大數據在商業銀行反洗錢的應用
2016-04-08 06:18:05周彩冬潘維民
軟件 2016年2期
周彩冬++潘維民


摘要:隨著電子商務和移動互聯網的發展,數據流量的持續增長和以雙十一為代表的多種數據洪峰的出現,給商業銀行傳統的反洗錢手段帶來了巨大的壓力。海量交易數據下隱藏著各種洗錢行為,傳統的反洗錢方式在應對持續增長的數據時越來越捉襟見肘。當前,大數據技術的發展為海量數據數據的收集、存儲、處理等提供了技術支撐。本文分析了商業銀行的反洗錢業務需求,從業務的角度對比研究當前大數據領域眾多新技術,提出了一套實用、可擴展的反洗錢處理架構,并且提出了的大數據反洗錢的演進方向。
關鍵詞:計算機應用技術;反洗錢;大數據;商業銀行
中圖分類號:TP31
文獻標識碼:A
DOI: 10.3969/j.issn.1003-6970.2016.02.001
引言
洗錢行為給國家和社會帶來了巨大損失,我國從上世紀末就開始從國家層面實施反洗錢建設,并且參考國際經驗總結了諸多反洗錢策略。但是隨著金融業的快速發展和金融領域信息化的不斷深入,數據量的增長和新興金融產品的不斷推出,傳統的反洗錢方式在處理能力和處理精度上越來越不能滿足需求,所以商業銀行需要使用新技術來提升自己的反洗錢能力。本文介紹了反洗錢現狀和大數據相關技術及其優勢,分析對比了當前大數據領域的一些適用技術,并且結合商業銀行的業務情況提出了一套實用的大數據反洗錢架構,最后總結了大數據反洗錢的一些發展方向。
1 反洗錢現狀
在21世紀初,為了適應國際反洗錢形勢,我國反洗錢工作逐步開展,反洗錢監管體系從無到有,逐步建立起來。但是,當前反洗錢的形勢依然很嚴峻。根據中國人民銀行發布的《中國反洗錢報告2013》的統計,2013年人民銀行共發現和接收4854份洗錢案件線索,中國反洗錢監測分析中心全年向公安部等部門主動移送和協查反饋數量超過前兩年總和。最近幾年,隨著走私、毒品、貪污賄賂等犯罪不斷曝光,非法轉移資金活動大量存在,對洗錢行為的預防監控愈發顯得重要。
由于洗錢行為大多以商業銀行作為操作平臺,因而商業銀行在反洗錢方面具有重要的基礎性作用,商業銀行有能力也有義務對客戶身份、客戶交易行為進行識別,完成反洗錢工作的初篩工作。如果銀行在反洗錢方面工作不利,不僅會對銀行造成經濟還有聲譽的損失,更會影響反洗錢當局的對于洗錢行為識別,造成國家層面的經濟損失,影響國家的聲譽。
同時,隨著數字化信息時代的來臨,網絡交易和移動支付的數量不斷上升,越來越多、越來越詳細的交易數據對傳統的反洗錢處理方式構成了挑戰,單純的升級硬件或軟件已經無法應對可預期的數據量的瘋狂增長,因而商業銀行需要新技術來確保未來的反洗錢工作能準確高效地進行。大數據處理技術的發展為商業銀行提供一個可靠的解決方案。
2 大數據簡介
大數據(big data),是指無法在可承受的時間范圍內用常規軟件工具進行捕捉、管理和處理的數據集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的信息資產。在維克托·邁爾一舍恩伯格及肯尼斯·庫克耶編寫的《大數據時代》中,大數據是指不用隨機分析法(抽樣調查)這樣的捷徑,而采用所有數據進行分析處理。大數據的SV特點:Volume(大量)、Velocity(高速)、Variety(多樣)、Value(價值)和Veracity(準確性)。
隨著移動互聯網、物聯網、社交網絡和云計算等領域的發展,大數據技術在眾多的領域得到了應用并推動了這些領域的發展。比如,在商業領域,沃爾瑪公司通過分析銷售數據,了解顧客購物習慣,得出適合搭配在一起出售的商品;在公共衛生領域,谷歌通過對最頻繁檢索的詞條和美國疾控中心在2003年至2008年間季節性流感傳播時期的數據進行了比較,預測了2009年冬季流感的傳播;在社會安全管理領域,美國麻省理工學院通過對某地區十萬多人的SNS等信息進行處理,提取人們行為的時空規律性,進行犯罪預測。大數據技術的運用,給人類帶來了更多的想象。
雖然有些數據處理技術已經出現,然而在一段時間內它們只為調查局、研究所和世界上的一些巨頭公司所掌握,但隨著開源軟件的發展,以Hadoop為代表的數據處理技術和系統得以不斷的發展和完善,并且在諸多領域中得以運用,極大地推動了各個產業的發展。眾多大公司和研究所都在研究和使用Hadoop平臺,并且針對各個細分領域貢獻了更多實用的組件,使得Hadoop生態圈更加完善。
商業銀行每天都會產生大量的交易數據和客戶信息,使用大數據處理技術來實施反洗錢,對于商業銀行保證反洗錢職能、提升反洗錢效率、降低反洗錢成本等方面有著重大的意義。
3 大數據反洗錢的優勢
使用大數據技術實現反洗錢,將大大提升商業銀行的反洗錢處理能力,跳過計算能力的瓶頸。當前,商業銀行傳統的反洗錢方式是依據《金融機構大額交易和可疑交易報告管理辦法》,對交易數據進行計算,若交易數據符合大額交易或者可疑交易標準,就將該數據報送反洗錢監管機構。商業銀行一般使用Oracle等傳統的關系型數據庫進行數據的計算分析,由于傳統關系型數據庫的擴展能力有限,數據處理能力只能通過提升硬件性能來實現有限提升,無法應對越來越大量的交易數據。大數據處理技術能實現橫向擴充計算能力,在處理能力、擴充能力、成本等方面有巨大優勢。當前,基于關系型數據庫的反洗錢操作都是通過SQL來實現的,大數據平臺有Hive、Spark SQL、Dremel等實現SQL接口的大數據處理工具,對于技術方案切換成本和技術學習成本都能有很好的控制。
大數據技術也讓反洗錢有更多的提升空間。傳統的關系型數據庫需要滿足范式等約束,一般只能處理結構化的數據。大數據技術支持非結構化的數據,同時配合強大的存儲能力能收集記錄更多維度的數據,在對交易數據計算的時候可以避免樣本計算帶來的缺陷,使用完整的數據進行計算分析提升反洗錢的效果。由于擁有強大的計算能力和存儲能力,反洗錢的識別可以突破《金融機構大額交易和可疑交易報告管理辦法》中相關規則的限制,提供更加細致的識別方案,比如可以針對每個客戶的歷史數據,對比每筆交易,統籌考慮時間、地點、金額、流向、頻繁程度等要素,理解相關交易行為的特點,配合離群值分析等機器學習算法,進而提升可疑交易的識別準確率。
4 大數據反洗錢的設計
4.1 反洗錢業務需求
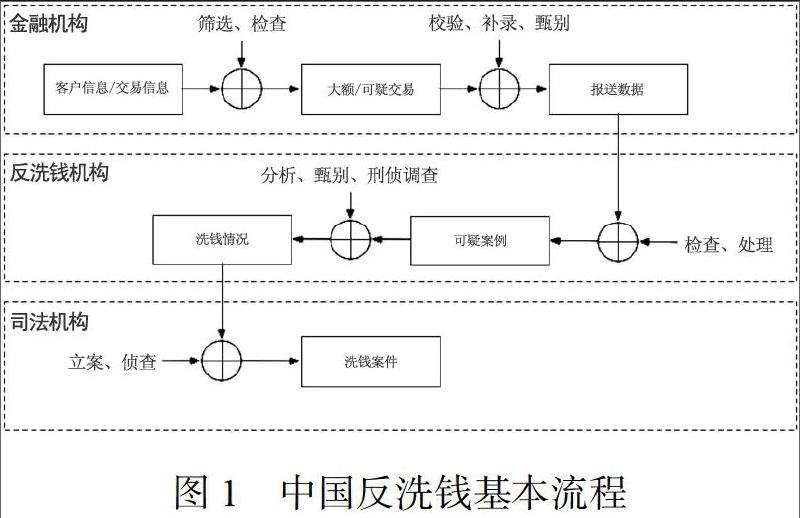
中國反洗錢工作具有多部門協作的特點,商業銀行反洗錢工作只是其中一部分。完整的反洗錢工作流程包括:客戶和交易信息收集及篩選、大額和可疑交易分析及甄別、大額和可疑報告報送、數據匯總檢查及預處理、可疑交易甄別及行政調查、移交司法立案偵查等環節(見圖1),并由各商業銀行、人民銀行反洗錢機構和司法機構分別承擔,形成反洗錢工作的完整閉環。
當前大多數商業銀行都是采用Oracle、MySQL等傳統的關系型數據庫作為數據處理的主要T具,然而隨著信息數據的增長和數據分析的需求的轉變,傳統數據庫遭遇諸多瓶頸,比如數據量增長過快,導致運算效率下降;數據抽取處理的代價過高,無法在統一的視圖下處理;無法處理多種類型的數據;不具備進行搜索或關聯分析以發現隱藏關系的能力;不具備數據挖掘等高級分析的能力等等。大數據相關技術的發展為商業銀行快速精準分析數據提供了解決方向。
目前,商業銀行的數據分析一般是基于傳統的數據倉庫,考慮到技術演進的漸進性,需要對反洗錢處理的前后端兼容,同時兼顧使用的便捷性和穩定性,所以使用大數據數據倉庫來實現;考慮到今后反洗錢策略的升級,新系統也需要為策略升級留下擴展接口。
《金融機構大額交易和可疑交易報告管理辦法》規定,金融機構應當在大額交易發生后的5個T作日內,在可疑交易發生后的10個工作日內以電子方式報送相關報告到中國反洗錢監測分析中心。上報的時間比較寬裕,在線處理和離線處理都可滿足需求。
4.2 技術方案比較
4.2.1 數據采集技術
機構信息、員工信息、客戶信息、賬戶信息、牌價匯率信息、本外幣交易信息等數據的采集是由商業銀行的業務柜臺等直接和用戶交互的機構錄入到系統的,是典型的聯機事務處理(OITP),傳統的關系型數據庫和新興的NoSQL都是備用方案。下表對關系型數據庫和NoSQL數據庫做了對比:
從上表可以看出,關系型數據庫和NoSQL具有不同的適用場景。商業銀行的交易數據相對來說模式比較固定,沒有大量的非結構化數據,單純OLTP場景下處理能力也完全能滿足需求,同時,銀行現有的業務系統也是基于傳統關系型數據庫,所以數據采集主要還是依靠傳統的數據庫來完成。客戶數據是非常冗雜的數據,當前商業銀行記錄的數據主要是交易相關的固定模式的數據,但是用戶數據是非常具有挖掘價值的,隨著用戶數據分析策略的升級,會有很多非結構化的數據作為補充,所以客戶數據可以逐步采用Apache HBase等NoSQL數據庫,增加對非結構化數據的支持,為在大數據平臺上實施客戶評級、風險監控等策略的升級提供接口。
4.2.2 數據分析技術
實現大數據反洗錢,最主要的就是在交易數據中識別洗錢行為。中國人民銀行對商業銀行的反洗錢的要求就是識別和報送大額交易和可疑交易,使用SQL的方式進行反洗錢數據處理,是便捷有效的方式。反洗錢相關需求的實施是典型的聯機分析處理(OIAP),當前基于大數據平臺的OLAP方案主要有Apache Hive、Dremel clones、Spark SQL三種。在技術方案選型時,當前技術的成熟程度、開源分支的活力和技術演進的方向都需要考慮,需要從趨勢上避開一些不具發展潛力的技術,比如之前的Shark。
Apache Hive最初由Facebool公司創建,是第一個基于Hadoop之上的SQL引擎,且至今仍是最成熟的。Hive主要解決的問題就是為開發人員提供SQL方言來存儲和處理Hadoop集群中的數據,封裝了復雜的編程任務,方便在海量靜態數據上做離線分析處理。到目前為止,Hive擁有最完整的SQL功能支持、最為穩定,并且也是擁有最多貢獻者的項目,事實上大多數SQL引擎都以這種或那種方式依賴于Hive。Hive最初是構建在MapReduce之上的,運行穩定但是耗時較多。Hortonworks于2013年提出Apache Tez引擎以提高Hive性能,Tez使用數據流(Dataflow)的方式避免了MapReduce中間結果的寫磁盤讀磁盤的性能瓶頸,提高數據分析的效率。Hive社區于2014年推出了Hive on Spark項目(HIVE-7292),并且在Hive l.1版本中正式推出。Hive on Spark在設計時盡可能重用Hive邏輯層面的功能,從生成物理計劃開始,提供一整套針對Spark的實現。在Hive l.l及以后的版本,MapReduce、Tez、Spark三個引擎可以自由切換。
2010年,Google公開了《Dremel:InteractiveAnalysis of WebScaleDatasets》一文,提出了PB級數據規模上的“交互式”數據分析系統。在PB級數據規模上,Hive使用MapReduce作為引擎執行數據處理需要分鐘級時間,Dremel只需要秒級。Dremel論文公開后,外部有很多克隆版本,比如Facebook Presto、Cloudera Impala和Apache Drill. Dremel Clones沒有再使用緩慢的Hive+MapReduce批處理方式,而是通過使用與商用并行關系數據庫( Parallel DatabaseSystem)中類似的分布式查詢引擎,可以直接從HDFS或HBase中用SELECT、JoIN和統計函數查詢數據,從而大大降低了延遲。然而,由于流式傳輸過程中,中間數據都保存在內存中,當數據量過大內存無法容納時,查詢就會失敗。Dremel Clones適用于原型階段的快速數據分析和模型建立,不適合有復雜處理邏輯的計算,不適合大數據量的計算。
Spark是一個通用的大規模快速處理引擎,Spark完全跳出 MapReduce的處理模型,將數據集緩存在內存中,并用Lineage機制容錯,其彈性分布式數據集(Resilient Distributed Datasets)也提供更豐富的編程接口。總體而言,Spark為我們提供了一個全面、統一的框架用于管理各種有著不同性質(文本數據、圖表數據等)的數據集和數據源(批量數據或實時的流數據)的大數據處理的需求。Spark在SQL方面的發展最早是基于Hive的Shark,由于Shark對于Hive有太多依賴(查詢優化、語法解析等),性能提升遭遇瓶頸,2014年Spark Submit上Databricks宣布放棄了的Shark的開發,從此Spark上的SQL就分成兩個路線:Spark SQL和Hiveon Spark。Hive on Spark可以認為是前端Hive后端Spark,基于MR或Tez的Hive既有用戶可以在原系統與Hive on Spark系統之間輕松切換,切換工作僅僅只需要簡單地修改下配置參數。Spark SQL是一個完整的新引擎,Spark SQL團隊吸收Shark的優點重新開發了Spark SQL代碼,使得Spark SQL無論在數據兼容、性能優化、組件擴展方面都得到了極大的提升。Spark SQL在2015年5月的1.3的版本中才走出“Alpha”狀態,是全新的平臺,相對于Hive在功能豐富性和穩定性上還有很多不足。
綜合分析各個數據處理平臺,結合商業銀行高穩定性、高可用性需求以及大量交易數據和充足的離線運行時間的實際情況,選用至今最成熟的Apache Hive是商業銀行的最佳選擇。Hive支持MapReduce、Tez、Spark三大引擎,在運行效率和運行穩定性之間有比較大的選擇空間。Dremel Clones可以作為輔助分析工具,幫助調研調試新的反洗錢規則。同時,Spark SQL發展迅速,也可能成為今后的最佳選擇。
4.2.3 數據存儲技術
大數據平臺的數據存儲主要是HDFS和HBase兩種。雖然HBase的底層也是基于HDFS,但是在許多特性上和HDFS是有明顯的區別的。
由于HBase是基于HDFS的,所以HBase也擁有HDFS的高吞吐量、高可伸縮性等特點。實質上,HBase就是在HDFS的基礎上增加了基于內存的緩沖區并調整數據查找方式。HBase適用于數據存儲和搜索,但是對于數據分析,性能會比HDFS差一些,因為HDFS上典型的訪問是順序I/O,而HBase上的訪問有服務器的socket連接資源消耗和對底層多個文件的合并過程。當前,有Apache Kudu這樣的項目來兼顧數據掃描、隨機訪問和數據分析的高性能,避免額外的數據移動,但是該項目正在處于孵化階段,暫時無法在項目中運用。
商業銀行反洗錢的主要數據源是交易數據,輔助數據源為客戶、賬戶信息;同時在數據的ETL處理階段,有碼值映射表等輔助數據。銀行每天業務結束后,會將數據導入到HDFS中,以供分析。交易數據是確定不變的數據,可以使用HDFS來存儲;對于客戶數據等可變數據,可以使用HBase存儲,在運行時加載到HDFS中以提高分析速度。如果不考慮非結構化和半結構化的數據,可以不用HBase直接將所有原始數據存入關系數據庫然后統一導入HDFS。 文件存儲格式對于數據分析的效率也有很大影響。目前,Hive支持的幾種主要的數據格式如下:
相對于純文本格式和面向行的二進制格式,面向列的二進制格式性能消耗較大,但是具有較好的壓縮比和查詢響應;同時ORC和Parquet還增加了數據的塊統計,能有效減少數據分析的時間。反洗錢業務需要大量的數據分析,所以分析時采用ORC格式具有比較好的效果。在數據倉庫中,數據會進行分層,不同的數據層應該根據實際采用不同的數據格式。
數據存儲文件也需要配合文件壓縮來減少占用的磁盤空間并加速數據在網絡間的傳輸。在反洗錢處理情景中,主要數據都是交易記錄,使用壓縮比和壓縮效率比較均衡的LZO或者Snappy皆可。
4.3 大數據反洗錢的應用
4.3.1 大數據反洗錢的架構設計
通過對反洗錢的業務研究和各個數據處理階段相關技術的對比研究,確定使用MySQL+HBase的方式來進行數據采集(不考慮非結構化數據可以全部使用MySQL);使用HDFS+HBase的方式實現數據存儲。結合反洗錢的實際業務,對反洗錢整體的架構設計如下:
MySQL集群中存儲每天的交易數據和客戶數據,同時維護著一份反洗錢的配置文件。每天業務結束后,將MySQL中的數據導入到Hadoop處理平臺中。Hadoop環境中主要是使用Apache Hive作為數據倉庫,在Hive中進行ETL操作,將數據整理轉換為反洗錢計算的輸入,然后進行反洗錢的數據計算。最后將計算得出的預警結果導出到MySQL中。
就具體的數據分布而言,MySQL主要用于當前操作型事務和少量在線數據應用,其主要存儲系統基礎數據、元數據、當前處理數據(補錄數據、案例處理、報告信息等)等數據。Hadoop是作為數據處理平臺(Hive)和數據歸檔平臺(HBase),主要存儲海量指標數據和歷史數據(交易、報告、客戶/賬戶、評級歷史、日志等)。Hive作為基于Hadoop的數據倉庫,具有天然的易于擴充的海量數據存儲能力,所以存儲了所有歷史數據,但是基于Hive的查詢操作會很慢,所以使用HBase來輔助查詢。具體的數據流如下:
Hive相關的部分,是整個系統的數據處理中心,包括ETL和規則計算。數據源是銀行的業務系統每天產生的基礎數據,導出到Hadoop文件系統上;Hive通過Load命令將數據文件加載進入到貼源層,貼源層與源系統結構一致。數據加載到HDFS后,需要進行ETL轉化,主要使用HQL語言進行數據整理,最終在Hive中生成標準數據接口,然后將數據導入HBase,以供應用訪問。標準數據接口中的數據是全部數據,使用合適的過濾規則將當日規則計算需要的數據從標準數據模型中取出來,以縮小需要訪問的數據范圍。然后就可以進行反洗錢核心環節的處理,進行大額和可疑規則的計算,并且生成預警結果,最后將預警中間結果寫到MySQL。
每天的預警結果生成以后,需要在Mysql中對生成的預警結果進行案例生成,數據校驗等操作,其中并對部分數據進行補錄。對經過在MySQL中補錄的業務數據,如客戶信息、賬戶、交易信息,歸檔到Hive中的標準數據接口中,再同步到HBase中。對經過在MySQL中補錄、認定、報送已經接收過回執的數據,同步到Hive的歷史庫中,再同步到HBase中的歷史庫中。
前臺訪問主要涉及下面三個操作,日常的補錄、案例分析、報告及報送工作在MySQL中操作;對于查詢交易、賬戶、客戶等大數據量數據訪問HBase,通過服務接口;對于歸檔的歷史數據,通過服務接口訪問HBase。
4.3.2 大數據反洗錢計算實現
具體的反洗錢計算如3所示,涉及的過程是從“標準數據接口”開始,到生成“預警結果中間表”結束。主要的計算邏輯就是《金融機構大額交易和可疑交易報告管理辦法》中規定的4條大額規則和18條可疑規則,使用HiveQL根據客戶數據和交易數據的特征來識別可疑數據。
在計算過程中,由于數據量巨大,全部計算會浪費過多資源,所以需要根據反洗錢的計算規則提煉出一些過濾規則以減少待計算的數據量。當前使用的是以客戶為中心的篩選過濾規則,具體的過濾邏輯如下:
首先根據當天的交易流水過濾出所有出現過的客戶ID(包括對方客戶),然后計算回顧周期,最后根據回顧周期從歷史數據中篩選出回顧周期內需要計算的數據。以客戶為基準過濾非計算數據,可以有效的避免計算資源的浪費。
反洗錢的計算過程中,描述性的規則在實施過程中需要量化。一條規則在量化后,會劃分成對公規則/對私規則、本幣規則/外幣規則等多種不同的子規則。大多數描述可以通過簡單的屬性劃分來完成,但是有些描述無法通過簡單的劃分來實現。以中國人民銀行的可疑規則第五條為例:與來自于販毒、走私、恐怖活動、賭博嚴重地區或者避稅型離岸金融中心的客戶之間的資金往來活動在短期內明顯增多,或者頻繁發生大量資金收付。“短期內資金往次數明顯增多”這種行為的識別需要和前期的數據比較得到,然而每次計算時都統計歷史上的交易次數明顯是很低效的。為此,設計了資金收付偏移比這一指標:
短期內日平均交易次數
資金收付偏移比=——————————
長期日平均交易次數+1
其中,“短期”和“長期”都是可調控參數,針對對公用戶和對私用戶等不同用戶有不同的時間設置。由于分母是日平均交易次數,可能是遠小于1的值,這樣的值會將偶爾出現的交易放大而出現失真,所以添加了基數1來控制敏感度。實際的資金收付偏移比的閾值和上面所列出的指標一樣,也是在參數表中動態配置的,默認的偏移比閾值是3。長期參數可以定期計算保存,這樣每次計算短期的日平均交易次數既可以獲得資金收付偏移比,“短期內資金往次數明顯增多”可表示為資金收付偏移比大于閾值,大大減少計算量。在實際的反洗錢計算中,還有新賬戶指標、賬戶活躍度指標等,都是為了降低計算復雜度而設立的,在此就不全部列舉。
5 反洗錢發展展望
隨著信息科技的發展,互聯網金融等眾多新興的交易模式逐漸增多,這些新技術在方便普通用戶的同時,也給不法分子提供了新的洗錢手段。因此,作為反洗錢前沿陣地的商業銀行更需要提升反洗錢的能力,保證金融市場的有序穩定。商業銀行提高反洗錢能力,一方面是反洗錢平臺技術的提升,提高數據處理能力;另一方面就是反洗錢識別策略的提升,提高數據處理的效率。
在平臺技術方面,通過上文的對比分析,可以看出當前大數據技術已經從具有處理能力向具有快速處理能力發展,越來越多的考慮使用內存、固態硬盤等硬件睞加速執行過程。MapReduce、類分布式搜索引擎、Spark等諸多技術的發展,提供越來越高效的數據分析手段。當前,類似Kudu、Spark SQL等部分新的技術尚處在初期發展階段,暫時不能在商業銀行這種對穩定性要求比較高的隋況下使用,但是將來肯定會是數據處理的有力擴充。本文采用的是離線的處理方式,針對反洗錢的部分規則,可以采用Storm等流式計算引擎來完成在線實時分析計算,如果能在秒級別識別洗錢行為,那么對于整個反洗錢生態都是顛覆性的。
在反洗錢識別策略方面,商業銀行傳統的反洗錢監控上報都是基于《金融機構大額交易和可疑交易報告管理辦法》,這一套方式是對過去反洗錢手段的總結,在應對眾多新型交易方式,難免有疏漏之處。升級反洗錢識別策略,主要就是引入分類、估計、預測、關聯規則、聚類、描述和可視化等數據挖掘技術,從大量數據中揭示J葉J隱含的、先前未知的并有潛在價值的信息。增強對客戶的風險控制,避免顯性檢測規則的弊端,降低反洗錢的識別成本,提升反洗錢執行效率。本文的反洗錢架構給反洗錢識別策略的升級預留了接口,可以使用機器學習組件Apache Mahout在HDFS上直接調試部署;也可以使用Hivemall直接基于Hive進行算法的訓練部署;也可以使用基于Spark的機器學習系統MLbase及底層的分布式機器學習庫MLlib來進行反洗錢新策略的訓練升級。盡管近年來在反洗錢識別策略方面的研究取得不少進展,但總體來講‘框架研究多,具體方法研究少;理論研究多,結合具體場景研究少”,目前并沒有切合實際的方案,但這是反洗錢的必然發展方向。
6 結語
隨著全球經濟信息化不斷加快,洗錢犯罪也呈現出更加多變、隱蔽的特點。商業銀行作為反洗錢的前鋒,承擔著反洗錢工作的重要職責。大數據時代的海量數據不僅給商業銀行的反洗錢帶來巨大壓力,同時也給整個金融市場帶來了全面提升反洗錢效率的契機。
本文從當前商業銀行的反洗錢技術在數據處理能力不足的角度出發,分析了商業銀行的反洗錢業務需求,并對比總結了當前大數據相關技術在反洗錢場景下的優缺點和適用情況,根據實際的業務情況提出一套實用的可擴展的大數據的反洗錢處理框架,并且在反洗錢計算部分提出了優化意見,最后討論了反洗錢發展的兩個方向。相信在不久的將來,大數據技術將和反洗錢碰撞出更多的火花。
猜你喜歡
大眾投資指南(2020年10期)2020-07-24 08:03:40
消費導刊(2017年20期)2018-01-03 06:27:21
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
湖南城市學院學報(自然科學版)(2016年4期)2016-02-27 14:02:56
山西大同大學學報(社會科學版)(2016年6期)2016-01-23 02:06:18
當代經濟(2015年4期)2015-04-16 05:57:02
現代企業(2015年6期)2015-02-28 18:52:13
