基于SolrCloud的網(wǎng)絡(luò)百科檢索服務(wù)的實(shí)現(xiàn)
2016-01-24 12:09:46郝強(qiáng)高占春
軟件 2015年12期
關(guān)鍵詞:計(jì)算機(jī)軟件
郝強(qiáng)++高占春

摘要:網(wǎng)絡(luò)百科是一部在線百科全書,為用戶提供了資源豐富、內(nèi)容詳實(shí)的網(wǎng)絡(luò)查詢工具。網(wǎng)絡(luò)百科檢索服務(wù)是基于SolrCloud搭建的檢索平臺,服務(wù)部署在集群上,具有集中式的信息配置、自動(dòng)容錯(cuò)、近實(shí)時(shí)搜索和查詢時(shí)自動(dòng)負(fù)載均衡的特點(diǎn)。本文介紹了SolrCloud平臺的搭建方案,結(jié)合數(shù)據(jù)特點(diǎn)設(shè)計(jì)了索引結(jié)構(gòu),增加了中文分詞器和中文詞表,提高了在創(chuàng)建索引和檢索索引過程中的中文分詞效果。在SolrCloud平臺基礎(chǔ)上,本文根據(jù)搜索引擎原理提出了搜索引擎優(yōu)化方案,進(jìn)一步提升了搜索效果。通過在創(chuàng)建索引時(shí)對關(guān)鍵字段設(shè)置多顆粒度分詞模式,在檢索索引時(shí)對不同顆粒度分詞設(shè)置不同的權(quán)重,提高檢索效果;通過挖掘數(shù)據(jù)內(nèi)在的引用關(guān)系為文檔質(zhì)量評分,提高優(yōu)質(zhì)文檔在搜索結(jié)果中的排名。實(shí)驗(yàn)數(shù)據(jù)表明,優(yōu)化方法對網(wǎng)絡(luò)百科檢索服務(wù)效果有很大的提升。
關(guān)鍵詞:計(jì)算機(jī)軟件;搜索引擎優(yōu)化;SolrCloud;中文分詞
中圖分類號:TP311
文獻(xiàn)標(biāo)識碼:A
DOI:10.3969/j.issn.1003-6970.2015.12.024
本文著錄格式:郝強(qiáng),高占春.基于SolrCloud的網(wǎng)絡(luò)百科檢索服務(wù)的實(shí)現(xiàn)[J].軟件,2015,36(12):103-107
0 引言
1.網(wǎng)絡(luò)百科是一個(gè)包羅萬象的在線百科全書,涉及經(jīng)濟(jì)、政治、文化等各個(gè)方面。網(wǎng)絡(luò)百科的主體為詞條,分為中文和英文,由千萬量級的詞條構(gòu)成了龐大的知識庫,具有很強(qiáng)的知識性和科普價(jià)值,同時(shí)又鼓勵(lì)用戶參與創(chuàng)建和修改詞條,使網(wǎng)絡(luò)百科在豐富權(quán)威的同時(shí),也具有趣味性和快更新的特點(diǎn)。
2.在海量的數(shù)據(jù)中,按照用戶的需求高效、準(zhǔn)確地檢索出詞條和同條內(nèi)容是一項(xiàng)極具挑戰(zhàn)的任務(wù)。搜索引擎技術(shù)可以通過對數(shù)據(jù)文檔創(chuàng)建索引,實(shí)現(xiàn)對相關(guān)查詢的高效快速檢索,為用戶返回相當(dāng)數(shù)量的排序搜索結(jié)果。并且可以根據(jù)實(shí)際的數(shù)據(jù)特點(diǎn),通過多種手段對搜索引擎的進(jìn)行優(yōu)化,提高搜索結(jié)果的準(zhǔn)確率。
3.在處理大規(guī)模數(shù)據(jù)時(shí),不但需要考慮檢索的效果,也需要考慮計(jì)算機(jī)的運(yùn)算能力和故障風(fēng)險(xiǎn)。分布式搜索技術(shù)在集群上搭建服務(wù),通過負(fù)載均衡降低了機(jī)器的運(yùn)算負(fù)擔(dān),通過并行計(jì)算提高了集群的運(yùn)算能力,通過分布式存儲提高了整個(gè)集群的容災(zāi)能力。
4.本文使用SokCloud搭建分布式搜索引擎,為海量數(shù)據(jù)提供了高效準(zhǔn)確的檢索服務(wù),并提出了優(yōu)化搜索的方法,實(shí)驗(yàn)數(shù)據(jù)表明優(yōu)化方法有效提高了搜索的準(zhǔn)確率。
l SolrCloud介紹
Solr是一個(gè)基于Lucene的全文搜索服務(wù)器。Solr與Lucene相比,提供了更為豐富的查詢語言,提供了提供了基于Http的可返回json、xml等格式的接口。Solr提供了配置接口和擴(kuò)展接口,并能對查詢性能進(jìn)行優(yōu)化。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,SolrCloud將服務(wù)部署在集群上,通過Zookeeper進(jìn)行集群管理。SolrCloud在Solr的功能基礎(chǔ)上,具有4個(gè)新特性,包括集中式的配置信息,自動(dòng)容錯(cuò),近實(shí)時(shí)搜索和查詢時(shí)自動(dòng)負(fù)載均衡。SolrCloud為大數(shù)據(jù)量檢索提供了良好的解決方案。
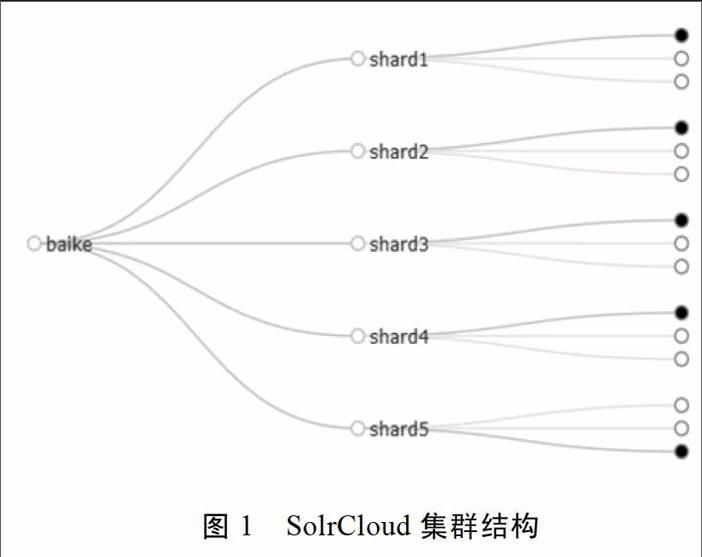
SolrCloud集群中collection是一個(gè)邏輯意義上的完整索引。一個(gè)collection通常被分成一個(gè)或多個(gè)shard,同一個(gè)collection的所有shard具有相同的配置。一個(gè)shard有一個(gè)或多個(gè)replica作為副本,每個(gè)shard的replica中會選舉出一個(gè)leader。
2 SolrCloud部署
2.1 SolrCloud搭建
網(wǎng)絡(luò)百科檢索服務(wù)使用的是solr-5.2.1版本,solr-5.2.1需要運(yùn)行在jdkl.7及以上版本。分析網(wǎng)絡(luò)百科數(shù)據(jù)量大小,以及自動(dòng)容錯(cuò)和負(fù)載均衡的需要,網(wǎng)絡(luò)百科檢索服務(wù)創(chuàng)建了名為baike的collection,baike分為5個(gè)shard,每個(gè)shard有3個(gè)replica。SolrCloud管理頁面展示的集群結(jié)構(gòu)見下圖。
搜索服務(wù)部署在5臺機(jī)器上,每臺機(jī)器分配4G內(nèi)存和16G存儲空間。分別在5臺機(jī)器上部署solr-5.2.1,在一臺機(jī)器的configsets目錄下創(chuàng)建屬于網(wǎng)絡(luò)百科檢索服務(wù)的配置目錄baike_configs,并在該機(jī)器上啟動(dòng)SolrCloud創(chuàng)建baike實(shí)例,在其余4臺機(jī)器上啟動(dòng)SolrCloud并加入該baike實(shí)例。這5臺機(jī)器組成了SolrCloud集群。
2.2 分詞器和詞表
網(wǎng)絡(luò)百科檢索服務(wù)是基于詞的倒排索引的查詢。詞是表達(dá)語義的最小單元,對于以英文為代表的的西方拼音語言來說,詞之間有明顯的分界符,英文以空格作為天然的分隔符。與西方拼音語言不同,中文繼承于古代漢語傳統(tǒng),詞之間沒有明確的分隔符。古代漢語中詞通常就是單個(gè)字,而現(xiàn)代漢語中雙字或多字居多。因此,中文搜索服務(wù)在索引創(chuàng)建和索引檢索之前,需要對文本中的句子進(jìn)行分詞,然后才能做相應(yīng)的其他處理。
分詞器的分詞效果直接影響了創(chuàng)建索引的內(nèi)容以及檢索的準(zhǔn)確度。中文分詞算法可分為三大類:基于字典、詞庫匹配的分詞方法;基于詞頻度統(tǒng)計(jì)的分詞方法和基于知識理解的分詞方法。目前,成熟的中文分詞器主要有IKAnalyzer、Paoding、MMSEG、ICTCLAS等。其中,IKAnalyzer和Paoding是基于字符串匹配的分詞器,加入一些啟發(fā)式規(guī)則,比如“正向/反向最大匹配”、“長詞優(yōu)先”等策略優(yōu)化。ICTCLAS分詞理論使用的模型是層疊隱馬爾可夫模型,該分詞器除了具有中文分詞和詞性標(biāo)注功能外,還支持新詞識別。
通過對分詞器的分詞效果、執(zhí)行效率和是否符合SolrCloud接口的綜合考量,在網(wǎng)絡(luò)百科檢索服務(wù)選擇了MMSEG分詞器。MMSEG由Chih-Hao Tsai開發(fā),使用了加入3段回溯式方法的基于詞表的分詞。MMSEG提供了三種模式,simple、max-word和complex。網(wǎng)絡(luò)百科檢索服務(wù)使用了細(xì)顆粒度分詞的max-word模式和加入了四個(gè)過濾規(guī)則的粗顆粒度分詞的complex模式。并收集整理了自定義詞表。關(guān)于增加中文分詞器的schema.xml配置如下。
2.3 網(wǎng)絡(luò)百科索引
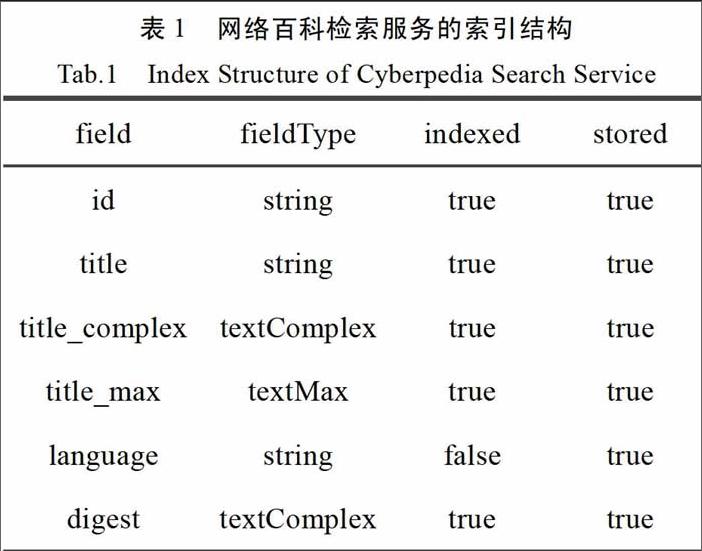
網(wǎng)絡(luò)百科的數(shù)據(jù)結(jié)構(gòu)為詞條標(biāo)題、詞條摘要、詞條正文、詞條語言和詞條圖片,在數(shù)據(jù)庫中存儲的對應(yīng)字段為title、digest、content、1anguage、picture。結(jié)合網(wǎng)絡(luò)百科的數(shù)據(jù)結(jié)構(gòu),設(shè)計(jì)的索引數(shù)據(jù)結(jié)構(gòu)見下表。
表l中,field列是索引中的字段名,fieldType列是索引中該字段的處理類型,indexed為布爾值,代表該字段數(shù)據(jù)是否被用來建立索引,stored為布爾值,代表該字段數(shù)據(jù)是否存儲。其中title對應(yīng)詞條標(biāo)題,language對應(yīng)詞條語言,digest對應(yīng)詞條摘要。
與詞條的字段結(jié)構(gòu)相比,索引字段中增加id字段,作為SolrCloud創(chuàng)建索引的唯一標(biāo)識字段,同時(shí)需要在schema.xml中將該id字段配置成uniqueKey。
索引字段中添加title_complex和title_max字段,這兩個(gè)字段是對title字段數(shù)據(jù)的復(fù)制,目的是實(shí)現(xiàn)對title字段的多顆粒度的分詞,為此需要在schema.xml中增加配置如下。
3 SolrCloud優(yōu)化
3.1 優(yōu)化概述
檢索服務(wù)本質(zhì)上是索引創(chuàng)建和索引檢索的過程。在海量的網(wǎng)絡(luò)資源中,每一個(gè)網(wǎng)頁都是一個(gè)文檔。在創(chuàng)建索引的時(shí)候,首先將每一個(gè)文檔進(jìn)行分詞得到詞,然后按詞生成倒排索引,倒排索引中存儲了文檔編號,也就是2.3節(jié)中的id字段。用戶在查詢時(shí)輸入查詢內(nèi)容。在檢索索引的時(shí)候,首先將用戶的查詢內(nèi)容進(jìn)行分詞得到詞,然后按詞在倒排索引中進(jìn)行檢索,最后對檢索結(jié)果處理,對檢索出的文檔進(jìn)行評分,按照評分對檢索結(jié)果排名,將最終結(jié)果返回給用戶。
評分越高,說明文檔內(nèi)容與用戶查詢的相關(guān)性越高。每個(gè)文檔由詞組成,每個(gè)詞有一個(gè)權(quán)重,那么一個(gè)文檔中的所有詞可以組成一個(gè)向量,表達(dá)式如下。
將每一個(gè)詞作為N維空間中的一維,將網(wǎng)絡(luò)百科檢索服務(wù)中的文檔中詞組成的詞向量與用戶輸入查詢內(nèi)容中的詞組成的詞向量放在N維空間中,比較不同文檔的詞向量與查詢的詞向量的夾角。
文檔與查詢的相關(guān)性大小可以使用文檔的詞向量與查詢的詞向量之間的夾角大小表示。文檔的詞向量與查詢的詞向量之間夾角越小,文檔的相關(guān)性越大。向量夾角可以使用余弦定理計(jì)算出來,計(jì)算公式如下。
結(jié)合以上公式和分析,從以下幾點(diǎn)對SolrCloud搭建搜索服務(wù)進(jìn)行優(yōu)化。
(1)對文檔和查詢語句進(jìn)行準(zhǔn)確地分詞;
(2)對關(guān)鍵字段使用多顆粒度分詞模式;
(3)對文檔內(nèi)容進(jìn)行評分,提高優(yōu)質(zhì)文檔在搜索結(jié)果中的排名。
其中,(l)已經(jīng)在2.2節(jié)介紹。
3.2 多顆粒度查詢
多顆粒度是指對語句分詞時(shí)切分的詞的粒度的大小。顆粒度大,平均詞的字?jǐn)?shù)較多,語句分詞后詞的數(shù)量較少;相反,顆粒度小,平均詞的字?jǐn)?shù)較少,語句分詞后詞的數(shù)量較多。在漢語中,詞是表達(dá)意思最基本的單位,但是不同的人對于詞的顆粒度理解是不同的。例如,某個(gè)語句中出現(xiàn)了“聯(lián)想公司”,有些人會將“聯(lián)想公司”看作一個(gè)整體,這是粗顆粒度分詞;有些人會認(rèn)為“聯(lián)想”是修飾“公司”的定語,那么分詞為“聯(lián)想”和“公司”兩個(gè)詞,這是細(xì)顆粒度分詞。
通常,粗顆粒度的詞會攜帶更多的信息,在消除不確定性上發(fā)揮更大的作用。粗顆粒度的詞在語義上更加明確。雖然粗顆粒度的詞有諸多好處,但是在檢索服務(wù)的實(shí)現(xiàn)中,并不能只使用這一種分詞方法。比如在創(chuàng)建索引時(shí)將“清華大學(xué)”看作一個(gè)整體,那么用戶在搜索“清華”時(shí)就無法找到“清華大學(xué)”的文檔。
在網(wǎng)絡(luò)百科檢索服務(wù)的設(shè)計(jì)中對關(guān)鍵字段title進(jìn)行了多顆粒度的分詞,通過字段的復(fù)制方法將title復(fù)制成title_complex和title max,并分別使用了完全匹配模式分詞、MMSeg的complex模式的粗顆度分詞和MMSeg的max模式的細(xì)顆粒度分詞。同時(shí),對于不同分詞模式的結(jié)果,在評分階段給以不同的權(quán)重。因?yàn)椴煌w粒度的詞所表達(dá)的信息量不同,通常粗顆粒度的詞會攜帶更多的信息,所以完全匹配模式的分詞給以最高的權(quán)重,complex模式的分詞次之,max模式的分詞給以最小的權(quán)重。分詞的顆粒度對查詢結(jié)果排名影響的計(jì)算公式如下
公式(4)中,coord(query,doc)表示一個(gè)文檔中包含查詢詞的數(shù)量,表示了該文檔與查詢語句的相關(guān)性。文檔中包含查詢詞的數(shù)量越多,coord(query,doc)的分?jǐn)?shù)越高,導(dǎo)致搜索結(jié)果的評分score(query,doc)越高。term.getBoost()表示了查詢內(nèi)容中每種顆粒度的分詞對查詢結(jié)果的影響。根據(jù)上面介紹的設(shè)置不同分詞模式的權(quán)重,不同分詞顆粒度對評分的影響大小也是不同的。顆粒度越大,term.getBoost()的分?jǐn)?shù)越高,導(dǎo)致搜索結(jié)果的評分score(query,doc)越高。所以完全匹配模式的評分對最終評分的影響最大,粗顆粒度分詞模式對最終評分的影響次之,細(xì)顆粒度分詞模式對最終評分的影響最小。
3.3 文檔評分
搜索結(jié)果的好壞即取決于查詢與網(wǎng)頁的相關(guān)性,也取決于網(wǎng)頁的質(zhì)量。在網(wǎng)絡(luò)百科檢索服務(wù)的設(shè)計(jì)中,通過文檔之間的相互引用關(guān)系來評價(jià)詞條內(nèi)容的質(zhì)量。網(wǎng)絡(luò)百科中的詞條都經(jīng)過專業(yè)編輯,詞條的內(nèi)容是可靠的,所以一個(gè)詞條被越多的文檔引用,那么它的內(nèi)容就越重要,所獲得的評分就會越高。該詞條的評分會影響到搜索結(jié)果的評分,最終影響詞條在搜索結(jié)果中的排名。
網(wǎng)絡(luò)百科檢索服務(wù)是通過solr4j編寫程序創(chuàng)建索引的。首先,使用分布式并行運(yùn)算統(tǒng)計(jì)出詞條的被引用情況并加以處理;然后創(chuàng)建索引時(shí),為每個(gè)詞條的SolrInputDocument對象,通過setDocument Boost()方法將處理后的文檔質(zhì)量評分存入索引。
文檔評分會影響搜索結(jié)果中文檔的排名,搜索結(jié)果評分的計(jì)算公式如下。
公式(5)中doc.getBoost()表示文檔評分。文檔評分越高,在搜索結(jié)果的評分也會越高。
3.4 實(shí)驗(yàn)結(jié)果
在搭建了SolrCloud平臺基礎(chǔ)上,從三個(gè)方面對網(wǎng)絡(luò)百科檢索服務(wù)進(jìn)行優(yōu)化,以提高搜索效果。增加分詞器和詞表,提高對文檔和查詢內(nèi)容的分詞效果;設(shè)置分詞的多種模式,并在檢索時(shí)對不同分詞顆粒度設(shè)置不同的權(quán)重;對文檔質(zhì)量進(jìn)行打分,提高優(yōu)質(zhì)文檔在搜索結(jié)果中的排名。通過實(shí)驗(yàn),上述三種方法有效提高了網(wǎng)絡(luò)百科檢索服務(wù)的搜索效果。實(shí)驗(yàn)結(jié)果見下圖。
在實(shí)驗(yàn)中,通過比較不同優(yōu)化方法對搜索準(zhǔn)確率的影響來評估對搜索效果的影響。在無優(yōu)化的搜索實(shí)驗(yàn)中,搜索的準(zhǔn)確率為56.2%。在分詞優(yōu)化的實(shí)驗(yàn)中,對SolrCloud增加了中文分詞器和多種顆粒度分詞,搜索的準(zhǔn)確率為80.6%,比無優(yōu)化的搜索準(zhǔn)確率提高了43.4%。在分詞+評分優(yōu)化的實(shí)驗(yàn)中,不但增加了中文分詞器和多種顆粒度分詞,還對文檔質(zhì)量進(jìn)行評分,評分結(jié)果影響查詢搜索的排名,該種方法實(shí)驗(yàn)中搜索的準(zhǔn)確率為85.3%,比無優(yōu)化的搜索準(zhǔn)確率提高了51.8%。實(shí)驗(yàn)數(shù)據(jù)表明,對SolrCloud的優(yōu)化方法對搜索效果有較大提升,最終的搜索結(jié)果準(zhǔn)確率更高。
4 結(jié)論
網(wǎng)絡(luò)百科檢索服務(wù)使用SolrCloud搭建檢索海量網(wǎng)絡(luò)百科數(shù)據(jù)的平臺,為用戶提供了高效優(yōu)質(zhì)的查詢功能。結(jié)合網(wǎng)絡(luò)百科的數(shù)據(jù)字段設(shè)計(jì)了索引的結(jié)構(gòu),分析了搜索引擎原理并提出了優(yōu)化檢索服務(wù)的方法,為SolrCloud增加了中文分詞器和詞表,結(jié)合實(shí)際數(shù)據(jù)設(shè)置了多種顆粒度分詞模式,挖掘數(shù)據(jù)內(nèi)在引用關(guān)系為文檔質(zhì)量評分。優(yōu)化方法有效提高了SolrCloud的搜索效果。
猜你喜歡
消費(fèi)電子(2021年7期)2021-08-10 06:03:55
信息技術(shù)時(shí)代·上旬刊(2020年1期)2020-09-10 07:22:44
電子制作(2018年16期)2018-09-26 03:27:08
電子制作(2018年1期)2018-04-04 01:48:36
電子制作(2017年14期)2017-12-18 07:08:03
電子制作(2017年10期)2017-04-18 07:22:58
電子制作(2017年24期)2017-02-02 07:14:40
工業(yè)設(shè)計(jì)(2016年7期)2016-05-04 04:02:29
汽車維護(hù)與修理(2015年2期)2015-02-28 12:15:57
河南科技(2014年19期)2014-02-27 14:15:24
