基于Schema的XML混合編碼索引查詢技術
2016-03-17 03:51:34劉林靜樓文高
計算機應用與軟件 2016年2期
夏 剛 劉林靜 樓文高,2
1(上海理工大學光電信息與計算機學院 上海 200093)
2(上海商學院 上海 200235)
?
基于Schema的XML混合編碼索引查詢技術
夏剛1劉林靜1樓文高1,2
1(上海理工大學光電信息與計算機學院上海 200093)
2(上海商學院上海 200235)
摘要Web中存在著越來越多的XML的文檔,如何高效地從XML文檔查詢出有效信息已經成為當前在半結構化數據研究領域中的熱點問題。針對XML文檔節點進行編碼和建立索引結構可以有效地提高查詢速度,提出一種SBXHCI(Schema-Based XML Hybrid Coding Indexing)查詢技術,該方法充分利用Schema信息對XML文檔進行編碼和構建索引。對創建索引所花費的時間和空間,查詢響應的時間進行大量的實驗分析,結果表明SBXHCI方法的編碼機制降低了索引結構在時間和空間的資源消耗,并且在路徑查詢的響應速度有著顯著的提高。
關鍵詞SchemaXML路徑表達式混合編碼索引
QUERY TECHNOLOGY FOR SCHEMA-BASED XML HYBRID CODING INDEX
Xia Gang1Liu Linjing1Lou Wen’gao1,2
1
(School of Optical-Electrical and Computer Engineering,University of Shanghai for Science and Technology,Shanghai 200093,China)2(Shanghai Business School,Shanghai 200235,China)
AbstractThere are more and more XML documents in Web, how to efficiently query the effective information from XML document has become the hot issue in the field of semi-structured data research at present. Aiming at that coding for XML document nodes and the establishment of index structure can improve the query speed effectively, this paper proposes an SBXHCI (schema-based XML hybrid coding index) query technology, it makes full use of Schema information to encode the XML documents and to build index. Then we carry out a great deal of experimental analysis on the index creation time, space and query response time. Results show that the encoding mechanism of SBXHCI method reduces the resource consumption of the index structure in time and space, and the response speed of path query has improved significantly.
KeywordsSchemaXMLPath expressionHybridcodingIndex
0引言
隨著互聯網的迅速發展,可擴展標記語言XML由于其良好的數據格式、豐富的數據表示能力及驗證機制,已經成為Web中數據表示和交換的標準。XML在Web中廣泛應用使得XML文檔的結構變得越來越復雜和數據量越來越大,導航式的遍歷顯然已經不能滿足查詢所需的要求,對XML文檔節點編碼并建立索引可以快速有效地定位出需要訪問的節點[1],提高XML數據訪問的查詢效率。因此對XML數據建立索引是一個必要的手段,也成為了當前XML查詢中研究的熱點問題。
對XML文檔建立索引,就是將具有相同標簽的XML節點劃分在同屬一個索引節點類中[2]。目前,國內外對XML建立索引技術的研究取得了豐富的研究成果。例如,最早提出對XML文檔建立索引的思想來源于文獻[3]提出的基于結構概要的DataGuide索引方法,它的本質是一個確定自動機,能夠根據絕對路徑很好地給出響應查詢,但卻不能提供相對路徑的查詢。文獻[4]提出帶有分支路徑查詢的F&B索引,它可以快速地查詢出帶有分支路徑的查詢,但是F&B在構建索引時消耗的內存資源過大。文獻[5,6]提出的基于元素、屬性和結構的XISS索引,它將一個復雜的路徑表達式分解成若干個簡單路徑,通過對XISS索引的訪問來處理每個簡單路徑的查詢處理得到滿足結構關系的中間結果,最后對這些中間結果依次進行結構連接得到查詢的最終的結果。但該方法對具有N個元素或者屬性組成的路徑查詢表達式,XISS索引需要從XML文檔中訪問N組節點,并且至少需要N-1次結果的結構連接,因此會增加結構連接運算的時間。文獻[7-9]都是基于DTD的XML索引方法DBXI,該方法能夠很好地將DTD的結構信息保存到XML文檔中元素和屬性中,并且能夠快速地訪問到結果集。但該方法對XML文檔使用區間編碼的方法,這種編碼對于分解后的簡單路徑查詢存在著很多不相關的結果和結構連接運算相對復雜,并且對于DTD自身也存在著很多的缺陷性。文獻[10,11]提出了基于Schema的SBXI索引方法,但這些方法中對XML文檔也是使用區間編碼的方法。
為了避免上述方法中存在的缺點,本文提出了一種基于XML Schema混合編碼的索引方法SBXHCI,其優點在于:通過使用Schema,避免了DTD本身的多種缺陷;把Schema中的信息存入相應的XML文檔中,可以快速地去除了不相關節點的訪問,有效地減少結構連接次數,并能確保所有待查詢節點都能被訪問;根據前綴編碼和區間編碼各自的優點,對XML文檔采用混合編碼建立索引結構,這種編碼方法可以快速地查詢出待查詢的節點和加快了結構連接的速度,從而提高查詢效率和準確率。
1XML文檔和模式
1.1XML文檔模型
定義1XML文檔樹:一個XML文檔T可以表示成一顆帶有標簽的有序樹(V,E,Label,Root)。其中V表示文檔中節點的有限集合,V=element∪attribut,element和attribute分別代表文檔中的元素節點和屬性節點;Root是文檔樹T中的根節點Root∈V;E=V×V是文檔中有向邊的集合;Label是文檔中V到V的集合,既文檔樹中每個節點分別指明一個標簽作為節點標識。下面給出了一個關于書架的XML文檔簡略片段,圖1給出了對應的文檔樹的模型,其中橢圓形代表節點,三角形代表屬性,矩形代表文本。
< publisher>China Machine Press

圖1 書架的XML Schema文檔示例
從圖1中可以看出文檔的根節點為bookshelf,它的子節點是由book元素組成,每個book節點都有一個屬性id;節點集合及其邊對應的關系都可以很容易從文檔書中看出。
1.2XML模式
模式定義語言使XML文檔遵循一定規則,可以有效地描述和確定出文檔的特性,從而得到一個良構的XML文檔。它不僅規定了XML文檔中可以使用的元素和元素的數據類型,而且還定義了文檔中元素出現的順序和次數以及其節點的嵌套關系等。目前比較廣泛使用的是DTD和XML Schema模型。
DTD使用一種特殊的語法來表示XML文檔中的元素和屬性,如表示bookshelf元素包含一個或者多個book元素,表示book元素的屬性id是必須且只能出現一次。而Schema使用一種與XML文檔相同的語法來定義XML文檔的元素,如使用
定義2Schema摘要樹:對于一個Schema文檔可以映射成一個文檔摘要樹(V,children)(本文不考慮Schema結構中存在環的情況),其中V表示文檔中標簽生成的節點集合,children表示一個元素映射到子元素上的映射集合。
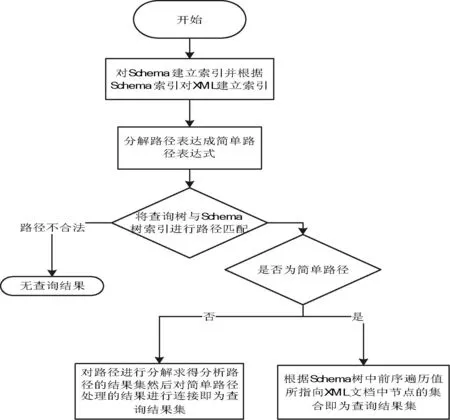
2基于Schema索引的關鍵技術
2.1文檔編碼和索引結構
目前對XML文檔常用的編碼方法有基于區間編碼[12,13]和基于前綴編碼[14]:區間編碼是對XML文檔中的每個節點賦予一對整數值,父節點的編碼區間包含其子節點和后代的編碼區間;前綴編碼是保存了XML文檔節點的路徑信息,任何父節點的編碼都是其子節點和后代節點編碼的前綴。本文充分利用兩種編碼的特點,分別對XML文檔和Schema文檔分別進行編碼。
Schema編碼:把Schema映射成一個摘要樹,節點n的編碼用(Code(n),Level(n),E/A)標識,其中Code(n)表示節點n的前綴編碼,Level(n)表示節點n在摘要樹中的層數,E/A表示節點是元素節點還是屬性節點。
定理1給定一個有效的XML文檔樹T采用區間編碼,則對T中任意兩個節點m和n,若m是n的祖先節點的充分必要條件為Precode(m)·Order(m)是Precode(n)·Order(n)的一個前綴,其中Precode(m)表示節點m的前綴編碼,Oeder(m)表示節點m的順序碼。
通過對Schema編碼采用倒排索引建立一個Schema索引結構,在倒排索引中把關鍵詞存儲在一個索引文件中,使用指針鏈表指向關鍵詞相關的文檔,從而有效的完成倒排索引列表。如圖2所示,本文把具有相同元素/屬性的節點歸并到一個索引中,這樣可以通過在Schema索引中快速的訪問指定元素/屬性節點。

圖2 Schema編碼索引示例
XML編碼:XML文檔采用混合編碼,每個節點的編碼都包含前綴編碼和區間編碼信息。節點n編碼為(Start(n),End(n),S_Code(n))。其中Start(n)和End(n)分別表示節點n的前序遍歷和后續遍歷值,S_Code(n)是節點n所對應的元素或者屬性在Schema文檔樹中具有相同路徑相同位置的節點前綴編碼Code(n),Level(n)表示節點n在XML文檔樹中的層數。因此,XML文檔將Schema的前綴編碼信息存入節點,通過使用S_Code(n)使得每個節點都包含了相應的Schema中的結構信息,這使得在SBXHCI可以直接判斷出無效的路徑表達式中,并且在結構連接運算中提供精確的定位和減少結構連接的次數。
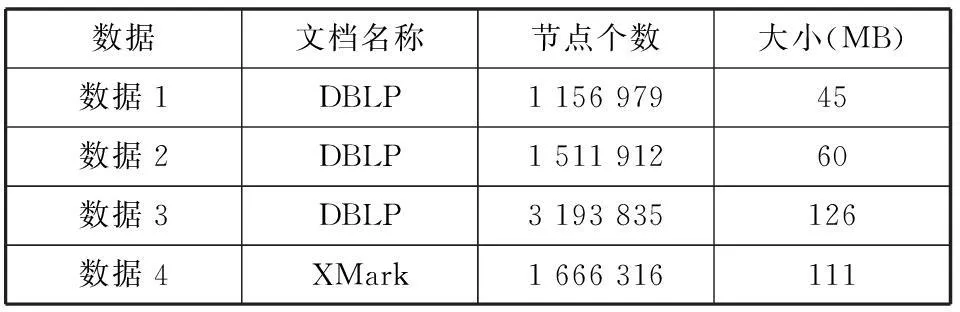
定理2給定一個有效的XML文檔樹T采用區間編碼,則對T中任意兩個節點m和n,若m是n的祖先節點的充分必要條件為Start(m) 根據Schema索引可以建立一個XML文檔索引結構,如圖3所示。首先根據Schema摘要樹先序遍歷的節點建立一個目錄,然后把XML文檔中具有相同前綴編碼的元素歸并到一起,這樣可以快速地定位某個節點的祖先節點,最后根據B+樹將XML文檔中具有相同元素/屬性的節點歸并到一個索引中。從XML編碼可以看出,任意一個節點的前綴編碼都包含了從根節點到該節點的簡單路徑信息。 圖3 XML文檔索引示例 一般實際的應用中,Schema文檔和XML文檔之間是多對多的關系。本文為了方便測試SBXHCI方法的效率,提出的索引技術是基于一個Schema文檔對應一個XML文檔的,因此在實際開發中,我們只需要在schema文檔和XML文檔編碼過程中分別加入Schema_ID(n)和XML_ID(n)即可。 2.2路徑查詢語言 XML查詢語言共同的特點是使用路徑表達式在XML文檔中導航到待查詢節點并返回指定路徑的節點集合,目前最常用的XML查詢語言是XPath。XPath使用路徑表達式來查找XML文檔中的節點、節點集合、原子值等,節點是沿著路徑選取的,它的基本語法為Step1/Step2/…/StepN,其中Step=Axis::Node_test[Predicate*]。軸Axis實際上是指一個方向,即查詢是沿著選著的軸的方向移動,節點測試Node_test是指選著的節點類型或者是節點名,謂詞Predicate對定位步選擇的節點作更進一步的篩選。 一般情況下路徑表達式為復雜路徑,即表達式會存在多個謂詞使得查詢過程中存在多個分支幾點。本文處理復雜路徑的基本思想是路徑分解的方法,即將復雜路徑查詢分解成若干個簡單路徑表達式,對每個簡單路徑查詢的結果集進行連接得到需要查詢的結果集。 2.3算法分析 SBXHCI查詢文檔分為四個步驟:建立索引,路徑分解,與Schema索引匹配,與XML文檔匹配。SBXHCI查詢算法流程圖如圖4所示,具體算下如下: (1) 建立索引。分別對Schema和XML文檔建立索引,具體步驟可參見2.1節中的說明。為了減小索引空間,本文改進了Schema摘要樹中前綴編碼的方法,根據摘要樹層次中最大的兄弟節點個數(記作bNode)來決定編碼的長度1=[log2max(bNode)],既每層的編碼長度,從而減小了Schema編碼中前序編碼的Code(n)的長度。如圖1中第三層節點中最大的兄弟節點為5,則可以用3位來表示每個節點的編號。 圖4 SBXHCI查詢算法流程圖 (2) 路徑分解。在進行路徑表達式查詢過程中將復雜路徑分解為若干個簡單路徑的子查詢,對于分解后含有目標節點的簡單路徑稱為目標匹配路徑,只含有一個謂詞約束的簡單路徑稱為條件匹配路徑。例如一個復雜路徑表達式a/b[c>d]/e/f[g=h]/i,可以分解為條件匹配路徑a/b[c>d],b/e/f[g=h]和目標匹配路徑f/i。 (3) 與Schema索引匹配。對分解后的子查詢在Schema索引中進行有效性的驗證,可以通過定理1來判斷一個簡單路徑是否合法。如果子查詢中存在Schema索引文檔中無相匹配結構的路徑信息,則說明待查詢的路徑表達式不合法,返回無查詢結果。因為Schema中定義了XML文檔遵循的規則,即XML文檔中可以使用的元素和元素的數據類型,而且還定義了文檔中元素出現的順序和次數及其嵌套關系等, 如果在Schema中查詢不到相應的路徑信息,則在相應的XML文檔中也不會存在此路徑表達式的查詢結果集。因為Schema文檔的大小比XML文檔的小的多,所以加快了對無效路徑的查詢效率。如果在Schema索引中有相應匹配的路徑信息,則說明待查詢的路徑是一個合法的表達式。 (4) 與XML文檔匹配可以根據待查詢的路徑表達式的復雜度分為兩種情況: a) 如果查詢路徑為簡單路徑,即查詢路徑為目標路徑,則可以直接根據路徑的目標節點在Schema摘要樹中找到對應的S_Code(n)值,從而在XML文檔的索引中直接獲取到待求的XML節點; b) 如果查詢路徑為復雜路徑,可以將查詢路徑分解為若干個分支路徑集合{bPath}和一個包含目標節點的目標路徑TPath。如果{bPath}包含兩條及兩條以上的路徑集合,首先從{bPaht}依次取出兩條路徑找出葉子節點的前綴編碼S_Code(i),并找出對應的Schema摘要樹中的相同的前綴編碼Code(i),使用“與”操作計算出相鄰路徑中節點的最長的前綴編碼,循環操作{bPath}既可以得到分支路徑結果集bResult;如果{bPath}只包含一條路徑,則直接可以求出bResult。最后使用同樣的方法對bResult和tPath進行連接,得到待求的XML節點。具體算法如下所示: 輸入:分支路徑集合{bPaht},目標路徑tPath 輸出:待求的XML節點集Result if({bPath},length>2){ for each bPathi→bPath{ //獲取bPaht中葉節點對應的前綴編碼Code(i) Code(i)=GetPreCode(bPathi) Code(i+1)=GetPreCode(bPathi+1) //獲取相鄰路徑的最長前綴編碼,Align先根據編 //碼層次獲得其編碼長度然后使用與操作連接 MaxCode(i)=Align(Cod(i)&Code(i+1)); } //獲取分支路徑結果集bResult } else{ Code(1)=GetPreCode(bPath1); bResult=Code(Code(1)); } Result=Align(bResult&tPath); 3實驗及其分析 為了測試和評估本文提出SBXHCI查詢系統中的混合索引方法性能和查詢效率,本文使用了Java語言實現SBXHCI查詢系統。實驗運行在一臺CPU主頻為2.3 GHz雙核,內存大小為4 GB,操作系統為Windows 7電腦上。實驗采用的數據有兩種:第一種是廣泛應用于XML測試的DBLP數據,它的特點是結構簡單,樹的深度不高;第二種是XML基準數據庫XMark,它包含了復雜的樹形記錄結構。本文實驗中忽略了XML數據中的空格,并且所有的實驗都是經過多次實驗所取得穩定的平均結果值。表1表示兩種不同數據及的特征。 表1 表示兩種不同數據及的特征 根據實驗的可行性和可獲得性,本文選取文獻[6]中的XISS方法、文獻[8]中DBXI方法、文獻[11]中SBXI方法三種具有代表性的方法和本文提出的SBXHCI方法進行分析和比較測試。 3.1構建索引的時間和空間比較 衡量一種索引機制的性能可以從以下三個方面來考察:① 創建索引所花費的時間;② 存儲索引所需的空間;③ 查詢響應消耗的時間。創建索引所花費的時間越短,消耗的存儲空間越少,查詢響應的時間越短,則說明索引的性能越好。圖5分別表示不同方構建索引的時間和空間比較。 從圖5(a)中可以看出,不管是結構相對簡單的DBLP文檔,還是相對復雜的XMark文檔,SBXHCI方法建立索引所需的時間都是最小的。原因是解析Schema與解析XML文檔使用相同的解析器,相對于解析DTD時減小了消耗的時間,加快了索引的構建,因此使用Schema構建索引的方法SBXHCI和SBXI所消耗的時間小于使用DTD構建索引的方法DBXI。 從圖5(b)中可以看出,XISS構建索引消耗的空間最小,原因是XISS在構建索引的過程中只對XML文檔中每個節點賦予一個二元組(pre,post)編碼,并沒有包含模式信息,因此構建索引使用的空間最小;對于結構相對簡單的DBLP文檔,SBXHCI方法建立索引所需空間則比DBXI和SBXI要小,而對于結構相對復雜的XMark文檔,SBXHCI方法建立索引所需空間則比DBXI和SBXI要大,雖然本文優化了前綴編碼標識節點的位數,但在構建索引的過程中比區間編碼使用了更多的存儲空間,因此SBXHCI方法在構建XMark索引過程中比DBXI方法使用了更多的存儲空間。 圖5 不同方法建立索引所需時間和空間消耗對比 3.2查詢響應時間的比較 為了測試文檔索引的查詢響應時間,本文針對表1中數據2-DBLP和數據4-XMark兩種數據集,分別給出了4種具有代表性的路徑表達式查詢語句,如表2所示。其中D1-D5是關于DBLP的查詢表達式,X1-X4是關于XMark的查詢表達式,D1和X1是不包含謂詞的簡單路徑查詢,D2和X2是含有謂詞的簡單路徑查詢,D3和X3是含有謂詞的復雜路徑查詢,D4、D5和X4是錯誤路徑查詢。查詢響應時間實驗結果如圖6所示。 表2 實驗中的查詢路徑表達式 圖6 查詢響應時間 從圖6中可以看出,對于無效路徑的查詢,DBXI、SBXI和SBXHCI三種方法都可以快速的判斷出無查詢結果。在XML文檔建立索引中有效的利用了模式信息,都是先從相應的模式信息中進行匹配,無需查詢XML文檔,可以直接判斷出無效查詢,因此大大降低無效路徑的查詢響應時間。 對于有效路徑的查詢,SBXHCI方法相對于其他三種方法明顯的降低了查詢響應時間。對于XISS查詢具有N個元素組成的路徑查詢時,需要N-1次的結果結構連接,因此查詢響應消耗的時間最大;DBXI和SBXI方法都是采用區間編碼建立索引,在結構連接算法的性能低于采用前綴編碼的索引;而SBXHCI采用混合編碼索引的機制,在結構連接中去除了不相關節點的連接操作,減少了結構連接次數,加快了結構的連接運算,這使得查詢效率得到更進一步的提高,優于其他三種方法。 4結語 本文提出了一種基于Schema混合編碼的索引查詢技術SBXHCI,充分利用Schema信息并將Schema編碼信息引入到XML文檔節點編碼中,對XML文檔綜合利用混合編碼建立索引。這種編碼方法充分利用了區間編碼的可以快速訪問節點的優點和前綴編碼的可以加快結構連接運算的優點,并且在結構連接中去除了不相關節點的連接操作,可以快速地訪問到查詢結果。通過實驗結果表明SBXHCI方法的索引結構在時間和空間方面都有較大的提高,并且可以有效地提高文檔的查詢速度。但目前對XML文檔查詢研究工作還存在眾多的問題,如沒有考慮XML的存在的“參考”屬性,這使得XML文檔對應一個圖形結構而不是一個簡單的樹形結構,從而處理起來更加復雜,這需要在將來的工作中進一步的提高。 參考文獻 [1] 孟小峰,王寧,王小峰.XML查詢優化研究[J].軟件學報,2006,17(10):2069-2086. [2] 季玉梅.一種基于XML模式的XML索引技術[D].北京:北京工業大學,2013. [3] Goldman R,Widom J.DataGuides:Enabling Query Formulation and Optimization in Semistructured Databases[C]//Proceedings of the 23rd International Conference on Very Large Data Bases,1997:436-445. [4] Wang W,Jiang H,Wang H,et al.Efficient processing of XML Paht queries using the disk-based F&B Index[C]//Proceeding of the 31st Interational Conference on Very Large Data Bases,Trondheim,Norwey,2005:145-156. [5] Li Q,Moon B.Indexing and querying XML data for regular path expressions[C]//Proceeding of the 27th International Conference on Very Large Data Bases,Roma,Italy,2001:361-370. [6] 王錦,何先波,賀春林.改進的XISS索引技術的仿真研究[J].計算機科學,2012,39(1):148-151. [7] 路燕,張亮,段起陽,等.一種基于DTD的XML索引方法[J].計算機研究與發展,2005,42(1):30-37. [8] 滿慎江,陳近森,郭希娟,等.面向XML文檔檢索的索引技術[J].小型微型計算機系統,2008,29(1):89-92. [9] Che D,Ling T,Hou W.Holistic boolean-twig pattern matching for efficient XML query processin[J].IEEE Trans on Knowledge and Data Engineering,2012,24(11):2008-2024. [10] 肖芳橋.基于模式的XML索引技術研究[D].濟南:山東大學,2010. [11] 鄒為偉,宋余慶,耿飆,等.基于Schema的XML索引方法研究[J].計算工程,2011,37(6):74-76. [12] 萬常選,劉云生,許升華,等.基于區間編碼的XML索引結構的有效結構連接[J].計算機學報,2005,28(1):113-127. [13] 莊燦偉,馮少榮,林子雨,等.XML動態區間編碼方法[J].軟件學報,2012,23(3):582-593. [14] 萬里勇.基于索引技術的XML查詢優化研究[D].長沙:中南大學,2012. 中圖分類號TP311 文獻標識碼A DOI:10.3969/j.issn.1000-386x.2016.02.008 收稿日期:2014-06-04。上海高校知識平臺“上海商貿服務知識服務中心”建設項目(ZF1226)。夏剛,碩士生,主研領域:軟件工程,數據挖掘,人工智能。劉林靜,碩士生。樓文高,教授。



猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
兒童故事畫報(2019年5期)2019-05-26 14:26:14
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
現代企業(2015年9期)2015-02-28 18:56:50
