音頻哼唱檢索技術的設計與實現
2016-04-09 02:03:30天津廣播電視臺石家瑞
電子世界 2016年5期
天津廣播電視臺 石家瑞
?
音頻哼唱檢索技術的設計與實現
天津廣播電視臺 石家瑞
【摘要】通過文字輸入音頻屬性信息進行音頻檢索無法滿足通過音樂的旋律進行檢索的需求,因此基于內容的音頻檢索應運而生。研究、設計并實現一套基于內容的音頻哼唱檢索技術,對音頻進行分割處理,基音提取,旋律編碼和旋律匹配,完成音頻搜索。在實驗中,通過對輸入語音的處理、匹配,以85.5%的相似度成功檢索出目標音頻,為今后音頻哼唱檢索技術的實際應用提供依據和保證。
【關鍵詞】音頻;哼唱;檢索技術
0 引言
隨著數字化和網絡化的快速發展,音頻的檢索已經隨著大眾的需要從一維擴展到多維。傳統的音頻檢索需要用戶輸入音頻的屬性信息,包括名稱、演唱者、年代等文本信息進行檢索,然而用戶熟悉某些歌曲的旋律和風格,但是并不知道名稱和主唱,運用傳統的屬性信息進行檢索無法滿足他們的需求。因此,通過音頻內容進行檢索的方法應運而生。哼唱檢索作為基于內容的音頻檢索的一種,需要用戶哼唱某一段音樂,這段音樂作為一種非語義符號表示且非結構化的二進制碼流輸入到計算機中,通過搜索引擎去尋找一些歌曲,并將歌曲中包含用戶所哼唱的旋律和風格的歌曲反饋給用戶。
本文詳細研究并介紹了哼唱檢索的流程和所用方法,并通過程序演示,以實驗形式完成了哼唱檢索過程。
1 哼唱檢索流程
哼唱檢索的流程是:用戶通過一個麥克風哼唱一段音樂,這段音樂以音頻數據的方式被采集到了計算機里面,被分割成一個個片段,這些片段又分別對應了一個個的音符[1]。之后就能找出這些片段的基因頻率,獲得哼唱片段的旋律信息,將哼唱的旋律信息與音樂庫中音樂的旋律信息進行匹配比較,并將相關度最高的一首或幾首樂曲作為檢索結果返回給用戶,流程如圖1-1所示:
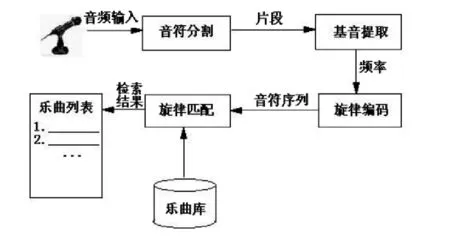
圖1-1 哼唱檢索流程
2 哼唱檢索方法
2.1音頻切割
音頻分割的方法是:在得到輸入信號的對數能量曲線之后,對其進行平滑處理,再由曲線的極值求出有聲區的能量閾值,接著就能根據音符的對應關系將輸入信號分割成小片段,圖2-1所示。
這種分割方法要求用戶在每個音符直接按留出一定的空隙,但這種要求不一定都會滿足,因為用戶發音不準或者哼唱的很連貫,各個音符之間沒有停頓,就無法在能量上來區別各個音符,這都會導致這種方法的失效或者不理想。但是人們通過實驗發現,音頻的倒譜的峰值隨著時間也有起伏,而且能夠反映出靜音和非靜音的邊界,如圖2-2所示,所以在進行音頻分割時一般綜合考慮能量曲線和倒譜峰值曲線,這樣能夠得到最好的分割效果[2],如圖2-3所示。

圖2-1 能量曲線以及音符分割結果

圖2-2 倒譜峰值曲線
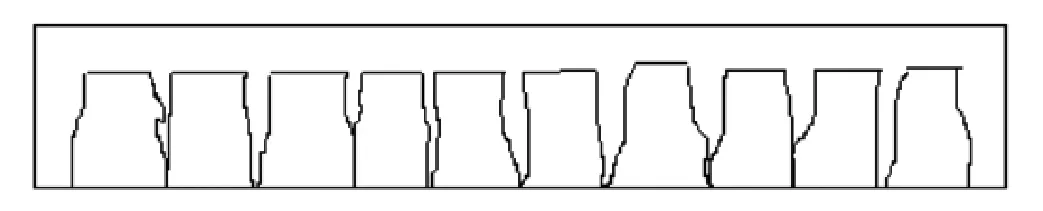
圖2-3 能量曲線和倒譜曲線綜合考慮的結果
2.2基音提取
音符分割完成以后,就要進行基音的提取了。人類聲音的頻率一般大于60Hz,而小于1000Hz,所以可以利用哼唱信號良好的周期性特性,采用時域的自相關方法,來求取每一幀哼唱信號的基頻信息,然后再將其轉換成半音單位[3]:
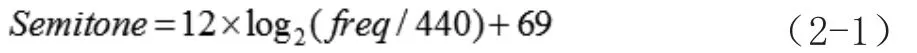
其中,freq是以Hz為單位的基頻值。
半音是音樂中常用的表示音高的單位,MIDI中所采用的音高表示也與此相同。接下來的計算方法所采用的音高單位都是半音。
一般一個音符都包含若干個幀,在得到每一幀的音高之后,可以采用加權求特征值的辦法來求得每個音符的特征值,比如一個音符由n幀組成,這些幀的編號為,則每一幀的權重系數為[4]:
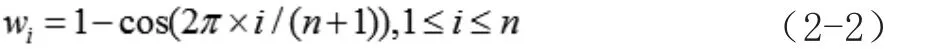
采用自相關算法對哼唱信號進行基音提取的流程如圖2-4所示。
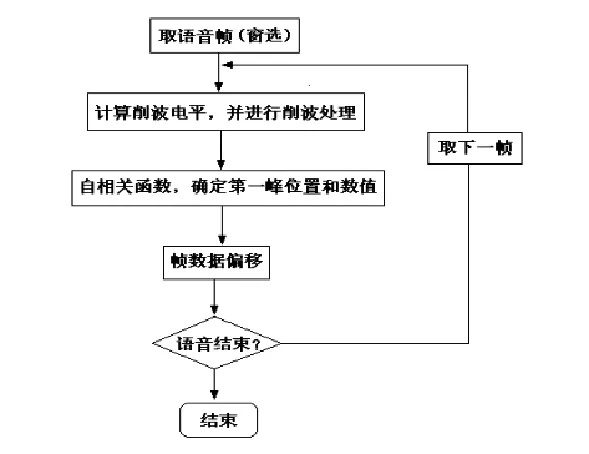
圖2-4 基音提取流程
一般情況下是用固定長度的窗來對語音信號進行分幀的,然后再計算每一幀的基音周期。但是漢語的語調會發生變化,因而基音周期的變化范圍也很大,如果用固定窗長來進行計算,得不到良好的短時特性。鑒于此,可以采用長度可變的窗來進行計算,因為相鄰幀的基音周期變化不大,所以可以把每一幀的窗長設為前一幀窗長的3倍。
2.3旋律編碼
在得到哼唱數據的基音信息之后,就需要根據各個音符的音高來進行旋律編碼了。旋律編碼是指在進行音樂檢索時,把輸入音頻以及音頻庫中的音頻的樂曲旋律用一種中間形式來表示出來,比如音符序列。旋律編碼完成之后,就可以采用這種中間形式的數據來進行匹配計算了[5]。
為了降低檢索的難度,在進行旋律編碼時,可以在音高這個檢索特征之外再加上一個節奏特征,也即每個音符的時間信息,這樣一來使用雙特征來進行檢索,效率更高,困難程度也降低了。根據一般人的哼唱特點,在采用節奏信息時,只考慮每個音符的出現時間,而不考慮它們的結束時間。
2.4旋律匹配
旋律編碼完成之后,就可以進行旋律匹配了,線性對齊匹配法的具體思路是[6]:先把兩段旋律在時間軸上伸展到相同的長度,然后把它們發聲時刻接近的音符對齊,分析旋律在節奏上的相似性之后,繼續比較兩段等長旋律在每個時間點上音高頻率的距離。因為采用的是音高差值來作為檢索特征的,所以就可以忽略哼唱者的音調高低問題。然后把節奏和音高兩方面的信息綜合考慮就能夠很容易得到相似度的匹配結果了。
因為檢索特征是節奏和音高的組合,假設為(P,T),經過旋律編碼得到的旋律序列為,而音頻庫中的旋律為。其中,P和Q表示音高差,T和U表示音符發聲時刻,而且:
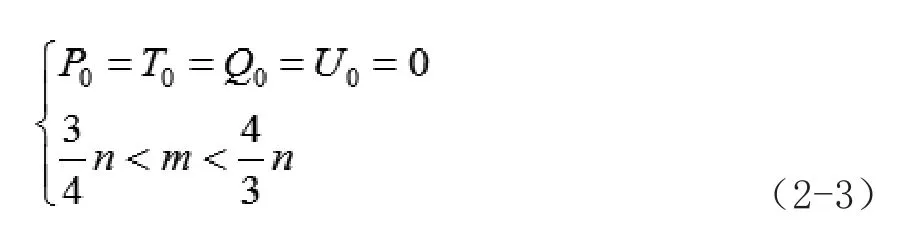
(2-3)中第一個式子可以通過前面的說明很容易的得出,第二個約束條件規定了兩段旋律的音符數不能相差過多。
2.4.1節奏匹配
在進行節奏匹配時,首先要將(P,T)在時間上進行線性變換,和(Q,U)對齊,然后通過對齊的音符總數占總音符數的比例來確定兩段旋律在節奏上的相似度。假設變換后的音符序列為(R,V),其算法如下[7]:
①初始化:
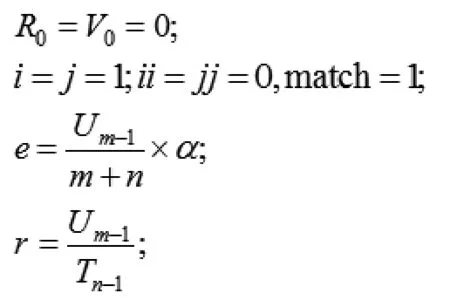
②線性變換:
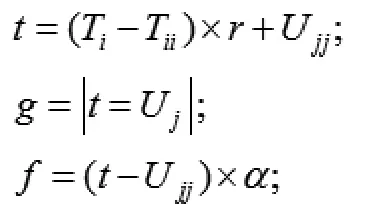
③對齊判斷:
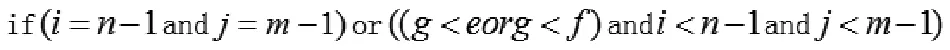
跳轉到④,否則跳轉到⑤。
④將(P,T)的第i個音符與(Q,U)的第j個音符對齊。
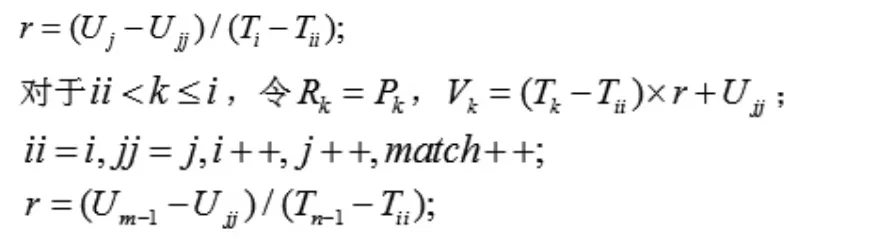
跳轉到⑥。
⑦計算節奏相似度,結束。
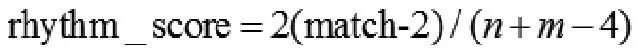
對齊的音符數占總音符數的比例就是節奏上的相似度。一般情況下旋律的首尾音符都是對齊的,所以計算時把首尾的4個音符去掉。其中的a表示對齊誤差,經驗值為0.3。也就是說如果兩個音符在時間上的距離小于其音符延時的30%,就可以認為它們是對齊的[8]。
2.4.2高音匹配
節奏匹配完成后,就可以進行音高的匹配了。經過上面的運算,(P,T)轉換成(R,V),其中(R,V)和(Q,U)在時間上完全等長。音高的匹配過程就是比較(R,V)與(Q,U)在對應時刻上的音高差值。和節奏相似度一樣,音高的相似度也是根據音高接近的旋律片段占總旋律的比例得到的。其計算過程如下:
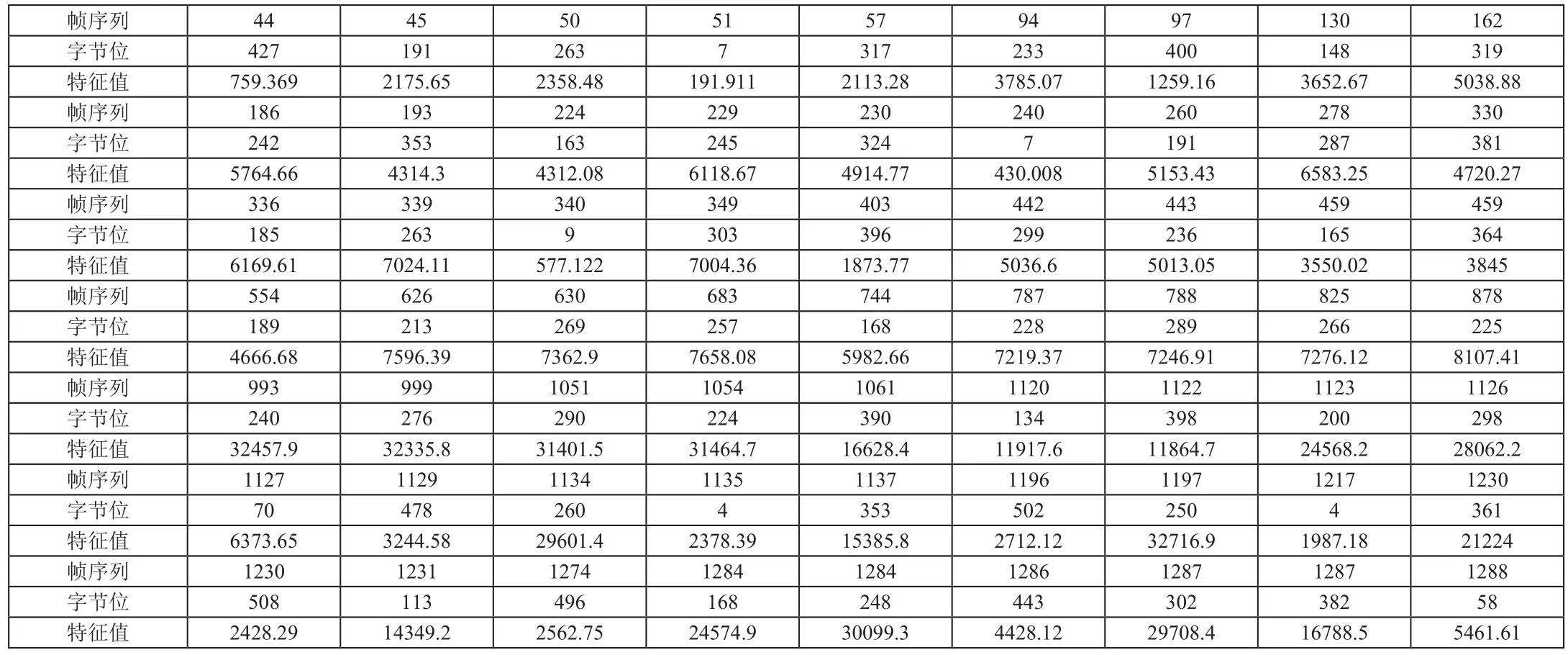
表3-1 輸入音頻的特征序列表
①初始化。
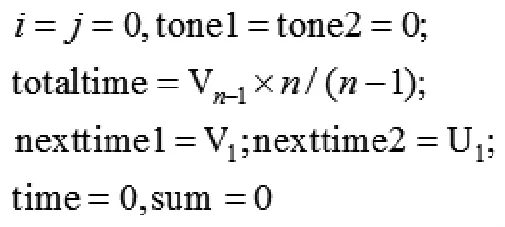
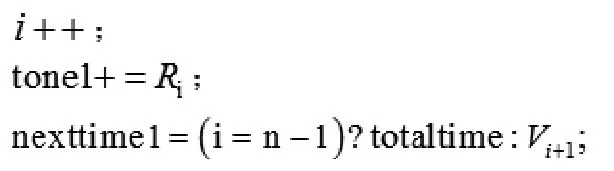
跳轉到②;
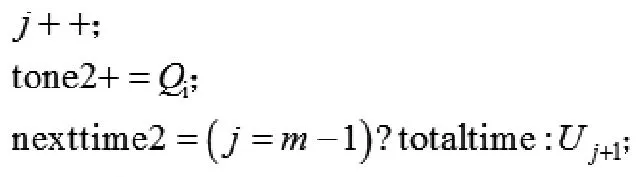
跳轉到②;
⑤計算音高相似度,結束。
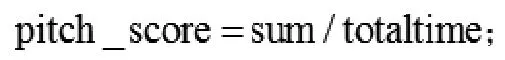
旋律的節奏信息只是記錄了音符的開始時間,并沒有記錄它的持續時間或結束時間,因此最后一個音符的長度一般設定為前面音符的長度的平均值。其中函數的定義如下:
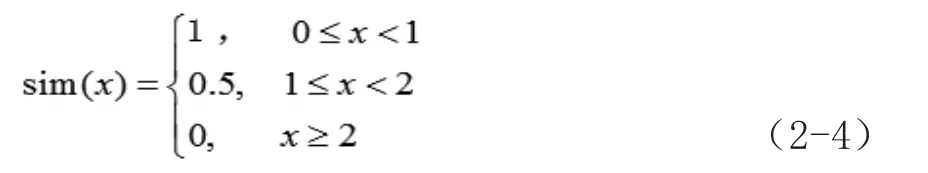
節奏匹配和音高匹配完成之后,把它們的數值相加,就能得到兩段旋律的總匹配度:
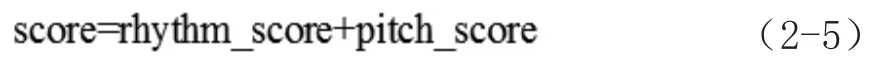
至此,哼唱檢索的所有算法都已完成,只要將哼唱輸入的旋律信息與音頻庫中的音頻的旋律信息進行匹配比較,并將其中匹配程度最高的幾首音頻作為最終結果反饋給用戶,就完成了了一次完整的哼唱檢索。
3 實驗分析
3.1實驗準備
音頻檢索程序是在Microsoft Visual Studio平臺下用C++語言開發的一套對輸入音頻特征序列提取、特征值比對的程序,通過該程序可檢索出與輸入音頻特征匹配的目標音頻,以完成搜索任務。
測試音頻均為WAV格式。從話筒哼唱一段音樂并保存,記錄音頻為test-fragment.wav,該音頻作為音頻檢索的輸入數據源。樂曲庫中保存了大量WAV格式的樂曲和音頻,作為檢索庫中的被檢索數據源。
3.2實驗過程
從輸入音頻提取特征值,整理成特征值序列表,與樂曲庫中的各個樂曲特征序列表比對,找到相似度最高的樂曲,即為檢索結果。
首先,對輸入音頻進行分割,以512Byte為一個片段,輸入音頻被分割成1347個片段,計算512bit×1347≈689kB,實際的輸入音頻為674KB,略小,原因是在切割過程中每個片段加入了相應的校驗和序號信息,便于后續處理。
3.3實驗結果
經過FFT變換和轉碼等一系列過程,提取出輸入音頻的特征值如表3-1所示。
表3-1列出了輸入音頻的特征值序列。其中,“幀序列”表示提取特征值所在的片段,位數從1至1347;“字節位”表示在該幀序列中所在的字節位,位數從1至512;“特征值”表示相應的能量特征值。
從樂曲庫中每條歌曲對應的特征序列表,與輸入序列按照指定的幀序列的字節位進行比對,找到與相應字節位特征值差異最小的特征序列,該特征序列所對應的樂曲即為檢索結果。圖3-1列出了檢索音頻幀序列誤差分布。大部分誤差集中在20%以內,少數誤差高達50%,出現誤差的原因是由于哼唱音頻的音調、音色、節奏因個人嗓音的不同和節奏的把控而產生差異。誤差平均值為14.5%,即音頻相似度達85.5%。而音頻的檢索結果也正是哼唱者所要查找的音頻。
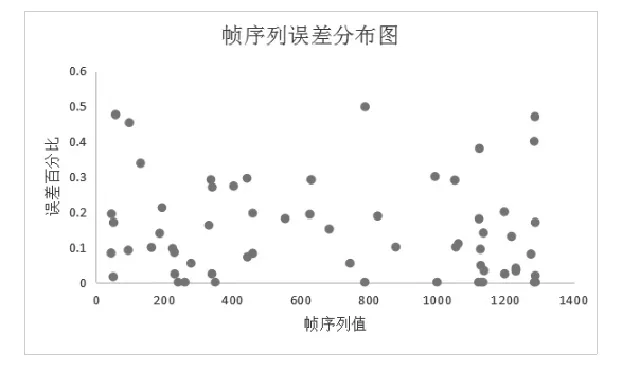
圖3-1 音頻幀序列誤差分布圖
4 結束語
基于內容的音頻哼唱檢索,實現了將音符分割成若干片段,對每個片段進行基音提取,對提取出的頻率進行旋律編碼形成特征值序列,并與樂曲庫的歌曲進行特征值序列匹配,返回檢索結果。通過編寫程序并運行音頻實例,實現了基于哼唱的音頻檢索實驗,匹配率高,為今后哼唱檢索在實際中的應用提供依據和保證。
參考文獻
[1]潘復平,趙慶衛,顏永紅.一個基于語音識別的音頻檢索系統的實現[J].聲學技術增刊,2005,24:428~432.
[2]歲駿,歐智堅.一種高效的語音關鍵詞檢索系統[J].通信學報,2006,27(2):113~118.
[3]A.V.奧本海姆,R.W.謝弗.數字信號處理(董士嘉,楊耀增)[M].北京:科學出版社,1980,45~46.
[4]Reynolds DA,Rose RC.Robust.Text-independent Speaker Identification Using Gausian Mixture Speaker Models.IEEE Speech and Audio Processing,1995(1):72~83.
[5]吳春輝,黃胤科,鐘寶榮.基于內容的音頻檢索技術[J].現代計算機(專業版),2006,4.
[6]L.A.Smith,R.J.McNab.I.H.Witten.Music Information Retrieval Using Audio Input.Proc AAAI Spring Symposium on Intelligent Integration and Use of Text, Image,Video,and Audio Corpora,Stanford,CA,1996:12~16
[7]R.J.McNab,L.A.Smith,I.H.Witten,C.L.Henderson,Cunningham S.J. Towards the Digital Music Library:Tune Retrieval from Acoustic Input.Proc Digital Libraries’96,1996:11~18.
[8]李國輝等,基于內容的音頻檢索與分類[J].計算機工程與應用,2002,(7):54~57.
石家瑞(1977—),男,天津人,高級工程師,現供職于天津廣播電視臺,研究方向:廣播電視工程。
作者簡介:
