基于支持向量機的超超臨界鍋爐受熱面污染監測模型研究
2016-02-05 08:17:50周保中
發電技術 2016年6期
關鍵詞:模型
周保中
(華電電力科學研究院,浙江杭州310030)
基于支持向量機的超超臨界鍋爐受熱面污染監測模型研究
周保中
(華電電力科學研究院,浙江杭州310030)
通過某發電集團科技(創新基金)項目“超超臨界鍋爐吹灰優化試驗研究”,利用電廠已有的DCS采集系統,得到實時數據樣本,采用ε-支持向量機回歸機(ε-SVR)來進行模型學習預測,結果表明基于支持向量機的預測模型的均方誤差很小,能夠準確快速得跟蹤實際過程,取得了很好的預測效果。
支持向量機;鍋爐;污染監測
0 引言
近年來,國內外研究者對大型燃煤鍋爐受熱面灰污在線監測和吹灰優化開展了深入地研究,并作為節能與安全運行的重要措施得到了廣泛的應用和推廣。目前,基于熱平衡與傳熱計算原理開發的在線監測系統,已經在很多亞臨界和超臨界鍋爐中得到運用。
但鍋爐是一個非常復雜的動態系統,影響鍋爐受熱面積灰的因素很多,如受熱面布置、煙氣流速、負荷波動、煤質、有無吹灰等,這就使傳統的基于熱平衡和傳熱原理計算的結果與實際工況常有較大的出入。針對這些問題,國內外研究者開展了基于人工神經網絡、模糊系統、專家系統等智能技術的污染監測和智能吹灰研究,對優化鍋爐吹灰方案提供了有益的幫助[1-5]。但由于人工神經網絡這些非線性方法缺乏統一的數學理論基礎,特別是其中的結構選擇和權重初值設定均需依賴經驗,得到的模型通常并非全局最優,而是局部最優解,并且容易出現“過學習”的現象。本文采用在統計學習理論基礎之上發展起來的支持向量機(SVM)算法,對鍋爐受熱面污染監測模型做回歸預測,SVM可以很好得解決神經網絡“過學習”、網絡模型結構難以確定以及局部最小點等問題。
1 支持向量機回歸原理[6]
1.1支持向量機
1995年,Vapnik等人根據統計學習理論中結構風險最小化原則提出了支持向量機(SVM),其通過非線性變換(核函數)將輸入空間變換到高維空間,并在這個高維空間中求廣義的最優分類面。基于VC維和結構風險最小化原則的SVM根據有限的樣本信息在模型的復雜性和學習能力之間尋求最佳折中,能夠盡量提高學習機的推廣能力并同時有效避免“過學習”現象,并保證找到的極值解就是最優解。SVM在形式上如同神經網絡,輸出s個中間節點的線性組合,其每個中間節點對應一個支持向量。
1.2 ε-支持向量機回歸機(ε-SVR)
支持向量的方法應用到回歸預測問題中,就是要最小化一個凸函數,并且要求它的解是稀疏的。回歸算法就是要定義一個可以忽略真實值一定范圍內誤差的損失函數,即ε不敏感損失函數。ε-支持向量機回歸機就是建立在使用ε不敏感損失函數上的,而在ε-支持向量機回歸機的基礎上又發展出了ν-支持向量回歸機。下面主要介紹ε-SVR的算法。
設已知訓練集T={(x1,y1),…,(xl,yl)}∈(X×Y)l,其中xi∈X=Rn,yi∈Y=R,i=1,…l;
選擇適當的正數ε和C;選擇適當的核K=(x,x′);
構造并求解最優化問題:

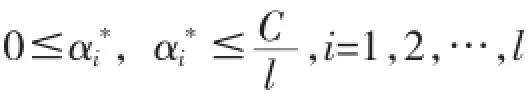
構造決策函數:


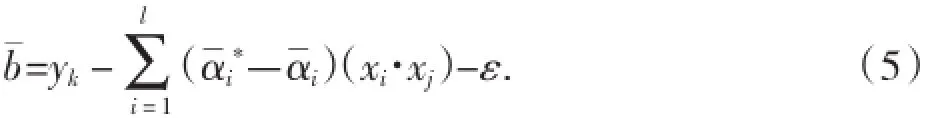
2 基于SVM的灰污監測模型
2.1研究對象的介紹
某發電廠超超臨界鍋爐是本生直流鍋爐。根據鍋爐各級受熱面清潔需求,共安裝有82支爐膛吹灰器、40支長伸縮式吹灰器以及12支半伸縮式吹灰器。爐內主要受熱面包括:爐膛、屏式過熱器、高溫過熱器、高溫再熱器、低溫過熱器、低溫再熱器、省煤器和空氣預熱器,各受熱面在爐內的布置如圖1所示。
2.2 樣本的選取

圖1 某發電廠超超臨界鍋爐受熱面布置示意圖
在基于熱平衡及傳熱原理計算的受熱面污染監測模型中,定義受熱面的污染因子CF(Cleanliness Factor)為受熱面實際傳熱系數Ksj與理想狀態傳熱系數Klx的比值,直接反映受熱面的污染程度。當受熱面清潔時,CF=0;CF越大則表明受熱面積灰結渣污染越嚴重。

作為輸出樣本點的灰污系數是綜合反應受熱面污染狀態的參數,通過試驗進行長時間積灰使受熱面積灰達到動態平衡,作為灰污系數的上限,假定為0.9;吹灰器動作后,灰污系數將快速下降,以吹灰器吹掃完畢時刻的灰污系數為下限,由于吹灰存在死角,沒有完全清潔的狀態,可以假定下限為0.2;根據積灰的規律,用多項式擬合積灰和吹灰過程中的灰污系數得到輸出樣本點。本文選取高再積灰試驗的數據作為總樣本,選取總樣本的一半樣本點作為學習樣本,另一半作為檢驗預測樣本,并在使用前先進行歸一化處理。
2.3 參數和核函數的選取
采用ε-支持向量機回歸機(ε-SVR)來進行模型學習預測。首先核函數選取徑向基函數:

為了獲得最佳的參數C和σ,并訓練得到最優支持向量回歸機,本文采用的尋優方法的多次交叉驗證。如根據數據情況將其拆分為3組,先用1和2來訓練分類器,預測3以得到誤差率;再用1和3訓練并預測2得到誤差率,最后用2跟3訓練并預測1得到誤差率。在進行交叉驗證時,記錄不同參數所對應的誤差率平均值,最終選取最小的誤差率平均值所對應的C和σ作為最優參數。通過LibSVM軟件采用此尋優方法得到最優參數C=2.0,σ=8.0和損失函數ε= 0.0009765625,將尋優得到的參數輸入對學習樣本進行學習,可以得到一個高再受熱面的灰污監測模型。
2.4模型分析
將尋優得到的參數運用到支持向量回歸機中對學習樣本進行學習,可以得到一個高再受熱面的灰污監測模型。再通過此模型對預測數據樣本進行預測,所得預測結果的均方誤差Means squared error=0. 000593793,相關系數Squared correlation coefficient=0. 989223,結果如圖2所示。由于選取的是高再受熱面積灰試驗的樣本,開始吹灰之前的灰污系數已經接近于上限0.9,當吹灰開始后,灰污系數明顯下降,吹灰結束后緩慢上升。由均方誤差和相關系數可見模型的準確性很高,曲線能夠很好的跟蹤實際過程,模型能夠準確反應出高再受熱面污染狀況的改變。

圖2 模型預測結果
3 結語
運用支持向量機算法對超超臨界鍋爐污染監測模型進行了預測,主要得出下面結論:
(1)支持向量機相比于神經網絡算法,使用了很小的樣本獲得了更準確的預測模型,并且避免了神經網絡“過學習”和局部最優化的問題。
(2)通過預測曲線可以看到,運用ε-支持向量回歸機得到的預測結果均方誤差很小,曲線能很好的跟蹤實際過程,運用支持向量機預測灰污系數的方案是可行的。
(3)目前基于支持向量機的鍋爐污染監測模型的研究還有待推廣到實際應用中,這是下一步的研究方向。
[1] 王新,馬波,向文國.600MW機組鍋爐對流受熱面在線監測研究[J].江蘇電機工程,2007,26(5):63-65.
[2] 萬俊松,向文國.基于神經網絡的電站鍋爐空氣預熱器積灰在線監測模型研究[J]. 能源研究與利用,2006,(3):14-16.
[3] 朱予東,閻維平,高正陽,等. 600MW機組鍋爐對流受熱面污染狀況實驗與吹灰優化[J]. 動力工程,2005,25(2):196-200.
[4] 吳觀輝,向文國.基于神經網絡的鍋爐對流受熱面灰污監測研究[J].鍋爐技術,2005,36(2):18-21.
[5] 王廣軍,欒秀春.基于人工神經網絡的電站受熱面污染部位診斷[J].鍋爐技術,2000,31(11):28-32.
[6] 白鵬,張喜斌,張斌,等.支持向量機理論及工程應用實例[M].西安:西安電子科技大學出版社,2008.
修回日期:2016-12-14
Research on Fouling Monitoring Model for Heating Surface of Ultra-supercritical Boiler Based on the Support Vector Machine
ZHOU Bao-zhong
(Huadian Electric Power Research Institute,Hangzhou 310030,China)
Through the study of“Experiments on Soot-blowing Effect of ultra-supercritical Boiler”from a science (innovative funding)project in a electricity generation group, a novel method was presented in the following part. To begin with, the real-time data sample was gathered by the DCS data acquisition system from the power plant. Furthermore, the ε-support vector regression(ε-SVR)was used to build the learning and prediction model. Eventually, the consequence confirms that the predictive model based on the support vector machine could achieve a minimal mean square error, which means this approach will perform well in actual process tracking and forecast results.
support vector machine (SVM);boiler;fouling monitoring
10.3969/J.ISSN.2095-3429.2016.06.010
TK16
B
2095-3429(2016)06-0036-03
周保中(1984-),男,江蘇寶應人,碩士研究生,主要研究領域為熱力系統優化、能源戰略與規劃、碳排放管理、電力市場等。
2016-10-08
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
