XML文檔的聚類研究尹路修
2015-12-24 01:38:36湖南師范大學數(shù)學與計算機科學學院中國長沙410081
湖南師范大學自然科學學報 2015年5期
(湖南師范大學數(shù)學與計算機科學學院,中國 長沙 410081)
?
XML文檔的聚類研究尹路修
(湖南師范大學數(shù)學與計算機科學學院,中國 長沙410081)
摘要隨著互聯(lián)網的迅速發(fā)展,XML已經成為互聯(lián)網中最常用的數(shù)據交換與存儲語言,如何從大量的XML文檔中提取有價值的信息是目前的研究熱點之一.本文提出了一種基于SET/BAG模型的改進的相似度計算方法.該方法將XML文檔的每個節(jié)點轉換成一個對象(由對象名、父對象、屬性集合以及該對象相對于其父對象的權重組成),能較完整地表達XML文檔的結構信息,并且通過調整重復節(jié)點的權重來降低其在相似度計算中的影響.在真實數(shù)據集與人工數(shù)據集上分別進行實驗,仿真實驗結果表明,本文提出的基于SET/BAG模型下改進的相似度計算方法能得到很好的聚類結果.
關鍵詞XML;文檔聚類;相似度計算
在研究如何從大量的XML文檔中提取有價值的信息時,關于XML文檔的聚類[1]研究顯得非常重要.通過XML文檔的聚類,可以將大量的XML文檔在未知類別的情況下進行分類整理,使用戶可以用更短的時間獲得更為完整和有用的信息.XML文檔聚類研究主要有兩大研究方向.一種是對聚類算法進行改進,使之能更好地結合XML文檔的特點以及更好的聚類結果.目前主要的聚類算法[2-3]有基于劃分的,基于層次的和基于密度的.另一種是對XML文檔的表示模型進行改進,以便得到更有效率的相似度計算方法.目前主要的XML文檔的表示模型[4-7]有3種,分別是SET/BAG模型,向量空間模型和樹模型.本文著重對SET/BAG模型的相似度計算方法進行改進,提出一種基于SET/BAG模型改進的相似度計算方法.
1SET/BAG模型相似度計算
SET/BAG模型[8]是將XML文檔用集合的形式來表示,通過Jaccard相似系數(shù)計算公式得到兩個文檔的相似度.設有2個XML文檔集合,x1,x2,Jaccard相似系數(shù)計算公式:
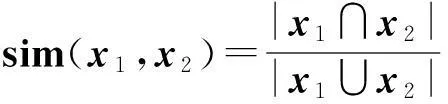
(1)
基于SET/BAG模型的相似系數(shù)計算公式,再結合XML文檔的自身特點,有以下幾種相似度計算方法:
(1)節(jié)點比較法.節(jié)點比較法是將一個XML文檔中的所有節(jié)點組合成一個集合,這個集合代表這個XML文檔.相似度計算是使用Jaccard相似系數(shù)計算公式得到相似度.節(jié)點比較法只是簡單地提取了XML文檔中的節(jié)點,忽略了XML文檔的結構信息,如XML文檔結構中的父子關系,同時嵌套節(jié)點與重復節(jié)點帶來的相似度計算的影響也并未得到解決.并且XML文檔中層級越高的節(jié)點概括的信息量越大,層級越低的節(jié)點概括的信息量越小,但是在節(jié)點比較法中并未得到表現(xiàn).
(2)邊集比較法.邊集比較法與節(jié)點比較法類似,只是集合中的節(jié)點不是XML文檔里的元素,而是用表示父子關系的有向邊.相似度計算方式與節(jié)點比較法一樣,也是計算兩個集合之間的交集除以兩個集合之間的并集.邊集比較法在一定程度上保存了XML文檔中的父子關系,但和節(jié)點比較法一樣也未能解決嵌套元素與重復元素的影響.
2基于SET/BAG模型改進的相似度計算
2.1基于SET/BAG模型改進的相似度計算
2.1.1XML文檔的數(shù)據預處理XML文檔中的一個對象由一個四元組表達,即,O={Name,Parent,AttributeList,Weight},其中Name:該對象的名字,Parent:該對象的父對象,AttrubuteList:該對象的屬性集合,Weight:權重,是該對象相對于其父對象的重要度,如圖1所示.在進行對象集合相似度計算之前,需要遍歷XML文檔中的每個節(jié)點并將其轉換成一個對象.于是,計算兩個XML文檔的相似度時,即對這個XML文檔的對象集合進行比較.


圖1 XML文檔示例Fig.1 XML document sample

名稱父對象屬性權重booknulltitle;publisher;year;author;price1titlebooknull0.2publisherbooknull0.2yearbooknull0.2authorbookfirstname;lastname0.2pricebooknull0.2firstnameauthornull0.5lastnameauthornull0.5
2.1.2節(jié)點對象的相似度計算在將數(shù)據處理成對象集合之后,需要進行對象的相似度計算.對象的相似度取決于對象名和對象的屬性集合.兩個XML文檔的相似度等于兩個XML文檔的頂層對象的相似度.
設有對象P1和P2,P1的屬性集合為{a11,a12,…,a1m},P2的屬性集合為{a21,a22,…,a2n},對象的相似度計算公式:

(2)
基于SET/BAG模型改進的相似度計算算法采用遞歸的方式從頂層對象(樹模型里的根節(jié)點)開始計算,通過動態(tài)規(guī)劃算法的思想,分別求解出兩個頂層對象下屬性集合的相似度,然后將每個屬性與各自對于頂層對象的權重相乘再累加除以2得到兩個頂層對象的相似度,也就是XML文檔的相似度,有兩種情況:
(1)如果對象的屬性集合為空,則比較對象名是否一樣.當屬性名一樣時,判定兩個屬性的語義是否相同,若相同,則similaryValue=1,否則similaryValue=0.
(2)如果對象屬性集合不為空,先比較對象名,如果相同,則比較其屬性集合.先將兩個對象的所有屬性進行兩兩比較,然后分別查找出相似度最大的值作為這兩個屬性的相似度,若沒有匹配上的屬性, similaryValue=0.
基于SET/BAG模型改進的相似度計算算法描述如下:
函數(shù):compareObject
輸入:O1,O2;// 頂層對象O1,頂層對象O2
輸出:similaryValue;//兩個對象集合的相似度值
方法:
(1)比較頂層對象名是否相同,如果相同,則跳入(2);
(2)比較兩個對象的屬性集合,
If(其中一個對象的屬性集合為空,而另一個對象的屬性集合不為空){
similaryValue = 0;
返回 similaryValue;
}else if (兩個對象的屬性集合都為空){
If(o1.name == o2.name){
similaryValue = 1;
}else{
similaryValue = 0;
}
返回similaryValue;
}else{
Repeat
//將兩個對象的屬性集合進行兩兩對比,跳入(1);
//將相似度最大的兩個屬性劃分為一組,得到的相似度結果為這兩個屬性的相似度;
Until
//所有屬性比較完畢
//跳入(3)
}
(3)分別乘以這個屬性在該對象的權重,得到最終帶權重的相似度,代入公式(1)中,得到兩個頂層對象的相似度.
基于SET/BAG模型改進后的相似度計算方法結合了語義相似度的比較,并未通過語義詞典來得到兩個屬性的語義相似度.由于目前的語義詞典如WordNet存在一些不足的地方如合并詞匯與縮寫詞匯不能計算相似度,例如圖3.1中firstname是由first和name合并的,但是在語義詞典里面不能被識別.還有語義詞典中的詞匯不完善,簡寫詞匯和專業(yè)術語的單詞如VSM是Vector Space Model的簡寫,但是在語義詞典中也不能被識別.因此,改進后的相似度計算方法并未采用語義詞典進行相似度的計算.
在嵌套節(jié)點與重復節(jié)點的處理方面,由于基于SET/BAG模型改進后的相似度計算方法將節(jié)點轉換成對象處理,而對象包含了名稱與屬性,所以對于嵌套節(jié)點不會影響相似度的計算.而在重復節(jié)點的處理上,通過在XML文檔的預處理中,降低重復節(jié)點的權重,減少重復節(jié)點在相似度計算中的影響.
2.2實驗結果
為了驗證基于SET/BAG模型改進的相似度計算方法的有效性,使用NIGARA數(shù)據集(actor, movies, department, club, bib),分別從actor類中抽取117個文檔,moives類中抽取282個文檔,department類中抽取19個XML文檔,club類中抽取12個文檔,bib類中抽取16個文檔,總計446個文檔進行混合.分別使用SET/BAG模型下的節(jié)點比較法、樹模型下的樹編輯距離和基于SET/BAG模型下改進的相似度計算方法與DBSCAN聚類算法結合對XML文檔進行聚類.節(jié)點比較法與樹編輯距離法是XML文檔相似度計算中有代表性的計算方法.并且通過與節(jié)點比較法和樹編輯距離法進行對比,能很好地表現(xiàn)出基于SET/BAG模型改進的相似度計算方法在XML文檔結構特征的存儲與對重復節(jié)點和嵌套節(jié)點的處理上有很大的提升.實驗結果如表2所示.

表2 NIGARA數(shù)據集的聚類結果
由于NIGARA數(shù)據集中的部分類別重復節(jié)點較多,對樹編輯距離的影響較為嚴重,節(jié)點比較法其次.并且因為club,department和bib類別的XML文檔較少而重復節(jié)點在這些類別中有些文檔出現(xiàn)次數(shù)較多,有些文檔次數(shù)較少,導致基于樹編輯距離的DBSCAN算法將這些類別中的XML文檔計算成孤立點并排除在外,所以樹編輯距離的聚類結果不理想.而改進后的SET/BAG模型相似度計算方法由于將重復節(jié)點的權重進行調整,能很好地消除重復節(jié)點的影響.
為了防止單一數(shù)據集帶來的偶然性,本文使用XML Generator人工生成XML文檔數(shù)據集,此人工數(shù)據集分為3類,分別通過play.dtd,dblp.dtd和SigmodRecord.dtd生成150個XML文檔,其中play.dtd有45個文檔, dblp.dtd有65個文檔, SigmodRecord.dtd有40個文檔.實驗結果如表3所示.

表3 人工數(shù)據集的聚類結果
人工生成的數(shù)據集由于重復節(jié)點較少,因此,節(jié)點比較法和樹編輯距離的表現(xiàn)比在NIGARA數(shù)據集要好,但是仍然不能將所有數(shù)據集放入正確的簇集中.而基于SET/BAG改進的相似度計算方法始終能夠得到很好的聚類結果.
參考文獻:
[1]ALSAYED A, MARCO M, RICHI N,etal. XML data clustering:an overview[J]. ACM Comput Surv, 2011,43(4):25.
[2]ANAND R, JEFFREY D U. Mining of Massive Datasets[M].Cambridge: Cambridge University Press, 2011.
[3]周水庚,周傲英.一種基于密度的快速聚類算法[J].計算機研究與發(fā)展, 2000,37(11):1287-1292.
[4]BERTINO E, GUERRINI G, MESITI M. Measuring the structural similarity among XML documents and DTDS[EB/CD].Technical Report DISI-TR-02-02,Department of Computer Science, University of Genova, 2002.
[5]FLESCA S, MANEO G, MASCIARI E,etal. Detecting structural similarities between XML documents[C]// Proceedings of the 5th International Workshop on the Web and Databases, Madison, Wisconsin, 2002:55-60.
[6]SALTON G, WONG A, YANG C S. A vector space model for automatic indexing[J]. Comm ACM, 1975,18(11):613-620.
[7]LEE J W, LEE K, KIM W. Preparations for semantics-based XML mining[C]//Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, 2001:345-352.
[8]ANDREA T, SERGIO G. Semantic clustering of XML documents[J]. ACM Trans Inform Syst, 2010,28(1):1-56.
(編輯胡文杰)
Clustering Research on XML Document
YINLu-xiu*
(College of Mathematics and Computer Science, Hunan Normal University, Changsha 410081, China)
AbstractWith the rapid development of Internet, XML has become the most commonly used language for the Internet data exchange and storage. How to extract valuable information from a large number of XML document is one of the hottest research topics currently. This paper proposes a model based on the SET/BAG improved similarity calculation method, which converts each node of the XML document to an object (the object name, object, attribute set, and the weight of the object relative to the parent object) and can fully express the structure of an XML document information, by adjusting the repeated node weights to reduce its influence in similarity calculation. Based on real data sets and artificial datasets experiments respectively, the simulation experimental results show that the proposed method in this paper based on the SET/BAG model improved similarity calculation can get good clustering results.
Key wordsXML; document clustering; similarity computation
中圖分類號TP391.1
文獻標識碼A
文章編號1000-2537(2015)05-0091-04
通訊作者*,E-mail:55749691@qq.com
收稿日期:2015-02-17
DOI:10.7612/j.issn.1000-2537.2015.05.015

- 湖南師范大學自然科學學報的其它文章
- Weighted Pseudo Almost Automorphic Mild Solutions to Abstract Functional Differential Equations
- Boundedness of Vector-Valued Multilinear Singular Integral Operators on Generalized Morrey Spaces
- 基于城市流視角的泛珠江三角洲經濟圈空間聯(lián)系分析
- Synthesis, Characterization and Thermal Decomposition of Co(Ⅱ) Complexes Based on Biuret Ligand
- 三種鯻科魚類同工酶組織特異性及群體遺傳結構分析
- 翹嘴鱖miR-146a在胚胎發(fā)育過程中的表達及溫度對其表達的影響