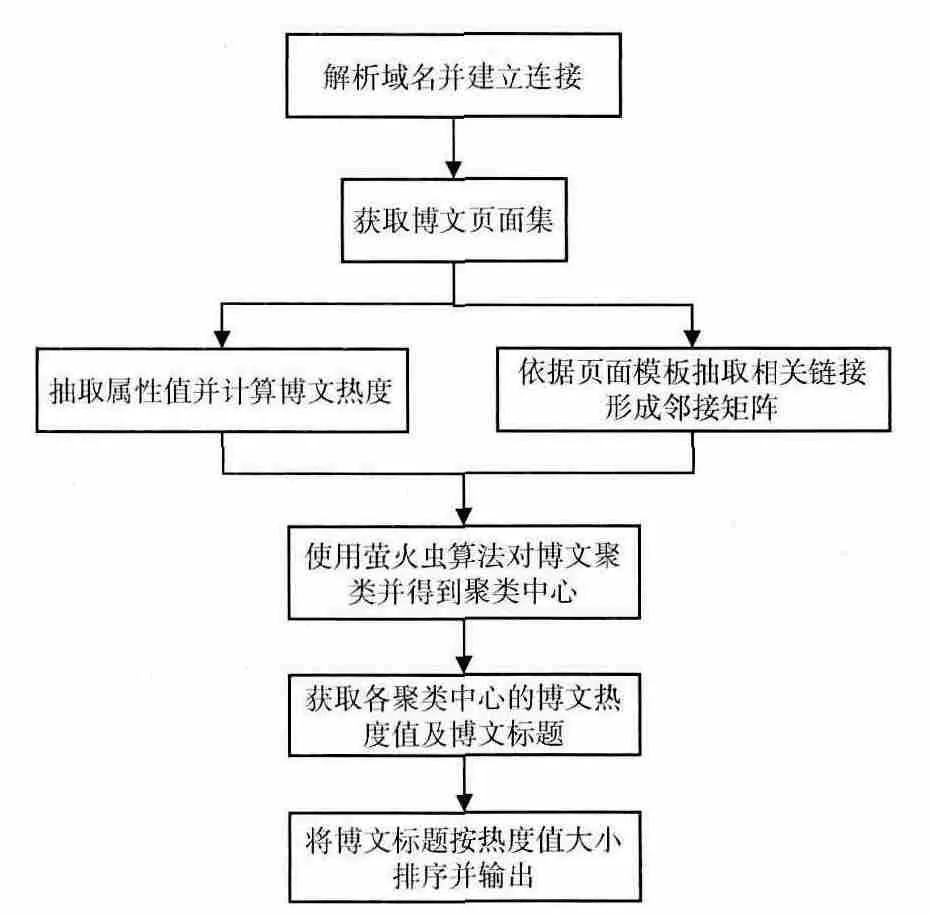
圖2 融合運用鏈接分析與螢火蟲算法聚類博文的熱點話題發現方法
3.2 算法描述
本文將博文頁面映射成螢火蟲個體,將尋找簇結構(相似博文聚成的話題)即聚類過程映射成螢火蟲個體間的相互吸引和位置移動過程,并利用歸一化開銷控制螢火蟲種群的迭代輪數。獲得簇結構后,選取各簇亮度最大的螢火蟲 (權威頁面)作為聚類中心,螢火蟲個體代表的博文頁面即為博客熱點話題。融合運用鏈接分析和螢火蟲算法聚類博文的熱點話題發現算法 (簡記為Blog-IPO 算法)描述如下:
算法1:Blog-IPO 算法
輸入:博文頁面集
輸出:熱點排行
Begin
(1)對參數χ、ε、φ、η、γ、β0、α、δ、μ初始化;
(2)抽取博文頁面Xm的相關屬性,按式 (1)計算博文Xm的熱度Hotness(Xm),m=1,2,…,n;
(3)抽取Xm的轉發鏈接及相似博文鏈接;
(4)形成鄰接矩陣E;
(5)t=1;
(6)for i=1to ndo
(7)for j=1to ndo
1)若eij=1則按式 (4)計算螢火蟲個體Xi、Xj的適應度向量F(Xi)、F(Xj);
2)若F(Xi)<F(Xj)則按式 (5)更新Xi的Xt+1i;
3)按式 (7)和式 (8)計算αt+1i;
(8)按后述的式 (11)計算歸一化開銷 (CDet)Norm,將第t輪迭代計算所得的歸一化開銷 (記為)與第(t-1)輪迭代計算所得的歸一化開銷進行比較,若<則令t=t+1,轉歩驟 (6),否則轉歩驟 (9);
(9)依據Xt+1i形成聚類中心Xcenter,center=1,2,…,h,h為聚類中心數目;
(10)將Xcenter的標題按照Hotness(Xcenter)從大到小排序;
(11)輸出熱點話題排行Topic1,Topic2,…,Topich;
End
Blog-IPO算法利用復雜網絡的簇結構高度主題相關的特性建立博客話題模型,同時運用博文以及博主的相關屬性來衡量頁面權重,并提取博文的發布時間作為平衡熱度的因子以消除因發布時間不同造成的熱度差異,選取與博文內容相同或相關的鏈接形成鄰接矩陣,并運用螢火蟲算法對博文進行聚類形成聚類中心 (熱點話題),克服了基于鏈接分析的輿情發現方法存在的主題漂移現象,并消除了作弊鏈接對頁面排名的影響,提高了熱點話題發現的準確度。
4 實 驗
4.1 數據集
實驗數據來源于新浪博客,利用開源工具HTML Parser解析目標博客網站的頁面,然后利用模板匹配抽取相關信息。新浪博客抽取信息及屬性見表1。
4.2 實驗環境
本文的實驗硬件環境為主頻2.90GHz、4GB 內存、500G 硬盤的Intel奔騰雙核G2020 計算機,操作系統為Windows XP,編程開發工具為VC++6.0。
4.3 實驗參數
本文實驗采用的參數χ=0.001、δ=0.1、ε=0.3、φ=0.2、η=0.5由文獻 [16]獲得,μ=4由文獻 [15]獲得,控制聚類效果的參數α、γ由實驗獲得。文獻 [17]的研究表明當α∈ [0,1]、γ∈ [0,10]時算法性能較好,本文令α以間隔0.1、γ以間隔1的幅度變化構造55 對組合參數,用歸一化開銷作為聚類質量的評測標準對本文數據集進行測試。實驗結果表明當α=0.2、γ=1時,歸一化開銷達到最低,即聚類質量最佳。

表1 抽取的信息及屬性
4.4 實驗結果
對博客而言,博文能夠越多地被聚類到正確的話題簇中,并且能夠識別出越多的話題,則說明該熱點話題發現方法的性能越好。因此,本文從聚類博文精度以及發現話題的個數兩個方面進行實驗測試,并與文獻 [9]的方法(記為HITS-PageRank)對比結果。
4.4.1 博文聚類精度對比
實驗抽取新浪博客專題模塊中如下10個專題作為測試數據:韓國歲月號沉船事件、蘭州自來水苯含量超標、文章出軌、中國大媽盧浮宮跳廣場舞、內地小孩在港隨地小便、房價下調、中紀委嚴懲貪污腐敗、黑龍江火車脫軌案、城管被打、馬來西亞人質。
依據TDT 評測標準,采用漏檢率Pmiss、錯檢率Pfault以及歸一化開銷 (CDet)Norm來評價網絡輿情熱點發現方法的博文聚類精度

其中:Cmiss是Pmiss的代價常量,Cfault是Pfault的代價常量,Ptarget表示一個文本屬于某個話題的先驗概率,Ptarget=1-Ptarget。根據TDT 評測標準,通常取Cmiss=1、Cfault=0.1和Ptarget=0.02。
Blog-IPO 方法與HITS-PageRank方法對不同專題的漏檢率、錯檢率結果如圖3、圖4所示。
由圖3、圖4可以看出,對于各個話題專題,Blog-IPO方法的漏檢率均低于HITS-PageRank方法,Blog-IPO 方法的漏檢率比 HITS-PageRank 方法的漏檢率平均降低24.53%。這是因為本文提出的Blog-IPO 方法使用的鏈接均是話題的有效鏈接,大大提高了話題中相似博文的聚合力,聚類后的話題相關博文數量增多,從而降低了漏檢率。除了Blog-IPO 方法對專題1 與專題4 的錯檢率略高于HITS-PageRank方法的錯檢率以外,Blog-IPO 方法對其余專題的錯檢率均明顯低于HITS-PageRank 方法的錯檢率。這是因為Blog-IPO 方法對頁面權重評判以及鏈接清洗,避免了話題漂移現象,有效地提高了話題聚類的準確率,從而使得Blog-IPO 方法整體上降低了錯檢率。
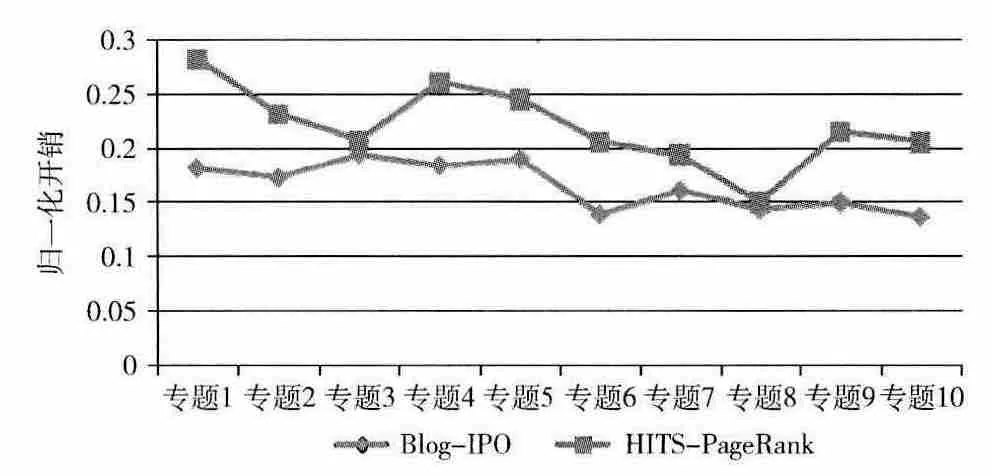
圖3 Blog-IPO 方法和HITS-PageRank方法對不同話題專題的漏檢率
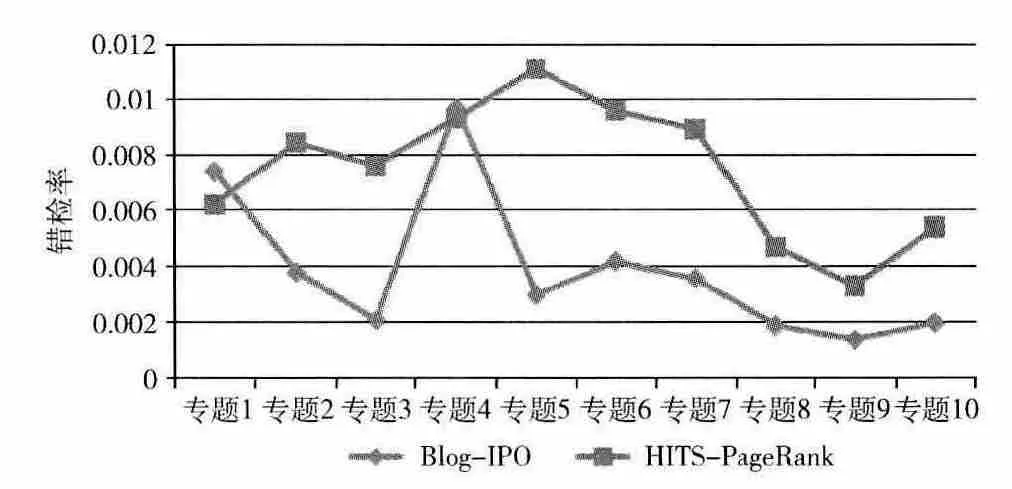
圖4 Blog-IPO 方法和HITS-PageRank方法對不同話題專題的錯檢率
Blog-IPO 方法與HITS-PageRank方法對不同話題專題的歸一化開銷如圖5所示。
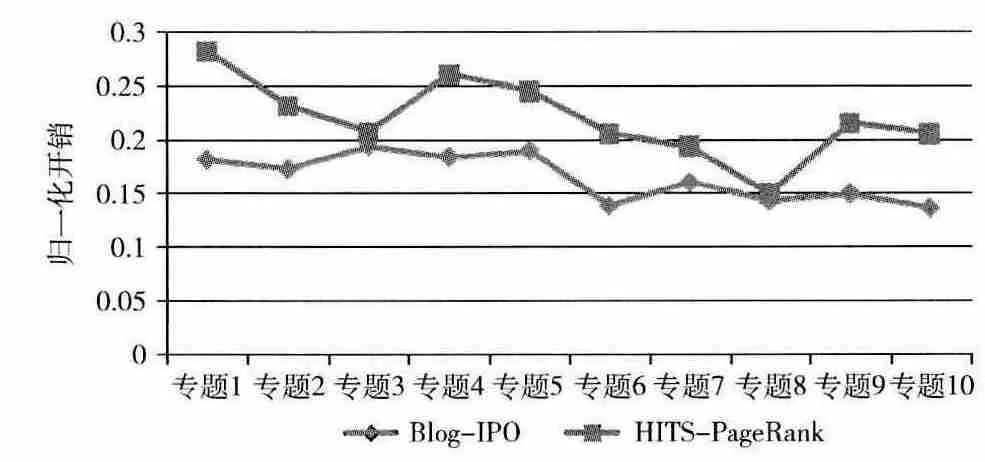
圖5 Blog-IPO 方法和HITS-PageRank方法對不同話題專題的歸一化開銷
圖5的結果表明,對于不同話題專題的歸一化開銷,Blog-IPO方法均低于HITS-PageRank方法,平均降低了27.81%。這是因為相較于錯檢率,漏檢率在歸一化開銷中占據的比重較大,而本文的Blog-IPO 方法的漏檢率明顯低于HITS-PageRank方法的漏檢率。
綜合以上實驗結果分析可知,本文給出的融合運用鏈接分析和螢火蟲算法聚類博文的熱點話題發現方法能夠有效地挖掘出精度更高的博客熱點話題。
4.4.2 熱點話題挖掘結果
實驗抽取了從2014年4月1日8時至4月30日18時新浪博客發表的4236個博文頁面及62341條鏈接作為測試數據。HITS-PageRank方法與Blog-IPO 方法發現的熱點話題結果分別見表2、表3。
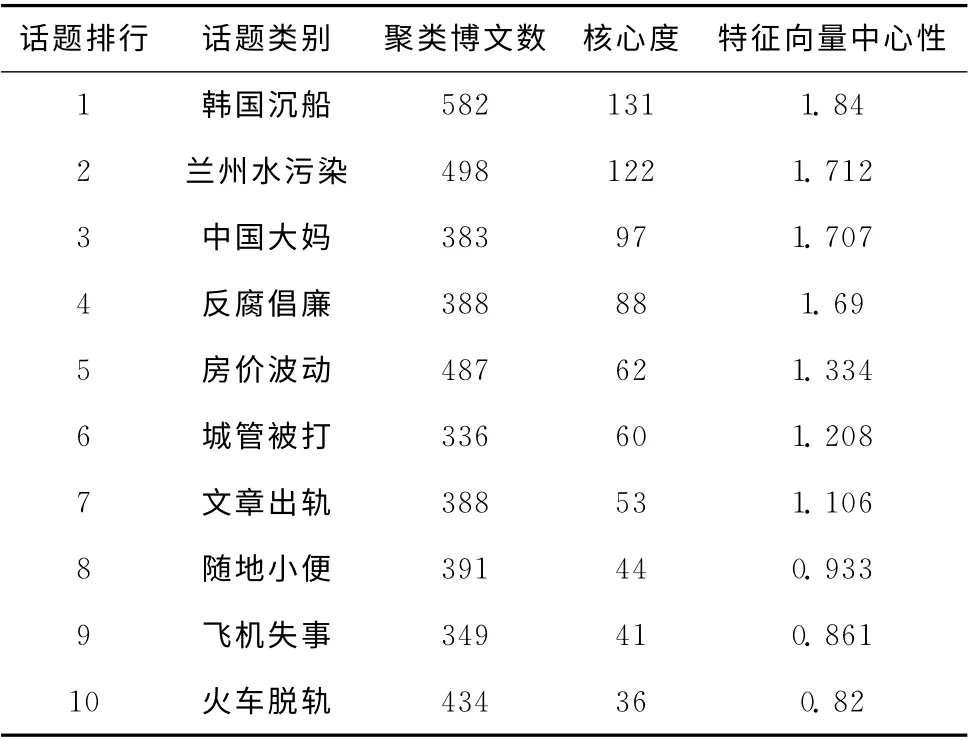
表2 HITS-PageRank方法發現的熱點話題結果
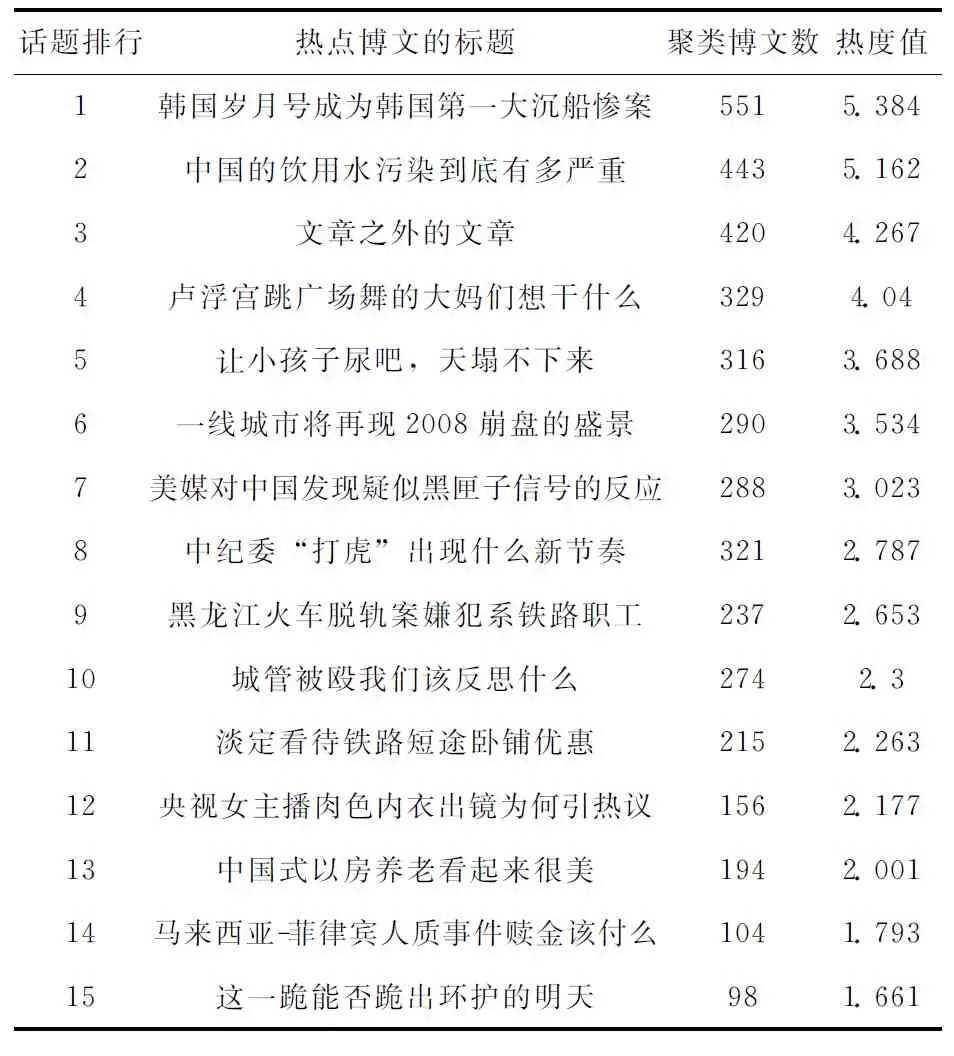
表3 Blog-IPO 方法發現的熱點話題結果
對比表2、表3可知,Blog-IPO方法發現了15個熱點話題,HITS-PageRank方法發現了10個熱點話題,兩種方法發現的話題均為2014年4月的熱點信息,但是Blog-IPO 方法發現的話題數量更多。HITS-PageRank方法發現的話題數量少于本文提出的Blog-IPO 方法發現的話題數量,是因為HITS-PageRank方法存在話題漂移現象,將主題詞相似但實質表述不同事件(例如表3中的以“火車”為關鍵詞的話題9與11、以“住房”為關鍵詞的話題6與13)的博文歸為一類。此外,HITS-PageRank方法受到非相關鏈接的影響,未能識別出相對規模較小的表3中的熱點話題12、14以及15。
5 結束語
本文給出的利用復雜網絡簇結構高度主題相關的特性、基于三層博客話題模型、融合運用鏈接分析和螢火蟲算法聚類博文的熱點話題發現方法,克服已有的基于鏈接分析的輿情熱點發現方法抵抗作弊鏈接能力較弱、存在主題漂移現象的問題,能夠發現精度更高、數量更多的博客熱點話題。本文的博客熱點話題發現方法依據復雜網絡簇結構進行建模,對于社區結構明顯的論壇熱點話題發現研究有參考價值。為適應大數據時代Web信息挖掘的需求,下一步工作將研究適合大規模博文頁面熱點話題發現的方法。
[1]ZHENG Kui,SHU Xueming,YUAN Hongyong.Hot spot information auto-detection method of network public opinion[J].Computer Engineering,2010,36 (3):4-6 (in Chinese).[鄭魁,疏學明,袁宏永.網絡輿情熱點信息自動發現方法 [J].計算機工程,2010,36 (3):4-6.]
[2]WANG Tietao,WANG Guoying,CHEN Yue,et al.Study of network public opinion situation based on semantic pattern and word sentiment orientation [J].Computer Engineering and Design,2012,33 (1):74-77 (in Chinese). [王鐵套,王國營,陳越,等.基于語義模式與詞匯情感傾向的輿情態勢研究 [J].計算機工程與設計,2012,33 (1):74-77.]
[3]LONG Zhiyi,CHENG Wei.Kind of hot topic detection algorithm based on clustering keywords [J].Computer Engineering and Design,2011,32 (6):2214-2216 (in Chinese).[龍志禕,程葳.基于詞聚類的熱點話題檢測算法 [J].計算機工程與設計,2011,32 (6):2214-2216.]
[4]ZHU Hengmin,SU Xinning,ZHANG Xiangbin.A topic tracking method of Internet public opinion based on link network diagram[J].Journal of the China Society for Scientific and Technical Information,2012,30 (12):1235-1241(in Chinese).[朱恒民,蘇新寧,張相斌.基于鏈接網絡圖的互聯網輿情話題跟蹤方法[J].情報學報,2012,30 (12):1235-1241.]
[5]LI Dongfang,YU Nenghai,YIN Huagang.Mining hot topics on Internet under Web 2.0 [J].Journal of Electronics &Information Technology,2010,32 (5):1141-1145(in Chinese).[李東方,俞能海,尹華罡.一種Web 2.0 環境下互聯網熱點挖掘算法[J].電子與信息學報,2010,32 (5):1141-1145.]
[6]XIE Fenghong,ZHANG Dawei,HUANG Dan,et al.Keywords extraction based on weighted complex network [J].Journal of Systems Science and Mathematical Sciences,2010(11):1592-1596 (in Chinese). [謝鳳宏,張大為,黃丹,等.基于加權復雜網絡的文本關鍵詞提取 [J].系統科學與數學,2010 (11):1592-1596.]
[7]Nonaka H,Kubo D,Kimura T H,et al.Correlation analysis between financial data and patent score based on HITS algorithm [C]//IEEE International Technology Management Conference,2014:1-4.
[8]Ji-Lin Z,Yong-jian R,Wei Z,et al.Webs ranking model based on pagerank algorithm [C]//2nd International Conference on Information Science and Engineering.IEEE,2010:4811-4814.
[9]HUANG Min,HU Xuegang.Internet public opinion hot spot mining base on complex network theory [J].Computer Simulation,2011,28 (9):114-117 (in Chinese). [黃敏,胡學鋼.基于復雜網絡方法的輿情熱點挖掘 [J].計算機仿真,2011,28 (9):114-117.]
[10]YANG Bo,LIU Dayou,LIU J,et al.complex network clustering algorithms [J].Journal of Software,2009,20(1):54-66 (in Chinese).[楊博,劉大有,Liu J,等.復雜網絡聚類方法 [J].軟件學報,2009,20 (1):54-66.]
[11]HE Jianmin,ZHANG Yi.Research on identifying method for the hot topics based on class entropy distance measurement[J].Information Science,2012,30 (8):1147-1150 (in Chinese).[何建民,張義.基于類熵距離測量的熱點話題識別方法研究 [J].情報科學,2012,30 (8):1147-1150.]
[12]Senthilnath J,Omkar S N,Mani V.Clustering using firefly algorithm:performance study [J].Swarm and Evolutionary Computation,2011,1 (3):164-171.
[13]Banati H,Bajaj M.Performance analysis of firefly algorithm for data clustering [J].International Journal of Swarm Intelligence,2013 (1):19-35.
[14]Yang X S.Nature-inspired metaheuristic algorithms [M].Bristal,UK:Luniver Press,2008:83-96.
[15]Amiri B,Hossain L,Crawford J W,et al.Community detection in complex networks:Multi-objective Enhanced Firefly Algorithm[J].Knowledge-Based Systems,2013,46 (1):1-11.
[16]ZHOU Erzhong.Blog hot topic detection and its analysis on public opinion [D].Beijing:Beijing University of Technology,2013 (in Chinese).[周而重.博客輿情熱點發現與分析[D].北京:北京工業大學,2013.]
[17]Yang X S.Multiobjective firefly algorithm for continuous optimization[J].Engineering with Computers,2013,29(2):175-184.
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
