IT運維分析成新趨勢
2016-02-27 20:14:39劉晶晶
中國信息化周報 2016年6期
劉晶晶
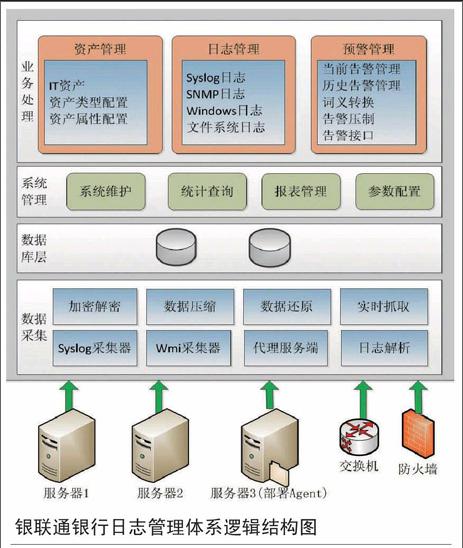
隨著近幾年大數據技術的興起,業內開始把大數據技術應用到IT運維上進行分析,進而產生了IT運維分析ITOA。把大數據技術應用到IT運維上分析的目的是提高數據質量和效率,以及可用性監控、應用性能監控、故障根源分析、安全審計等方面的指標。根據權威的調查機構Gartner預測,到2017年15%的大企業會積極使用ITOA,盡管2014年這個數字只有5%,日志易首席執行官陳軍表示ITOA是新生事物,正在被市場逐步接受。
多源的數據支持
ITOA將大數據技術應用在運維數據的分析上,數據的來源就非常重要。ITOA的數據來源主要分為四方面:第一是機器數據、服務器、網絡設備產生的數據,簡言之就是日志;第二是通信數據,如今網絡普及,后臺的設備很多都是大型的分布式系統,都有網絡的通信;第三是代碼級別進行統計分析,例如通過PHP、JAVA這些字節碼來插入統計分析的代碼,進而統計函數調用情況、堆站的使用情況等,從代碼級別來進行統計分析會呈現更加精細化的成果,也可稱為代理數據;第四是探針數據,例如全國用戶訪問IDC的延時是多少,必須在全國布點并發起模擬用戶的請求探測,進行端到端延時方面的度量。
美國有一家運作ITOA的公司,他們做了一項用戶調查來統計四種數據來源使用情況,其中日志的使用比例非常高,達86%,網絡抓包達93%,插入代碼代理數據是47%,探針數據是72%。日志與網絡抓包占的比例非常高,占總體的80%-90%,這充分顯示了日志數據采用的重要性。
日志無所不在,所有服務器、網絡設備、應用系統都會產生日志,不同的應用輸出的日志完整性與可用性不同。通信數據從網絡流量統計的信息非常全面,但也有局限性,一些事件未必觸發網絡通信,如果沒有觸發網絡通信的話就不會產生網絡流量,也就沒法做出統計。
代理數據潛入代碼的使用比例較低,它的優勢在于可以進行代碼級別的精細監控,能看到代碼的執行情況,但它也存在一定的侵入性。插入代碼,執行時已經改變了原來程序的執行流程,每次執行都會插入代碼,插入的代碼可能會帶來性能問題,降低被檢測程序的性能。另外,還有安全、穩定性的顧慮,插入代碼有沒有把一些敏感信息竊取,插入的代碼是不是足夠穩定,如果插入代碼崩潰則會導致被監測程序的一系列崩潰。
探針數據是用來模擬用戶請求,完成端到端監控,可以從手機訪問到服務器端到端的延時,但并不是真實的用戶度量,業界希望度量到用戶真正的延時情況,而不是模擬。例如像騰訊、百度類似的移動應用廠商,已經有數以億計的終端用戶,他們可以直接在手機應用端做真實的用戶度量,可以看到真實用戶的訪問情況。2008年汶川地震的時候騰訊QQ客戶端實時監測到汶川地區用戶QQ掉線,馬上知道那里發生了重大事故,做到了真實的網絡度量。
海量日志的“前世”與“今生”
日志,學術性的說法是時間序列機器數據,因為它是帶時間戳的機器數據,由網絡設備、服務器產生,并包含IT系統很多信息,其中涉及服務器、網絡設備、操作系統、應用軟件,甚至包括用戶、業務的信息。日志反映了事實數據,不管是數據中心還是企業發生的一切都會被記錄下來。通過統計分析日志,不同系統之間的通信也可以通過日志傳遞信息。
日志呈現非結構化特征,如果要進行分析就要轉化為結構化,一條日志包含的信息非常多,從統計分析的角度就會得出更多有價值的信息。日志可以用到哪些場景?首先是運維監控,保證系統的可用性,如果出現故障,能夠及時地追溯根源并及時知道問題。
其次是應用性能監控,主要是得知性能的情況,例如網站的運轉速度,緩慢的原因等,這些均屬于應用性能監控。數據中心還有一條很重要的原則就是安全,要保證數據中心的安全,防止黑客的入侵。這可以用在安全審計方面,主要是安全信息事件管理、合規審計、發現高級持續威脅APT等。
日志如此重要,包含了那么多重要信息,以前怎么處理日志值得探討。過去中小型公司不太重視日志,大型的企業正開始重視日志。企業日志沒有集中管理,散落在各臺服務器上,出了問題就登錄到各臺服務器上用腳本命令、用VI去查看日志,其中不乏一些水平高的運維工程師用AWK寫一些腳本分析程序去分析日志,但是這樣的做法也有問題。因為登錄到各臺服務器,這些服務器都是生產服務器,一不小心的錯誤操作可能會導致事故。
另外有的運維工程師把日志當做垃圾,看到磁盤空間達到極限,首先做的事情就是刪除日志,刪除日志后如果發現有些故障需要分析又找不到日志。后來業界開始重視日志,他們用數據庫存儲日志,這也是如今一個比較普遍的做法。原則上講,數據庫是用來存結構化數據的,日志是非結構化的數據,數據庫有固定的Schema,為了讓表的格式最大限度的靈活化,數據庫就定義了三列,其中第一列是產生日志的機器IT地址,第二列是時間戳,第三列是日志本身的信息,把整個日志的文本當做一個字段放到數據庫中,并沒有針對日志中的信息進行抽取進行分析。現在產生的日志越來越多,每臺服務器一天產生幾GB甚至幾十GB的數據,一個數據中心上千臺服務器一天可能產生幾TB的數據,數據庫沒辦法適用TB級的海量日志。
如今,Hadoop出現后業界開始用Hadoop處理日志。首先Hadoop是批處理的框架,不夠及時。用Hadoop處理分析都是今天看昨天的數據,或者是看幾個小時之前的,最快也只能看到幾十分鐘之前的。要想看幾秒鐘之前的,Hadoop是做不到的。Hadoop的查詢,雖然有Hef(音)這樣的東西來做查詢,但Hef的查詢也非常慢,所以Hadoop基本是用來做數據的離線挖掘,沒辦法做在線數據分析。后來又開始出現了Storm、Spark,但這些都是使用框架,后來出現NoSQL,但沒辦法全文檢索。可見在海量日志的處理方面還有很多可挖掘與突破的地方。
隨著互聯網的飛速發展以及Web日志數據的爆炸式增長,海量日志數據的處理越來越受到人們的關注。對這些海量日志的數據挖掘,可以從中分析用戶的行為特征,獲取用戶屬性,也可以發現用戶訪問網站頁面的模型與訪問習慣,為網站管理員優化網站頁面設計提供有效依據,但這只是未來發展方向之一。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
