自適應過濾預測在連接集中器中的應用研究
2016-03-17 03:51:35張文宇周琪云
計算機應用與軟件 2016年2期
張文宇 周琪云
(江西師范大學計算機信息工程學院 江西 南昌 330022)
?
自適應過濾預測在連接集中器中的應用研究
張文宇周琪云
(江西師范大學計算機信息工程學院江西 南昌 330022)
摘要DB2以線程的方式處理所有事務,利用連接集中器優化線程的資源消耗。針對實際應用中大量連接請求導致的線程資源使用過高問題,建立改進的連接集中器模型,提出并實現在應用服務器上連接集中器的資源預測。通過自適應過濾預測模型構建連接集中器,在保證其高性能的同時,預測代理的資源使用情況,事先分配資源建立代理。測試結果及預測分析表明,改進后的連接集中器有效降低線程的資源消耗,提高事務處理的響應時間,同時保證服務器資源得到合理的分配。
關鍵詞連接集中器時間序列自適應過濾預測數據庫
ON APPLYING ADAPTIVE FILTERING PREDICTION IN CONNECTION CONCENTRATOR
Zhang WenyuZhou Qiyun
(School of Computer and Information Engineering,Jiangxi Normal University,Nanchang 330022,Jiangxi,China)
AbstractDB2 database handles all affairs in the form of threads and uses the connection concentrator to optimise the resources consumption of threads. Aiming at the problem of high thread resources consumption in a large number of connection requests in practical application,we built an improved connection concentrator model,proposed and implemented the prediction of connection concentrator resources on application server. To construct the connection concentrator by adaptive filtering prediction model,the scheme predicts the resource usage of agent while ensuring the high efficiency of connection concentrator,the resources are allocated in advance to establish the agency. Test results and prediction analysis showed that the improved connection concentrator could reduce the resource consumption of thread effectively,improve the response time of the transaction request,and ensure the server resources to be allocated reasonably at the same time.
KeywordsConnection concentratorTime seriesAdaptive filteringPredictionDatabase
0引言
DB2數據庫在銀行、證券等金融行業有著廣泛應用,能夠為客戶提供可靠的數據保障,具有良好的安全性、兼容性和擴展性。更重要的是,DB2數據庫擁有穩定的性能,在數據的并行處理、存儲優化、分布式訪問等方面與其他數據庫相比存在著明顯的優勢。連接集中器是DB2用來優化數據庫連接的一種方法。在DB2中,所有事務都是在線程的上下文中進行處理,那么在高容量環境中線程的資源使用情況便非常值得關注。連接集中器將很多數據庫連接分插到集中的代理進程或線程上,由這些代理處理傳來的任務,以減少大量線程所帶來的資源開銷。連接集中器不同于我們經常提到的連接池,連接集中器與線程的上下文切換相關。基于實際的事務負載,在不要求外部應用程序斷開連接的情況下實現資源重用,決定當事務結束后代理將服務于哪一個應用程序。而連接池與數據庫連接本身相關,需要在外部應用程序斷開連接后讓另一個應用程序重用,決定當連接斷開后代理是否與連接保持在一起。現在,由于應用程序往往會建立較長時間的數據庫連接(幾天甚至幾個月),所以連接池已變得不那么重要,而連接集中器則是必不可少的組件。盡管現有的連接集中器在一定程度上可以降低資源消耗,但在并發量大、實時性強的環境中,代理的資源消耗仍然很高,導致事務處理的響應時間過長。
本文從改進連接集中器出發,提出在連接集中器上實現資源消耗的預測方法。即基于自適應過濾模型構建連接集中器,對代理資源的消耗情況進行事先預測,保證現有資源得到更好的利用。
1連接集中器
1.1連接集中器原理
連接集中器的代理池存放著服務于應用程序請求的代理進程。代理進程能夠重用外部連接,即多個排隊的應用程序可以重復使用一個存在的代理。連接集中器的代理分為邏輯代理和工作代理。邏輯代理對應外部的應用程序連接,工作代理則擁有實際的線程資源,并執行應用程序的事務請求。連接集中器初始化時,代理池內創建少量的代理進程。由于沒有外部連接請求存在,代理池中的代理處于待命狀態,即為空閑代理;當有外部程序連接到數據庫時,空閑代理開始服務這些新建連接而變為協調代理;當事務處理完畢且外部連接斷開后,協調代理將重新返回到空閑代理狀態。分配器是連接集中器的關鍵組件,它將入站的連接或事務請求分配給代理進程,并控制連接到代理進程的多路復用。連接集中器允許多個請求同時連接數據庫,以減少創建連接的內存消耗,同時避免頻繁的刪除和創建代理所帶來的系統開銷[1]。
1.2連接集中器改進
為最大限度減少服務器資源消耗,提高事務處理的響應時間,本文首先對連接集中器進行改進。
建立改進模型如圖1所示。模型設計分為三部分:控制單元、數據緩沖區及隊列通道。其中控制單元包括預測控制器和代理池,由預測控制器完成對代理池的預測、控制和管理;數據緩沖區為高速存儲區域,對外部應用程序的數據進行存儲;隊列通道則連通于控制單元與數據緩沖區,用來完成數據的傳輸。

圖1 改進模型
模型將控制單元的代理池在邏輯上劃分為空閑池和活動池,每個子池與一個信號量關聯,每個信號量的引用計數[2]監控子池中的代理數目。由預測控制器替代原有的分配器,根據外部連接請求數提前預測空閑池中的代理數,并分配相應的系統資源。當有外部連接請求時,預測控制器負責將空閑池內的空閑代理轉移到活動池中并分配給連接請求。請求完畢或連接斷開后,代理將返回到空閑池,代理資源的釋放與否也由預測控制器決定(如圖2所示)。需要說明的是,所有預測活動均在服務器空閑時完成,并不占用繁忙時段的系統資源。

圖2 預測控制器
數據緩沖區利用共享內存臨時存儲應用程序數據,減少數據在代理進程間的拷貝次數,提高運行效率。模型將數據緩沖區劃分一定數量的存儲單元,每個存儲單元記錄一條數據。存儲單元定義空閑(Idle)、寫滿(Full)、讀空(Empty)、寫回(Write-Back)等四種狀態。利用狀態間的轉換實現進程間的同步互斥,進而避免讀寫數據緩沖區產生的沖突。存儲單元的狀態轉換如圖3所示。

圖3 狀態轉換圖
隊列通道完成控制單元與數據緩沖區的交互功能。當數據緩沖區的存儲單元處于“Full”狀態時,將對應存儲單元編號發送給隊列通道,即有連接請求或事務請求到來。控制單元從隊列通道接收編號并分配空閑代理,代理按照指定的存儲單元讀取數據進行事務操作,操作結束后將結果按編號直接寫回相應的存儲單元。
2預測控制器
2.1自適應過濾模型
自適應過濾是建立在歷史時間序列觀測值的基礎上進行最優加權平均的預測方法,能夠自動調整權數,是一種可變系數的預測模型。基本思路是:通過分析時間序列原始數據,計算初始的權數序列,在預測過程中反復迭代調整權數,過濾掉誤差,選擇出最佳的預測權數序列,并利用新的權數序列進行未來的預測活動。
模型的形式化[3]表示如下:設x1,x2,…,xt為某一時間序列,則關于時間序列的預測模型為:
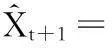
(1)

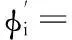
(2)
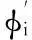
對自適應過濾模型分析后得出預測過程如下:
(1) 初值和系數的確定


(3) 計算預測誤差et+1

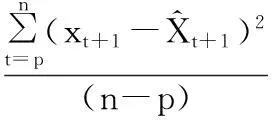
2.2基于自適應過濾模型的預測控制器
考慮到實際的業務訪問請求往往具有周期性和規律性,同時又可能存在一定波動以及變化趨勢,也就是說預測活動受時間因素和具體業務影響。比如在銀行業務中每天存在著幾個高峰時段,對數據庫的訪問非常頻繁,顯然需要更多的代理資源。如果預測控制器僅對當天的代理資源進行全局預測,必然會產生較大的誤差及資源浪費。考慮到時間段和誤差,本文對預測控制器進行如下構建[4,5]:
(1) 數據處理利用一階差分和標準化處理公式對訓練數據進行無量綱處理,消除數據的趨勢和波動。
Δxi=xi+1-xi
(3)
(4)
式中,1≤i≤p,t為預測期數。
(2) 權數調整對權數調整公式進行修改以提高預測精度。
(5)
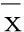
(3) 預測執行對一天24小時進行半小時分隔,構建48個局部預測對象,利用連續10天內相同時段的數據建立預測模型,完成下一天代理資源的預測。 進行預測時,預測控制器依照圖4所示流程執行。當然預測資源是在服務器空閑時進行,而在服務器正常工作時僅完成代理的分配與解分配任務。
圖4 執行流程
3測試實驗及預測分析
根據連接集中器的改進模型和預測理論,基于Linux平臺設計實現連接集中器,并已應用在江西省電子信息產業振興和技術改造項目中。為驗證連接集中器在高容量環境中的性能表現及預測效果,本文模擬大量連接請求進行測試實驗,同時分析實際應用過程中的預測效果。
3.1測試環境
測試環境包括1臺數據庫服務器、1臺應用服務器和3臺壓力測試機,所有配置均為Intel i3-2130 3.40 GHz處理器,2 GB內存。兩臺服務器均運行RedHat Enterprise Linux 6.4,測試機運行Windows XP,數據庫為DB2 V9.7,連接集中器部署在應用服務器上。HP Loadrunner 11作為測試工具用來模擬大量連接請求,同時利用rstatd service監控系統資源的使用情況。
3.2測試分析
本文共設計兩組測試實驗,分別對改進連接集中器和DB2內置連接集中器進行對比測試,分析其處理能力、響應時間及資源使用情況。將DB2內置連接集中器的主要參數進行配置[6]:MAX_CONNECTIONS=300,MAX_COORDAGENTS=100,NUM_INITAGENTS=100,NUM_POOLAGENTS=100。測試結果如圖5和圖6所示,對比發現改進連接集中器性能明顯優于DB2內置連接集中器,尤其在響應時間方面有較大提升。
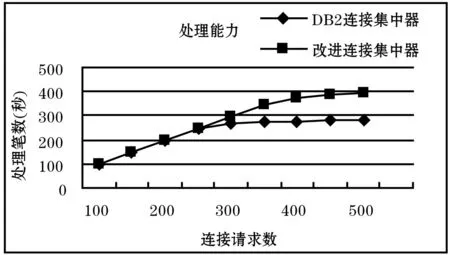
圖5 處理能力
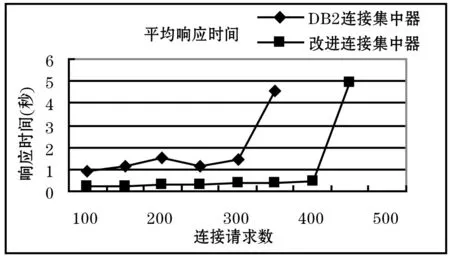
圖6 平均響應時間
測試過程中系統資源的使用情況如表1和表2所示,對比分析得出,改進后連接集中器使數據庫服務器的User CPU使用率大幅下降,應用服務器User CPU使用率略有升高,而Memory和System CPU使用率兩者則幾乎相同。改進的連接集中器降低了數據庫服務器的資源消耗,釋放出更多的資源。

表1 改進連接集中器資源利用率

表2 DB2連接集中器資源利用率
3.3預測分析
選取實際應用過程中連續20天內9:00至9:30時刻的數據進行預測分析。由前10組數據建立初始預測模型,此后每連續10組數據進行訓練來調整權數,并預測下一期的代理數。取學習常數k=0.00000038,4個權數φ1,φ2,φ3,φ4,對數據訓練后生成初始預測模型為:

根據以上模型進行第一次預測,經過多次權數調整后再重新執行預測,整個預測過程如圖7所示。

圖7 預測分析
從圖7可以看出,自適應過濾預測模型對代理資源的預測具有較高的精度,預測曲線接近于實際曲線,且計算得出其擬合精度[7-9]達90%,迭代調整次數約為800次。也就是說,連接集中器能夠快速、高效地預測代理資源的使用情況,提前分配代理來服務于連接請求,保證了系統資源的合理利用[10]。
4結語
本文針對DB2數據庫在實際應用中存在的資源分配問題,在現有連接集中器的基礎上進行改進,引入自適應過濾預測模型,最大限度降低資源的消耗,保證資源的合理分配。測試結果及實際應用表明,改進的連接集中器使服務器的資源消耗和響應時間得到明顯改善。今后的工作將進一步分析連接集中器在高實時性、高并發性下的優化規律,同時研究對各種異常情況的處理機制。
參考文獻
[1] 呂健波,戴冠中,幕德俊.絕對延遲保證在Web應用服務器數據庫連接池中的實現[J].計算機應用研究,2012,29(5):1838-1841.
[2] 羅榮,唐學兵.基于JDBC的數據庫連接池的設計與實現[J].計算機工程,2004,30(9):92-93,111.
[3] 徐國祥.統計預測和決策[M].上海: 上海財經大學出版社,2012.
[4] 田占偉,劉臣,王磊,等.基于模糊PA算法的微博信息傳播分享預測研究[J]. 計算機應用研究,2014,31(1): 51-54.
[5] Yanyan Zheng,Renzuo Xu. An Adaptive Exponential Smoothing Approach for Software Reliability Prediction[C]//WiCom’08.04th International Conference,2008,1-4.
[6] 牛新莊.DB2數據庫性能調整和優化[M].北京: 清華大學出版社. 2009.
[7] 馬華林,李翠鳳,張立燕.基于灰色模型和自適應過濾的網絡流量預測[J].計算機工程,2009,35(1):130-131,152.
[8] 馬華林,張立燕.基于自適應過濾法和馬爾柯夫鏈的網絡流量預測方法[J].計算機應用與軟件,2009,26(12): 216-218.
[9] 趙飛.基于殘差自回歸和自適應過濾的生活能源消費量組合預測模型[J].統計與決策,2010(3),162-163.
[10] 陶庭葉,高飛,吳兆福.自適應過濾法及其在大壩監測中的應用[J].測繪科學,2009,34(5): 181-182.
中圖分類號TP311
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.02.015
收稿日期:2014-08-14。江西省電子信息產業振興和技術改造項目(2013- 260)。張文宇,碩士生,主研領域:網絡與數據庫。周琪云,教授。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
