SPSS中判別分析的使用
2016-03-23 02:56:51瞿健菊
文教資料 2015年34期
瞿健菊
摘 要: 判別分析是多元統計分析中最常用的方法之一。該文結合一個語言學實驗的例子對SPSS判別分析的操作步驟和輸出結果作了詳細的介紹,并對判別分析的不同方法在SPSS中的使用進行了區分。
關鍵詞: SPSS 判別分析 語言學
1.引言
判別分析是多元統計分析中判別樣本所屬類型的一種常用方法。它的研究對象是訓練樣本,也就是說原始數據的具體分類是事先已知的,然后根據原始數據求出判別函數將待判樣本的數據代入判別函數中判斷其類型。[1]常用的判別分析方法主要有:距離判別法、Fisher判別法和Bayes判別法。然而,在SPSS操作中只能實現Bayes判別法與Fisher判別法兩種,并且這兩種方法的操作是合在一起進行的,所以使用起來需要特別注意。[2]下文將結合一個語言學實驗的例子對SPSS判別分析的步驟和輸出結果作詳細解釋和說明。
2.語言學實驗
2.1實驗背景
Fletcher和Peters(1984)研究發現,可以用語法和詞匯兩個維度來刻畫語言受損兒童在語言表達方面的特征。被試分為兩組,一組是20個正常兒童(LN),另一組是用標準化測試尺度在年齡和智力活動方面跟LN組相比而診斷為語言受損的9個兒童(LI)。在標準條件下收集他們的自發的語言數據(LN組的年齡均值為60.86個月,LI組的年齡均值為62.33個月)。圍繞65個語法與詞匯范疇——大部分引自Crystal、Fletcher和Garman(1976),每組兒童提供的樣本都包括200個話語的得分。其中一個語法變量是根據無標記動詞形式——既無后綴又無助動詞修飾的實義動詞詞干——的個數來評分的。另外一個詞匯范疇是動詞詞型,即一個兒童在樣本中使用不同的實義動詞的個數。[3]
2.2數據錄入
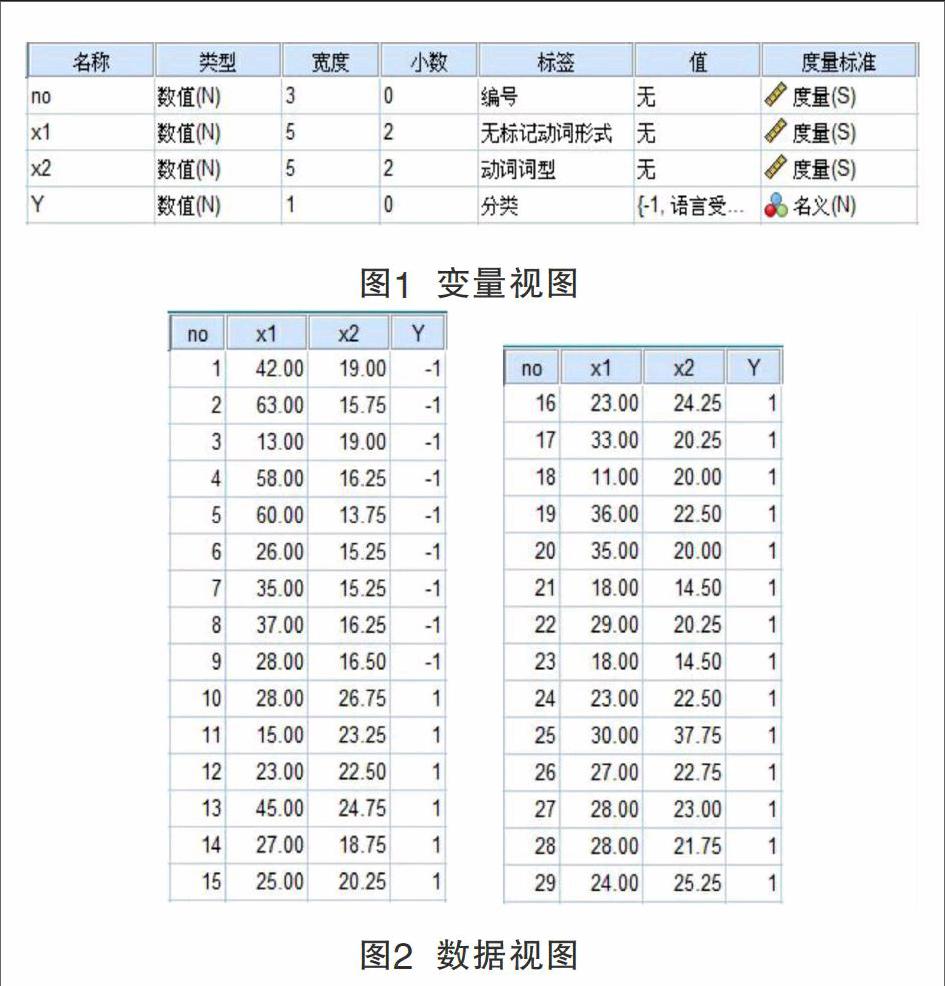
本文使用的SPSS為20.0版本。首先建立一個數據文件linguistics.sav,將Fletcher和Peters所提供的每個被試的數據錄入進去。數據文件的變量視圖和數據視圖分別如圖1和圖2所示。在變量視圖中,定義變量Y(分類)的值標簽,-1為語言受損,1為正常。在數據視圖中,共29行數據,分別為29個被試兒童在x1和x2這兩個變量上的得分及所屬類別。
圖1 變量視圖
2.3判別分析步驟
①單擊“分析”→“分類”→“判別分析”,從對話框左側的變量列表中選中進行判別分析的變量“無標記動詞形式[x1]”和“動詞詞型[x2]”進入“自變量”框,作為判別分析的基礎數據變量。從對話框左側的變量列表選中“分類[Y]”進入“分組變量”框,并單擊“定義范圍”按鈕,在“定義范圍”對話框中,定義判別原始數據的類別數,在最小值處輸入-1,在最大值處輸入1。分析方法按默認的“一起輸入自變量”。
②打開“統計量”對話框,在“描述性”中,選擇“單變量ANOVA”和“BoxsM”。在“函數系數”中選擇“Fisher”(注:此為Bayes選項)和“未標準化”(注:此為Fisher選項)。
此外,“均值”可以輸出各類中各自變量的均值和標準差。“矩陣”選項組可選擇自變量的系數矩陣。
③打開“分類”對話框,在“先驗概率”(注:此為Bayes選項)中,按默認選擇“所有組相等”。在“使用協方差矩陣”中,按默認選擇“在組內”。在“輸出”(注:此為Bayes選項)中,選擇“摘要表”和“不考慮該個案時的分類”。在“圖”(注:此為Fisher選項)中,選擇“合并組”、“分組”和“區域圖”。
此外,“個案結果”可以輸出每個觀測量包括判別分數實際類預測類(根據判別函數求得的分類結果)和后驗概率等。
④打開“保存”對話框,選擇“預測組成員”、“判別得分”和“組成員概率”。
全部選擇完成后,單擊“判別分析”對話框中的“確認”按鈕。
2.4判別分析結果
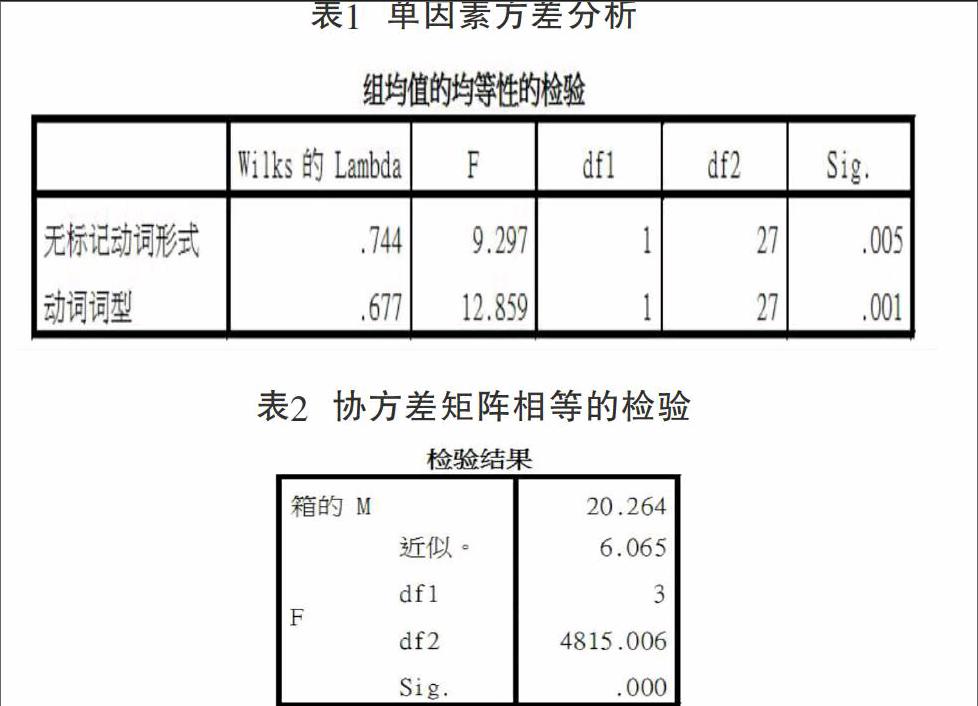
①適用條件檢驗。在“統計量”對話框中,選擇“單變量ANOVA”和“BoxsM”,可分別得到下面的表1和表2。表1中的Sig值表示這兩個變量均值在各組間都是有差異的,因此這兩個變量對類間的判別都是有作用的。表2中的Sig值表示組間協方差齊這一假設是被拒絕的。不過,協方差齊的這一要求在實際應用中往往是被忽視的。[4]
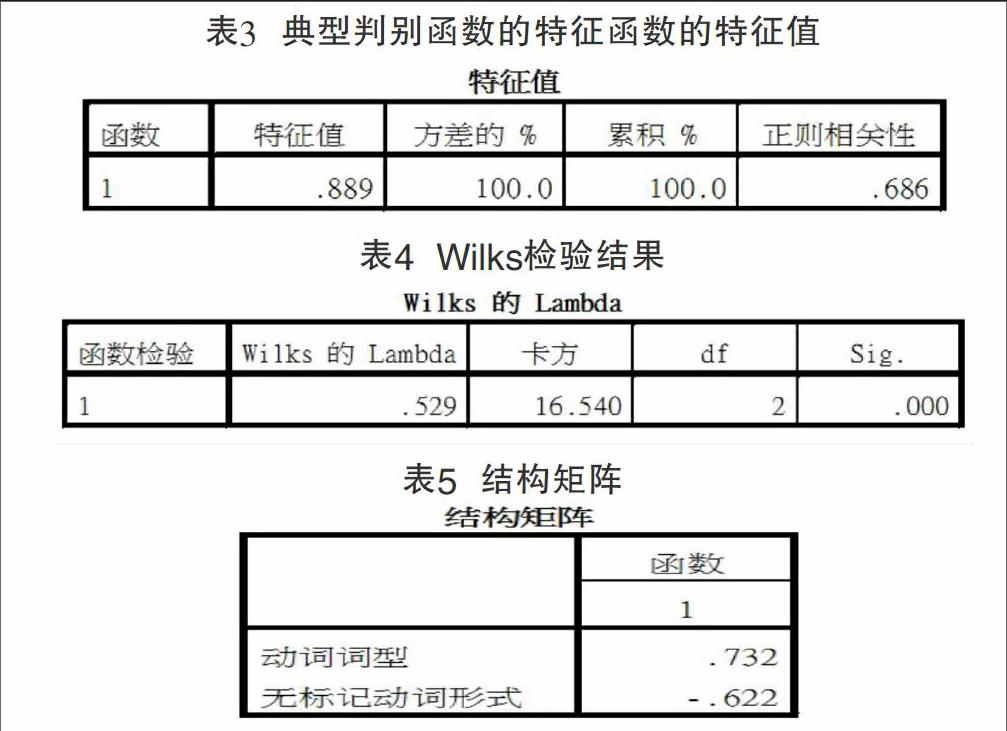
②基本輸出結果。表3給出了判別函數的特征根以及判別指數。本實驗中只有一個判別函數,所以只有一個特征值。表4中的Sig值表示差異達到顯著水平,即這個投影函數能將兩組兒童區分開。從表5中,可以看出判別函數主要與“動詞詞型”這個自變量相關。由于本實驗只有一個判別函數和兩個自變量,那么可以推測在區分正常兒童和語言受損兒童上,“動詞詞型”這個變量在判別分析中起了主要作用。表6是各組的判別函數的重心。注意此處使用的是非標準化典型判別式函數。
③三種判別式。判別分析默認會給出表7的判別函數,其中的判別函數使用的是標化變量。如果在“統計量”對話框中,選擇“未標準化”,可以得到表8的判別函數;選擇“Fisher”,可以得到表9的判別函數。注意此處“Fisher”復選框對應的實際上是Bayes判別。
標準化典型判別式為:
F(X)=-0.684×Z無標記動詞形式+0.785×Z動詞詞型(變量前加Z表示標化后的數值)
未標準化典型判別式為:
F(X)=-2.046–0.060×無標記動詞形式+0.190×動詞詞型
Bayes判別式為:
語言受損=-13.760+0.285×無標記動詞形式+0.897×動詞詞型
正常=-17.050+0.167×無標記動詞形式+1.271×動詞詞型
④圖表。由于本實驗只有一個判別函數,所以沒有產生區域圖和合并圖,只有如圖3和圖4所示的分組直方圖,從直方圖中可以大致看出各組中樣本的分布情況。
圖3 分組直方圖(語言受損)
圖4 分組直方圖(正常)
⑤分類結果。在“分類”對話框中,選擇了“摘要表”可以得到表10中的上半部分,是采用回代法得到的判別信息,由表可見有96.6%的正確率,其中語言受損有1例錯判。在“分類”對話框中,選擇了“不考慮該個案時的分類”可以得到表10中的下半部分,是采用交叉驗證法得到的判別信息,本實驗中正確率為86.2%,其中語言受損有1例錯判,正常有3例錯判。
⑥保存結果。運行判別分析后回到數據文件的數據視圖,如圖5所示,生成了新的變量。在“保存”對話框,選擇“預測組成員”,產生“Dis_1”變量,顯示的是各樣本按Bayes判別所屬的類別;選擇“判別得分”得到“Dis1_1”列,是樣本在Fisher投影函數下投影的坐標;選擇“組成員概率”得到“Dis1_2”和“Disc2_2”,為樣本分別屬于第1類與第2類的后驗概率大小。根據表10所示,語言受損有1例錯判。在圖5中可以看出,語言受損兒童中錯判的是第3例,因為其第2類的后驗概率0.90727大于第1類的后驗概率0.09273,因此判別為第2類。此外,“Dis1_1”的值還可以結合表6的類中心坐標使用距離判別法進行類別判別。
3.結語
綜上所述,SPSS只能完成Bayes判別與Fisher判別,無法直接完成距離判別。SPSS判別分析是以Bayes判別為主,主要菜單與選項都是針對Bayes判別分析設置,并且最終保存的判別結果也是以Bayes判別為依據;Fisher判別操作僅給出投影表達式、各類投影中心坐標及投影分界圖,最終判別結果需要自己根據各類投影中心坐標或投影分界圖去做判別。[5]此外,由于判別分析有著比較嚴格的前提條件,比如自變量和因變量間的關系要符合線性假定等等。當自變量和因變量間的聯系為比較復雜的非線性函數,甚至無法給出顯式表達時,這些基本的判別法就不適用了。而SPSS在“分析”菜單中,還提供了“樹”和“神經網絡”,這些方法均為非參數方法,因此沒有太多的適用條件限制,應用范圍更廣,也更適合對各種復雜聯系進行分析判斷。
參考文獻:
[1]任志娟.SPSS中判別分析方法的正確使用[J].統計與決策,2006(2):157.
[2]陳希鎮,曹慧珍.判別分析和SPSS的使用[J].科學技術與工程,2008,8(13):3567-3571.
[3][英]Woods,A.等著.語言研究中的統計方法[M].陳小荷等譯.北京:北京語言文化大學出版社,2000:275-280.
[4]張文彤.SPSS統計分析高級教程[M].北京:高等教育出版社,2004:261-277.
[5]陳敏瓊.利用SPSS進行判別分析的幾個問題的說明[J].現代計算機(專業版),2015(2):34-39.
