基于Spark的Apriori算法的改進(jìn)
2016-04-11 02:54:10牛海玲魯慧民劉振杰
東北師大學(xué)報(bào)(自然科學(xué)版) 2016年1期
牛海玲,魯慧民,劉振杰
(長(zhǎng)春工業(yè)大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院,吉林 長(zhǎng)春 130012)
?
基于Spark的Apriori算法的改進(jìn)
牛海玲,魯慧民,劉振杰
(長(zhǎng)春工業(yè)大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院,吉林 長(zhǎng)春 130012)
[摘要]基于Spark大數(shù)據(jù)框架,將傳統(tǒng)Apriori算法進(jìn)行并行化處理,提出了一種改進(jìn)的并行化AMRDD算法,使Apriori算法能夠適用于大數(shù)據(jù)關(guān)聯(lián)規(guī)則的挖掘.該算法利用Spark基于內(nèi)存計(jì)算的抽象對(duì)象存儲(chǔ)頻繁項(xiàng)集,通過引入矩陣概念減少掃描事務(wù)數(shù)據(jù)庫(kù)的次數(shù),應(yīng)用局部剪枝和全局剪枝方法縮減生成候選頻繁項(xiàng)集的數(shù)量.通過搭建Spark平臺(tái)實(shí)現(xiàn)該算法,并與傳統(tǒng)Apriori算法和基于Hadoop的Apriori算法進(jìn)行性能上的比較. 結(jié)果表明,該算法能夠較大程度地提高大數(shù)據(jù)關(guān)聯(lián)規(guī)則挖掘的效率.
[關(guān)鍵詞]Apriori;Spark;矩陣;局部剪枝;全局剪枝
0引言
隨著大數(shù)據(jù)時(shí)代的到來,云計(jì)算技術(shù)的興起,如何從海量數(shù)據(jù)中高效地提取知識(shí)是目前急需解決的問題.同時(shí),人們?cè)絹碓疥P(guān)注數(shù)據(jù)挖掘技術(shù)在大數(shù)據(jù)環(huán)境下的應(yīng)用,很多學(xué)者在該領(lǐng)域進(jìn)行了改進(jìn)研究,如數(shù)據(jù)分類、聚類方面等[1-2].關(guān)聯(lián)規(guī)則挖掘作為數(shù)據(jù)挖掘的一個(gè)重要組成部分,在數(shù)據(jù)挖掘中扮演重要角色,作為關(guān)聯(lián)規(guī)則中的經(jīng)典算法Aprioi的地位更是舉足輕重.然而傳統(tǒng)的串行算法已經(jīng)不能滿足大數(shù)據(jù)時(shí)代的要求,因此新型的挖掘模式成為人們新的選擇.
近年來,隨著Hadoop和Spark等云計(jì)算平臺(tái)的開源化,采用云計(jì)算并行編程框架,將傳統(tǒng)的數(shù)據(jù)挖掘算法進(jìn)行分布式并行化處理,提高大數(shù)據(jù)挖掘的效率,已成為數(shù)據(jù)挖掘領(lǐng)域的一個(gè)熱點(diǎn).本文將經(jīng)典的Apriori關(guān)聯(lián)規(guī)則挖掘算法基于Spark框架進(jìn)行改進(jìn),提出了一種分布式并行化AMRDD算法,使之能夠適用于大數(shù)據(jù)關(guān)聯(lián)規(guī)則的挖掘.同時(shí),算法采用矩陣向量結(jié)構(gòu)減少掃描數(shù)據(jù)庫(kù)的次數(shù),應(yīng)用局部剪枝和全局剪枝策略減少候選項(xiàng)集的數(shù)目,從而提高大數(shù)據(jù)環(huán)境下Apriori算法關(guān)聯(lián)規(guī)則挖掘的效率.
針對(duì)Apriori算法需多次掃描數(shù)據(jù)庫(kù)和可能產(chǎn)生大量頻繁項(xiàng)集的缺點(diǎn),人們提出了很多改進(jìn)算法.包括基于概念格的頻繁項(xiàng)集挖掘算法、基于頻繁模式樹的分布關(guān)聯(lián)規(guī)則挖掘算法及在Apriori算法基礎(chǔ)上進(jìn)行改進(jìn)的算法.[3-5]
文獻(xiàn)[6]基于Hadoop平臺(tái)提出一種MapReduceApriori,該算法針對(duì)Apriori的一些缺陷和Hadoop在大集群中表現(xiàn)出的優(yōu)勢(shì),用HDFS來存儲(chǔ)數(shù)據(jù),以MapReduce方式實(shí)現(xiàn)并行處理,用于海量數(shù)據(jù)中發(fā)現(xiàn)頻繁項(xiàng)集,處理效率明顯比傳統(tǒng)算法高,且表現(xiàn)出很好的加速比;文獻(xiàn)[7]提出AprioriMMR算法,引入了矩陣的概念,通過矩陣與運(yùn)算計(jì)算項(xiàng)目集的支持度,結(jié)合MapReduce計(jì)算框架,改進(jìn)和優(yōu)化了頻繁項(xiàng)集的產(chǎn)生,在海量數(shù)據(jù)挖掘中大大提高了效率,不足之處是求解局部頻繁項(xiàng)集的過程無剪枝操作,生成的候選項(xiàng)集數(shù)目過大;文獻(xiàn)[8]基于MapReduce框架提出一種有效的關(guān)聯(lián)規(guī)則算法ScadiBino,該算法首先將數(shù)據(jù)離散化處理轉(zhuǎn)換為二進(jìn)制,其次通過N個(gè)mappers和一個(gè)reducer過程,直接得到關(guān)聯(lián)規(guī)則,而不是尋找頻繁項(xiàng)集,有效地降低了執(zhí)行時(shí)間.本文提出了一種改進(jìn)的并行化AMRDD算法,使Apriori算法能夠適用于大數(shù)據(jù)關(guān)聯(lián)規(guī)則的挖掘.
1基于Spark的Apriori算法改進(jìn)
Spark是一個(gè)通用的大規(guī)模數(shù)據(jù)快速處理引擎,主要提供基于內(nèi)存計(jì)算的抽象對(duì)象RDD,允許用戶將數(shù)據(jù)加載至內(nèi)存后重復(fù)地使用.Spark編程模型參考MapReduce,不同的是Spark基于內(nèi)存的計(jì)算特點(diǎn)在某些應(yīng)用的實(shí)驗(yàn)性能上超過MapReduce 100多倍.Spark平臺(tái)完全由Scala語言編寫,Scala是一種融合了面向?qū)ο蠛秃瘮?shù)式的編程語言,它專門為分布式而設(shè)計(jì),精簡(jiǎn)且具有并發(fā)的威力.
RDD的基本操作[9]包括轉(zhuǎn)換(Transformation)和動(dòng)作(Action).可通過Scala集合或Hadoop數(shù)據(jù)集構(gòu)造一個(gè)新的RDD,或通過已有的RDD產(chǎn)生新的RDD,例如map,filter,groupBy,reduceBy.Action是通過RDD計(jì)算得到一個(gè)或者一組值,例如count,collect和save.Spark中的所有轉(zhuǎn)換都是惰性的,不會(huì)直接計(jì)算結(jié)果,只是記住應(yīng)用到基礎(chǔ)數(shù)據(jù)集(例如一個(gè)文件)上的這些轉(zhuǎn)換動(dòng)作.只有當(dāng)發(fā)生一個(gè)要求返回結(jié)果給Driver的動(dòng)作時(shí),這些轉(zhuǎn)換才會(huì)真正運(yùn)行,這個(gè)設(shè)計(jì)讓Spark更加有效地運(yùn)行.
1.1基于Spark的Apriori算法基本思想
在Hadoop上實(shí)現(xiàn)基于矩陣的Apriori算法思想[7],引入矩陣概念,只需2次掃描數(shù)據(jù)集D,結(jié)合Spark技術(shù)框架,并運(yùn)用局部剪枝性質(zhì)和全局剪枝性質(zhì)改進(jìn)頻繁項(xiàng)集產(chǎn)生的過程,提高關(guān)聯(lián)規(guī)則挖掘的效率.事務(wù)數(shù)據(jù)集及頻繁項(xiàng)集的存儲(chǔ)基于Hadoop的HDFS文件系統(tǒng).矩陣的行為事務(wù)的集合,矩陣的列為項(xiàng)的集合,向量矩陣存儲(chǔ)變量為0和1,可以減少數(shù)據(jù)存儲(chǔ)空間,減少掃描次數(shù),根據(jù)向量的操作規(guī)則,只需在矩陣中使用“與”操作即可快速產(chǎn)生項(xiàng)集的支持度.根據(jù)Spark內(nèi)部運(yùn)行機(jī)制,整個(gè)Spark編程框架均是基于對(duì)RDD的操作,算法命名為AMRDD.具體算法描述為:
(1) 掃描事務(wù)數(shù)據(jù)庫(kù),求頻繁1項(xiàng)集的集合L1.
(2) 存儲(chǔ)在HDFS上的事務(wù)數(shù)據(jù)庫(kù)即為一個(gè)RDD,RDD被平分成n個(gè)數(shù)據(jù)塊,并且這些數(shù)據(jù)塊被分配到m個(gè)work節(jié)點(diǎn)進(jìn)行處理.
(3) 構(gòu)造局部矩陣.設(shè)Di為事務(wù)數(shù)據(jù)庫(kù)中的某一個(gè)數(shù)據(jù)塊(1≤i≤n),假定L1的個(gè)數(shù)為H,Di中事務(wù)數(shù)目為J,則用L1和Di構(gòu)造H×(J+2)矩陣Gi,其中第1列為L(zhǎng)1中的項(xiàng),最后一列為L(zhǎng)1中對(duì)應(yīng)項(xiàng)的支持度計(jì)數(shù),Gi中的其余各列為Di中的事務(wù)T,若T中存在對(duì)應(yīng)于L1中的項(xiàng),則相應(yīng)位置1,否則置0.矩陣向量的具體轉(zhuǎn)換如圖1所示.

TIDItemsT0I0,I3,I5T1I3,I4T2I0,I2,I3T3I0,I1,I2,I5T4I1,I4T5I0,I2,I3,I6T6I2,I3,I5T7I1,I2,I4T8I0,I2,I6劃塊→T0I0,I3,I5T1I3,I4T2I0,I2,I3T3I0,I1,I2,I5T4I1,I4T5I0,I2,I3,I6T6I2,I3,I5T7I1,I2,I4T8I0,I2,I6根據(jù)L1構(gòu)建矩陣→I01012I10011I21113?è????÷÷G1I00011I11012I20011?è????÷÷G2I00011I11113I21000?è????÷÷G3
圖1矩陣向量的轉(zhuǎn)換
(4) 用Gi生成候選項(xiàng)集的局部支持度.含有k個(gè)項(xiàng)目的候選項(xiàng)集即為Gi中第1列對(duì)應(yīng)k個(gè)項(xiàng)目的集合,因此只需對(duì)Gi中對(duì)應(yīng)的k行進(jìn)行“與”操作即可計(jì)算含有k個(gè)項(xiàng)目的候選項(xiàng)集的局部支持度.在求k候選項(xiàng)集時(shí),只需對(duì)最后一列大于k的行進(jìn)行“與”操作即可,可以大大減少候選項(xiàng)集的數(shù)量.利用局部剪枝性質(zhì),刪除局部支持度小于局部支持度閾值的項(xiàng).
(5) 利用ReduceByKey操作,求得候選項(xiàng)集的全局支持度.如果全局支持度大于支持度閾值的項(xiàng)直接加入頻繁項(xiàng)集集合L;如果全局支持度小于支持度閾值的項(xiàng)利用全局剪枝性質(zhì),再次掃描數(shù)據(jù)庫(kù),最終求得頻繁項(xiàng)集的集合L.
1.2AMRDD算法描述
輸入:數(shù)據(jù)集D(以數(shù)據(jù)塊的形式存儲(chǔ)在Hadoop的分布式文件系統(tǒng)中),最小支持度閾值min_sup;
輸出:D中的頻繁項(xiàng)集的集合L.
(1)求L1
instans = sc.textfile(D)
L1= instans.map(_,1).reduceByKey(_ + _).filter(_ > min_sup)
(2)構(gòu)造局部矩陣
Matrix G =?;//初始化H×(J+2)矩陣
foreach(1 inL1)
foreach(tinDi)
if(1 int)
G.add(1) //若L1中的項(xiàng)l在事務(wù)t中,則相應(yīng)位置1
else
G.add(0) //否則,相應(yīng)位置0
(3)求局部候選項(xiàng)集
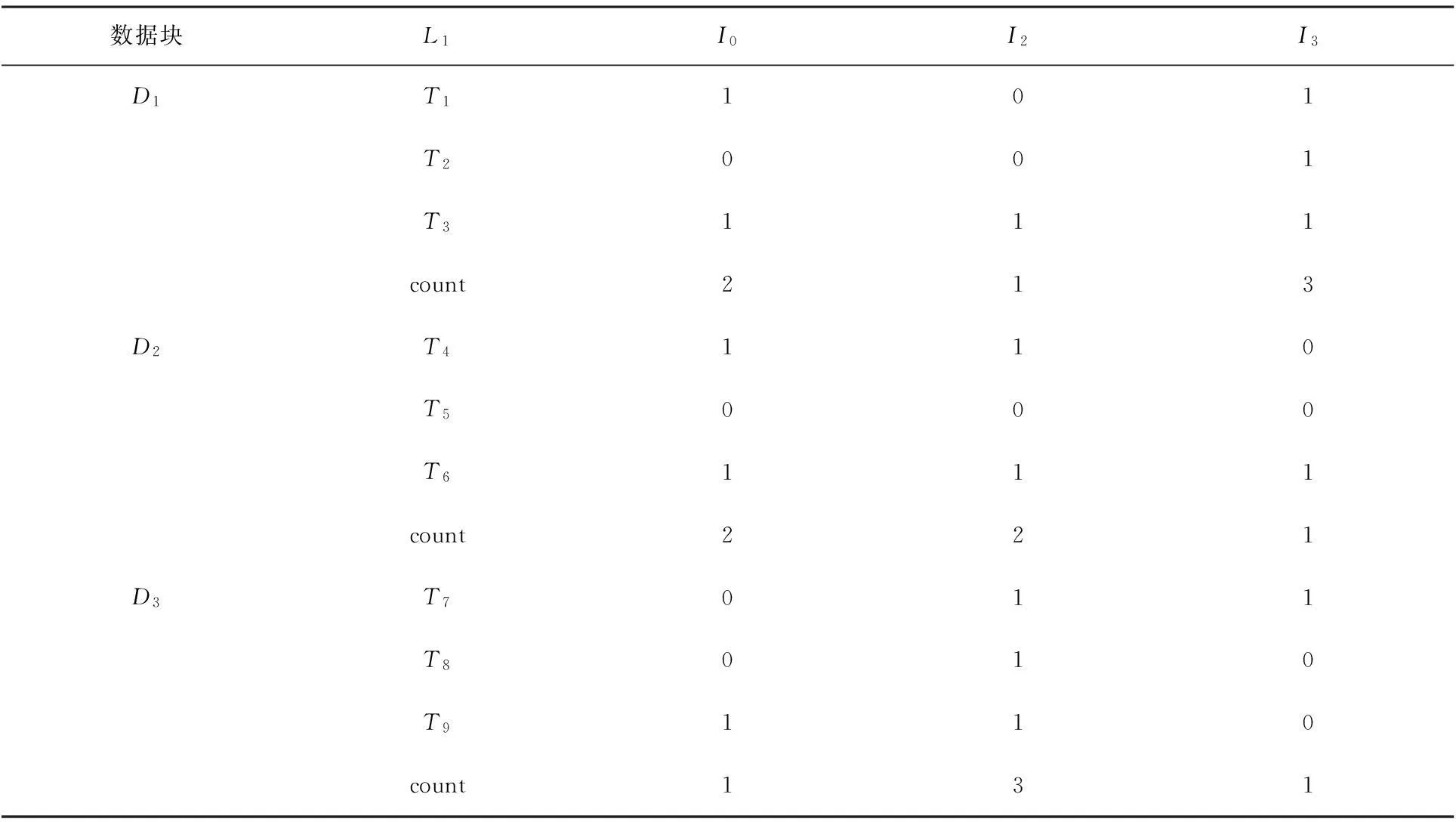
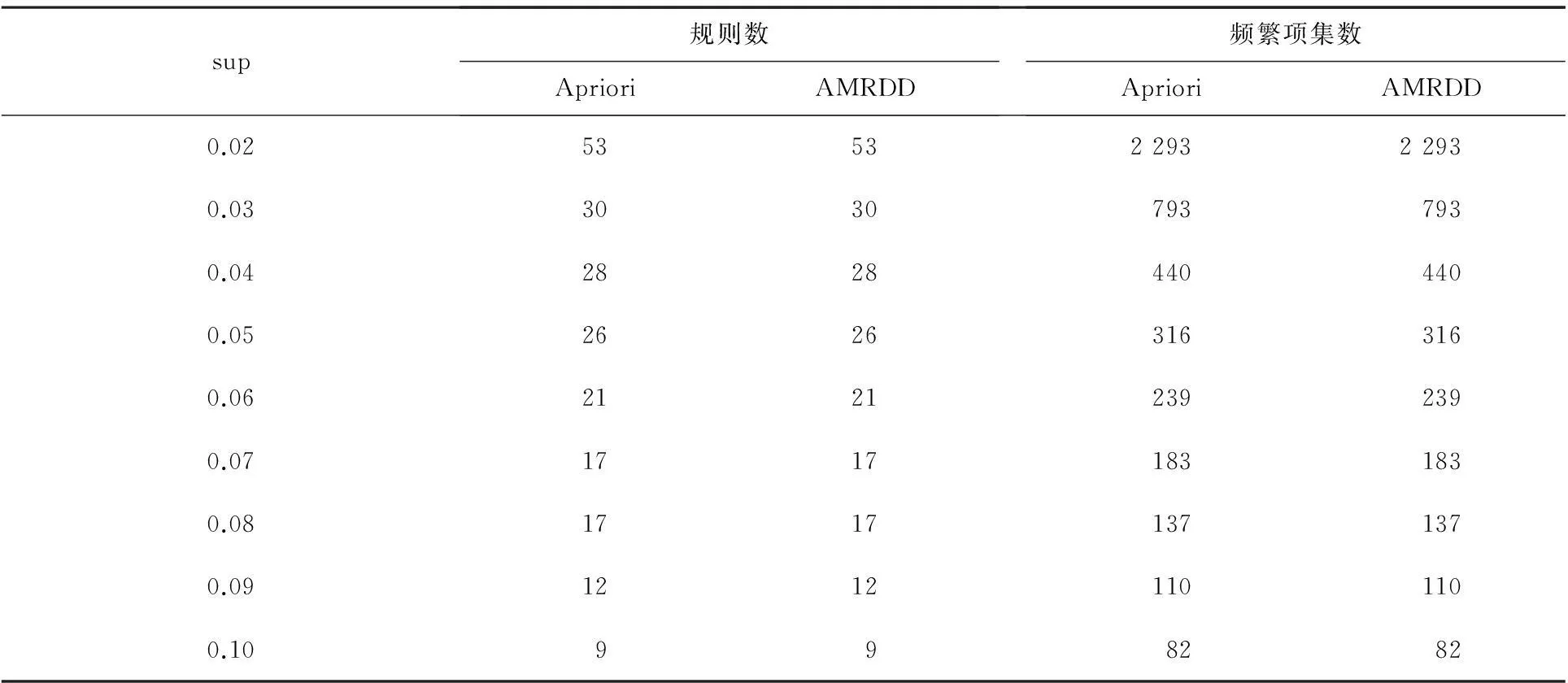
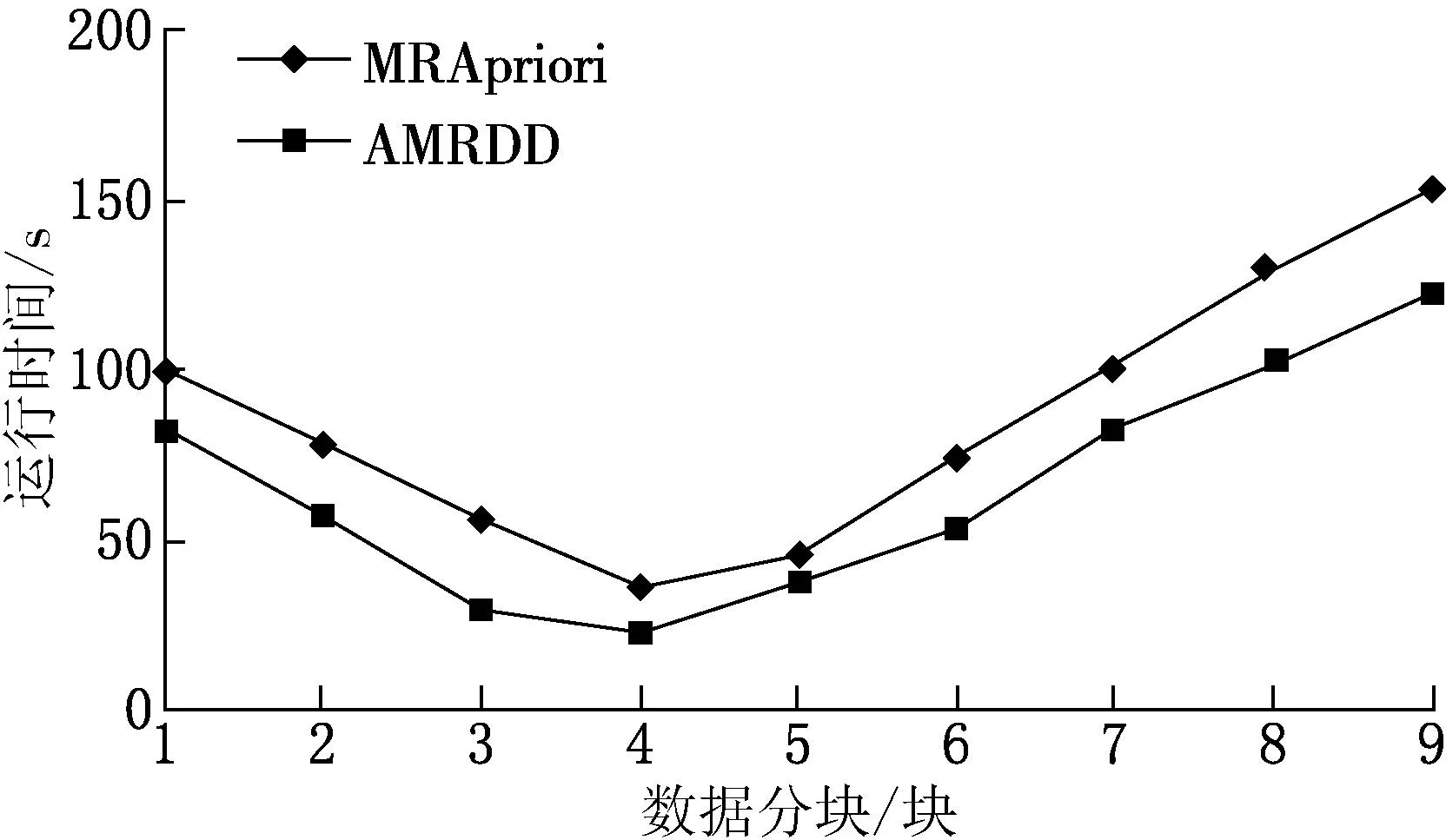
for(1 for(0= count=0 for(m while(count if(G[m][maxL-1] break else count += 1 } local_sup_count = [use“AND” operation on ‘kcolumn items’ of G]; Ck.add( } } } (4)計(jì)算全局支持度,得到頻繁項(xiàng)集L 對(duì)全局支持度小于最小支持度的項(xiàng)應(yīng)用全局剪枝策略,遍歷事務(wù)數(shù)據(jù)庫(kù)進(jìn)行剪枝 gCk=Ck.reduceByKey(_ + _).filter(_.2 < min_sup) L= instans.map(_,gCk).reduceBykey(_ + _).filter(_ > min_sup) //全局支持度大于最小支持度的項(xiàng)直接加到頻繁項(xiàng)集集合 L+=Ck.reduceByKey(_ + _).filter(_.2 > min_sup).add(kitems,sup_count) returnL 2實(shí)驗(yàn)結(jié)果 實(shí)驗(yàn)環(huán)境為3臺(tái)CPU Intel Core4、主頻2.3 GHz、4 G內(nèi)存,操作系統(tǒng)為CentOS6.5臺(tái)式機(jī),其中1臺(tái)為master節(jié)點(diǎn),同時(shí)也作為worker節(jié)點(diǎn),另外2臺(tái)為worker節(jié)點(diǎn),通過交換機(jī)組成一個(gè)局域網(wǎng).所用軟件為JDK1.7、Hadoop2.4.0、Scala2.10.4、Spark1.1.0和IntelliJ13.6.實(shí)驗(yàn)數(shù)據(jù)采用IBM數(shù)據(jù)庫(kù)生成器隨機(jī)生成數(shù)據(jù). 2.1算法有效性驗(yàn)證 采用圖1中的事務(wù)數(shù)據(jù),對(duì)AMRDD算法有效性進(jìn)行驗(yàn)證,事務(wù)數(shù)據(jù)庫(kù)D有9條交易記錄D={T0,T1,T2,T3,T4,T5,T6,T7,T8},I為項(xiàng)目集合,且I={I0,I1,I2,I3,I4,I5,I6}.假定數(shù)據(jù)被分成3個(gè)數(shù)據(jù)塊D1={T0,T1,T2},D2={T3,T4,T5},D3={T6,T7,T8},最小支持度閾值為4.傳統(tǒng)Apriori算法和AMRDD算法挖掘這3塊數(shù)據(jù)文件進(jìn)行算法有效性驗(yàn)證. AMRDD算法生成頻繁1項(xiàng)集L1.以T0為例,產(chǎn)生鍵值對(duì)〈I0,1〉,〈I3,1〉,〈I5,1〉.同樣,其他交易記錄也將產(chǎn)生相應(yīng)鍵值對(duì).合并相同的key,可得到L1:{〈I0,5〉〈I2,6〉〈I3,5〉}. 構(gòu)造局部矩陣.根據(jù)L1,通過掃描數(shù)據(jù)塊將每條交易記錄轉(zhuǎn)化為一個(gè)列向量v.若一條交易記錄中的項(xiàng)在L1中,則相應(yīng)位值為“1”,否則為“0”.表1展示了3個(gè)數(shù)據(jù)塊的列向量表示. 表1 數(shù)據(jù)塊D1,D2和D3的列向量表示 以D1為例計(jì)算局部支持度local_sup.由表1可看出,I2的count計(jì)數(shù)為1<4/3,因此求候選項(xiàng)集進(jìn)行“與”運(yùn)算時(shí)忽略此行,候選項(xiàng)集為{I0I3},則{I0I3}的局部支持度local_sup=1×1+1×0+1×1=2;用同樣方法可計(jì)算D2,則{I0,I2}局部支持度分別為2,而D3由于count均小于4/3,因此沒有生成候選項(xiàng)集,最后計(jì)算全局支持度.將候選項(xiàng)集局部支持度相加,得到{I0,I2},{I0,I3}的全局支持度都為2,均小于最小支持度閾值,故運(yùn)用全局剪枝策略再次掃描事務(wù)數(shù)據(jù)集,得到頻繁項(xiàng)集L1:{〈I0,5〉〈I2,6〉〈I3,5〉},L2:{〈I0I2,4〉},符合要求的關(guān)聯(lián)數(shù)據(jù)是I0和I2.傳統(tǒng)Apriori算法生成的頻繁項(xiàng)集L1:{I0I2I5},L2:{I0I2,4},符合要求的關(guān)聯(lián)數(shù)據(jù)是I0和I2.從最終結(jié)果可以看出,AMRDD算法與傳統(tǒng)Apriori算法挖掘出的頻繁項(xiàng)集和關(guān)聯(lián)規(guī)則結(jié)果及數(shù)量是一致的,證明了AMRDD算法沒有丟失相關(guān)挖掘數(shù)據(jù),算法改進(jìn)后是有效的. 2.2算法支持度實(shí)驗(yàn) 對(duì)Apriori算法支持度設(shè)定不同也會(huì)影響算法的執(zhí)行效率和產(chǎn)生的規(guī)則條數(shù),若設(shè)定支持度太高,挖掘出的知識(shí)量可能有限,若支持度設(shè)定太低,將使算法運(yùn)算復(fù)雜,也會(huì)產(chǎn)生一些無用冗余的規(guī)則.對(duì)傳統(tǒng)Apriori算法和改進(jìn)的AMRDD算法在設(shè)定不同支持度情況下挖掘的關(guān)聯(lián)規(guī)則條數(shù)進(jìn)行實(shí)驗(yàn),結(jié)果如表2所示. 由表2可以看出,當(dāng)sup=0.07和sup=0.08時(shí)產(chǎn)生的規(guī)則數(shù)一樣多,但是sup=0.08時(shí)明顯比sup=0.07時(shí)產(chǎn)生的頻繁項(xiàng)集數(shù)目少,由此可見選擇合適的支持度既可以產(chǎn)生適當(dāng)?shù)囊?guī)則數(shù),也可以縮短算法的運(yùn)行時(shí)間,從而提高了效率. 表2 不同支持度算法輸出結(jié)果 2.3算法數(shù)據(jù)分塊實(shí)驗(yàn) 數(shù)據(jù)集的大小對(duì)算法的運(yùn)行效率有一定影響,劃分的數(shù)據(jù)塊過大,每個(gè)運(yùn)算節(jié)點(diǎn)的計(jì)算量和負(fù)載則加大,影響算法效率,若劃分的數(shù)據(jù)塊小,數(shù)據(jù)集分塊多,則運(yùn)算節(jié)點(diǎn)間通信壓力變大,也同樣會(huì)影響算法的運(yùn)算效率,所以實(shí)驗(yàn)將數(shù)據(jù)集分成1,2,3,4,5,6,7,8,9塊數(shù)據(jù)進(jìn)行挖掘,實(shí)驗(yàn)效果如圖2所示.由圖2可看出,隨著數(shù)據(jù)分塊數(shù)增多,程序運(yùn)行時(shí)間不斷下降,數(shù)據(jù)塊為4的時(shí)候,運(yùn)行時(shí)間最短,之后隨著數(shù)據(jù)分塊數(shù)增加運(yùn)行時(shí)間也不斷增加.因此,數(shù)據(jù)分塊是影響算法效率的一個(gè)因素. 2.4不同數(shù)據(jù)量下算法運(yùn)行時(shí)間實(shí)驗(yàn) 實(shí)驗(yàn)分別實(shí)現(xiàn)了單機(jī)的Apriori算法、Hadoop平臺(tái)上的MRApriori算法和Spark平臺(tái)上的AMRDD算法.在不同大小的數(shù)據(jù)集上,不同算法的運(yùn)行時(shí)間比較見圖3. 圖2 不同數(shù)據(jù)分塊下運(yùn)行時(shí)間比較 圖3 不同算法運(yùn)行時(shí)間比較 由圖3可看出,當(dāng)數(shù)據(jù)量小于百萬條時(shí),基于Spark和Hadoop的算法與傳統(tǒng)Apriori算法所用的時(shí)間相差不多,隨著數(shù)據(jù)量增加,時(shí)間差逐漸增大.這是因?yàn)楫?dāng)數(shù)據(jù)量逐漸增大時(shí),基于Spark平臺(tái)和Hadoop平臺(tái)數(shù)據(jù)處理時(shí)間比例上升,通信開銷所占比例逐漸縮小,甚至可以忽略.當(dāng)數(shù)據(jù)量繼續(xù)增大時(shí),AMRDD算法比MRApriori算法有明顯的優(yōu)勢(shì),產(chǎn)生這種現(xiàn)象的原因是Spark可以將計(jì)算的中間結(jié)果cache存到內(nèi)存中,省去了MapReduce大量的磁盤I/O操作. 3總結(jié) 本文在傳統(tǒng)Apriori算法的基礎(chǔ)上提出了AMRDD算法,該算法引入矩陣概念,應(yīng)用了局部剪枝策略和全局剪枝策略從而大大減少了生成候選項(xiàng)集的數(shù)量,并充分利用Spark的并行化優(yōu)點(diǎn),迭代計(jì)算基于內(nèi)存,比Hadoop更快.實(shí)驗(yàn)結(jié)果表明,傳統(tǒng)Apriori算法不適合處理大數(shù)據(jù),基于Spark的算法明顯優(yōu)于基于Hadoop的算法.將傳統(tǒng)的數(shù)據(jù)挖掘算法移植到Spark平臺(tái)上來處理大數(shù)據(jù)將會(huì)是未來的一個(gè)趨勢(shì). [參考文獻(xiàn)] [1]李鋒剛,梁鈺. 基于LDA-wSVM模型的文本分類研究[J]. 計(jì)算機(jī)應(yīng)用研究,2015,32(1):21-25. [2]宋天勇,趙輝,李萬龍,等. 引入自檢策略的進(jìn)化K-means算法[J]. 東北師大學(xué)報(bào)(自然科學(xué)版),2014,46(3):59-63. [3]柴玉梅,張卓,王黎明. 基于頻繁概念直乘分布的全局閉頻繁項(xiàng)集挖掘算法[J]. 計(jì)算機(jī)學(xué)報(bào),2012,35(5):990-1001. [4]馮勇,尹潔娜,徐紅艷. 基于垂直頻繁模式樹帶有負(fù)載均衡的分布關(guān)聯(lián)規(guī)則挖掘算法[J]. 計(jì)算機(jī)應(yīng)用,2014,34(2):396-400. [5]CHANCHAL YADAV,SHULIANG WANG,MANOJ KUMAR. An approach to improve Apriori algorithm based on association rule mining[C]//2013 Fourth International Conference on Computing,Communications and Networking Technologies (ICCCNT),USA:IEEE,2013:1-9. [6]楊新月. 云計(jì)算環(huán)境下關(guān)聯(lián)規(guī)則算法的研究[D]. 成都:電子科技大學(xué),2011. [7]毛衛(wèi)俊. 基于云平臺(tái)的并行關(guān)聯(lián)規(guī)則挖掘算法研究[D]. 上海:華東理工大學(xué),2014. [8]MOHAMMADHOSSEIN BARKHORDARI,MAHDI NIAMANESH. ScadiBino an effective MapReduce-based association rule miming method[C]//ICEC’14:Proceedings of the Sixteenth International Conference on Electronic Commerce,Philadelphia:ICEC,2014:1-8. [9]MATEI ZAHARIA,MOSHARAF CHOWDHURY,TATHAGATA DAS,et al. Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing[C]// Presented as part of the 9thUSENIX Symposium on Networked Systems Design and Implementation,USA:Matei University of California,2012:25-27. (責(zé)任編輯:石紹慶) The improvement and research of Apriori algorithm based on Spark NIU Hai-ling,LU Hui-min,LIU Zhen-jie (School of Computer Science and Engineering,Changchun University of Technology,Changchun 130012,China) Abstract:The AMRDD algorithm is proposed on the basis of the traditional Apriori algorithm,which is a distributed association rules algorithm based on Spark. To reduce the times of scanning the database,the matrix is introduced,and the number of candidate frequent itemsets is reduced by using local pruning strategy and global pruning strategy. The algorithm is realized on Spark platform,and compare with the traditional Apriori algorithm and the Apriori algorithm based on Hadoop. The experimental results show that AMRDD algorithm performs effectively on big data for mining frequent itemsets. Keywords:Apriori;Spark;matrix;local pruning strategy;global pruning strategy [中圖分類號(hào)]TP 391[學(xué)科代碼]520·20 [文獻(xiàn)標(biāo)志碼]A [作者簡(jiǎn)介]牛海玲(1985—),女,碩士研究生; 通訊作者:魯慧民(1972—),女,博士后,副教授,主要從事智能信息處理、大數(shù)據(jù)研究. [基金項(xiàng)目]國(guó)家自然科學(xué)基金資助項(xiàng)目(61472049);吉林省自然科學(xué)基金資助項(xiàng)目(20130101055JC);吉林省科技發(fā)展計(jì)劃項(xiàng)目(20150204005GX);長(zhǎng)春市重大科技攻關(guān)計(jì)劃項(xiàng)目(14KG082). [收稿日期]2015-05-08 [文章編號(hào)]1000-1832(2016)01-0084-06 [DOI]10.16163/j.cnki.22-1123/n.2016.01.018