基于信息擴散和可變模糊集的石林縣旱災風險評價
2016-03-22 04:46:10陳志明河海大學商學院南京20098河海大學水文水資源與水利工程科學國家重點實驗室南京20098
中國農村水利水電 2016年11期
張 強,陳志明,2,張 雪(.河海大學商學院,南京 20098;2.河海大學水文水資源與水利工程科學國家重點實驗室, 南京 20098)
0 引 言
旱災是世界上最嚴重的自然災害之一,它在持續時間、影響范圍、災害影響等方面位列自然災害之首[1]。2010-2012 年中國西南地區連續三年特大春旱等都預示著未來的干旱威脅將更大[2]。隨著中國經濟不斷發展,生態環境的易損性和脆弱性增大,導致干旱成災率和旱災損失呈明顯增加的趨勢。
干旱的風險評價已成為國內外學者們研究的熱點問題。Tsakiris[3]等在區域干旱評價中采用了一種全新的偵查指數,它包含了除降水外其他的氣象參數、潛在蒸散等因素,更適用不斷變化的環境。李文亮[4]等采用信息擴散理論對黑龍江省氣象干旱災害進行了風險評估與區劃研究分析。陳曉楠[5]等建立了神經網絡模型對農業干旱程度進行量化計算,詳細地研究了農業干旱的概率分布,并以河南省濮陽市渠村灌區作為實例,計算出該區域的農業干旱程度概率分布。陳家金[6]等利用正態 信息擴散的計算方法,結合東南沿海三省歷年的作物干旱受災面積和成災面積資料,對該區域進行農業干旱風險評估。楊奇勇[7]等基于干旱風險管理的穩定性、脆弱性和恢復性,同時考慮到區域的應急抗旱水平,以湖南省的14個地州市為研究對象,利用灰色關聯聚類法、層次分析法等方法建立評價模型,對湖南農業干旱風險進行了分析。張星[8]等以農業氣象自然災害為研究對象,采用灰色分析方法對其進行評估,根據關聯度對災害輕重程度進行排序,運用GM模型預測了災害嚴重年份。
國內外關于干旱風險評估已經取得了非常豐富的研究成果,考慮到干旱災害的不確定性和隨機性,以及小樣本和模糊性問題,引入模糊數學領域的信息擴散和可變模糊集理論建立干旱災害風險評價模型,該模型具有可操作性強、數據需求小等特點。通過對云南省石林縣的調研實際情況,從干旱災害的危險性、敏感性和受損性3個方面出發,選取相應的農業干旱災害風險評價指標,建立指標體系,將可變模糊評價與信息擴散相結合的模型運用到石林縣旱災風險評估中,為該縣應對農業干旱災害提供了決策依據。
1 干旱風險評價指標體系
1.1 研究區簡介
本文以云南省石林縣的農業旱災為研究對象,時間跨度為2000-2010年共11年。2008 年以來,石林縣出現了自有氣象記錄以來最嚴重的干旱災害,旱災發生范圍之廣、干旱程度之重、持續時間之長、損失之重都是歷史罕見的。對農業生產造成了很大的危害,嚴重制約了農業生產和社會經濟的發展,造成全縣5.1 萬人、2.6 萬頭大牲畜飲水困難,農作物受災面積13 717.9 hm2,成災面積7 282.9 hm2,絕收面積2 560 hm2。
1.2 干旱風險評價指標體系
在進行干旱災害風險評價時,指標體系的選取尤為重要。一般來說,合理的干旱評價指標不僅應能準確地描述干旱的程度、范圍和起止時間,而且應包含明確的物理機制,充分考慮到降水、蒸發、土壤等因素的影響。根據自然災害系統理論,干旱災害風險取決于致災因子的危險性、孕災環境的敏感性和承災體的受損性。本文從這三方面出發,選取相應的干旱風險評價指標,如圖1所示。
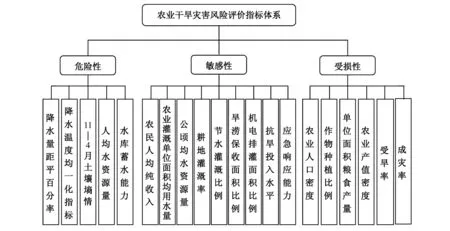
圖1 農業干旱災害風險評價指標體系Fig.1 Agricultural drought disaster risk evaluation system
1.3 干旱災害風險評數據來源
通過實地調研及查閱《云南統計年鑒》、《云南省水利統計年鑒》、《云南省水資源公報》、《云南省旱情簡報》、《抗旱規劃初稿》等資料,獲得了2000-2010年11年間石林縣的評價指標特征值。由于篇幅所限,表1只列出部分指標數據。
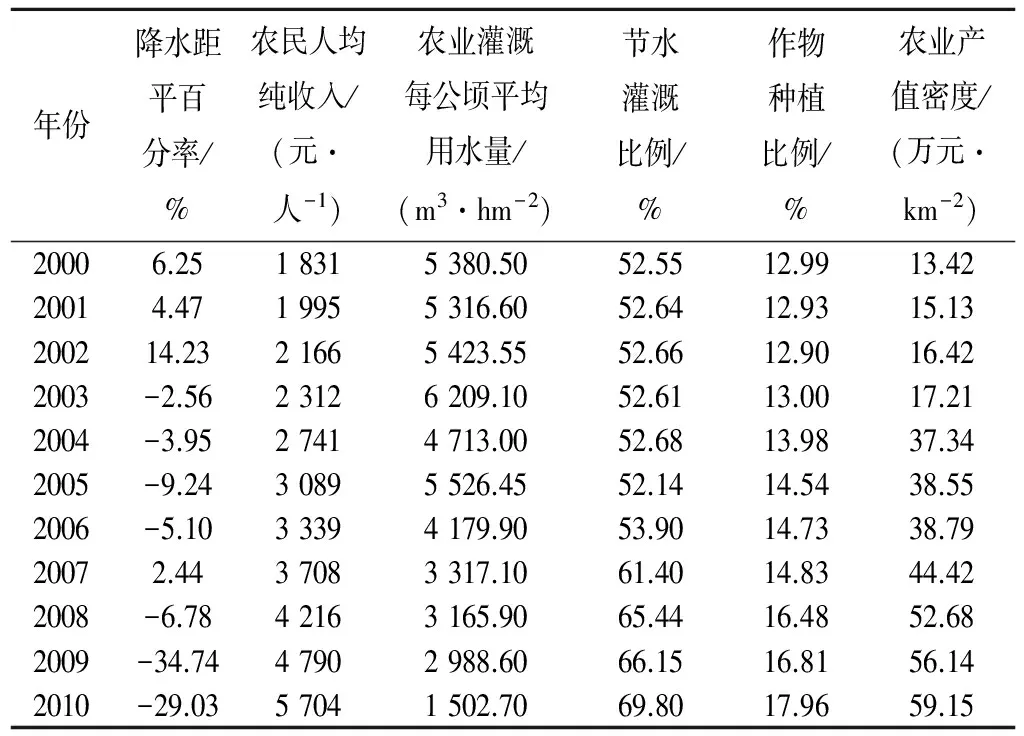
表1 云南省石林縣2000-2010年的農業旱災風險評價指標特征值Tab.1 Agricultural drought risk assessment eigenvalues of Yunnan Shilin County during 2000-2010 years
2 模型構建
基于干旱災害風險評價隨機性和不確定性等特點,引入模糊信息處理中的信息擴散方法[9](Information Diffusion Method)和模糊數學領域的可變模糊集理論[10](Variable Fuzzy Sets,VFS)建立基于信息擴散-可變模糊(IDM-VFS)耦合的干旱災害風險評價模型,有效解決風險評價中的小樣本、信息不足和模糊性等問題,其建模主要過程如下。
2.1 信息擴散的計算步驟
信息擴散是一種通過適當的擴散模型將樣本集值化的模糊數學處理方法,它能夠優化利用樣本的模糊信息。本文選用正態擴散模型,其基本計算步驟如下:
設某一評價指標的離散點為X={x1,x2,…,xn},xi(i=1,2,…,n)為樣本點的觀測值,其論域U為U={u1,u2,…,um},uj(j=1,2,…,m)為論域內的某個取值。
通過正態擴散函數fi,將樣本點xi所攜帶的信息擴散給論域U中的每一個取值uj:
(1)
(i=1,2,…,n,j=1,2,…,m)
式中h為擴散系數,計算公式如下:

(2)
式中:a、b分別為樣本中的最小值、最大值。
為了使每個集值樣本地位相同,對擴散函數fi(uj)進行歸一化處理,令:
(3)
則歸一化后的擴散函數gi為:
(4)
在所有樣本都經過以上處理后,計算經信息擴散后推斷出的觀測值為uj的樣本個數q(uj)和各uj上的樣本總數Q:
(6)
則樣本落在uj處的頻率為:p(ui)=q(uj)/Q,也就是災情為uj的概率,而指標值超過uj的超越概率為:
(7)
計算出各評價指標xi在其論域內的取值uj出的超越概率P(uj),按照旱情等級的超越概率分級標準,求出各評價指標對應旱情等級的臨界值,得到旱情等級劃分標準。
2.2 模糊可變評價法的步驟
基于可變模糊集理論的模糊可變評價法通過模型并變化其參數組合,科學地計算出干旱評價等級,提高干旱風險評價結果的可信度。模糊可變評價法主要包括以下幾個步驟:
(1)生成指標特征值矩陣。設有n個自然災害樣本組成的樣本集,X=(x1,x2,…,xi,…,xn),依據r個指標特征值對樣本進行識別。第i個樣本的特征用r個指標特征值表示:xi=(x1i,x2i,…,xsi,…,xri)T,則樣本集可以用r×n階指標特征值矩陣表示:X=(xsi)r×n,其中:xsi為第i個樣本的第s個指標特征值,s=1,2,…,r,i=1,2,…,n。
(2)建立指標標準特征值矩陣。樣本集根據r個指標按c個級別的指標標準特征值進行識別,則有r×c階指標標準特征值矩陣:Y=(ysh)r×c,ysh為級別h關于指標s的標準特征值,h=1,2,…,c。
(3)確定吸引域、范圍域及點值矩陣。參照指標標準值矩陣和待評價地區的實際情況確定干旱災害可變集合的吸引域矩陣與范圍域矩陣,Iab=([ash,bsh])和Icd=([csh,dsh])。根據干旱災害風險度分為c個級別的實際情況確定吸引域[ash,bsh]中DA(xsi)h=1的點值Msh的矩陣M=(Msh)。
(4)計算指標分級相對隸屬度矩陣。判斷樣本特征值xsi在Msh點的左側還是右側,根據如下公式計算差異度DA(xsi)h:
x落入M點左側時的相對差異函數模型為:
(8)
x落入M點右側時的相對差異函數模型為:
(9)
D(u)=-1x?[c,d]
(10)
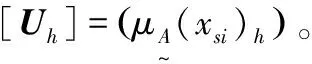
(5)確定各指標權重。
ω=(ω1,ω2,…,ωr)
(6)計算綜合相對隸屬度。
(11)
式中:iu′h為非歸一化的綜合相對隸屬度;α為模型優化準則參數;ωs為指標權重;r為識別指標數;p為距離參數,p=1為海明距離,p=2為歐氏距離。
α與p可采用不同的組合參數,即α=1,p=1;α=1,p=2;α=2,p=1;α=2,p=2 4種取值。
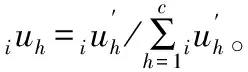
(7)計算級別特征值進行分級評價。根據模糊概念在分級條件下最大隸屬度原則的不適應性,計算級別特征值對樣本進行級別評價,如下式。
H=(1,2,…,c)·U
(12)
3 云南省石林縣農業旱災風險評價
將建立的IDM-VFS模型運用到云南省石林縣的農業干旱災害風險評價中。首先利用信息擴散模型確定各風險評價指標的分級標準。以干旱評估通用的分級方法,將干旱等級劃分為五個等級,分別是無旱、輕旱、中旱、重旱和特旱。各評價指標等級劃分標準確定后,采用可變模糊評價法對云南省石林縣進行農業干旱災害風險評價。石林縣農業干旱風險評價指標等級劃分標準見表2。
目前,確定指標權重的方法主要包括客觀賦權法和主觀賦權法兩大類。客觀賦權法根據實際問題的樣本數據,采用一定方法對指標權重進行計算;而主觀賦權法主要取決于決策人的主觀判斷,評判者根據自身經驗確定各指標的重要程度。兩類方法各有利弊,因此,文章將兩種方法結合起來確定各評價指標的權重,首先采用熵權法計算出各指標的數學權重,然后利用網絡分析法(ANP)確定指標的經驗權重,最終將兩套權重進行加權組合,從而求得每個指標的權重值。計算求出的農業干旱災害評價各指標權重值如表3所示。
表2 干旱風險評價指標等級劃分標準Tab.2 Drought risk assessment classification standard

表3 基于熵權法和ANP法的云南省石林縣農業旱災風險評價指標權重Tab.3 The agricultural drought risk assessment index weight of Yunnan Shilin County based on entropy and ANP method
根據表2建立石林縣可變集合的吸引域矩陣Iab與范圍域矩陣Icd以及點值Msh的矩陣。判斷樣本值與點值的位置關系,計算相對差異度D(xsi)h、指標對風險等級的相對隸屬度μA(xsi)h。采用第3節確定的各指標權重,根據公式采用不同的參數組合,可以計算得到非歸一化的綜合相對隸屬度向量iu′h,歸一化后得到綜合相對隸屬度矩陣U。石林縣各風險子系統評價指標相對隸屬度矩陣如表4所示。
最后通過變換參數α、p的取值,進行級別特征值的計算,可得各區縣干旱風險危險性、敏感性和受損性3個子系統的平均級別特征值。石林縣各年的農業干旱風險值如表5所示。
由表5可見,石林縣2009年干旱災害的危險性最高,其次為2010年、2005年。2009年以來,南盤江流域部分地區降雨較正常水平嚴重偏少,且氣溫持續偏高,土壤和植被含水量低,水庫塘壩蓄水得不到有效補充,從而導致干旱難以緩解。干旱災害的脆弱性總體為逐漸減弱的趨勢,這是由于農民收入、農業灌溉設施、抗旱投入水平以及應對旱災能力均逐漸增強,從而降低了干旱災害的脆弱性。2010年的易損性最高,石林縣的作物受旱率達到35.19%,因旱成災率達31.74%,是11年中最為嚴重的一年;其次是2002年,作物受旱率達到34.21%,因旱成災率達29.28%。2000-2011年平均來看,石林縣的危險性風險值為2.19,敏感性為3.42,受損性為3.04。
根據計算出云南省石林縣的干旱災害子系統的風險特征值,利用各子系統的綜合權重值可以得到區域的農業干旱災害綜合風險等級,即:

表4 石林縣各子系統評價指標的相對隸屬度矩陣Tab.4 Each relative membership degree matrix of subsystem index in Shilin County
R=W×H
(13)
式中:R為區域旱災綜合風險值;W表示各子系統綜合權重向量;H就是各區縣的子系統風險特征值向量,最終得到石林縣最終的綜合風險等級為3級。
4 結 語
本文綜合考慮其危險性、脆弱性和易損性3個因子,構建了干旱災害風險評價指標體系,形成干旱災害風險評估系統。基于信息擴散方法,確定評價指標的風險等級劃分標準。利用可變模糊評價模型,對干旱災害進行風險評
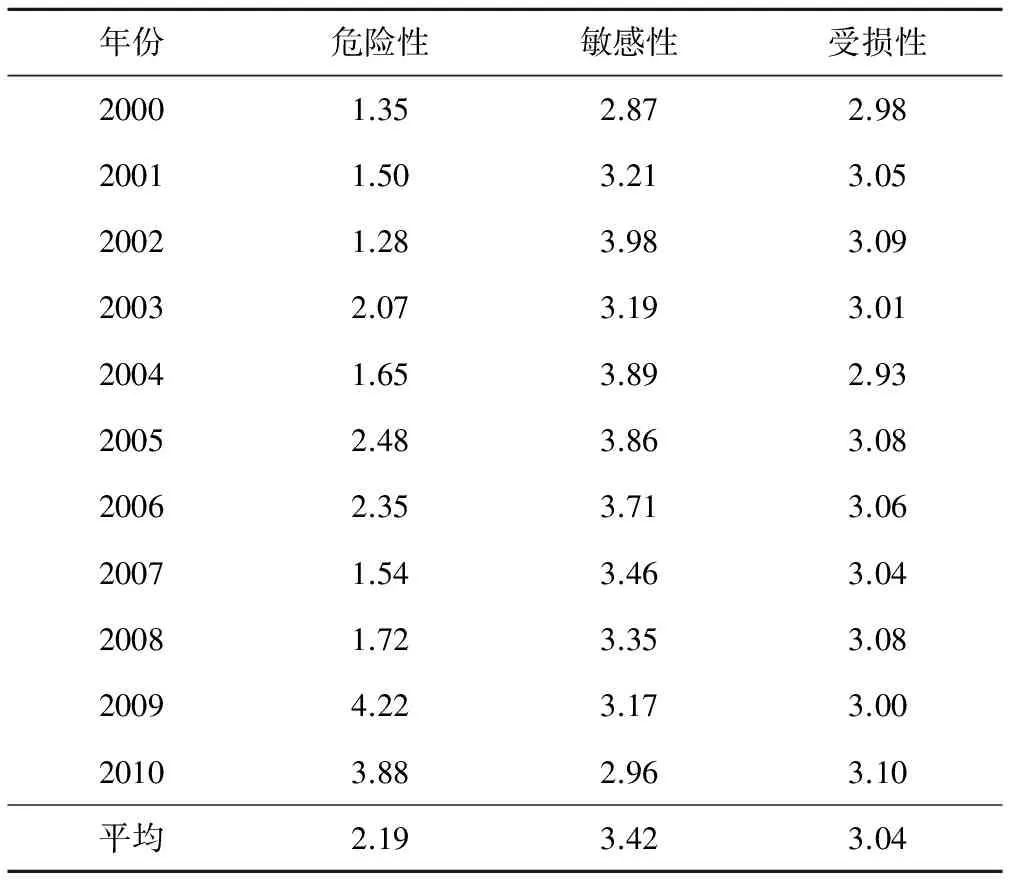
表5 石林縣農業旱災風險評價系統的干旱風險值Tab.5 The drought risk value of Shilin County about agricultural drought risk assessment system
價,建立基于信息擴散——可變模糊集理論的旱災風險評價模型。以云南省石林縣進行實證研究,采用IDM-VFS模型計算出該縣2000年-2010年的農業干旱風險水平,分別對危險性、脆弱性和易損性進行子系統風險分析,最后得到綜合風險等級。
□
[1] Sam Lake P. Drought and aquatic ecosystems: effects and responses[M]. Oxford, UK: John Wiley and Sons Ltd, 2011.
[2] 吳 迪,裴源生,趙 勇,等.湄公河流域農業干旱主要影響因素分析和預估[J]. 農業工程學報,2012,28(8):1-10.
[3] Tsakiris G, Pangalou D, Vangelis H. Regional drought assessment based on the Reconnaissance Drought Index (RDI)[J]. Water Resources Management, 2007, 21(5): 821-833.
[4] 李文亮, 張冬有, 張麗娟. 黑龍江省氣象災害風險評估與區劃[J]. 干旱區地理, 2009,32(5):754-760.
[5] 陳曉楠,黃 強,邱 林,等.基于混沌優化神經網絡的農業干旱評估模型[J].水利學報,2006,37(2):247-252.
[6] 陳家金,王加義,林 晶,等. 基于信息擴散理論的東南沿海三省農業干旱風險評估[J]. 干旱地區農業研究, 2010,28(6):248-251.
[7] 楊奇勇, 毛德華. 湖南省農業干旱水資源風險評價[J]. 湖南師范大學自然科學學報, 2008,31(1):125-129.
[8] 張 星,陳 惠,周樂照. 福建省農業氣象災害灰色評價與預測[J]. 災害學, 2007,22(4):43-45.
[9] 歐陽蔚,于艷青,金菊良,等. 基于信息擴散與自助法的旱災風險評估模型——以安徽為例[J].災害學, 2015,30(1):228-234.
[10] 陸志強,李吉鵬,章耕耘,等. 基于可變模糊評價模型的東山灣生態系統健康評價[J].生態學報, 2015,35 (14):1-17.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
今日農業(2021年14期)2021-11-25 23:57:29
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
