漢語冒號標注與自動識別方法研究
2016-05-04 00:41:24谷晶晶周國棟
中文信息學報 2016年3期
谷晶晶,周國棟
(蘇州大學 計算機科學與技術學院,江蘇 蘇州,215006)
漢語冒號標注與自動識別方法研究
谷晶晶,周國棟
(蘇州大學 計算機科學與技術學院,江蘇 蘇州,215006)
隨著對篇章分析研究的逐步加深,標點符號研究成為了篇章分析與消歧的一個重要切入點。有效識別標點符號在句子中的作用,將有助于句法分析、篇章分析以及其他自然語言處理技術的發展。該文主要任務是實現漢語冒號的人工標注與自動識別,其中自動識別采取了規則法和基于統計的最大熵法。基于規則的方法比較簡單且易于實現,最大熵方法把規則融入到統計之中,在實驗結果中具有更好的識別效果。
漢語冒號分類;最大熵;篇章分析
1 引言
近年來,標點符號在篇章分析中起到的作用逐漸引起相關研究者的關注。漢語中常用的標點符號有十幾種,其中逗號、冒號、分號和句號為句子的分割符號。逗號是所有標點符號中的使用方法最多的,有大量學者已經展開了逗號的相關研究工作。漢語冒號作為句子的分割符號,使用方法之多僅次于逗號。如果能夠有效識別冒號在句子中的作用,將有助于句法分析、篇章分析甚至其他自然語言處理技術的發展。
Hobbs[1]認為篇章單元可以小到句子,大到篇章本身。Mann 和Thompson的修辭結構理論[2-3]與Hobbs模型很相似,并認為篇章單元可以小到短語。在漢語中,樂明[4]把漢語篇章的基本單元定義為小句,形式上小句是由句號、問號、嘆號、分號、冒號等分割開的文字串。Xue等[5-6]綜合了Mann 和Thompson的修辭結構理論,定義了冒號作為句子的定界符,即可用冒號作為基本語篇單元(EDU,Elementary Discourse Unit)的定界符。
本文將冒號作為篇章基本單元的分隔符,提出了漢語冒號的分類標注體系,并對漢語冒號進行人工標注與自動識別。依據《中華人民共和國標準標點符號用法》[7]中公布的漢語冒號使用方法,以及通過對現實語料的統計與分析,制定了漢語冒號的標注體系。該體系的冒號標注范圍主要針對漢語中常使用的冒號,數學中使用的冒號(如: 比號)與機器語言中使用的冒號(如: 域名),都不在本文的考察范圍之內。
為實現漢語冒號的標注與自動識別,本文將通過以下三點展開: ①提出冒號使用方法分類的標注體系及標注方法; ②進行冒號分類的人工標注; ③采 用基于規則和基于最大熵兩種方法進行實驗,完成漢語冒號的自動分類與識別。實驗結果達到了預期目標,基于最大熵的方法比基于規則的方法實驗總體正確高達6.9%。本文研究熵有助于促進自然處理的基礎研究和應用研究。
本文組織結構如下: 第二節介紹相關工作;第三節簡介語料標注與識別;第四節提出基于上下文特征的冒號分類的方法;第五節闡述實驗結果及分析;第六節結語。
2 相關工作
針對標點符號的研究在自然語言領域越來越受到關注,近年來很多學者將標點符號作為中文分句相關問題研究的標志[8-15]。比如Jin等[11]提出利用逗號對漢語長句子進行劃分。該文章主要識別逗號左右兩邊的子句是并列關系還是從屬關系。
在李幸等[12-13]的文章中介紹了關于層次化漢語長句結構分析,提出了一種針對漢語長句子句法分析的分層處理方法。該方法用標點符號(包括逗號、分號和冒號)對長句子進行切分,然后對切分單元分別處理,得到各部分的分析子樹,最后將子樹合并,形成完整的句法分析樹。該文揭示了基于標點符號的層次化漢語長句結構分析的優越性。
Xue和Yang[14]這篇文章中,主要研究了如何識別哪些逗號等同于句子邊界的情況。并給出了逗號作為句子邊界的識別方法。該文對漢語標點符號的研究引發了一個新的熱點。Yang和Xue[15]一文中,對逗號的使用方法進行了更詳細的分類,共劃分了七類,其中也包含了逗號等同于句子邊界的情況。Xue等[5-6]在識別隱式關系中使用了冒號作為句子的定界符,利用冒號輔助解決篇章關系問題。
3 語料標注與分析
3.1 語料介紹
通過統計賓夕法尼亞中文樹庫(CTB 6.0)和清華中文樹庫中的冒號數量,發現這兩個樹庫中所包含的冒號數量都太少,不到一百個。本文工作無法在現有的語料基礎上進行,需要另外收集語料。
本文收集的語料來自搜狗語料庫*http: //www.sogou.com/labs/dl/c.html,包含的主要內容是新聞報道,之外涉及一些其他領域的語料,如: 古今中外的小說、人物傳記、節目訪談、法律文獻以及廣告等。本文將這些混雜在一起的語料劃分為五大類: 文言文、現代文學、法律文獻、節目訪談和新聞報道。
3.2 標注體系
本文將冒號的使用方法歸納為七類: 引用、動賓、邊界、總分、解說、提示、 other。其中引用、動賓和邊界又歸為話語引用類,而總分、長解說和短解說又歸為解釋說明類。other分類是對冒號的一些不經常使用的用法歸類。圖1展示了冒號分類標準。本文對漢語冒號的使用方法進行了詳細的劃分與自動識別,不僅可以用來切分基本篇章單元,還標示了這些篇章單元之間的關系。
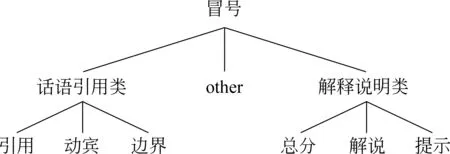
圖1 冒號分類標準
引用(Nm): 該類冒號用在是指人物或人物代指與該人的話語之間。文中以P1 P2 P3…標示冒號。如下列例句中的冒號p1。冒號p1前的詞為“秦牧”,是一個人物專名。冒號p1前的名詞還可以是某個職業群的代表,如“記者”;也可以是擬人化的主語,如一些擬人化的動物或植物名。該類冒號,通常出現在側重對話內容的對話記錄中,不關注對話人的語氣、表情、動作等,如訪談記錄、主持人手稿等。本文對該類冒號設置的標注標簽為Nm。
例1 秦牧: p1要學好語文,必須注意多讀、多寫、多思索。
動賓(VP): 動賓關系類是指該類冒號分割開了謂語動詞與賓語。常用的謂語動詞有: 問、答、說、曰、云、想、是、證明、宣布、例如、如下等。這類謂語的主語通常是人物主語或擬人化的主語,冒號后的句子通常是人物話語引用。如下面例句中的冒號p2,就是在句中起到了動賓作用。該類冒號的標注標簽為VP。
例2 克萊因說: p2 “普遍的觀點是人以群分,人們總喜歡和自己相似的人,所以有理論提出多樣化不利于團結。”
邊界(SB): 邊界是指句子邊界(Sentence Boundary),標注標簽為SB。這一類冒號被定義為句子邊界,是由于冒號前后的句子都是一個完整的IP結構,可獨立存在。冒號后的句子一般是對冒號前句中主語的話語引用,由左右雙引號界定。該類冒號所在的句子不但關注了對話人的對話內容,還包含很多人物的語氣、表情或動作的描寫,使人物刻畫更生動,多出現在文學作品中。在例3中的冒號p3,冒號后的句子是對冒號前句中主語“鳳姐”的話語引用。
例3 鳳姐連忙告訴小丫頭傳飯: p3 “我和太太都跟著老太太吃。”
總分(ZF): 總分類,顧名思義,冒號前的句子是總說,冒號后面的句子是對前面句子的具體分說。以本文中一個句子為例,即例4,由例句4可以看出,冒號p4前的句子是總說“冒號”的使用方法可分為七類,冒號p4后的句子是對“冒號”的使用方法具體有哪七類進行詳細分說。
例4 本文將冒號的使用方法歸納為七類: p4 引用、動賓、邊界、總分、短解說、提示、Other。
解說(LJ): 該類是指冒號后面的句子是對冒號前面的詞語進行解釋說明。這類冒號后的句子是對冒號前的某個詞或短語的解說。下面的例句5中的冒號p5就屬于解說類冒號,冒號p5后面的句子是對“對比試驗”的詳細解說。
例5 有人曾做過對比實驗: p5兩個病情相近,年齡和體重相差無幾的手術患者,每天食用一只海參的患者,會比另一個患者提前20天左右全面康復。
提示(SJ): 該類是生活中常用的、位于具有提示性短語后的冒號。該類冒號是從解說類中分離出來的一類,冒號后的內容也是對冒號前詞或短語的解說,該類冒號前通常只有一個詞或短語。這些詞或短語通常是: 電話、郵編、地址、姓名、年齡等。如下面的例句6,冒號p6就屬于提示類冒號。該類標注標簽為SJ。
例6 電話: p6 8888888
other: 本文設置的other分類,是為了將一些出現頻率較低的冒號使用方法類統歸為一類。這些冒號有: 分總類冒號,呼吁類冒號,作者與作品之間的冒號,如“朱自清: 《背影》”。
3.3 標注方法
人工標注冒號分類是指人為的在語料中對冒號標注分類標簽,分類標準參照前面的第3.2小節中介紹的冒號分類標準。標注過程中共使用了七類標簽,是在有分詞與詞性標注信息的文中直接標注。標注時,標注的標簽與冒號之間以下劃線為間隔。標注示例如下面的例句所示,例句7中的冒號屬于動賓類,則標注了“VP”標簽,而例句8中的冒號屬于總分類,則標注了“ZF”標簽。
例7 寶玉_nP 看見_v 道_v : _VP "_n 妹妹_n,_,我_rN 剛才_t 說_v 的_u 不過_d 是_vC 些_qN 呆話_n,_,你_rN 也_d 不用_dN 傷心_a。_。 ”_”
例8 第四十九_m 條_qN 期貨_n 交易所_n 應當_vM 以_p 適當_a 方式_n 發布_v 下列_n 信息_n : _ZF (_( 一_m)_) 即時_m 行情_n ;_; (_( 二_m)_) 持_v 倉量_n、_、 成交量_n 排名_vN 情況_n ;_; (_( 三_m)_) 標準_n 倉單_n 數量_n 和_c 可_vM 用_p 庫容_n 情況_n ;_; (_( 四_m)_) 交易所_n 業務_n 規則_n 規定_v 的_u 其他_rN 信息_n。_。
3.4 語料統計
本文收集的初始語料達437M,因標注量太大,只抽取了一部分進行人工標注。共標注了5 247個句子,6 469個冒號。標注的語料庫,包含了多個領域的語料。因各領域語料混雜在一起,為了便于統計分析,本文人為地將語料劃分為五大類: 文言文、現代文學、法律文獻、節目訪談和新聞報道。據統計,文言文中使用的冒號主要是動賓類;現代文學中出現的冒號主要是動賓類和邊界類;法律文獻中出現的冒號主要是總分類;節目訪談中使用的冒號主要是引用類;新聞報道中冒號使用方法主要是提示類和解說類。各領域語料所占的句子數量如表1所示。

表1 各領域語料句子數量統計
3.5 預處理
在對漢語冒號的人工標注與識別之前,需要先對新收集來的語料進行相關的預處理。預處理主要包括: 規整處理、分詞、詞性標注和手工調整。
(1) 規整處理
對收集來的生語料,要進行規整處理。首先去除不可識別的符號、地址鏈接等,再進行句子分割。句子分割是指把多個句子組成的段落分割的一個句子為一個段落,并保留包含一個或多個冒號的句子。在程序分割句子的過程中,要注意標點符號的匹配問題。
(2) 分詞
中文分詞是將一個漢字序列切分成詞的序列,是中文信息處理最基礎的技術之一。本文語料規整處理后,需對語料進行分詞。首先從清華樹庫中提取出分詞語料,劃分訓練語料和測試語料后,再使用CRF分類工具,訓練出分詞模型,并利用測試語料對模型評測,證實取得較高的正確率后,然后使用該模型對本文的語料進行分詞。
(3) 詞性標注
詞性標注是指對于句子中的每個詞都指派一個合適的詞性,如名詞、動詞、形容詞等。與分詞類似,實現詞性標注,需先構建詞性標注的訓練模型。同樣是從清華樹庫提取出詞性標注語料,劃分訓練語料和測試語料,使用最大熵工具,訓練出詞性標注模型,并用測試語料對模型評測,證實取得較高的正確率后,再利用該模型對本文的語料進行詞性標注。本文選擇清華樹庫作為分詞和詞性標注的環境,是由于該語料對詞性種類劃分較細,有助于提高本文實驗的正確率。
(4) 手工調整
在進行分詞與詞性標注的過程中,會出現很多不可預料的錯誤,包括分詞錯誤和詞性標注錯誤,這種現象在文言文中尤其多見。這些錯誤都可能對實驗正確率造成影響。手工調整就是對語料中出現的分詞錯誤或詞性標注錯誤予以更正,主要調整冒號附近的詞,盡量排除影響實驗正確率的因素。
4 冒號識別方法
自然語言處理中用到的研究方法,通常是規則法和統計法,以及二者相結合的方法。規則法是從語言學與認知學的觀念出發,適合處理自然語言中確定的一面;而統計法是從統計學和計算科學觀念為出發點,比較適合處理不確定性的一面。確定與不確定是表示某個語言現象中是否存在作為充分條件的可用特征,但這是相對而言的。規則法的本質是演繹,而統計法的本質是歸納。本文就分別使用了規則法和統計法,其中統計法采用了基于最大熵模型的方法。
兩種方法都主要使用了詞法特征和位置特征。詞法特征主要是冒號前的三個詞及詞性與冒號后的兩個詞及詞性,位置特征是指冒號前句子的長度,長度記為L。冒號前的三個詞(或稱左三詞)記為: lword_1、lword_2和lword_3,這三個詞相應的詞性記為: lpos_1、lpos_2和lpos_3,離冒號最近的詞為lword_1。冒號右邊的兩個詞及詞性記為: rword_1、rword_2和rpos_1、rpos_2,離冒號最近的詞為rword_1。
冒號左邊選取三個詞的原因有三點: (1) 動賓類的謂詞通常出現在左詞一位置,如例句2中的“說”;(2) 人物專有名詞經常出現在左詞一、左詞二或左詞三位置,如例句1中“秦牧”、例句2中的“克萊因”和例句7中的“寶玉”;(3) 總分類冒號一般都有數詞出現,該數詞通常出現在左詞二或左詞三位置,等同數詞表達含義的詞“下列”和“以下”也通常出現在左詞二或左詞三位置,如例句4中的數字“七”和例句8中的詞“以下”。
冒號右邊選取兩個詞的原因有兩點: (1) 左引號的位置通常出現在右詞一(rword_1)的位置,存在左引號可基本確定該類冒號為話語引用類,如例句2、例句3和例句7中的左引號。(2)總分類冒號右邊一般都有數詞,而該數詞通常出現在右詞一(rword_1)或右詞二(lword_2)的位置。
4.1 基于規則的冒號分類方法
基于規則的自動提取方法,主要通過對詞性和長度的分析,判斷冒號所屬的分類。主要規則如下:
(1) lpos_1是否為“v”或“vC”,是則標記動賓類,否則下一步。
(2) 若L長度小于2,且lpos_1或lpos_2必有一個為“nP”或“b”,余下的詞為名詞,則該冒號為引用類,否則下一步。
(3) 若rpos_1為左引號,則標記邊界類,否則下一步。
(4) lpos_2或lpos_3是否“m”,是則標記總分類,否則下一步。
(5) rpos_1或rpos_2是否為“m”,是則標記總分類,否則下一步。
(6) 若L小于3,且lpos_1為“n”,則標記提示類,否則下一步。
(7) 若L大于2,且lpos_1為“n”,則標記解說類,否則下一步。
(8) 余下都歸為other類。
4.2 基于上下文特征的冒號分類方法
本文的第二種方法是基于最大熵[16]的自動分類。該方法通過提取上下文特征,訓練最大熵模型,實現冒號的自動分類與識別。選取冒號前的三個詞時,是從冒號位置開始向左尋找,依次得到word_1、lword_2和lword_3。但這三個詞不能是圓括號及圓括號內的詞,遇到右圓括號的時候,要跳過圓括號及圓括號內的內容,到左圓括號的左邊繼續尋找左詞,直到句首或前一個冒號,則尋找結束。計算冒號前句子長度L時,也要排除圓括號及圓括號內的詞。其他特征的選取沒有特別要求。選取的具體特征,如表2所示,表2 中同樣給出了例句8中冒號所提取的特征值。
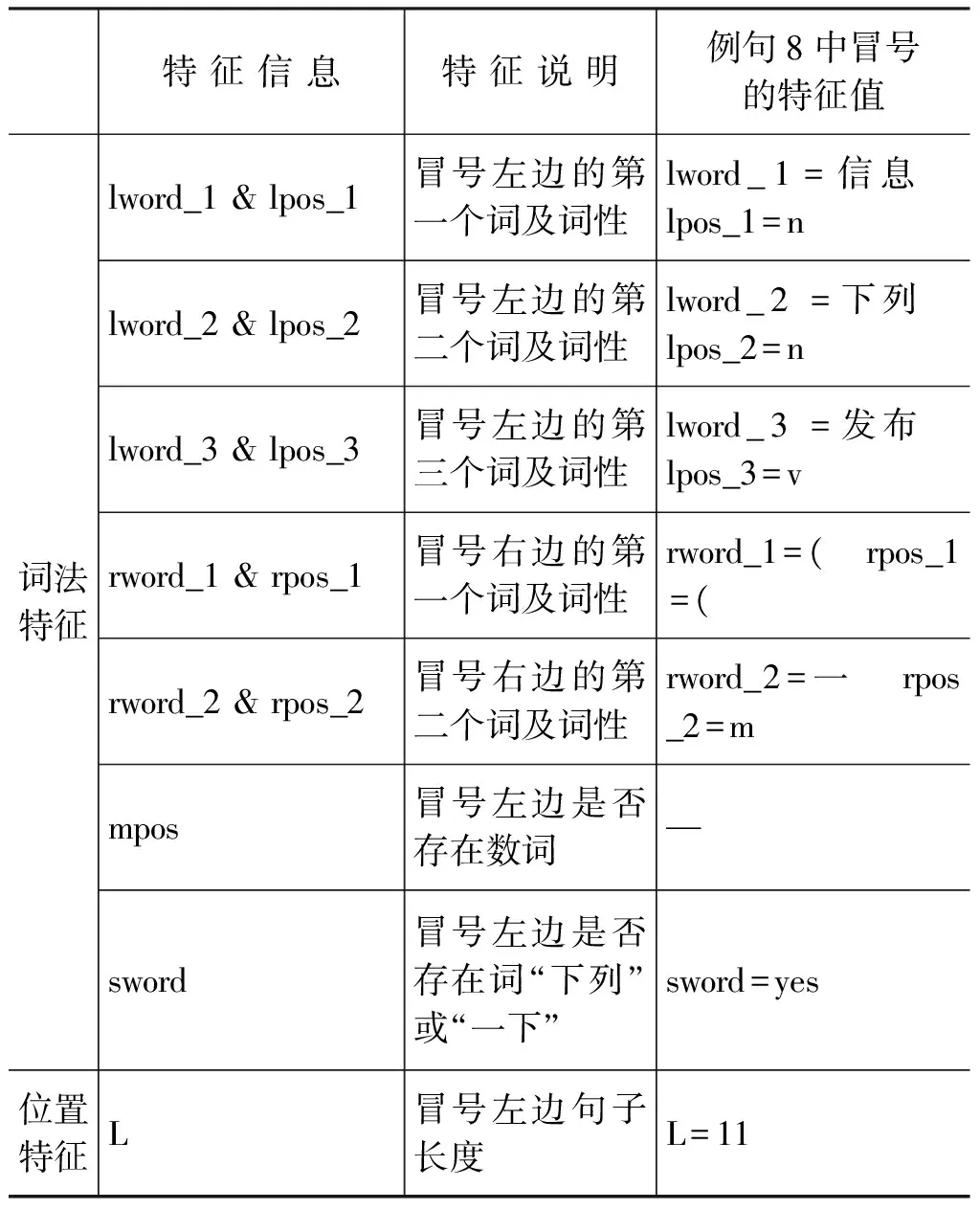
表2 特征列表
5 實驗結果及分析
5.1 實驗數據
在實驗過程中,將已標注的語料區分為訓練語料和測試語料。本文語料共人工標注6 469個冒號,訓練語料含有5 756個冒號,測試語料中含有713個冒號。測試語料中,SB類冒號共有40個,ZF類冒號共有64個,VP類冒號共有324個,Nm類冒號共有47個,SJ類冒號共有105個,LJ類冒號共有130個,other類冒號共有4個。
5.2 實驗結果
第四節中介紹了兩種冒號識別方法,分別是基于規則的方法和基于最大熵的方法,并將基于規則的方法系統作為本文的基準系統。基于最大熵的方法,需要先對訓練語料進行學習,再對測試語料進行實驗并統計結果;基準系統的實驗不需要進行語料學習,為了更好地進行實驗結果對比,只需在測試上直接實驗樣式統計結果即可。基于最大熵的方法,所使用的最大熵工具是由張樂編寫的Maxent工具包*http: //homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html。實驗結果如 表3所示。由表3可知,基準系統的實驗總體正確率為86.5%,基于最大熵的方法實驗總體正確率為93.4%,基于最大熵方法明顯比基于規則方法的識別效果更好。基于規則的方法相對是比較粗糙的,基于最大熵的方法能更好地利用上下文特征,得到更優解,使我們的實驗得到了更高的正確率。兩種方法中的VP類都是識別效果最好的,原因在于謂詞對動賓類的影響較大;而other類的識別是最不理想的,主要原因在于訓練樣本太少。
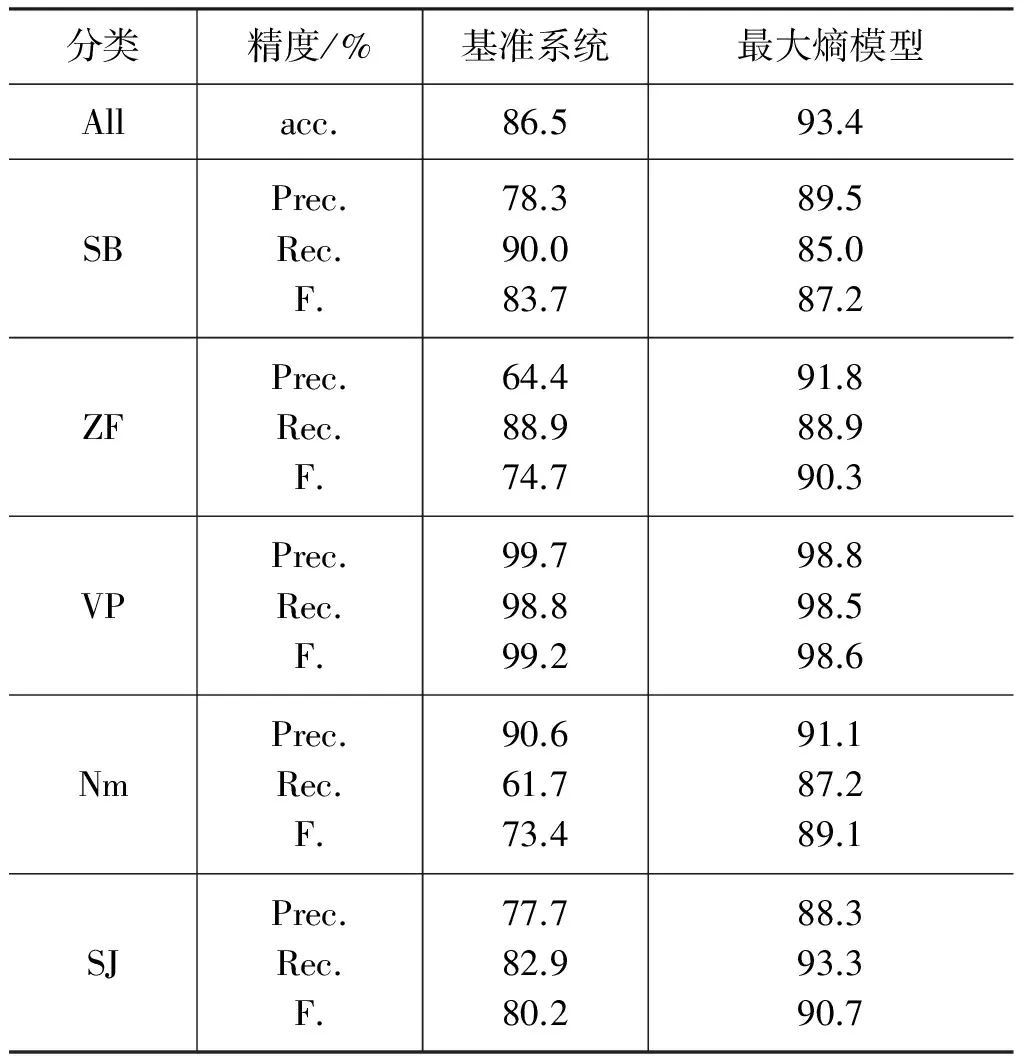
表3 實驗結果
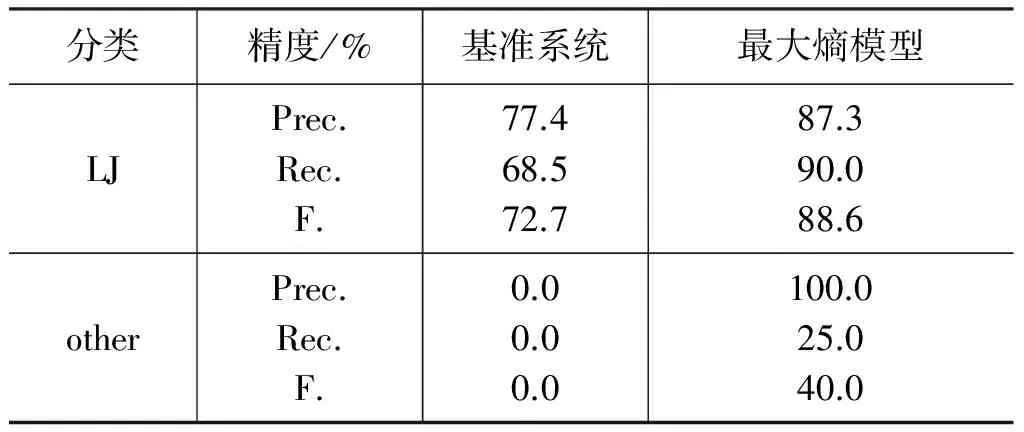
續表
5.3 語料分析
本文為了分析語料的差異性,分別對各語料進行了實驗。各語料的實驗是基于最大熵模型,實驗結果如表4 所示。由表4可知,節目訪談類的識別正確率達到了100%。原因在于該語料內基本上只存在引用類(Nm)和動賓類(VP)兩類冒號,等于是做二分類,說明了這兩類冒號很易于區分。文言文、現代文學以及法律文獻中也只含有三、四類冒號,且以其中某兩類為主,識別效果也很好。新聞報道語料雖然主要是提示、解說和動賓類的冒號,但其他類的冒號也有很多,且有很多不易區分的冒號,故該語料識別效果最不好。

表4 各語料實驗結果
由3.4節的語料統計和5.1節的實驗數據可知,新聞語料在總語料中占有將近一半的比例,動賓類冒號也在總測試語料中的冒號占到將近一半的比例。這種情況的語料分布符合現實生活的情況,但為了進一步對比分析,本文又構建了一個均衡語料用于實驗分析。均衡語料包含了新聞報道語料400句,和其他各語料分別300句,在選取過程中控制了VP類冒號的數量,使各類冒號也相對均衡。并采用了基準系統和最大熵模型進行對比實驗,實驗結果如表5所示。由表5可知,在均衡語料中,最大熵模型的總體識別正確比基準系統高8.4%。相比普通語料,最大熵的冒號識別正確率更加優于基準系統。均衡語料總體識別正確率低于普通語料的原因,在于VP類冒號的比例嚴重下降。

表5 均衡語料實驗結果
5.4 錯誤分析
利用規則自動提取的方法,會出現很多不可避免的錯分。采用最大熵的方法,也會出現一些和基于規則方法類似的錯分現象。如下面的三個例句,這三個例句中冒號左邊都是人物專名,右邊的內容有很大差別,但例句10和例句11中的冒號很容易被錯分為和例句9相同的引用類。例句10和例句11中的冒號出現的頻率很低,所以很容易被錯分為Nm。針對這些錯分,目前還沒有找到很好的解決辦法。這也將成為我們下一步工作中的一個挑戰。
例9 陳好_nP : _Nm 挑戰_v 要_vM 在_p 人_n 的_u 能力_n 范圍_n 內_f。_。
例10 王澤國_nP : _LJ 著名_a 的_u 納稅_vN 籌劃_n 操作_vN 實務_n 專家_n、_、 經濟學_n 碩士_n、_、 中國_nS 注冊_vN 會計師_n、_、 注冊_vN 稅務師_n,_,受訓_v 人數_n 超_v 萬_m 人_n
例11 朱自清_nP : _other 《_《 背影_n 》_》
6 結語
中文信息處理已經完成了字處理,較好地解決了詞處理,目前的研究重點轉向句子研究。句子內部的標點符號也成為了句子研究的一個熱點。本文首次提出了漢語冒號的標注與自動識別方法研究,定義了冒號分類的標準及標注方法,并標注了大量語料。我們采用了兩種方法來實現冒號的自動分類與識別,分別到基于規則的方法和基于最大熵的方法。基于最大熵的方法比使用基于規則的方法的實驗正確率高6.9%,因此也說明使用最大熵的方法能夠更好地解決冒號分類問題。在下一步工作中,我們將繼續立足于句子內部的標點符號研究。
[1] Hobbs J R Information,intention,and Structure in Discourse: A first draft[C]//Proceedings of the Burning Issus in Discourse. 1993: 41-66.
[2] Mann William C Sandra A Thompson. Rhetorical Structure Theory: [J].Toward a functional theory of text organization. 1988,8(3): 243-281.
[3] L Carlson,D Marcu,M E Okurowski. RST Discourse TreeBank[C]//Linguistic Data Consortium. 2002.
[4] 樂明. 漢語篇章修辭結構的標注研究[J]. 中文信息學報,2008,22(4): 19-23.
[5] Nianwen Xue,Fei Xia,Fu-Dong Chiou and Martha Palmer. The Penn Chinese TreeBank: Phrase Structure Annotation of a Large Corpus[C]/Proceedings of Natural Language Engineering. 2005,11(2): 207-238.
[6] Yuping Zhou,Nianwen Xue. PDTB-style Discourse Annotation of Chinese Text[C]//Proceedings of Annual Meeting on Association for Computational Linguistics(ACL-12). 2012: 69-77.
[7] 中華人民共和國國家質量監督檢驗檢疫總局、中國國家標準化管理委員會. GB/T15834-2011標點符號用法[M].中國標準出版社,2011.
[8] Yuqing Guo,Haifeng Wang,and Josef Van Genabith. A Linguistically Inspired Statistical Model for ChinesePunctuation Generation[C]//Proceedings of ACM Transactions on Asian Language Processing.2010,9(2).
[9] Hen-Hsen Huang and Hsin-His Chen. Chinese Discourse Relation Recognition[C]//Proceedings of the 5th International Joint Conference on Natural Language Processing 2011: 1442-1446.
[10] Vanessa Wei Feng,Graeme Hirst. Text-level Discourse with Rich Linguistic Feature[C]//Proceedings of Annual Meeting on Association for Computational Linguistics(ACL-12),2012: 60-68.
[11] Meixun Jin,Mi-Young Kim,Dong-Il Kim,and Jong-Hyeok Lee. Segmentation of Chinese Long Sentences Using Commas[C]//Proceedings of the SIGHANN Workshop on Chinese Language Processing,2004.
[12] Xing Li,Chengqing Zong,Rile Hu. A Hierarchical Parsing Approach with Punctuation Processing for Long Sentence Sentences[C]//Proceedings of the Second International Joint Conference on Natural Language Processing: Companion Volume including Posters/Demos and Tutorial Abstracts,2005.
[13] 李幸,宗成慶. 引入標點處理的層次化漢語長句句法分析方法[J]. 中文信息學報,2006: 20(4): 8-15.
[14] Nianwen Xue,Yaqin Yang. Chinese sentence segmentation as comma classification [C]//Proceedings of Annual Meeting on Association for Computational Linguistics(ACL-11). 2011: 631-635.
[15] Yaqin Yang,Nianwen Xue. Chinese Comma Disambiguation for Discourse Analysis[C]//Proceedings of Annual Meeting on Association for Computational Linguistics(ACL-12). 2012: 786-794.
[16] Adam L.Berger,Stephen A.Della Pietra,Vincent J.Della Pietra. A Maximum Entropy Approach to Natural Language Processing[C]//Proceedings of Annual Meeting on Association for Computational Linguistics(ACL). 1996: 39-71.
A Research on Chinese Colon Annotation and Automatic Identification
GU Jingjing,ZHOU Guodong
(School of Computer Science & Technology,Soochow University,Suzhou,Jiangsu 215006,China)
With the pragress of discourse analysis,punctuation researches have become an important entry to the analysis and disambiguation of discourse. Effective identificaton of the role of a punctuation in sentences;will help the development of syntax analysis,discourse analysis and other natural language processing technologies. The main task of this paper is to annotate and identify Chinese colon automatically. We adopt rule-based method and maximum entropy method. Rule-based method is relatively simpler and easier to implement. The maximum entropy method uses these rules into statistics,and gets better results in the experiments.
Chinese colon classification;maximum entropy;discourse analysis

谷晶晶(1986—),碩士研究生,主要研究領域為然語言處理。E?mail:20114227022@suda.edu.cn周國棟(1967—),博士,教授,主要研究領域為自然語言處理、信息抽取、統計機器翻譯、機器學習。E?mail:gdzhou@suda.edu.cn
2014-02-24 定稿日期: 2015-01-20
國家自然科學基金(61202162);教育部博士點基金(20123201120011)
1003-0077(2016)03-0016-07
TP391
A
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
