應對告警風暴告警的系統優化策略
2015-12-31 12:51:08宮大鵬黃甫光
電信科學 2015年5期
甘 雯 ,文 鋒 ,宮大鵬 ,徐 鉭 ,黃甫光 ,張 健 ,蘇 雷
(1.中國移動通信集團廣西有限公司 南寧 530022;2.億陽信通股份有限公司 南寧 530022)
1 引言
綜合告警系統是CMOSS2.0規劃的綜合網管系統,系統主要從OMC(operation and maintenance center,操作維護中心)等廠商網管系統獲取資源、告警、性能數據,包括從資源管理系統獲取資源數據、從各專業網管獲取告警和性能數據、從電子運維系統獲取工單數據等,然后通過列表、圖表、拓撲、GIS(geographic information system)等方式進行數據的匯總呈現,幫助監控人員了解全網的運行狀態。
在通信網絡運行過程中,告警是網絡管理員最為關注的。當系統出現影響正常業務的故障時,這些重要的故障信息會以告警的方式在第一時間通知管理人員并應該立即得到解決,否則,可能會導致提供服務失敗。為了方便運維人員處理告警和迅速定位告警源,綜合告警系統采取了各種方式處理這些告警信息,比如告警展現、長時間未處理的告警提示、告警轉發、告警過濾、告警相關性分析等。
在一種極端的情況下,眾多網元(BTS(base transceiver station,基站收發信臺)、RNC(radio network controller,無線網絡控制器)、Node B等)由于不特定原因,同時并且長時間地向網管系統上報大量的告警,導致告警風暴的發生。如果告警系統沒有及時處理,容易造成海量告警的堆積,導致網管系統癱瘓,失去管理和監控網絡的能力,更不能有效遏制網絡故障的進一步擴大。所以告警風暴的危害是巨大的,一方面應該盡量避免告警風暴的產生;另一方面,當告警風暴到來時,系統應有能力及時應對,將告警風暴的危害降到最低。
國外的研發機構一般通過研究告警關聯性和告警挖掘技術解決此項難題,例如,惠普公司的Event Correlation Services,是基于規則的方法研究出的告警相關性分析系統;IBM采用基于事例的告警相關性分析方法,研制了NetFACT系統,利用告警相關性的研究對告警發生進行業務關聯,達到突出主用告警、抑制無用告警的目的,從而大大減少告警量。
近年來,國內進行應對告警風暴研究的主要以設備廠商為主,例如中興通訊、華為技術、大唐電信等,都開始著力研制開發智能高效的移動通信網絡管理系統,包括告警相關性分析系統等。通過將一些研究成果融合到OMC、傳輸EMS(element management system,網元管理系統)等網管系統中,實現部分告警風暴抑制。
本文旨在探討對于架構在設備廠商網管之上的綜合網管系統,如何通過升級現有架構來應對告警風暴的發生,尋找合理的抑制告警風暴手段。
2 業務的高速發展和告警風暴的產生
所謂告警風暴往往被定義為在短時間內,產生了大量的告警事件,在這些事件中,有的互相存在一定關聯,是由于某種共用因素導致的。這樣大量的告警在短時間內擠壓告警上報通道,導致通道的堵塞甚至上層監控業務的崩潰。近年來由于告警風暴導致的數據庫鎖死、隊列溢出、告警監控服務掛死等現象時有發生,嚴重影響了運營商運維管理人員的日常監控作業。
隨著網絡規模的不斷擴大、新類型網元接入以及跨專業監控管理的現實需求,網管系統的數據接入量在不斷增加,但任何一個系統的運行均有其極限值,當數據處理效率不能滿足系統正常運行要求時,系統的可用性就會隨之下降,對于告警監控這類實時消息系統表現得就更為明顯。當在一段時間內的數據突增,超出系統處理能力時,會導致數據處理延時或者數據丟失,從而引發監控系統的不可用。
如圖1所示,在具體的生產實踐中,工程割接、自然災害、OMC重啟、傳輸鏈路異常中斷等引起的告警風暴是數據風暴的典型場景。通常反應為:在超出現有告警監控系統數據處理能力的情況下,監控系統無法及時準確地將某個網元或者相關網元的告警解析呈現,從而無法起到監控作用。
為了適應網絡規模和業務持續高速增長給網絡運維工作帶來的巨大壓力和挑戰,有力支撐公司未來發展,中國移動通信集團公司于2013年率先提出了“集中化”的網絡運維體制改革思路,經過不斷建設和深化,已經形成了全網跨專業的“集中監控、集中維護、集中管理”格局。集中監控的工作內容之一是告警的集中監控。隨著集中監控規模的不斷發展,告警監控工作面臨著前所未有的挑戰:由于集中化監控的設備數量逐年快速增長,集中監控對故障的處理質量提出了更高的要求,特別是當告警風暴發生時,系統崩潰導致值班人員無法正常開展監控工作,進而影響通信保障搶修。為此,迫切需要提高告警的準確性、有效性,并通過升級基礎架構提高告警處理的效率,應對極端情況下的告警風暴發生。
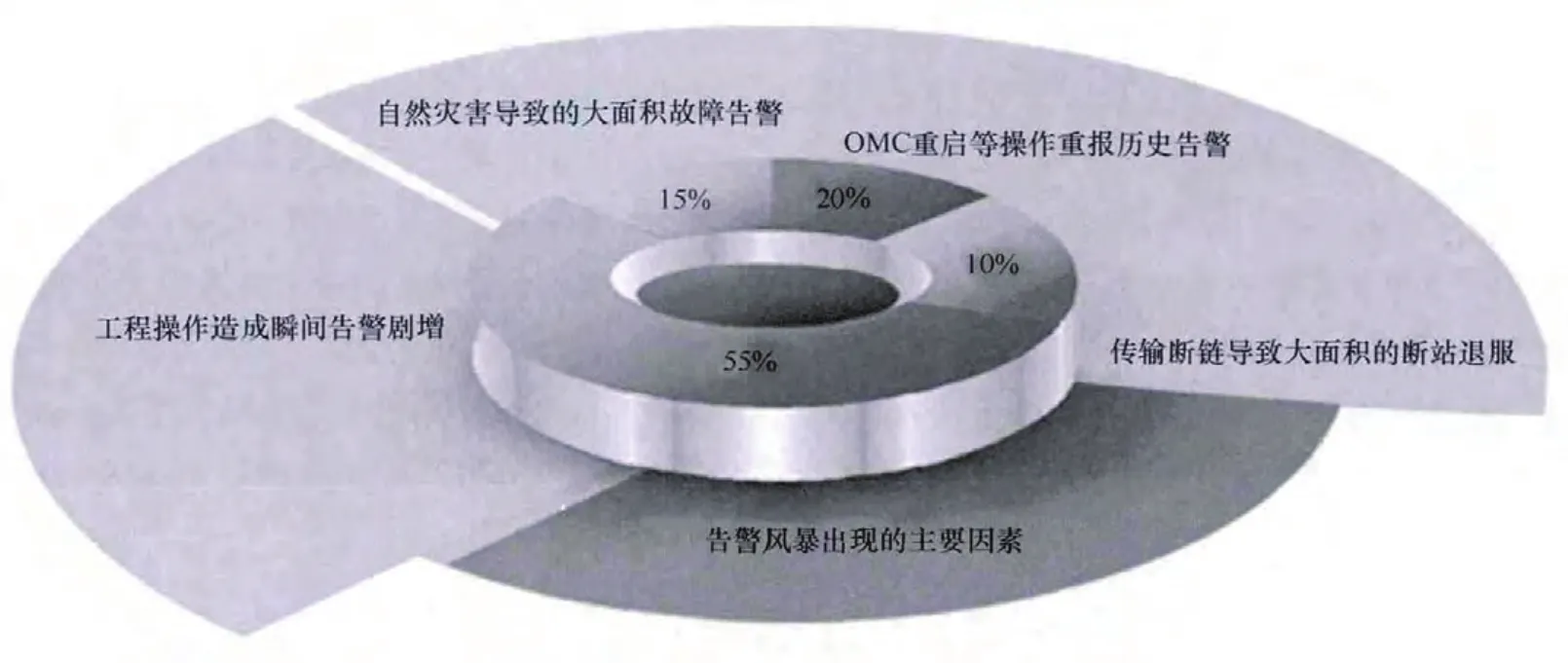
圖1 告警數據風暴出現的主要場景分析
3 綜合告警的網管技術架構升級
3.1 應對告警風暴的性能提升思路
在實際優化過程中,影響系統運行效率的原因是多方面的。網絡傳輸效率、硬件性能、MQ配置、應用軟件部署方式、采集軟件配置、數據庫效率、產品設計都會對系統性能造成影響。
河南省戰略性新興產業專利特別是發明專利的數量與質量,體現了河南省自主科技創新實力的強弱。通過對河南省戰略性新興產業專利競爭情報、專利數量、專利被引次數、專利成長率、專利實施率、產業標準化等指標經濟與技術方面的統計與分析,可以為河南省戰略性新興產業自主創新能力的提升提供決策參考。河南省戰略性新興產業專利能力的提升與競爭優勢的培育,需要政府與相關企業正確制定專利戰略,對專利進行前瞻性布局,提升核心專利技術的自主化水平,實施專利運營能力提升工程,以及構建知識產權驅動型的創新發展人才體系等,以推動河南省戰略性新興產業的高質量發展。
如圖2所示,告警風暴主要通過OMC產生,一旦產生,需要監控人員引起重視。告警風暴處理包含風暴抑制和風暴后處理兩部分內容:風暴抑制是系統判斷告警風暴產生后,將告警經過特殊通道直接傳遞到消息平臺,并將風暴告警保存到文件中,或者停止對某個網元某個告警標題的采集;風暴后處理是將風暴期間的告警入庫,以便于統計分析,并且將風暴期間漏掉的告警通過正常流程發送上去。告警風暴產生或已經停止時,系統產生預警消息,包括活動告警、清除告警。
從告警來源和架構上分析,為有效應對告警風暴,考慮從硬件、軟件、中間件等方面入手進行針對性的調整。同時通過配置合理的日常維護管理制度,可大大減少告警風暴導致的業務中斷情況發生的幾率。
3.2 網絡及系統硬件調整手段
2014年以前,中國移動綜合告警系統主要實現了全專業告警接入、告警標準化、告警關聯、集客業務監控、性能場景監控等功能模塊。以廣西移動綜合告警項目為例,在優化前,網管硬件平臺的網絡拓撲如圖3所示,系統部署在網管硬件平臺的2臺M9000服務器上,存儲使用網管硬件平臺的DX8700磁盤陣列。
隨著集中故障管理業務上線,經過對告警業務的處理量、并發事務數、峰值進行測算,得到硬件TPC-C吞吐率(TPC-C使用3種性能和價格度量,其中性能由TPC-C吞吐率衡量,單位是tpmC,其含義為每分鐘內系統處理的新訂單個數)的需求,進而推算出擴容方案,具體如下。
·系統數據庫服務器需要約149萬tpmC處理能力,當數據庫與MQ服務器同時部署在一臺服務器的時候,建議把綜合告警數據庫單獨拆分出來,利用已有M9000-2分區的計算能力,擴容4顆4核CPU,以滿足需求。
·采集服務器需要約127萬tpmC處理能力,將應用服務器的M9000分區的計算能力由6顆4核CPU內存擴容至8顆4核CPU,擴容后可滿足需求。
·消息服務器需要約128萬tpmC處理能力。將目前應用服務器的M9000分區由6顆4核CPU擴容至8顆4核CPU,擴容后分區能滿足需求。
·拓撲服務器的能力需求為34.86萬tpmC,從其他機房的x86資源池劃分1臺總能力大于35萬tpmC的虛擬機以滿足需求。另外,為了保證必要的數據緩存機制,還增加了2 TB的存儲空間。
最終調整結束后,硬件網絡拓撲如圖4所示。
此外,對于上層應用服務器也需要做負載均衡。根據廣西14個地市的網絡及業務規模,將其分成大、中、小3類地市,制定了動態分配應用服務器的負載均衡策略。例如,當沿海城市發生臺風等自然災害,告警突增時,策略器就會自動分配登錄服務在當前空閑的機器上,保證性能使用的最大化。
通過硬件調整,可處理200萬條/天的告警并發負載量,參照歷史最嚴重的告警風暴發生,評估得出該硬件架構能力可并發處理90%的告警。

圖2 告警風暴實例

圖3 綜合告警系統部署調整前拓撲
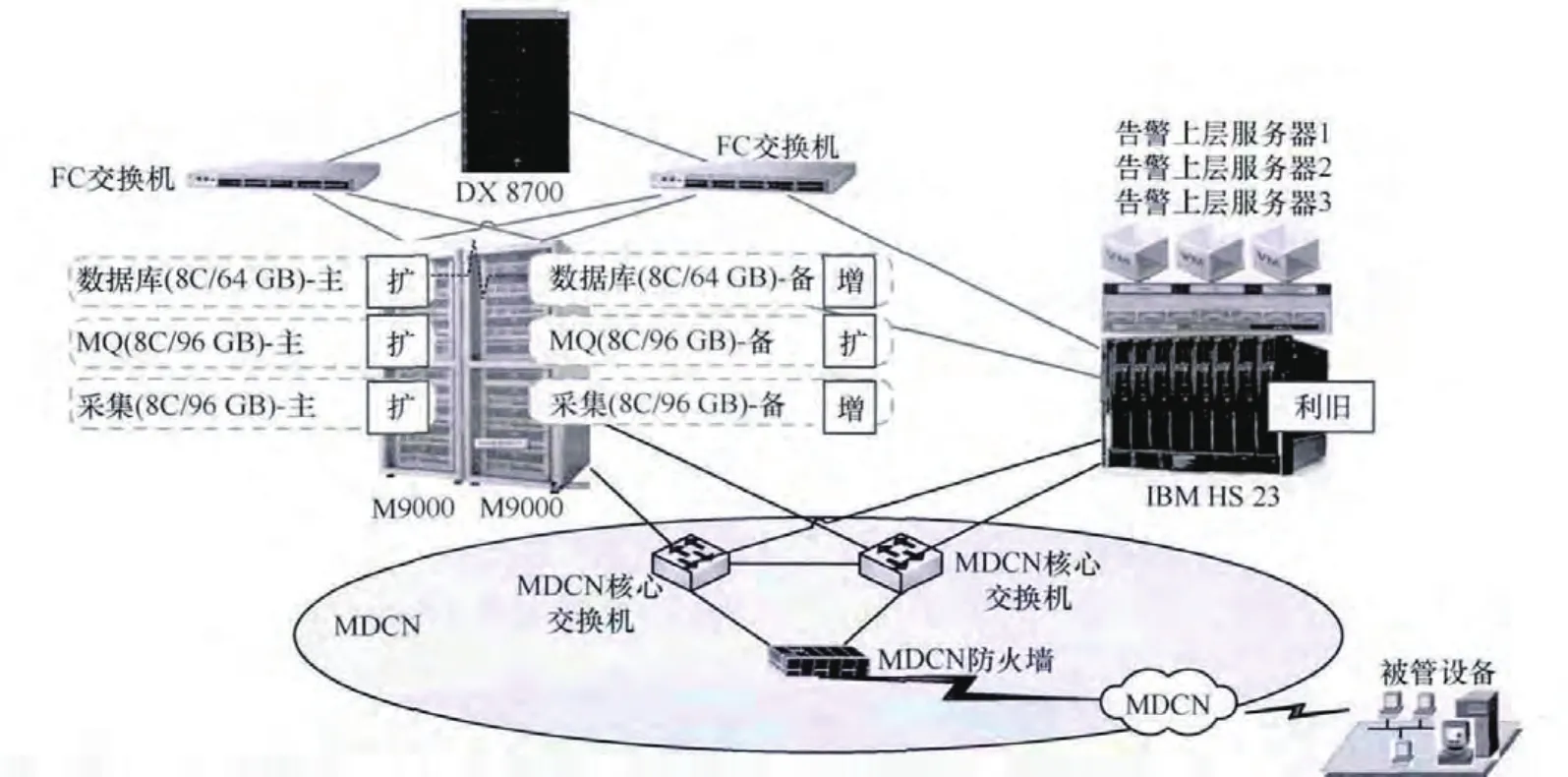
圖4 綜合告警系統部署調整后拓撲
3.3 軟件結構升級手段
除了對硬件進行改造外,還通過對現有告警消息處理機制進行優化來應對告警風暴。如圖5所示,告警在設備北向采集后會經過清洗階段、標準化階段、分發入庫階段和上層展現階段,每個階段都可能會成為告警上報的性能瓶頸。特別是在大量告警隊列堆積時,有針對性地調整腳本的處理效率,可大大提升告警處理效率。
優化手段可以從以下幾個方面考慮。
(1)智能并發告警采集
針對采集通道進行并行處理,設計軟負載均衡隊列管理語法,根據告警流量智能控制并行處理單元數,假設當A通道告警是B通道的兩倍時,會在給A通道多分配50%的處理進程,按照該算法,通過調整可提升單通道采集能力達到60條/s。
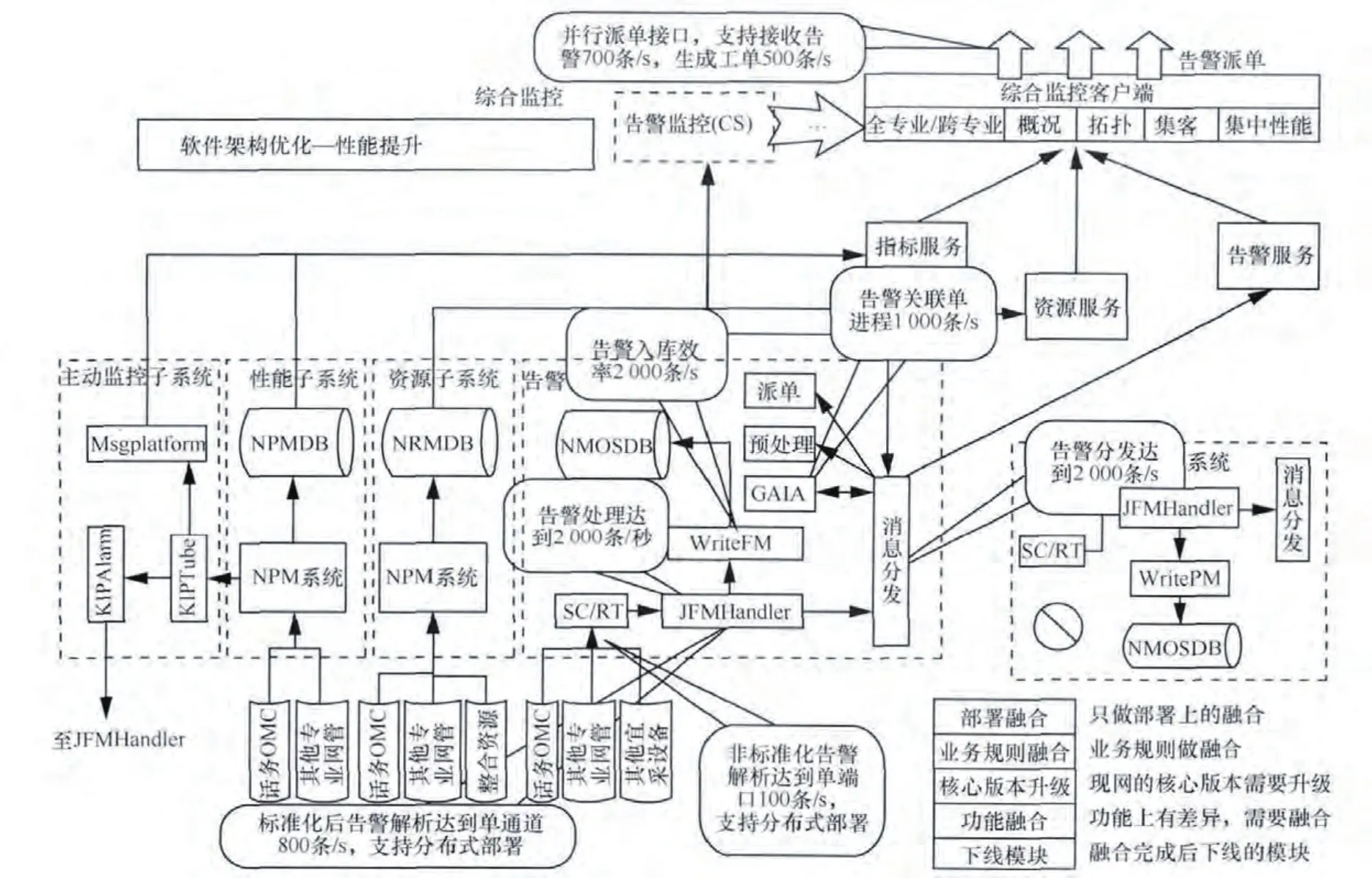
圖5 采集解析模塊優化架構
(2)基于高速緩存的告警處理系統
由于一般在告警標準化過程中,需要反復讀取告警進行標準化字段的翻譯。針對這種特點,可以利用高速緩存技術,如圖6所示,將待處理告警所需要的信息存儲在內存中,加快了CPU的處理效率,迅速提升告警標準化、工程預約等標準化處理能力,提升整體處理能力達到 400條/s。
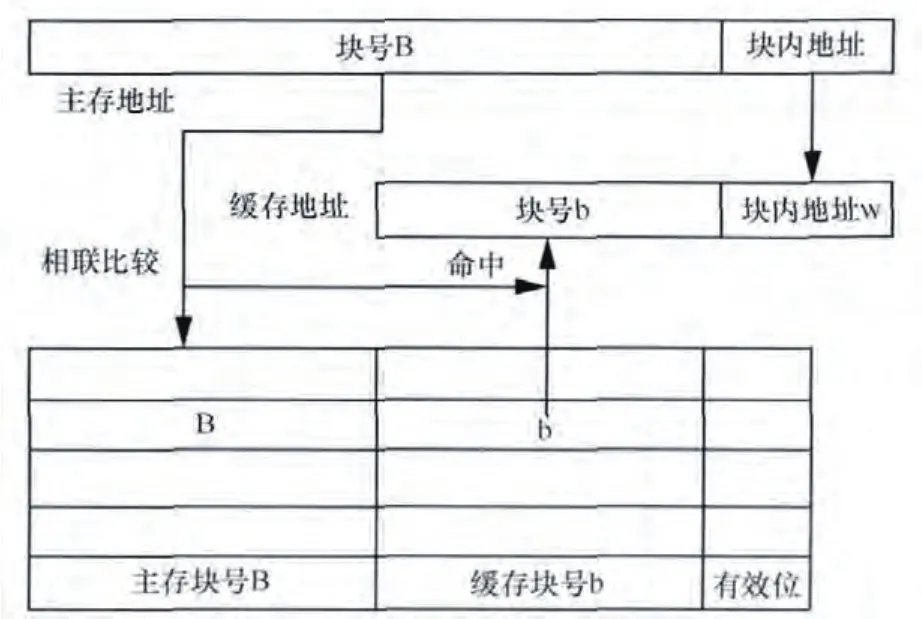
圖6 告警緩存建立示意
(3)基于高效規則處理和并發的告警訂閱分發系統
通過建立高效規則處理實現告警過濾器能力,識別多種閃現告警和關聯告警并予以合并或拋棄,并結合多并發分發處理,在并發多個過濾器(50個)情況下,提升分發效率,可以實現400條/s的處理速度。
基于流計算的告警關聯系統摒棄使用數據庫計算的方式,改為在接收告警流數據時就開始對其進行分析,通過實時的對象流計算,可快速處理告警之間的關聯關系,提升單規則處理能力,實驗表明可提升到200條/s。
(4)基于智能調度的告警派單處理能力提升
針對上層應用,告警的落地除了展現,更重要的是派單,提升EOMS派單系統自身處理效率可在業務上解決告警風暴的問題。針對EOMS單通道處理能力不夠的情況,通過建立智能的調度機制,動態并發調用,大幅提升派單能力,派單系統自身處理能力達到150條/s。
(5)數據庫調優
通過對數據庫Oracle/Informix進行分片機制、增加索引,并對大量歷史數據進行拆分,也可以使得告警實時查詢速率提升。廣西移動采集模塊優化測試結果見表1,以廣西移動實際項目測試結果為例,經過優化,可獲得顯著的提升效果。
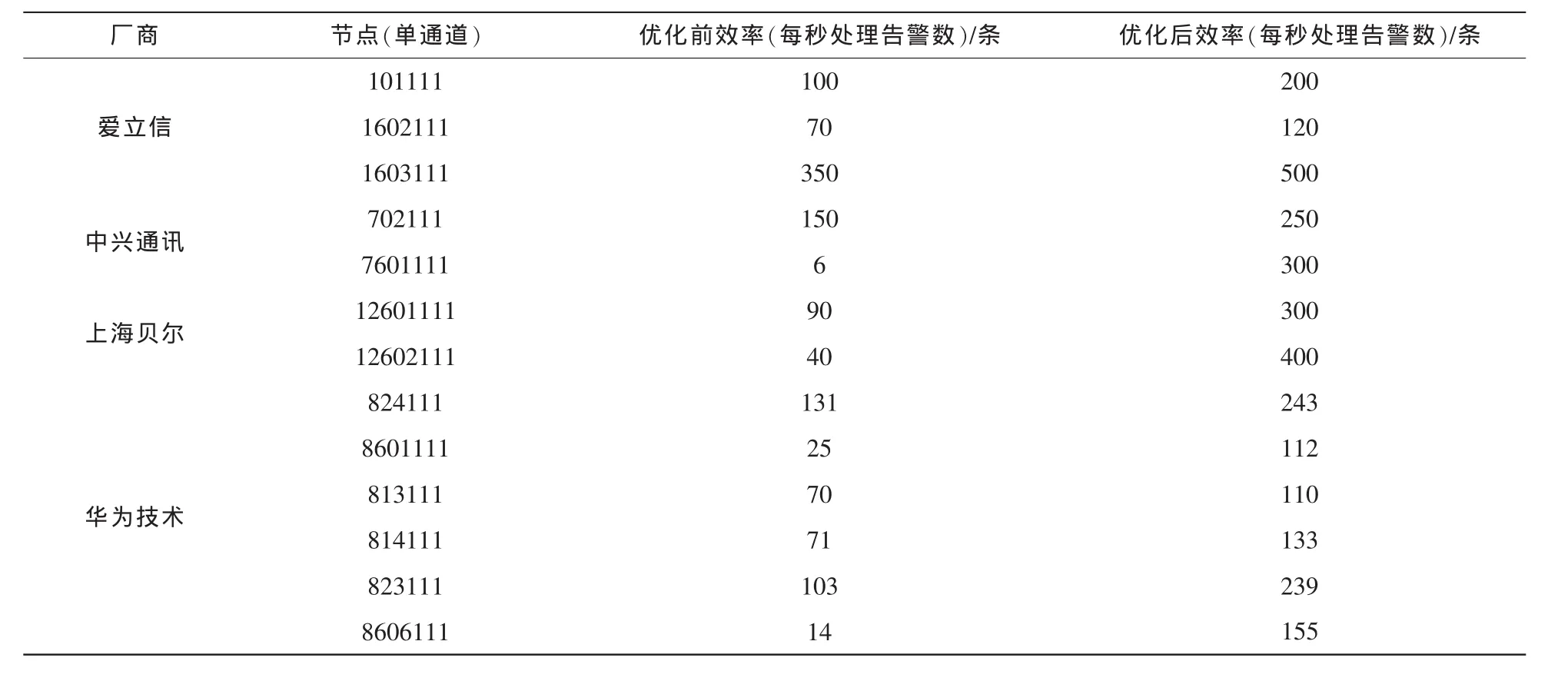
表1 廣西移動采集模塊優化測試結果
3.4 中間件參數配置手段
如圖7所示,消息隊列(MQ)是一種應用程序對應用程序的通信方法。應用程序通過“寫”和“檢索”出入列隊的針對應用程序的數據(消息)來通信,而無需專用連接器來鏈接它們。消息傳遞指的是程序之間通過在消息中發送數據進行通信,而不是通過直接調用彼此來通信,直接調用通常是用于諸如遠程過程調用的技術。排隊指的是應用程序通過隊列來通信。隊列的使用除去了接收和發送應用程序同時執行的要求。
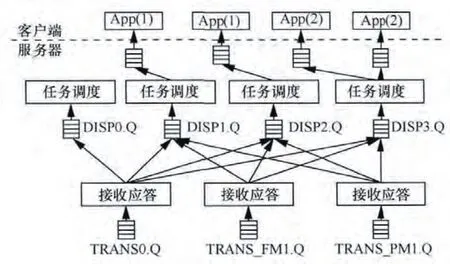
圖7 告警中間件MQ流程
IBM WebSphere MQ是綜合告警平臺使用的隊列中間件,對該中間件的參數配置進行優化,可以起到優化隊列長度,提高告警處理效率的效果。
對MQ進行了優化調校,主要從服務器參數、MQ參數、MQ日志配置、隊列參數、緩沖區參數、程序API調用等多個方面,增強了服務器處理性能,提高了MQ服務的處理速度,減少了核心程序對MQ的壓力。具體為以下幾個方面的調優。
·調整/etc/system系統參數,優化MQ服務的數據處理性能。
·優化MQ的斷網續傳參數,在Sun平臺下調整為:/usr/sbin/ndd-set/dev/tcptcp_keepalive_interval 15000。
· 優化MQ的日志配置,修改/var/mqm/qmgrs/隊列管理器名稱為/qm.ini,調整日志文件的個數、每個日志文件的大小、日志緩沖區大小。
· 修改偵聽的啟動方式,采用runmqlsr方式提高通道相關的性能。
·設置偵聽程序采用trusted方式運行,降低CPU和內存消耗。
· 增加通道的PipeLineLength屬性,設置MCA參數采用多個線程的方式傳輸消息,從而提高通道性能。
· 修改/var/mqm/qmgrs/隊列管理器名稱/qm.ini的TCP選項KeepAlive=Yes,使操作系統的TCP/IP參數設置對WebSphere MQ生效。
·修改核心程序對MQ的操作方式:MQCONN和MQDISC是最耗CPU的兩個函數,減少MQOPEN和MQCLOSE函數的調用,使用MQCONNX函數建立與隊列管理器的連接,使應用程序和本地隊列管理器代理組成同一個進程,從而提高性能。
以JFMHandler處理能力為例,經過測試,效果如圖8所示。
優化后,JFM處理消息的性能大約是544條/s,相比優化前的400條/s處理能力提升了36%。
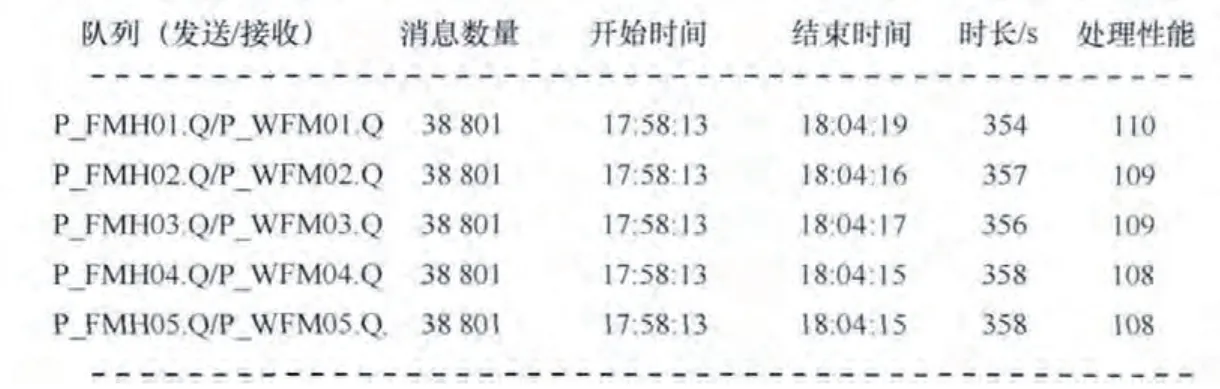
圖8 測試效果
3.5 服務異常檢測手段
為保證在告警風暴出現時,系統有能力對告警管理人員進行支撐,需要對告警系統新增服務負荷監控模塊,對綜合告警客戶端發起連接到服務端請求的過濾器服務進行監控,包括連接狀態、連接所占資源信息,方便監控人員及時定位服務異常情況。一旦發現服務內存溢出系統無法自行恢復時,可在最短時間內通過手工進行恢復,保證業務連續性。
4 升級改造后取得的成效
在2013年,廣西移動發生過類似臺風災害場景產生180萬條/天的告警量,平均處理能力只有12.66條/s。在經過了硬件擴容、軟件結構優化等調優工作,并進行測試和部署調整后,經過6個月的現網環境觀察,告警風暴處理能力有明顯提升。2014年7月,臺風威馬遜襲擊中國東南沿海,廣西受災。每天全網產生280萬條告警,形成特大告警風暴。平均每小時產生12萬條告警,峰值告警為15萬條,遠遠超過了系統的負載能力。經過事后日志分析,告警風暴最嚴重的7月19日,平均處理能力可達到120.4條/s,入庫60.3條/s。峰值擠壓時可在1 h內處理完畢。處理效率提高將近10倍,大大緩解了告警數據量的壓力。告警處理提升速度對照如圖9所示。
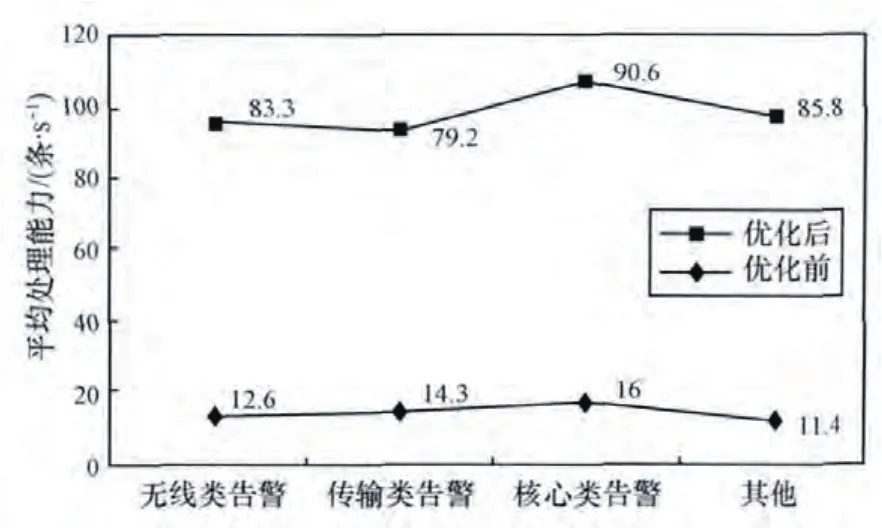
圖9 告警處理提升速度對照
告警風暴優化后,處理速度比優化前翻一番,細化了綜合監控的支撐粒度,解決了遇到重大故障不可用的問題,實現了由面向網絡到面向客戶、由被動運維向主動運維的轉變。以業務主體為核心,實現故障的集中監控、集中管理、工單直派一線,提高故障定位速度、分析和處理的效率,最終達到提升網絡運維質量的目的。
5 結束語
隨著移動通信4G網絡的建設以及集中化運維體制改革的深入推進,一個能有效管理網絡的運行支撐系統就成為必不可少的工具,成為影響運營質量的重要因素之一。通過升級綜合告警系統的軟硬件架構,使之具備應對告警風暴的能力,能夠使得綜合告警平臺為網絡運維創造更多價值。
在研究過程中,參考了部分省級運營商的先進經驗,結合自身“4+1”網管建設推進部署,每年都對系統進行深入研究,從業務(告警關聯)到技術(技術架構)進行深度優化,持續改進提升,以應對不斷變換的網絡環境,發揮網管系統的最大價值。
1 ITU-TRecM3200.TMNManagementServicesand Communications Managed Areas:Overview,2001
2 鄭慶國,呂衛峰.通信網絡中的告警相關性研究.計算機工程與應用,2002(2):11~15
Zeng Q G,Lv W F.Study on alarm correlation in communication network.Computer Engineering and Applications,2002(2):11~15
3 石永革,梅玉潔,石峰.通信網網管告警過濾機制的研究與應用.計算機工程與設計,2008,29(9):2169~2171
Shi Y G,Mei Y J,Shi F.Research and application of communication network management alarm filtering mechanism.Computer Engineering and Design,2008,29(9):2169~2171
4 klemettinen M,Mannila H,Toivonen H.Rule discovery in telecommunication alarm data.Journal of Network and Systems Management,1999(4):395~423
5 潘沛.電信網絡綜合告警系統需求分析與設計.大眾科技,2009(5)
Pan P.Analysis and design of telecom network integrated alarm system requirements.Public Science and Technology,2009(5)
6 聞海舟.淺談電信網絡綜合告警系統建設方案.廣西通信技術,2011(2)
Wen H Z.The construction scheme of telecom network integrated alarm system.Guangxi Communication Technology,2011(2)
7 馮婧篧,李興明.基于加權關聯模式的通信網告警相關性分析.電信科學,2007,23(11)
Feng J Y,Li X M.Telecommunication alarm correlation analysis model based on weighted association.Telecommunications Science,2007,23(11)
8 李寶山,王蘇東.告警管理系統中的告警同步模塊的設計.通信技術,2013(4)
Li B S,Wang S D.Design of alarm synchronization module in the alarm management system.Communications Technology,2013(4)
9 Kettschau H J,Bruck S,Schefezik P L.An expert system for intelligent fault management and alarm correlation.Proceedings of Network Operation and Management Symposium (NOMS),Florence,Italy,April 2002
猜你喜歡
發明與創新(2022年30期)2022-10-03 08:40:56
工業設計(2022年8期)2022-09-09 07:43:20
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
