數據挖掘在學生專業成績預測上的應用
2016-03-08 18:24:25崔仁桀
軟件 2016年1期
關鍵詞:數據挖掘
崔仁桀

摘要:學生特征的提取以及學習效果預測一直是教育數據挖掘領域的熱門課題。本文將結合國內高校教育現狀和現有的教育數據挖掘成果,以weka作為實驗平臺,應用C4.5算法對本科生的專業培養數據做建模分析以及成績預測,通過采集到的實際數據做實驗驗證,找到潛在于成績信息之中的學生行為規律,為提前干預學生學習行為,優化教育決策做出有意義的指引。
關鍵詞:計算機應用;數據挖掘;weka;學生成績預測
中圖分類號:TP391
文獻標識碼:A
DOI: 10.3969/j.issn.1003-6970.2016.01.007
0 引言
教育數據挖掘領域從2009年興起至今已經得到了飛速的發展。EDM社區對教育數據挖掘做了如下定義:教育數據挖掘是一個新興學科,致力于探索特定(來自于教育環境)數據的先進方法,并使用這些方法來更好的了解學生,并將其應用到他們的學習環境中。在高校的校園信息化建設已經日臻成熟的大趨勢下,高校教務信息管理系統里積存了大量教務數據,教育數據挖掘領域根植的環境已經具備,本文將以此為背景,利用課程成績對學生的專業學習行為進行建模,并對其未來的學習成果做出預測。研究過程中將基于weka實驗平臺,應用經典的C4.5決策樹算法作為模型建立方法展開研究和實驗。
本文的組織結構如下。第一章闡述研究主題內容的定義和算法原理簡述;第二章從數據預處理,算法應用和模型評估三個方面來分析機器學習方案的創建過程;第三章以實際數據為例執行建模實驗,分析和討論實驗結果,得出實驗結論。第四章對全文的研究作總結,并對未來的研究做出展望。
1 研究背景與算法簡述
1.1 研究背景討論
關于學生表現的預測,有很多專家和學者做出了嘗試和貢獻。M.Vranic,D.Pintar and Z.Skocir通過應用聚類、關聯分析和探索性數據分析等多重手段,分析了如何用本科生的生源情況,高考成績,以及大一的重點課程“電子工程基礎”的課堂表現情況預測出學生在這門課程的最終表現;Judith Zimmermann等學者從蘇黎世聯邦理工大學的一個專門制定的研究生推免計劃中獲得學生本科生和研究生成績信息,以GGPA代表學生研究生的評定等級,應用多種預測和統計手段進行基于模型的成績預測研究,分析如何用本科成績單上得到的數據來預測GGPA,來推斷其在研究生期間的表現。
然而對于這些跨越了學歷階段之間的預測分析并不適用于國內的教育體制,兩個問題:1.首先以GGPA評定整個學歷的學習行為未免過于粗糙,我們難以察覺出學生的具體特征;2.對于特定課程的預測需要用與之相關的解釋變量做模型訓練才更有意義,然而如果學習階段相差過大,學習內容和環境都有很大差別,這樣極大弱化了自變量和目的變量之間的相關性,使得預測結果的說服力大大降低。
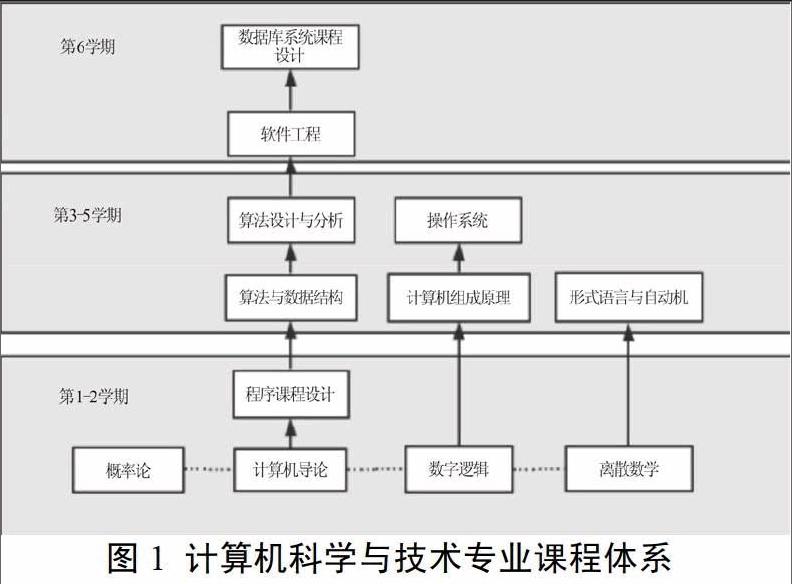
為了克服這兩點矛盾因素,我們將預測素材和預測目標都鎖定在本科教育階段。圖1列出了目前主流的計算機科學與技術專業的培養課程體系的主要內容。方案的主要思想是將重要的基礎課程放在大一大二兩個學年,將較為高階和關鍵的專業課放在大三學年,大四學年供學生根據自己意愿自由選擇更偏向于社會應用課程以及畢業設計。以此為指導,我們選用課程體系中的學科基礎課,專業基礎課作為解釋變量,來預測與之相關的高階專業課的學習成績,以達到加深對于學生學習行為的理解,和提前對學生學習進行干預,幫助其更好的完成專業培養的目的。
1.2 C4.5決策樹算法原理簡述
決策樹是一種預測模型,它以決策節點、分支和葉節點的構造形式表示,將實例通過屬性值逐步判別為某個類別標簽上。我們需要用訓練數據集來做決策樹模型訓練,然后將得到的樹形結構進行保存并應用到測試數據和實際數據中。
本文將使用最為先進的C4.5決策樹算法,它基于從上到下的遞歸分治策略,選擇信息熵增益最大的屬性作為樹的根節點,為每一個可能的屬性值創建分支,這樣將實例分成多個子集。算法將遞歸地執行這一步驟直到所有子節點的所有實例都屬于同一類別,也就是葉節點的產生。不過要將決策樹算法應用到成績預測問題的最關鍵部分在于我們要調整我們的數據集。決策樹算法需要應用在擁有名稱性類別屬性的數據集上,我們需要將我們的目標課程成績離散化后才能使用算法,具體的離散方法會在第2.1節講到。在weka中C4.5的實現是J48算法,我們可以通過調節api提供的多種參數來改變決策樹的生成和修剪過程,使得預測模型規模更加符合我們的預期,而且也往往伴隨著預測效果的提升。
2 決策樹預測方案的設計
2.1 數據預處理
為了構建預測模型,我們需要將多門課程的成績數據合并到同一數據集下,并指定數據的目標類別屬性(預測的專業課程)。為了將數據構建成分類模型,我們需要將預測的專業課程成績離散化,把數值型屬性轉換成名詞型屬性。成績的離散化可以通過表1的方式進行轉化。
由于數據收集來源和渠道的多樣化,在數據預處理階段不可避免的遇到缺失值的處理問題。在實際教育場景中,成績缺失的主要原因分為兩種:
(1)學生缺考或者申請緩考,這兩種成績缺失是由于多種客觀因素造成的,然而一般都會有相應的補考數據存在。為了正確判斷學生的學習表現,我們應該用對應的補考成績替換缺考的缺失值。如果實在找不到可替代的值,將其置為0或者“未通過”。
(2)學生流失,原因包括輟學或者轉專業等。事實證明,高校專業范圍內每級的學生流失率平均要達到3%到7%左右,這部分學生未能完成全部專業培養計劃,所以他們的數據對于構建學生成績預測模型沒有意義,應該被過濾掉。
另外對于多次補考、重考的數據實例,我們選擇“采用第一次有效成績作為屬性值”的原則,這樣可以避免補考出現的較高成績影響我們對于學生實際學習行為的判斷,同時避免了因特殊原因缺考而出現的0分成績對于學生學習成果造成的過低估計。
2.2 剪枝優化與模型建立
本文的1.2節已簡述了C4.5算法的工作原理,將其應用到我們準備好的數據集上就可以得到決策樹模型。然而樹模型在C4.5算法的訓練之后完全展開通常會包含著很多不必要的結構,使得樹模型的非常的龐大和繁瑣。所以在應用決策樹模型之前最好要進行剪枝優化。剪枝根據策略不同分為先剪枝和后剪枝兩類。C4.5算法采用的是后剪枝策略,即在得到決策樹模型以后再反向對其修改其結構,改變或提升其子樹的位置,使得模型的可信度更高。Weka中為J48算法提供了信心因數(confidenceFactor)參數。通過對信心因數的調整,算法會將具有更高可信度的子樹進行提升,從而調整整個樹形結構。
2.3 模型評估
對于應用于分類問題的模型,需要通過準確率來衡量分類器的性能。模型的建立和評估往往是一體的,算法需要在訓練數據集中應用,訓練出應用模型,然后再將模型應用到測試集中得到評估結果。測試集和訓練集必須保持獨立性,才能得到真實可靠的誤差率,有效的判斷出模型是否存在過度擬合等問題。
一種非常有效的評估方式是交叉驗證法,它不是簡單的將數據集分割成訓練集和測試集,而是對整體數據集分割成多等份,每次選用其中一份作為測試集,其余數據作為訓練集。將每一次訓練出的模型進行測試并得到結果,然后將得的預測精度取出均值和方差,得到最準確的評估反饋。最后,將算法應用于整體數據集訓練出最終的模型結果。本文采用的是十折交叉驗證算法作為模型的評估手段,即將數據集平均分成十份,完成十一次建模過程來得出最終的模型及其性能數據。
3 實驗驗證與結果分析
本次研究中我們用收集到的了某高校計算機科學專業的整級學生的專業課數據信息,包括其培養計劃內的專業基礎課和高階專業課中的“數據庫系統課程設計”共12門課程的等級成績,通過預處理篩選無效實例后,最后得到424個數據實例。本章通過應用第二章闡述的方案設計流程,以高階專業課的等級作為預測的目標類別屬性,完成學生成績預測模型的創建,并從模型結果中提取出規則結論。
3.1 可視化分析與分類基線精準度
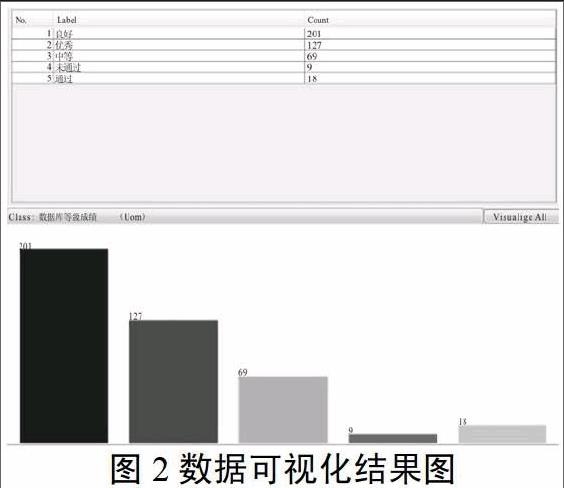
圖2展示了離散化以后weka的數據可視化結果,從圖中可以看到類別屬性“數據庫系統課程設計”的等級成績的每個屬性值的分布情況。
另外,在評估模型性能之前按需要一個基準線來對數據的可預測性做大致考量。OneR算法是一個非常簡單有效的分類算法,它會尋找出數據集中對于目標預測的貢獻值最突出的屬性作為唯一的分類依據。本例中OneR選擇了計算機導論的成績,得出本數據集的分類基準線在40.7%。
3.2 決策樹模型分析
我們將數據載入weka平臺,并調用J48算法對其進行建模。并不斷調整minNumObj參數以獲得最佳的樹形結構,最終結果如圖3所示。
交叉驗證的結果顯示決策樹模型的預測性能為83%,明顯高于基線精準度。從圖中可以看出,模型以“計算機導論”作為模型根節點,可見其是信息熵增益最強的屬性,其次是數據結構,算法設計與分析和離散數學等。因此在眾多基礎課程中,“計算機導論”與“數據結構”對于預測目標課程“數據庫系統課程設計”的成績的貢獻度最大,對于預測結果較差的學生應著重增強對這兩門成績的補習。
從圖4所示的混淆矩陣中我們注意到,決策樹模型對于成績較低的“未通過”與“通過”兩個類別的判斷比較準確,這意味著這個模型可以較好的預測出有掛科傾向的學生,模型可以幫助我們有效的避免學生掛科,及時進行有針對性的補習,有很高的實用價值。
我們可以根據這些屬性之間的相對關系來判斷學生未來的學習趨勢,進行提前干預和矯正,讓其在專業學習上取得更好的成就。這些規律都會對矯正學生學習行為,輔助教育決策的優化起到很好的輔助作用。
4 結論與展望
4.1 結論
本文結合教育環境中的成績數據特點,應用經典的C4.5決策樹算法為本科生的專業學習表現構建了完整的預測模型方案,包括將數據進行必要的與處理工作來適應建模算法的要求,對決策樹模型的剪枝優化,以及最后用十折交叉驗證方法對模型性能的評估等。
此外,本文對采集到的某高校計算機科學技術專業424個實例構成的數據集的進行了分類建模分析,以“數據庫系統課程設計”的成績預測為例,完成了整個數據建模流程,得出了能夠有效識別學生學習行為并預測學生未來成績的決策樹模型,并從中推導出了一些有價值的規則。
4.2 展望
本次研究有很多環節可以做更多補充和完善。首先對于學生特征來講除了課程成績以外,任課教師和出勤率等因素也可能導致對學習造成較大影響。然而由于本次研究所采集的數據數量集較小,無法很好地反映出這種變化幅度較輕的因素帶來的影響。在將來的研究中我們可以擴大研究對象范圍,擴展更多屬性作為分析因子,得出更加全面的結論。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
