基于Spark的流程化機器學習分析方法①
2016-02-20 06:52:08趙玲玲中國科學院大學北京0090中國科學院軟件研究所北京0090
計算機系統應用 2016年12期
趙玲玲, 劉 杰, 王 偉(中國科學院大學, 北京 0090)(中國科學院軟件研究所, 北京 0090)
基于Spark的流程化機器學習分析方法①
趙玲玲1,2, 劉 杰2, 王 偉21(中國科學院大學, 北京 100190)2(中國科學院軟件研究所, 北京 100190)
Spark通過使用內存分布數據集, 更加適合負載數據挖掘與機器學習等需要大量迭代的工作. 但是數據分析師直接使用Spark進行開發十分復雜, 包括scala學習門檻高, 代碼優化與系統部署需要豐富的經驗, 同時代碼的復用度低導致重復工作繁多. 本文設計并實現了一種基于Spark的可視化流程式機器學習的方法, 一方面設計組件模型來刻畫機器學習的基本步驟, 包括數據預處理、特征處理、模型訓練及驗證評估, 另一方面提供可視化的流程建模工具, 支持分析者設計機器學習流程, 由工具自動翻譯為Spark平臺代碼高效執行. 本工具可以極大的提高Spark平臺機器學習應用開發的效率. 論文介紹了工具的方法理論和關鍵技術, 并通過案例表明工具的有效性.
機器學習; 數據分析; 分布式; 大數據; Spark
1 引言
信息技術的發展帶來生活的便利與快速增長的數據. 隨著以機器學習為代表的大數據分析技術的日益成熟, 大數據為社會經濟生活帶來了巨大的影響, 并為商業決策提供了大量的幫助. 例如在電子商務行業,淘寶通過對海量交易數據進行學習, 為用戶提供專業的個性化推薦; 在廣告行業, 網絡廣告通過追蹤用戶的點擊對喜好進行預測, 提高用戶體驗.
但是, 傳統的商業關系型數據管理系統已經無法處理海量數據的大容量、多樣化與高維度的特點[1]. 為了解決大數據分析的問題, 分布式計算得到廣泛的應用. Apache Hadoop[2]是近年廣泛使用的分布式系統之一. Hadoop采用MapReduce作為嚴格的計算框架. Hadoop的出現促使了大規模數據處理平臺的流行. 與Hadoop同樣受到廣泛應用的還有Spark[3], 由伯克利大學的AMPLab開發的大數據架構. Spark融合了批量分析、流分析、SQL處理、圖分析以及機器學習等應用. 相對于Hadoop, Spark具有快速, 靈活, 容錯性等特點, 是運行機器學習分析程序的理想的選擇方案.但Spark是一個開發者使用工具, 要求分析人員具備一定的計算機技術能力, 并且花費大量時間去創建、部署與維護系統.
機器學習的結果嚴重依賴于數據質量與模型邏輯,所以為了令分析人員能夠專注于流程本身, 不在分析程序編譯、運行、并行化等方面花費精力, 本文設計并實現了一個基于Spark的流程化機器學習分析工具.形式上看, 每個機器學習分析任務被分解成不同的階段, 以組件的方式組成, 降低了使用者的學習成本.技術上, 通用的算法被封裝成組件包進行復用, 通過參數設置實現訓練過程的差異化, 減少了創建機器學習分析程序的時間成本. 使用者可以通過拖拽算法組件, 靈活地組建自己的分析流程, 提高應用的創建與執行效率.
本文將通過相關工作與目前存在的產品進行對比展示本工具的特點, 然后再從系統體系結構設計、使用案例闡述業務模型、深入系統模塊說明功能運作等部分進行詳細說明. 同時, 本文將在最后進行技術總結以及未來研究方向的展望.
2 相關工作
Azure Machine Learning(簡稱“AML”)[4]是微軟在其公有云Azure上推出的基于Web使用的一項機器學習服務, 它內置了基于監督學習和非監督學習的分類、回歸、聚類等的20多種算法, 并且仍在不斷的增加. 但AML基于Hadoop而且只能在Azure上使用, 與之不同, 本文的工具基于Spark設計與實現, 并且能夠靈活的在不同的虛擬機或云環境上部署.
Apache Zeppline[5]是一個基于Spark的響應式的數據分析系統. 其目標是打造集成多種算法庫的、互動的、可視化、可分享的Web應用. 現已成為開源的筆記式的分析工具, 支持大量的算法庫以及多種語言.但是Zeppline沒有提供一個用戶友好的圖形接口, 所有分析程序需要用戶編寫腳本提交運行, 提高了用戶的編程技術要求. 本論文的工具提供組件化的圖形工具以及大量的機器學習算法, 用戶可以簡單快速的定義機器學習流程并運行得到結果.
文獻[6]中介紹一個大數據分析服務平臺Haflow.該系統使用了組件的設計, 可以拖拽組建流程化的分析程序. 并且開放了擴展接口, 可以使開發者創建自定義的分析算法組件. 目前Haflow僅僅支持Hadoop平臺的MapReduce算法組件, 本文的工具以Haflow為基礎, 使其能夠支持Spark的組件應用, 并提供大量在Spark環境下運行的機器學習算法.
3 基于Spark的流程化機器學習分析工具
3.1 機器學習流程概述
本文旨在設計一個面向數據分析師的流程化機器學習工具, 所以需要實現常用的機器學習流程的功能.機器學習可以為監督學習與非監督學習, 主要依據是否有具體的標簽. 標簽是觀測數據的目標或預測的對象. 而觀測數據是用來訓練和測試機器學習模型的樣本. 特征是觀測數據的屬性, 機器學習算法主要是從觀測數據的特征中訓練得到預測規律[7].
實踐中, 機器學習流程包括一系列的階段, 包括數據預處理、特征處理、模型擬合以及結果驗證或預測. 例如, 將一組文本文檔進行分類包括分詞、清理、提取特征、訓練分類模型以及輸出分類結果[7].
這些階段可以看作是黑盒過程, 并且可以包裝成組件. 雖然有很多算法庫或是軟件為每個階段提供了程序, 但是這些程序很少是為大規模數據集或是分布式環境準備的, 并且這些程序并不是原生支持流程化,需要開發人員去連接每一個階段形成完整的流程.
所以本系統在提供大量機器學習算法組件的同時,也要完成自動執行流程的功能, 兼顧流程的運行效率.
3.2 系統業務模塊設計

圖1 典型的機器學習流程
本系統將組件做為主要業務功能提供給使用者.分析人員可以將現有組件自由的組合成不同的分析流程. 為了能夠覆蓋常用的機器學習流程, 本系統提供以下幾類業務模塊: 輸入輸出模塊、數據預處理模塊、特征處理模塊、模型擬合模塊以及結果預測模塊. 與其他系統不同, 本工具設計的業務模塊以流程中的各階段為定義, 前后依賴.
① 輸入輸出模塊. 本模塊用來實現數據的獲取與寫入, 主要處理數據源的異構性, 是整個機器學習流程的起點與終點. 為了能夠處理不同的數據類型,本系統提供結構化數據(如CSV數據)、非結構化數據(如TXT數據)、半結構化數據(如HTML數據)的輸入或輸出功能.
② 數據預處理模塊. 本模塊包括數據清理、過濾、join/fork與類型改變等功能. 數據質量決定了機器學習模型準確度的上限, 所以在進行特征提取前, 完善的數據預處理過程也是必需的. 本模塊可以對空值或異常值的清理、更改數據類型, 并且可以過濾掉不符合條件的數據.
③ 特征處理模塊. 特征處理是在對數據進行建模前最重要的環節, 包括特征選擇與特征抽取兩種功能本系統目前包含25種常用的特征處理算法, .
特征選擇是對多維的特征進行選擇, 利用算法挑選最有價值的特征, 選出的特征是原來特征的子集.根據選擇的算法不同分為信息增益選擇器、卡方信息選擇器與Gini系數選擇器等組件.
特征抽取是將觀測數據的特征按照一定算法轉換成新的變量, 相對于數據預處理, 對數據的處理規則更加的復雜. 抽取后的特征是原有特征的映射, 包括以下幾類:
I.標準化組件. 標準化是將數據的數值型特征映射到統一的量綱的算法. 經過標準化的特征被統一到相同的參考系下, 使訓練出來的模型更加準確, 訓練過程中收斂更快. 不同的標準化組件使用不同的統計量進行映射. 如Normalizer組件、StandardScaler組件、MinMaxScaler組件等.
II.文本處理組件. 文本類型的特征由于不能直接計算, 需要映射到新的數值類型變量上. 常用的算法有將文本進行分詞建立索引的TF-IDF組件, 分詞Tokenizer組件, 獨熱編碼OneHotEncoder組件等.
III.降維類組件. 這類組件將原有的特征通過一定的算法, 將原有的特征信息進行壓縮, 用更少的特征進行表示, 如主成分分析PCA組件等.
IV.自定義UDF組件. 用戶可以輸入SQL自定義特征處理的功能.
④ 模型擬合模塊. 模型訓練是用某種算法對數據進行學習, 得到的模型可以用于后續對數據的預測.本系統目前提供大量的監督學習模型組件, 根據觀測數據標簽性質的不同, 可以分為分類模型與回歸模型.
⑤ 結果預測模塊. 本模塊包括結果預測與驗證兩個功能.
通過以上通用的業務模塊的設計, 用戶可以在本系統環境下創建多樣化的常用的機器學習分析流程.
3.3 系統體系結構設計
本系統通過Web提供用戶接口, 以整體架構以MVC框架為主, 同時提供機器學習的業務模塊以及流程的執行模塊, 系統體系結構如圖2所示.
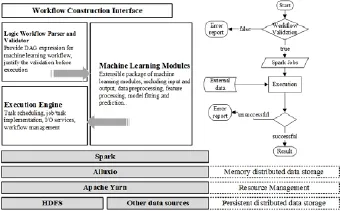
圖2 系統體系結構圖與工作流程圖
用戶通過系統提供的Web界面創建形式上的機器學習流程, 提交給系統. 系統將把接收到的原始流程轉換成邏輯流程圖, 并對流程圖進行有效性驗證. 流程的有效性驗證是分析流程在實際執行前的必要的一環, 當流程有明顯的邏輯或數據不匹配等錯誤時, 能夠立該返回錯誤, 而不是等執行到相應的組件時再報錯, 提高了系統的運行效率.
系統的執行引擎是系統的關鍵模塊, 實現多用戶和多任務的流程執行功能. 它將驗證有效的邏輯流程圖翻譯成相應的執行模型, 執行模型即是系統可識別的用來調度相應業務組件的數據結構. 執行模型的翻譯是一個復雜的過程, 本文將在4.3節中進行詳細介紹.
4 系統實現及關鍵技術研究
4.1 中間數據的存儲與管理
4.1.1 中間數據的存儲結構
在整個機器學習流程中, 數據處于流動的狀態,具有順序依賴的組件需要傳遞中間數據. 為了避免中間數據異構性的問題, 本系統規定組件間使用統一的基于DataFrame[8]的列式存儲結構進行通信. DataFrame是一種Spark支持的以列為主的分布式數據集合, 在概念上類似于關系數據庫的“表”, 但在Spark底層對其運算執行做了很多優化. 這種方式保留了結構化數據的關系, 并且對特殊的數據屬性進行定義,規定features和label作為模型擬合階段所需數據的頭部, 以方便流程的驗證與執行.
這種列式存儲結構可以被整個系統快速的持久化到中間數據存儲層, 并且在后面的組件使用時快速的還原成需要的數據對象.
4.1.2 中間數據的管理
中間數據在不同的生命周期需要不同的管理. 當組件對之前的數據進行處理后, 即在中間數據的生成階段, 系統會記錄中間數據的生成位置, 用于傳遞給下一組件. 在流程執行結束后, 所有該流程產生的中間數據將不再被使用, 會被系統統一刪除. 同時, 單個流程的中間數據存儲空間有規定的上限, 當中間數據產生過多時, 流程的資源管理器將采用近期最少使用算法(LRU, Least Recently Used)[9]對數據進行清除,以防止中間數據過多發生內存溢出的問題.
為了保證中間數據的IO效率, 本系統使用Alluxio[10]作為中間的存儲層, 將中間數據全部保存在內存中. Alluxio是一種基于內存的虛擬分布式存儲系統, 可以大幅加速數據的讀寫速度.
4.2 機器學習業務組件的實現方法
4.2.1 基于Spark MLlib的機器學習分析組件的實現
本文在第3.2節詳細的說明了系統的機器學習模塊的設計, 這些模塊通過組件的形式完成主要的數據處理與建模功能. 為了快速的提供盡可能多的算法組件, 除了少部分根據機器學習流程的特點編寫了處理程序的組件, 如輸入輸出組件、數據清理組件等, 很多的組件功能通過Spark MLlib自動轉換成相應的Spark Job完成. Spark MLlib[11]是Spark自帶的機器學習算法庫, 包含了大量的分類、回歸、聚類、降維等算法. 例如使用隨機森林進行分類, 系統的執行引擎根據流程的結點信息, 實例化具有相應參數的RandomForestClassifier對象, 調用fit方法對輸入的數據進行擬合, 生成相應的Model對象, 然后通過中間數據管理模塊將模型序列化保存, 供后續的預測或驗證組件使用. 通過這種方法, 能夠保證每個學習算法的質量, 而且能與Spark社區同步, 快速的添加新的算法組件.
4.2.2 共享Spark上下文執行流程中的組件
流程中的組件有兩種運行方式. 一種是作為獨立的Spark程序調用, 每次運行都啟動一次Spark上下文(SparkContext). Spark程序在剛開始啟動時, 會創建上下文環境, 確定資源分配, 如調用多少線程、內存, 之后再進行相應的任務調度. 一般的機器學習流程由很多個組件組成, 將會花費大量的運行時間去完成上下文的啟動與切換. 另一種方法, 可以令每個流程共享同一個上下文, 整個流程可以看作是一個大的Spark程序. 但系統的執行引擎需要為每個流程創建與管理上下文, 在流程結束時也要將上下文對象釋放回收資源.
為實現上下文的共享, 每個組件都要繼承SparkJobLike或者其子類, 并實現創建組件對象(createInstance)與執行組件(execute)方法. 圖3是類的設計與繼承關系圖. 其中, Transformers、Models、Predictors分別是數據清理與數據預處理模型、學習訓練模型、驗證與預測模型的父類.
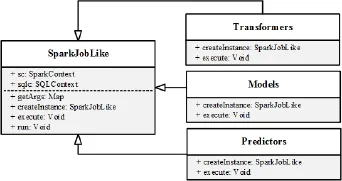
圖3 組件類設計與繼承關系圖
4.3 機器學習流程的創建與驗證
當用戶通過圖形界面設計好機器學習分析流程并提交后, 系統將開始創建邏輯上的分析流程. 系統首先通過對原始流程進行拓撲分析, 生成以有向無環圖(DAG, Directed Acyclic Graph)來表示的邏輯流程圖.邏輯流程圖包括各組件的前后依賴與并行關系, 以及輸入輸出、參數信息.
當前流程的邏輯結構生成后, 將對整體流程的有效性進行驗證. 具體步驟如下:
① 檢查圖中每個結點的輸入與輸出及其他必要的參數信息, 缺少則返回錯誤, 如特征處理的組件用戶必須定義input column與output column;
② 檢查整個流程的完整性, 如是否存在至少一個輸入組件與輸出組件作為開端和結束, 否則返回錯誤;
③ 檢查流程圖中是否存在自循環, 否則返回錯誤;
④ 檢查各個組件是否符合機器學習流程的前后依賴關系, 比如特征處理必須在模型擬合之前, 不符合則返回錯誤.
4.4 機器學習流程的翻譯與執行
對流程進行驗證后, 流程圖將被提交給執行引擎.首先系統需要將邏輯的流程圖表示成可以直接執行的模型, 再轉換成基于Spark MLlib的機器學習算法組件再串行或并行執行, 這個過程稱為流程的翻譯與執行. MLlib[11]是Spark內置支持的分布式機器學習算法庫,優化了大規模數據和模型的并行存儲和運算. 使用Spark MLlib, 可以快速開發出大量高效的組件程序.這部分將著重介紹系統如何將流程翻譯成可以執行的模型, 加速機器學習分析流程的運行.
4.4.1 流程中同時發生多個并行join/fork任務
Join組件是將不同的數據集歸并到同一個數據集的組件, 與之前的組件是多對一的關系. Fork組件是將同一個數據集分別應用到不同流程分支的組件, 與之后的組件是一對多的關系. Join/fork組件在實際中有大量的應用, 比如用于商品推薦的協同過濾算法中,為了充分的描繪用戶信息, 需要同時join用戶的交易數據、品牌數據、出生居住地信息等各種關聯的數據.得到的具體的用戶剖繪(user profile)再fork到每個商品得到相應的偏好概率[12].
當發生多個數據集同時join的任務時, 為了高效率的并行執行流程, 使用分治算法, 將不同的join分支分別執行, 最后再歸并. 當從同一數據集fork出多個流程分支時, 對每個流程分支并行執行, 不影響最終的模型結果. 總之, 對有多個join以及fork任務的機器學習流程要盡可能的并行執行, 提高運行效率.
4.4.2 多個串行與并行任務的復合流程的翻譯
上一節介紹了當流程中出現多個join/fork的并行任務時的翻譯方法, 但是實際中的機器學習流程并不會是單純的串行或并行的關系, 而是串行的任務和并行的任務組合成的, 所以實際中的機器學習流程的情況更加復雜. 要將復雜的流程轉換成執行引擎, 其難點在于要盡可能的并行執行流程, 但不會打亂組件的之間的數據依賴關系. 以下為復合流程的翻譯方法:
① 對流程圖進行廣度優先遍歷, 確定業務組件間的拓撲關系;
② 以數據預處理、特征處理、模型擬合與預測的階段為標準劃分相同階段的子流程;
③ 通過關鍵路徑算法判斷各子流程內部的執行情況, 以拓撲情況確定子流程中分支的層次關系;
④ 上個步驟后得到的同一層次的分支再按照上一節的算法進行優化.
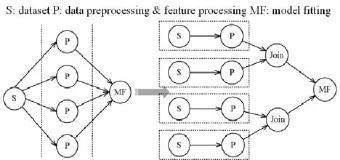
圖4 多個join和fork并行流程的翻譯
5 案例分析
5.1 實驗環境與數據說明
目前本系統尚處于原型階段, 為了實驗系統功能,本文使用四核處理器、8G內存、64位Ubuntu系統的單機布署偽分布式的環境進行實驗.
實驗數據是來自Kaggle[13]的公開數據集, 通過2003年至2015年的洛杉磯城市的犯罪記錄數據, 對犯罪類別進行建模. 為了方便流程的展示說明, 本文選取了三個原始特征, 選用常用的機器學習分析方法創建流程, 特征與標簽的數據特點如表1所示. 總結來說特征與標簽以字符串為主, 需要數據預處理進行特征提取, 并映射成數值型的特征.

表1 數據特點說明
5.2 機器學習流程的創建與說明
為了將原始特征轉換成訓練模型可以計算的數值型特征向量, 需要進行一系列的數據預處理工作. 表2是對每個特征處理方法的說明, 全部的參數設置一般為默認, 如有改動會特別說明.
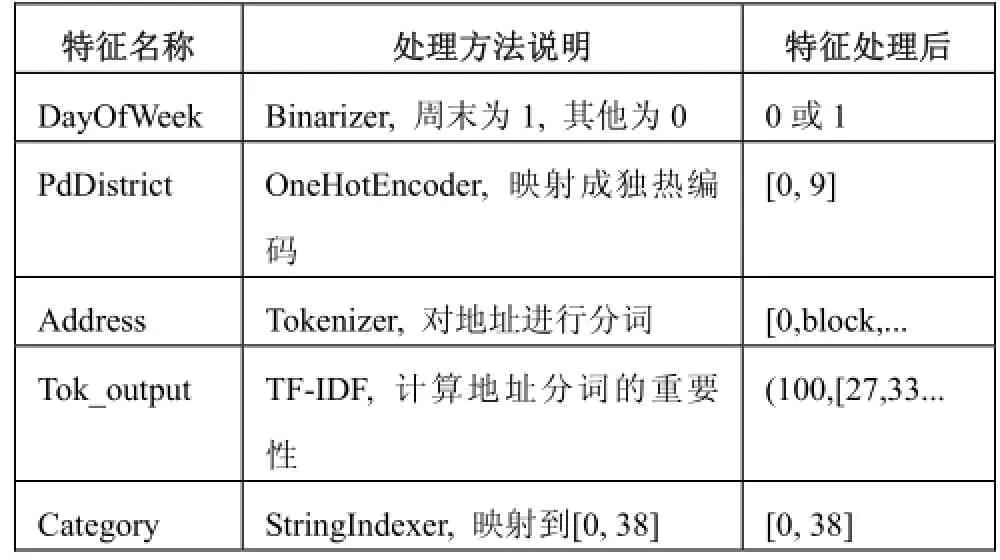
表2 數據預處理說明
預處理后得到的特征將通過Join組件合并成features向量, 經過TF-IDF后特征向量的維度高但比較稀疏, 使用ChiSqSelector選擇卡方信息量最大的100個特征擬合模型. 采用LogisticRegression-WithLBFGS擬合多分類模型, 然后將測試數據通過訓練好的模型進行預測, 將結果輸出保存成CSV文件.圖5是將上述分析流程在系統創建后的界面.
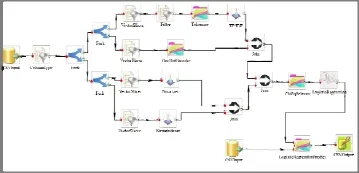
圖5 創建好的流程圖界面
5.3 實驗結果分析
通過比較測試數據的預測值和實際的label, 準確率在72.54%左右. 如果向流程中添加更多的特征, 模型的復雜度會變大, 同時準確率也會上升. 使用本系統, 可以方便快速的創建機器學習流程, 用戶可以專注于分析方法的改進.
本文在第四部分介紹了流程的并行執行優化, 為了測試優化方法的有效性, 將本實驗的數據隨機抽取,分成10%、20%、30%...100%大小的十份數據, 將這十份數據分別使用優化過的方法和沒有優化的方法執行本實驗的分析流程, 沒有優化是指將流程中的組件按照前后順序串行執行, 獲得每個流程的運行時間, 單位為ms, 如圖6所示.

圖6 優化與未優化的時間效率對比圖表
可以看出, 隨著數據量的線性增長, 未優化的流程執行的時間增長的更加快, 而且到后期時間的增長率有增大的趨勢. 而經過優化的流程執行方案, 隨著數據量的增加, 時間增長的相對緩慢, 說明系統執行優化方案的有效性.
6 結論
本文為了解決數據分析師采用Spark開展大規模數據的機器學習分析的問題, 設計并實現了一個分布式的、支持多種機器學習算法的流程化的分析系統的原型. 本文的第三部分從整體介紹了本系統的業務模型與體系結構. 第四部分從各個模塊開始詳細說明關鍵技術, 包括中間數據的存儲與管理、機器學習業務組件的實現、機器學習流程的創建與驗證、機器學習流程的翻譯與執行. 并且對復雜的機器學習流程的執行在邏輯上進行了優化, 將邏輯流程圖翻譯成可以在物理執行階段盡可能高效的并行執行的模型.
本系統目前將Spark MLlib所有算法自動轉換為組件, 仍需要在實踐中不斷的對算法庫進行擴展. 同時, 未來可以在數據依賴的方面進行研究, 如系統可以對數據集自動進行分片, 將同一數據集的不同特征的處理任務分配到不同的分布式結點并行處理, 提高特征處理任務的執行效率以及分布式資源的利用率.
1 Labrinidis A, Jagadish H V. Challenges and opportunities with big data. Proc. of the VLDB Endowment, 2012, 5(12): 2032–2033.
2 http://hadoop.apache.org/docs/current/.
3 Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets. HotCloud, 2010, 10: 10–10.
4 https://azure.microsoft.com/en-us/blog/.
5 https://zeppelin.incubator.apache.org/docs/0.5.6-incubating.
6 趙薇,劉杰,葉丹.基于組件的大數據分析服務平臺.計算機科學,2014,41(9):75–79.
7 Carbonell JG, Michalski RS, Mitchell TM. An Overview of Machine Learning. Springer Berlin Heidelberg, 1983: 3–23.
8 Armbrust M, Xin RS, Lian C, et al. Spark sql: Relational data processing in Spark. Proc. of the 2015 ACM SIGMOD International Conference on Management of Data. ACM. 2015. 1383–1394.
9 Megiddo N, Modha DS. Outperforming LRU with an adaptive replacement cache algorithm. Computer, 2004, 37(4): 58–65.
10 Li H, Ghodsi A, Zaharia M, et al. Reliable, memory speed storage for cluster computing frameworks. Proc. SoCC, 2014. 11 Meng X, Bradley J, Yavuz B, et al. Mllib: Machine learning in apache Spark. arXiv preprint, arXiv:1505.06807, 2015.
12 鄧愛林,朱揚勇,施伯樂.基于項目評分預測的協同過濾推薦算法.軟件學報,2003,14(9):1621-1628.
13 https://www.kaggle.com/c/sf-crime.
Method of Implement Machine Learning Analysis with Workflow Based on Spark Platform
ZHAO Ling-Ling1,2, LIU Jie2, WANG Wei212
(University of Chinese Academy of Sciences, Beijing 10090, China) (Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing 100190, China)
By using resilient distributed dataset, Spark is more adapted to iterative algorithms, which are common in data mining and machine learning jobs. However, the development of Spark applications is complicated for data analysts on account of the high threshold to learn scala, the rich experience of code optimization and system deployment, as well as multiple duplicated work due to the low reusing of code. We design and develop a machine learning tool with visible workflow style based on Spark. We design the stages of machine learning with workflow modules, including data preprocessing, feature processing, model training and validation. Meanwhile, a friendly user interface is brought forward to accelerate the design of machine learning workflow model for analysts, with the support of auto parsing from modules to Spark jobs by server end. This tool can greatly improves the efficiency of machine learning development on Spark platform. We introduce the theoretical methods and critical techniques in the paper, and prove its validity with a real instance.
machine learning; data analysis; distributed; big data; Spark
國家自然科學基金(U1435220)
2016-03-21;收到修改稿時間:2016-04-11
10.15888/j.cnki.csa.005454
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
家庭影院技術(2017年9期)2017-09-26 03:41:45
