基于概念網的媒體大數據分析和結構化描述方法
2016-03-24 00:12:47張寶鵬彭進業(yè)范建平
中興通訊技術 2016年2期
關鍵詞:可視化
張寶鵬 彭進業(yè) 范建平
摘要:提出基于概念網的媒體大數據結構化描述和分析的技術框架,該框架可以針對不同的數據獲取來源,通過層次式多角度概念描述模型融合數據的視覺特征、實例和概念關聯的語義,并提出面向單一媒體和多媒體文檔的跨媒體概念提取及基于結構的語義對齊方法,從而有效支持媒體大數據的語義關聯分析及多領域的智能應用。
關鍵詞:概念網;媒體大數據分析;概念抽取;結構化描述;可視化
Abstract:In this paper, we propose that a topic network-based enabling technology framework for big media analysis and structural description. And it proposes a hierarchical concept description model with multiple perspectives for different sources data to integrating semantic of visual, instance and concept correlation. And cross-media concept extraction method for single media and multimedia document and their structure-based semantic alignment method are also proposed, which can efficiently support the big media analysis and smart application in many domain.
Key words:topic network; big media analysis; concept extraction; structural description; visualization
隨著互聯網的普及和迅速發(fā)展,各類在線社交網絡(如Facebook、Twitter、新浪微博、騰訊網等)的飛速發(fā)展,網絡數據資源越來越多樣化,并呈爆炸式增長。這種大數據的勢態(tài)引發(fā)了多行業(yè)、多領域的時代性變革。大數據思想的重要在于[1]:人們可以在很大程度上從對于因果關系的追求中解脫出來,轉而將注意力放在相關關系的發(fā)現和使用上。目前,在互聯網中,大量文本、圖像、音頻、視頻等媒體大數據迅速增長,其中蘊含了很多人類社會活動的基本規(guī)律,公共衛(wèi)生、商業(yè)乃至思維模式因此醞釀著重大的機會和挑戰(zhàn)。基于大數據的研究逐漸成為各國政府重點發(fā)展的國家戰(zhàn)略,及時、準確地獲取并理解這些數據及其關系不僅僅可以為政府在社會生活、金融服務、醫(yī)療衛(wèi)生等方面發(fā)現和處理民生問題,輔助政府決策,同時也為互聯網經濟的發(fā)展提供有效的客戶和經濟規(guī)律的知識輔助,提供商業(yè)智能決策支持。
盡管媒體大數據成長迅速,應用廣泛,但其數據量大、種類繁雜、價值密度低以及時時刻刻不斷變化的特點,使得存儲、統計、分類以及調用都非常困難[2],其價值遠沒有得到充分的利用和開發(fā)。而人工智能領域的一些理論和比較實用的方法,已經開始用于大數據分析方面,推動兩個領域技術和應用融合的加速,但依然只是初期。目前谷歌、百度等通用的搜索引擎提供了基于文本描述的多媒體的檢索機制,但對于大數據背景下的多種媒體數據來說,還缺乏準確文本描述,需要不同的算法分析、理解其內容的語義,實現相應的文本描述,從而為搜索引擎所用。另外,媒體數據間的異構性特點,使得當前單一媒體的搜索引擎無法有效支持大數據條件下異構媒體間的數據語義關聯檢索。因此,從媒體大數據智能應用的角度來看,其表示、理解及檢索是重要的環(huán)節(jié),而根據異構媒體間語義關系實現媒體大數據的智能的模式發(fā)現是解決這些問題的關鍵點。
1 媒體大數據分析和描述的關鍵問題
根據媒體大數據深度分析的目標,以及其支撐媒體搜索引擎、媒體消費和關聯分析的需求,盡管當前異構媒體的關聯和分析技術有一些相關研究,但有些關鍵問題還沒有得到解決,包括:
(1)媒體數據標注的不確定性及歧義性
除了大數據的4個V(Volumn、Variety、Velocity、Value)之外,為充分利用大數據蘊含的知識信息,一個重要的問題是解決媒體數據標注的不確定性、歧義性,這種不確定的標簽數據包括:
粗糙標注,例如圖片中對象是在圖片層次上給出的,而忽略了其區(qū)域性的語義;
抽象標注,指標簽只從高層語義角度給出,缺乏具體語義關聯;
無關標注,指標注和圖像語義并無關聯;
噪聲標注,指錯誤的標注。
這些標簽數據將誤導數據驅動的機器學習方法,從而導致數據訓練分類器在性能和準確率上的退化。目前很多項目開展了圖像智能標注的工作,旨在提高標簽的準確率,包括傳統概率的方法[3-4]、場景限制下的綜合方法[5]、深度學習方法[6]及面向大規(guī)模的方法[7]等,但面向媒體大數據的復雜結構,復雜的語義及智能化的需求使得當前技術還遠遠不能滿足其需要。
(2)媒體大數據結構化描述及其機器學習的算法
媒體大數據包含大量的語義概念,而且語義概念之間有千絲萬縷的關系;同時對于不同主域的應用環(huán)境,不同的語義關系需要不同的結構化描述。目前傳統多媒體語義描述模型主要包括兩種:詞袋模型,其源于自然語言理解,適合于視覺的相似匹配,但與語義并沒有直接的對應關系;基于特征-語義的分類模型,源于機器學習,其主要參考的是人類語義感知設計,提取難度較大,準確率不高。由于傳統多媒體語義提取采用多類學習的方法,其中用兩類分類器合成的方法,訓練檢測復雜度較高,訓練難度大,而傳統的多任務學習和結構化支持向量機(SVM)學習方法,無法真正發(fā)掘出概念間相似性結構的信息。兩種方法必須要解決的問題就是面向媒體大數據的泛化能力。目前,基于深度學習的多媒體語義提取方法得到了空前的關注,如文本檢索會議(TREC)的視頻事件檢測提出的基于卷積神經網的深度學習算法,微軟的音、視頻索引服務(MAVIS)的語音識別系統,Google的深度學習模型等,都獲得了很好的效果。但它們主要對音頻、視頻或文本單一模態(tài)進行分析,沒有充分利用多模態(tài)信息間的相互協同關系。
(3)媒體大數據的關聯性分析
媒體大數據分析首先需要研究異構媒體的統一表示[8],相似度計算及語義關聯的分析方法。傳統的異構媒體采用基于子空間的映射技術,包括典型關聯分析(CCA)方法、概率潛語義分析(PLSA)方法等。在相似度計算方面,主要的度量方法是基于圖模型的相似度度量方法和基于學習的相似度度量方法[9],但目前兩者主要都是依賴共生性假設,即如果兩個多媒體文檔包含同一個媒體對象,則它們具有相同語義,也可以說是基于概念和概念的相似性或簡單的物理依賴。跨媒體數據中的內在語義關系和結構(概念相關性網絡)并沒有給予充分的考慮,并且概念間關系復雜,因此并不適用于媒體大數據的深度分析,而主流的機器學習方法可能無法直接解決其復雜、大規(guī)模學習問題。
(4)媒體大數據的可視化與可視化分析
在媒體大數據的深度分析中,準確率和查全率是主要的分類器的評估標準,但由于學習分類器會過擬合,以及用于分類器訓練和測試的樣本是服從于同樣的分布,因此評估標準會誤導分類器的判定能力,也就是說不能顯式地反映分類器和正確率和其辨識力。一種有效用于分類器評估的方法是可視化分類器的邊界和類間的邊緣,用戶可以交互式地評估其正確率。因此,在機器學習過程中融合人的交互式操作,來改善分類器訓練具有更高的應用價值。
2 媒體大數據關聯分析的
參考技術框架
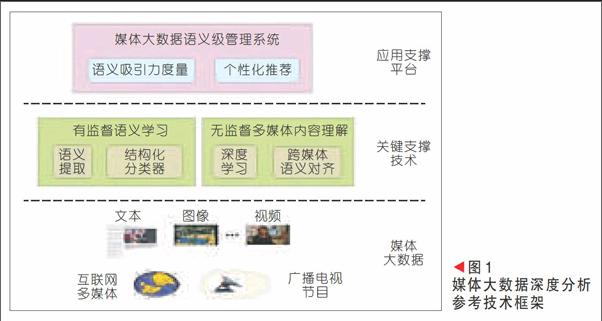
針對目前在媒體大數據深度分析中所面臨的問題,其未來發(fā)展的思路應該是基于內容語義的、全生命周期的支撐,因此我們提出了基于概念網的核心參考技術框架,如圖1所示。針對媒體大數據處理的數據特點,我們需要考慮兩種關鍵技術問題:有監(jiān)督的媒體語義學習;無監(jiān)督的多媒體內容理解。
目前媒體大數據的跨媒體概念的提取方法主要針對兩種不同的媒體數據獲取類型:一種是多媒體文檔,主要是電視節(jié)目和網絡媒體,包含圖像、視頻、音頻和伴隨文本描述等多種媒體形式。其關聯關系隱含在多媒體文檔中,重點解決的問題是多模態(tài)特征融合與跨模態(tài)關聯分析的問題,而跨模態(tài)深度學習技術可以基于已有的圖像、視頻、音頻及其對應的文本訓練其語義概念檢測模型,檢測數據中的語義概念,并使用跨媒體語義對齊技術實現不同媒體語義概念的對齊。另外一種是單一視覺媒體,主要指監(jiān)控錄像和照片包含單一視頻和圖像,但沒有伴隨文本描述,需要進行多媒體數據中視覺語義概念的直接檢測。其通過結合直接的標注數據和圖像或視頻的初級語義進行結構協同學習,提取語義概念并關聯到對應的初級語義概念上,得到跨媒體語義。結構協同學習是基于概念相似性結構進行協同學習獲得的分類模型的方法,其語義的統一于概念網絡,有助于融合異構媒體的內容及關系特征,同時易于進行增量計算、測試修正及擴展。
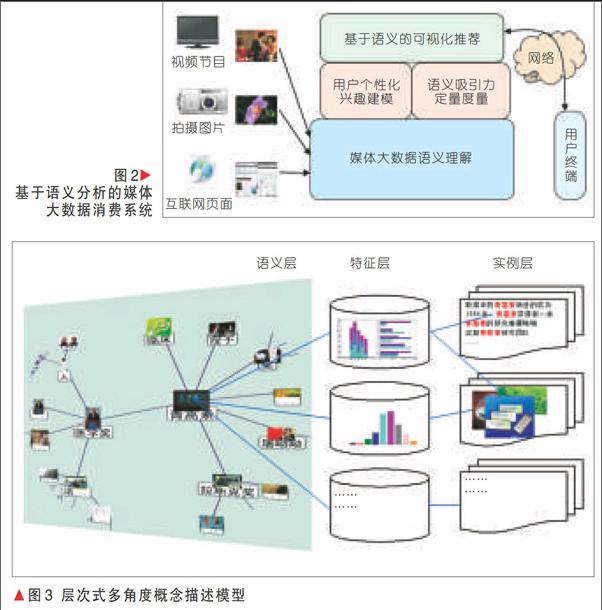
該技術框架可以有效支持異構媒體大數據的可擴展應用,包括與當前搜索引擎的結合及面向不同應用領域的推薦系統等,如圖2所示。
3 媒體大數據關聯分析的
關鍵技術
3.1 層次式多角度概念描述
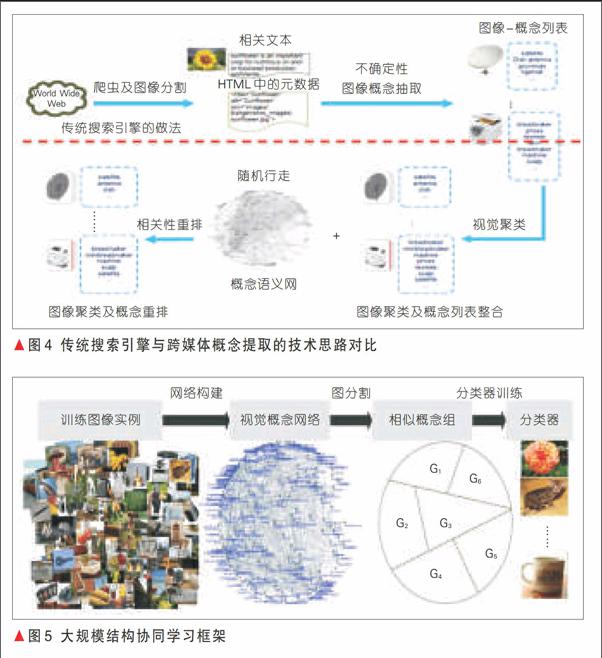
多模態(tài)數據的語義提取并存儲為語義庫,需要一個能夠描述所需語義信息,方便語義運算的語義模型作為數據語義存儲和運算格式。由于相關的數據應用需要在高層語義、底層特征和實例樣本等不同的層面處理海量數據及其語義,這要求語義描述模型要在統一的框架下存儲所有這些信息。其難點在于:模型必須能夠統一存儲不同種類、不同層面差異巨大的媒體數據及其特征和語義。我們認為:應包括3層結構組成的描述模型,通過整合3個層次的關聯(如圖3所示),實現語義-實體-關系模型。其中位于語義層次的概念網應充分考慮大規(guī)模概念間的相關性,并提供能夠對媒體大數據進行關聯分析與結構化描述的新框架,從而用于指導訓練大規(guī)模相關關聯的分類器,并大幅度提高概念檢測準確性。
3.2 基于多媒體文檔的跨媒體概念
提取
傳統搜索引擎技術支持的圖像-文本對應關系的獲取具有很大的不確定性(如圖4所示),而面向媒體大數據,語義對齊與關聯分析可以利用視覺聚類、隨機行走和概念語義網進行相關性重排以產生更準確的跨媒體語義對齊結果,并提取更準確的大規(guī)模跨媒體概念,同時利用視覺聚類可以進行跨媒體的語義消歧。這種跨媒體語義對齊方法可以為機器視覺研究提供大量的可靠標注的訓練數據。
3.3 基于單一媒體的跨媒體概念提取
結構協同學習利用多個語義概念之間的相似性關系信息設計檢測語義概念的分類器,通過充分利用這種相似性關系信息(該關系可以用結構表示),提升大類數媒體數據分類的性能和準確率。面向大媒體數據的大規(guī)模結構協同學習框架(如圖5所示),首先將語義概念相似性網絡進行分割以形成相似概念組,這一過程將最相似的語義概念分到同一組,而將差異較大的概念分到不同組,實現將語義概念中的相似結構表示為概念的分組情況。針對不同分類任務可選擇不同分類算法和不同特征表示,有助于大量減少訓練復雜度。同時,利用多層視覺樹[10]來管理大量分類器,實現快速提取大規(guī)模跨媒體概念。這其中一個重要的問題是:訓練圖像實例如何提取語義。目前,深度學習可以得到很好的特征提取及分類效果[11],而更為有效的方法是將各種傳統視覺特征作為先驗知識模型加入到深度學習算法的訓練當中。
3.4 跨媒體語義對齊
當前很多算法都是針對不同媒體的數據構建語義結構化模型。這些模型有的較好地關聯到了高層語義,但因為缺乏相關的文本數據標注而無法關聯到高層語義,只能通過深度學習算法獲得大量抽象的語義概念及其關系。為了統一管理和挖掘媒體大數據,必須實現抽象的語義概念與具體的語義概念(語言)對齊。描述媒體的結構化語義信息的模型一般為圖結構,我們需要研究語義對齊方法實現多個語義結構的對齊,提高語義信息的準確度。其難點在于:需要精確估計兩個圖的部分節(jié)點之間的相似度關系,但語義概念在不同媒體數據中的具體表現差異巨大,難以直接估算相似度。
為了充分利用所有語義信息獲得最高對齊精度,可以使用流形對齊方法,該方法對實現兩個語義結構的對齊是個較好的選擇。如圖6所示:流形對齊算法綜合計算兩個語義空間的語義概念的相似度和語義概念的內在關聯結構,從而實現兩個語義空間的對齊,這比僅僅依據語義概念之間的各種相似性的方法具有更高性能。
為簡化描述,下面我們把抽象的語義概念稱為未標記實體,具體的語義概念稱為語義實體。在使用流形對齊算法過程中,我們需要計算部分未標記實體和語義實體之間的相似度。我們提出了兩種相似度計算方法:結構協同分類獲得的語義概念包含對齊的圖像視頻數據,這些數據上也包括深度學習算法提取的未標記實體,通過統計未標記實體在某個語義實體對應的圖像、視頻數據中出現的概率,即可計算出未標記實體和語義實體的相似度;用結構協同學習獲得的語義概念檢測模型檢測所有圖像和視頻關鍵幀,可以獲得描述其語義的一個高維矢量,一對視覺實例間的語義相似度可以定義為其語義矢量之間的近似程度,未標記實體和語義實體的語義相似度則可基于兩者對應的圖像和視覺結構間的相似度進行計算。為了既可以體現跨媒體數據對齊的信息又利用結構協同學習的結果,有效的方法是將以上兩種相似度加權組合獲得未標記實體和語義實體之間的融合相似度,融合相似度可以用作流形對齊的節(jié)點間對應信息,從而實現大規(guī)模媒體數據的知識的融合和一致性處理。
3.5 基于概念網的媒體大數據關聯性
分析及其可視化
如果把語義概念之間的相似性用一個加權圖表示,語義概念之間的相似性結構信息將形成一個語義概念相似性網絡。這個網絡的結構對應于語義概念之間的相似性結構,因此可以用于結構化學習指導分類器結構設計。構造語義概念相似性網絡首先需要度量語義概念之間的視覺相似度,而語義概念之間的視覺相似度基于樣本之間的相似度計算,樣本之間的相似度要基于底層視覺特征計算。為了消除概念之間的相似性非常小卻仍然有連接的現象,我們采用自底向上層次式聚類算法裁剪全連接的語義網絡。
該方法可以有效表示主域的數據相關性。例如,用于描述新聞熱點間的相關性的新聞概念網,如圖7所示。這種概念網提供了一個對大規(guī)模媒體概念進行關聯分析和結構化描述的新框架結構,同時也便于面向不同消費系統進行擴展應用。
4 結束語
當前多領域、跨領域的網絡媒體數據呈大規(guī)模增長的態(tài)勢,而異構媒體的智能關聯、知識表示是合理利用數據并為行業(yè)提供智能化服務的核心研究問題,因此,突破媒體大數據的基于內容的結構化描述、關聯與深度分析,形成媒體內容語義的全生命周期的技術框架,以支持個性化搜索與智能推薦、跨終端的多媒體內容呈現等關鍵技術的發(fā)展,對建立面向用戶的智能服務平臺,推進知識獲取及推廣,改善用戶體驗具有非常重要的意義。
參考文獻
[1] 維克托.邁爾.舍恩伯格, 肯尼思.庫克耶. 大數據時代: 生活、工作與思維的大變革[M]. 盛揚燕, 周濤, 譯. 杭州: 浙江人民出版社, 2013
[2] ZHU W, CUI P, WANG Z. Multimedia Big Data Computing [J]. IEEE Multimedia, 2015, 22(3): 96-105. DOI: 10.1109/MMUL.2015.66
[3] FENG S L, MANMATHA R, LAVRENKO V. Multiple Bernoulli Relevance Models for Image and Video Annotation[C]//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. USA: IEEE, 2004(2): II-1002-II-1009. DOI: 10.1109/CVPR.2004.1315274
[4] BARNARD K, DUYGULU P, FORSYTH D, et al. Matching Words and Pictures [J]. J Mach Learn Res, 2013(3): 1107-1135
[5] LI J L, SOCHER R, LI F F. Towards Total Scene Understanding: Classification, Annotation and Segmentation in an Automatic Framework[C]//Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.USA: IEEE, 2009: 2036-2043
[6] FARABET C, COUPRIE C, NAJMAN L, et al. Learning Hierarchical Features for Scene Labeling[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence. USA: IEEE, 2012, 35(8): 1915-1929
[7] WESTON J, BENGIO S, USUNIER N. Large Scale Image Annotation: Learning to Rank with Joint Word-Image Embeddings [J]. Machine Learning, 2010, 81 (1):21-35
[8] ZHU S C. Statistical Modeling and Conceptualization of Visual Patterns [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(6): 691-712. DOI: 10.1109/TPAMI.2003.1201820
[9] 唐杰, 陳文光, 面向大社交數據的深度分析與挖掘[J]. 科學通報, 2015, 60(5): 509-519
[10] ZHOU N, FAN J. Jointly Learning Visually Correlated Dictionaries for Large-scale Visual Recognition Applications [J]. IEEE Transaction. on Pattern Analysis and MachineIntelligence, 2014, 36(4):715-730
[11] DEAN J, CORRADO G S, MONGA R, et al. Large Scale Distributed Deep Networks[C]// Proceedings of the 26th Annual Conference on Neural Information Processing Systems. Canada, 2012: 1223-1231
猜你喜歡
江蘇安全生產(2022年7期)2022-08-24 02:11:52
世界科學技術-中醫(yī)藥現代化(2022年3期)2022-08-22 00:32:50
北京測繪(2022年6期)2022-08-01 09:19:06
選煤技術(2022年2期)2022-06-06 09:13:12
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
山東農業(yè)工程學院學報(2019年11期)2020-01-19 02:49:22
傳媒評論(2019年4期)2019-07-13 05:49:14
