一種基于Kafka的可靠的Consumer的設計方案
2016-03-08 18:40:29王巖王純
軟件 2016年1期
王巖++王純

摘要:伴隨著互聯網和移動互聯網的發展,各種新興應用層出不窮,對大數據處理的實時性和高并發能力要求也在不斷提高。Apache Kafka,作為一種分布式的消息系統,具有可水平擴展和高吞吐率而被廣泛的使用。對于數據業務的基礎支撐系統,除了能夠滿足高并發度和實時性以外,數據的質量即數據可靠性也是關鍵的一環。但是,由Kafka原生提供的數據消費者不能夠保障數據的可靠性。本文首先簡單介紹了Kafka的組成、架構特性等技術背景,然后闡述了原生Consumer的原理和缺陷;最后,基于Kafka提出一個可靠的消費者的設計方案。本方案是基于Kafka的low-level的接口集,解決了Kafka原生Consumer由于將用戶消費數據的動作與數據消費位置的記錄獨立而引起的數據質量問題,保障了數據的可靠性。最后,搭建Kafka集群測試環境,驗證了方案的可行性和正確性。
關鍵詞:Kafka;數據可靠性;zookeeper;實時
中圖分類號:TP311.5
文獻標識碼:B
DOI: 10.3969/j.issn.1003-6970.2016.01.015
0 引言
隨著互聯網行業的不斷發展,各種業務的數據量不斷增多,在大數據處理環境下,對數據的實時性要求不斷提高。筆者原有的技術環境采用ftp技術作為數據傳輸手段和傳統關系型數據庫和文件系統作為存儲介質,效率較低,無法滿足客戶對數據實時性的要求。Apache KafkaⅢ,作為一種分布式的消息系統,具有可水平擴展、高吞吐率和實時性而被廣泛的使用。筆者為迎合項目的需求采用Kaika作為數據訂閱和發布系統,完成數據的傳輸和緩存功能。最初,由于初學Katka采用Kafka原生提供的High Level的Api,編寫數據生產者和消費者。隨著使用的深入和業務數據量的增大,發現數據質量不能得到保障,雖然偏差不大,但是對于某些敏感數據,對于數據質量要求十分嚴苛。
對于數據業務的基礎支撐系統,除了能夠滿足高并發度和實時性以外,數據的質量,也即數據可靠性也是關鍵的一環。本文的研究目的在于基于Kafka的底層Api給出一種具有數據可靠性的數據消費者(Consumer)的設計方案。
1 技術背景簡介
1.1 名詞介紹
主題(topic)是Kafka用于區分所發布消息的類別或是名,即一個主題包含一類消息。
分區(partitions)是Kafka為于每一個主題維護了若干個隊列,稱為分區。
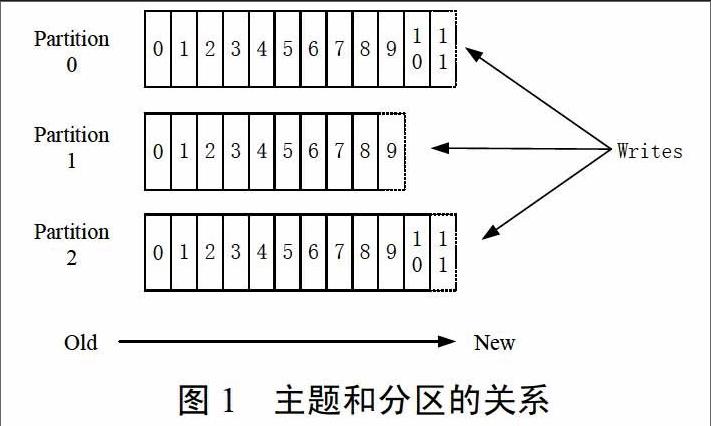
假設有一個擁有3個分區的主題,其中主題(topic)和分區關系如下圖,
Kafka中每個主題的每一個分區是一個有序寫入、不可變的消息序列,一個topic下可以擁有多個分區。
消息偏移量(offset)是Kafka賦予每個分區(partition)內的每條消息一個唯一的遞增的序列號,稱為消息偏移量(offset)。
生產者(producer)是根據對于主題的選擇向Kafka的發布消息,即向broker push消息的一系列進程。生產者負責決定某一條消息該被被發往選定主題(topic)的哪一個分區(partition)。
消費者(consumer)是向主題注冊,并且接收發布到這些主題的消息,即消費一類消息的進程或集群。
代理(broker)是組成Kafka集群的單元。Kafka以一個擁有一臺或多臺服務器的分布式集群形式運行著,每一臺服務器稱為broker。
副本(replications)即分區的備份,以便容錯,分布在其他broker上,每個broker上只能有這個分區的0到1個副本,即最多只能有一個。
消費者群組(Consumer Group)是有若干個消費者組成的集體。每個Consumer屬于一個特定的Consumer Group。Kafka采用將Consumer分組的方式實現一個主題(Topic)的消息的廣播(發給所有的Consumer)和單播(發給某一個Consumer)。
1.2 Kafka的基本架構
Kafka是一個分布式的消息訂閱和發布的系統。消息的發布者稱作producer,將消息的訂閱者稱consumer.將中間的存儲陣列稱作broker。
圖2極為簡要的描述了一個消息訂閱和發布系統,所必須具備的角色和工作機制。生產者(producer)將數據生產出來,推送給代理者(broker)進行存儲,消費者需要消費數據了,就從broker中拉取數據來,然后完成一系列對數據的處理。
圖3展示了Kafka作為消息訂閱和發布系統的典型系統架構模型。多個代理者(broker)協同合作,組成了Kafka集群。Kafka的集群架構采用P2P (peerto peer)模式。集群中沒有主節點,所有節點都平等作為消息的處理節點。優點是沒有單點問題,一部分節點宕機,服務仍能夠正常,缺點是很難達成數據的一致性和多機備份,如果一部分節點宕機會導致數據的丟失。
Kafka為避免上述的問題采用主節點選舉機制,利用zookeeper,對于每一個主題(topic)的分區(partitions),選出一個leader-broker(主節點),其余broker為followers(從節點),leader處理消息的寫入和備份;當leader宕機,采用選舉算法,從followers中選出新的leader,以保障服務的可用,同時保障了消息的備份和一致性。
生產者(producer)和消費者(consumer)部署在各個業務邏輯中被頻繁的調用,三者通過zookeeper管理協調請求和轉發。這樣一個高性能的分布式消息發布與訂閱系統就完成了。producer到broker的過程是push,也就是有數據就推送到broker,而consumer到broker的過程是pull,是通過consumer主動去拉取數據的,而不是broker把數據主動發送到consumer端的。
2 原生Kafka-Consumer的原理和缺陷
2.1 設計原理
圖4就是Kafka原生的Consumer的架構的簡要圖示。zkConnector提供一些關于與zookeeper交互操作的API;FetchDataChunk只要是提供獲取主題數據的API;ConsumerConnector即實現kakfa-Consumer的主體部分,即用戶API的接口類,提供Consumer鏈接和主題(topic)數據訪問的接口。
Kafka中的offset用于描述消息在一個分區中的位置偏移量,依從一個分區內的消息的達到順序遞增;同時,Kafka的Consumer利用消息的offset來記錄在一個topic中每個分區中的消費的水位線。在kakfa-Consumer中, 對于offset的處理是在ConsumerConnect建立連接的同時,開啟一個定時器,每隔一定時間(用戶可配置),就將現在用戶consumer的在每個分區的offset記錄到zookeeper中;因此,每次consumer啟動的時候都會先從zookeeper中讀取記錄其中的offset,作為這次消費的起始點。
以上,就是Kafka原生的Consumer的基本設計原理,下面我們闡述一下他的缺陷,以及會造成的問題。
2.2 非可靠性的缺陷
由上述kakfa-Consumer的設計原理,標記Consumer消費水位的offset的記錄是跟用戶對數據消費和處理是分離的。考慮如下場景,例如用戶的Consumer程序由于種種原因(程序異常、主機宕機、JVM異常、錯誤操作等)異常退出,此時用戶Consumer在異常退出前消費的數據,就很有可能恰好處于ConsumerConnect中記錄offset的定時器的運行周期,使得退出是丟失的數據的offset被記錄到了zookeepero這樣,當應用重新啟動,向zookeeper同步offset的時候,就會拿到錯誤的偏移量,導致數據的丟失,使得數據不可靠。
2.3 本文設計方案的創新性
本文由于生產業務對數據質量的需求,摒棄了Kafka提供的不可靠的High-Ievel接口集,而采用Kafka內部底層的low-level的接口集,即只使用Kakfa獲取數據的接口,不使用原生的的對于offset的維護服務。本文的設計方案重新封裝了kafka的消息結構,并且利用zookeeper自行構造了保存offset的結構和方式,定義了用戶獲取數據的接口以及用戶提交offset的接口,使得用戶的數據消費行為與offset提交的行為朕動起來,保障了數據的可靠性。具體方案的設計原理會在下面章節詳細闡述。
3 可靠的Consumer設計
3.1 可靠性的定義和條件
3.1.1 Consumer可靠性和本文的選型
對于Consumer的讀取數據的可靠性有如下三種可達標準:
l.At most once消息可能會丟,但絕不會重復傳輸
2.At least one消息絕不會丟,但可能會重復傳輸
3.Exactly once每條消息肯定會被傳輸一次且僅傳輸一次
對于Kafka的原生Consumer,實現的Consumer屬于第一種可靠性。在Kafka中是通過對于offset的保持,來控制數據的消費位置,即數據消費水位線。在Kafka的原生Consumer對于數據消費和數據水位線(offset)的保持是分離的。即在系統出現異常退出的時候,如果Consumer已經將數據消費,但是并未提交offset,當系統恢復重啟時,同步上次記錄的水位線時,就回讀取到較早提交的offset,就會造成數據的重復消費;如果Consumer還未來得及消費數據,但是offset已經提交,在下次系統恢復重啟,就回讀取到錯誤的水位線,導致一部分數據無法被消費而丟失。
這種模式下,即Consumer的數據消費與offset的不同步,造成系統故障后可能丟失數據也可能重復讀取數據,這就對應于At most once的可靠性。
本文要是現實的就是第二種可靠性,即At leastonce。將Consumer的數據消費與offset的提交同步起來,即Consumer在讀完消息先處理再commit。這種模式下,如果在處理完消息之后commit之前Consumer宕機了,下次重新開始工作時還會處理剛剛未commit的消息,實際上該消息已經被處理過了。這就對應于At least once。
由上面的描述,我們看出這種Consumer讀取的可靠性,有可能會導致讀取后的數據有重復的情況,這種情況很好解決。由于,在很多使用場景下,消息都有一個主鍵,所以消息的處理往往具有冪等性,即多次處理這一條消息跟只處理一次是等效的,那就可以認為是Exactly once;如果數據中沒有主鍵,我們也可以人為的在producer端對每一條數據加入一個唯一的ID作為主見,而后在Consumer后端的業務端進行去重,就能夠實現Exactly once。
如果一定要做到Exactly once,就需要協調offset和實際操作的輸出。經調研發現一般的做法有兩個:
1、引入兩階段提交。由于,許多輸出系統可能不支持兩階段提交,這種做法通用性很差,而且引入兩階段提交,這種類似同步的做法,會降低系統通用消息消費的性能,使吞吐大打折扣;
2、如果能讓offset和操作輸入存在同一個地方,會更簡潔和通用。這種方式可能更好。比如,Consumer拿到數據后可能把數據放到HDFS,如果把最新的offset和數據一起寫到HDFS,那就可以保證數據的輸出和offset的更新要么都完成,要么都不完成,間接實現Exactly once。但是這種做法,也限制了Consumer端的輸出形式,并將業務和接口耦合在一起,是系統具有很差的擴展性。
因此,綜合考慮了系統的性能和可擴展性,以及通過后端數據再處理達到Exactly once可靠性的可實現性,本文選擇了實現能夠保障At least once可靠性的Consumer。
3.1.2 本文的可靠性設計的外部依賴條件
本文只設計并實現一個可靠的kakfa-consumer,只關注Consumer從broker拉取數據到處理完成數據輸出到業務層這段的數據可靠性,這就需要一些外部條件的保障:
1、假設producer是可靠的,即不會丟失數據,能夠建數據源的數據不丟失的推送到broker;
2、假設broker是可靠的,不會有丟失數據;不會有超過replication數目的broker不能夠提供服務;
3、假設zookeeper是可靠的,能夠保障服務的提供以及數據的一致性。
3.2 Zookeeper技術
Zookeeper分布式服務框架是Apache Hadoop的一個子項目,它主要是用來解決分布式應用中經常遇到的一些數據管理問題,如:統一命名服務、狀態同步服務、集群管理、分布式應用配置項的管理等。Zookeeper的典型的應用場景:配置文件的管理、集群管理、同步鎖、Leader選舉、隊列管理等。
本文使用Zookeeper開源工具,保持offset數據,利用zookeeper的數據一致性的特性,來保障offset的數據可靠性。
3.3 設計詳述
3.3.1 Consumer的模塊設計
本文的Consumer設計如圖5所示
ZKTools模塊,主要負責與zookeeper相關的交互操作,提供與Zookeeper進行讀寫操作的相關操作的API;
ConsumerClient是主體模塊,主要負責針對主體的每個分區的數據讀取和可靠性維護的操作;
BatchMessage是對Kafka的原生的消息結構進行封裝,加入了該消息的offset和讀取該消息所在分區的ConsumerClient類的對象,為數據可靠性的實現提供支持,豐富了原生的Message結構的功能;
ClientEngine是整個kafka-consumer的對用戶的接口模塊;提供了設置c onsumer鏈接,獲取數據讀取入口的API。
3.3.2 Consumer的詳細設計
圖6是kafka-consuemr的詳細設計的類圖,具體闡述了每一個模塊在代碼層面完成的功能:
ZkTools是一個單件類,提供與zookeeper相關的操作:
_init_ (confMap):構造函數,參數是用戶配置,配置主要包括zookeeper的ip和端口、要消費的主題名稱、consumer的群組名稱。構造函數完成,與zookeeper的鏈接、初始化一些類變量。
setData (zkPath,offset):設置zkPath指定的zookeeper中的文件的內容
getData (zkPath):獲取zkPath指定的zookeeper中的文件內容
createPath (zkPath):創建zkPath指定的目錄
checkExist (zkPath):判斷zkPath是否存在
getPartitions (topic):獲取主題的所有分區編號的列表。
BatchMessage是原生Message的擴展類,提供一些系列get和set方法,是用戶完成消費動作的入口:
getThisOffset():獲取該消息的起始offset
setThisOffset():設置該條消息的offset
setConsumerClient 0:設置ConsumerClient對象,當該條消息,被用戶讀取并執行完處理邏輯,可以利用該對象,調用fnish()方法,完成對該消息的消費,從而提交該消息的偏移位置,只是保障消息不丟失,達到可靠性重要的一環,即用戶每當對一條消息完成用戶邏輯的時候就調用frnish (),這樣使得數據消費的偏移量和用戶處理邏輯能夠協同工作,保證數據的可靠性;
getsumerClient():獲取ConsumerClinet對象
ConsumerClient是整個kafka-Consumer的核心,完成主要的功能,ConsumerClient類,是Runable類的實現類,實現run()方法,是一個線程類,每個線程針對主題的某一個分區進行處理:
_init_():構造函數,獲取用戶配置confMap、處理的分區編號partld_存放消息的共享隊列bq。構造函數完成一系列的初始化工作:
1、與zookeeper建立連接
2、根據主題名稱、和分區編號獲取該主題的leader-broker的ip和port
3、根據主題名稱、分區編號、groupld獲取當前最新的消費offset作為起始offset
4、初始化各種數據結構
5、建立用于周期性提交offset的Timer
CommitOffset():是Timer定時器的定時調用函數,周期性向zookeeper提交offSet。
利用offset的存儲結構和提交策略保障可靠性
在ConsumerClient類中有一個排序的數據結構,對象名稱叫msgWait,是一個存放offset的有序列表。
另外,與msgWait,相關的是fnish()函數,功能為從msgWait中刪除最小的的offset,而由于msgWait本身有序,即刪除第一個元素。
run()方法根據初始化的leader-broker的ip和port,利用Kafak底層Api向broker拉取數據(Message),并將數據、當前ConsumerClient對象、該數據的起始offset,也即消費的curOffSet(當前offset)構造為BatchMessage對象,裝填到共享消息隊列bq里面;然后將curOffSet追加到msgWait中。
用戶讀取共享隊列中消息并執行完處理邏輯,調用fnish()方法,將該消息的起始offset從msgWait中刪除。
CommitOffset()方法,是從msgWait中取出最小的offset.并將其提交到zookeeper()。也即如果用戶沒有處理完該消息,就不會調用finish()方法,那么CommitOffset就一直在提交上一條已經消費完成的消息的偏移量;當用戶消費完成后,調用了finish方法,將該條消息的起始位置的offset從msgWait中刪除,那么msgWait中最小的offset就是該消息的偏移量位置,就會在下一個周期被提交。本文的方案就是利用一個offset有序的結構和finish的方法,將用戶的處理邏輯和Consumer對于offset的提交,聯系到了一起,確保只有當用戶處理完成數據后,才會提交消息的offset,從而保障數據的可靠性。
getLeader():獲取該分區的le ader-broker的的ip和port。
getLeaderAfterElection():前文提過, 當leader-broker異常時,kafka會采用某種選舉方式,重新選舉leader-broker,但是這個過程不是原子的,會產生獲取數據失敗的情況,該函數就是在獲取數據失敗的情況下,重新獲取選舉后的leader-broker。
getLastestOffset():獲取該分區最新的offset。
ClientEngine是kafka-consumer提供給用戶的入口類,主要完成ConsumerClient現成的啟動,提供消費數據接口:
init():構造函數,獲取用戶配置、初始化共享消息隊列bq、向zookeeper獲取主題的分區編號的列表:
Start():根據分區列表,啟動ConsumerClient線程
getConsumerlterator():返回共享消息隊列的迭代器,作為用戶消費數據的入口。
4 方案驗證
4.1 測試環境
測試環境采用實驗室的pc機進行測試。機器配置如表1所示,
測試主機有三臺,組成kaika和zookeeper的測試集群,三臺主機網絡配置信息如下,
4.2 測試用例和結果
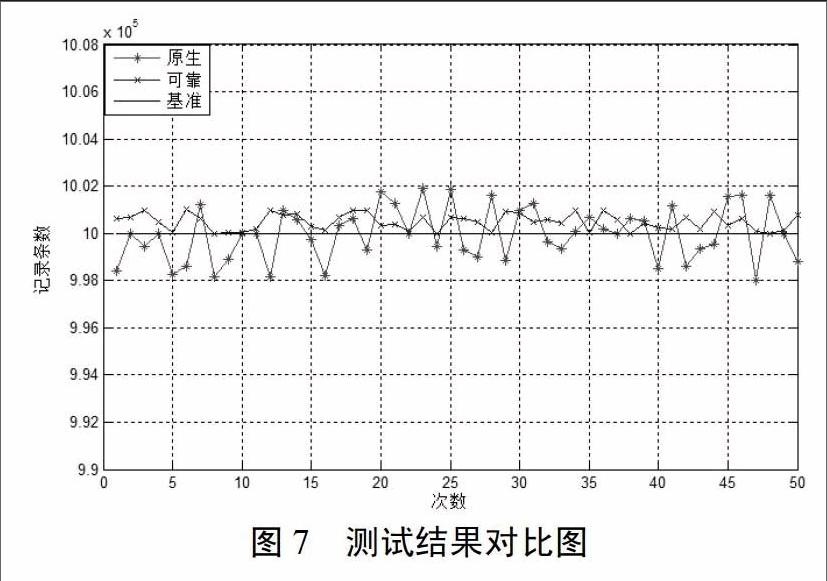
由于篇幅有限,上表實例性的展示了10次測試的對比結果,為了清晰的對比展現測試結果,見如下對比圖,圖7中,紅線代表原生Consumer在測試用例下的結果數據,藍線代表本文設計方案下的Consumer的結果數據,黑線代表著原始數據的記錄條數。由圖我們可以清楚的看出,原生Consumer無法保證數據的可靠性,時而多數據,時而缺失數據;而本文實現的可保證At least once可靠性的Consumer的線圖一直在黑線之上,表明本文的設計方案下數據在系統意外宕機時不會缺失,能夠保障At least once的可靠性,從而證明了本文設計方案的可行性和正確性。
5 結論
隨著互聯網的飛速發展,新的業務對數據處理的實時性、高并發、高吞吐的要求在不斷的提高。然而,數據的可靠性也是十分重要的一環。本文基于Kafka分布式消息隊列,提出了一種可靠的Consumer的設計方案,保障了數據的可靠性,能夠在業務端保證數據冪等的條件下,達到數據不會丟失也不重復的效果。然而,本文實現的Consumer對于可靠性的保障是有局限性的、并且對于主題分區較多的情況效率也會下降。所以,筆者也會不斷的學習,為了使用信息社會的瞬息萬變,需要不斷地變革和創新,才能為社會創造更好的互聯網服務。
