基于Nutch的搜索引擎的研究
2016-05-14 07:11:51杜旭升
電子技術(shù)與軟件工程 2016年6期
摘 要面對互聯(lián)網(wǎng)浩如煙海的信息,如何從中挑選出合理、排序公平的搜索結(jié)果是當(dāng)今的一大難題。Nutch擁有開放的結(jié)果排序算法,且具有一個大型分布式搜索引擎所需的基本功能,研究Nutch對于我們更加深入的了解搜索引擎具有突出的作用。
【關(guān)鍵詞】搜索引擎 Nutch
二十一世紀(jì)是互聯(lián)網(wǎng)的時代,隨著科技的發(fā)展,互聯(lián)網(wǎng)已經(jīng)深入到普羅大眾的日常生活中。然而面對如此巨量的信息,我們卻顯得不知所措。Nutch的誕生為我們從多如牛毛的信息中提取出相對公平客觀的信息提供了巨大的幫助。Nutch擁有搜索引擎的一些基本功能,并擁有自身特別的對網(wǎng)頁價值評定的算法,努力為使用者提供最合理的搜索結(jié)果。
1 Nutch簡介
Nutch是一個開源的、java實(shí)現(xiàn)的搜索引擎。雖然市場上已經(jīng)有比較成熟的幾款searcher engine,但并不妨礙我們對Nutch的研究,對Nutch的學(xué)習(xí)主要是因?yàn)椋?/p>
1.1 透明度
Nutch是一款開源軟件,因此任何開發(fā)者都可以看到它內(nèi)部的排序算法。因此Nutch比較適合對結(jié)果的公平性相對較高信息的查詢。
1.2 可以加深對搜索引擎的深入了解
Nutch的研究可以讓我們更好的了解到一個大型分布式的搜索引擎是如何工作的很有意義。
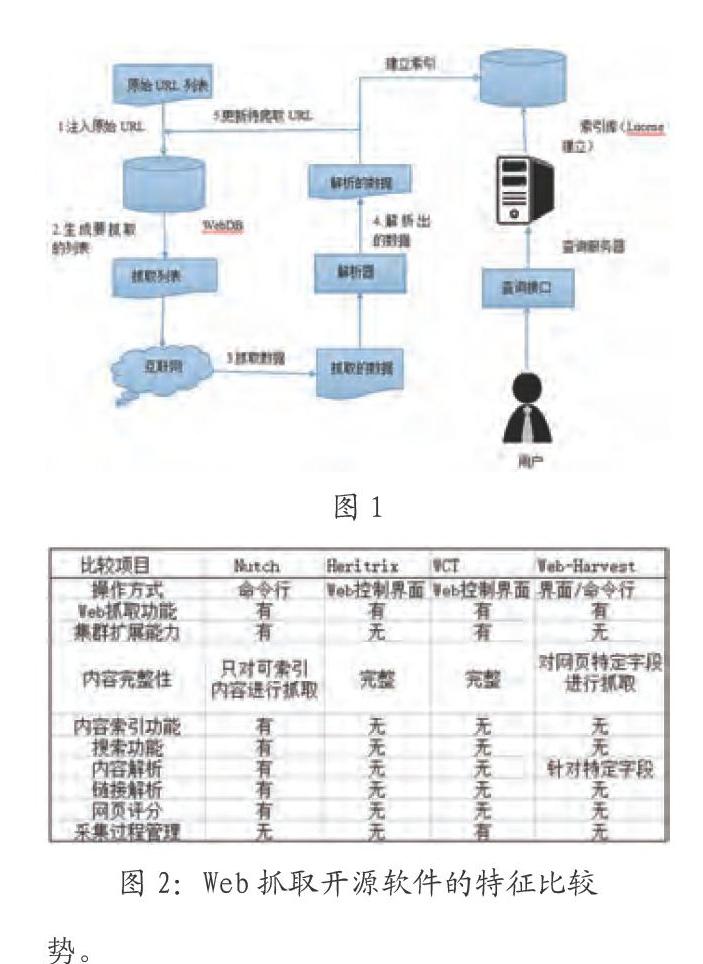
2 Nutch的系統(tǒng)結(jié)構(gòu)和工作流程
Nutch的基本組成主要包括爬蟲,索引,搜索三部分。其體系結(jié)構(gòu)如圖1所示。
Nutch由Web-DB、LinkDB、Segements和Index的數(shù)據(jù)結(jié)構(gòu)提供數(shù)據(jù)支持,Nutch整個的工作流程可以分為如下幾步:
(1)建立種子URL;
(2)將種子URL加入到crawlDB數(shù)據(jù)庫,整個網(wǎng)頁抓取過程將會從URL開始抓取,一直到指定的抓取層數(shù);
(3)創(chuàng)建抓取列表;
(4)執(zhí)行抓取,得到網(wǎng)頁內(nèi)容信息;
(5)更新數(shù)據(jù)庫;
(6)重復(fù)進(jìn)行3~5的步驟,直到預(yù)先設(shè)定的抓取深度。
(7)對于每一個Segement生成一個索引;
(8)從這些索引中刪除冗余的網(wǎng)頁和URL;
(9)將小索引合并成大的索引;
(10)用戶通過用戶端口進(jìn)行查詢操作;
(11)將用戶查詢轉(zhuǎn)化為Lucene查詢;
(12)返回結(jié)果。
3 Nutch的技術(shù)分析
Nutch主要由Crawler及Searcher組成。Crawler是從互聯(lián)網(wǎng)上抓取到網(wǎng)頁,并且給每個網(wǎng)頁建立一個特定的索引。Searcher則是利用crawler建立的索引根據(jù)用戶查找的關(guān)鍵詞來查找出結(jié)果。Crawler與Searcher的接口是索引。
3.1 Crawler的研究
Crawler的重點(diǎn)是其運(yùn)行過程和包含的data file的格式和含義。data file主要包括三類,web database,Segement以及index。Crawler詳細(xì)工作流程是:在創(chuàng)建一個WebDB之后,“產(chǎn)生/抓取/更新”循環(huán)根據(jù)一些種子URLs開始啟動。當(dāng)這個循環(huán)徹底結(jié)束,Crawler根據(jù)抓取中生成的Segement創(chuàng)建索引。在進(jìn)行URLs清除之前,每個Segement的索引都是獨(dú)立的。最終,各個獨(dú)立的Segement索引被合并為一個最終的索引index。
3.2 Nutch的網(wǎng)頁去噪
網(wǎng)頁去噪主要是去除掉廣告標(biāo)簽等無用的信息,盡量獲取到網(wǎng)頁的實(shí)質(zhì)性內(nèi)容,對于一個網(wǎng)頁,去噪過程包括以下步驟:
(1)在
標(biāo)簽中抽取正文題目,根據(jù)標(biāo)志字“by”,“l(fā)ast modified”等來抽取作者,修改日期等信息。
(2)利用HtmlParse去除掉各種腳本、圖片等信息,得到只有鏈接和文本的字符串。
(3)利用網(wǎng)頁的一般性特征去除掉導(dǎo)航欄文字,去除所有以“<”和“>”標(biāo)識的鏈接文字。
(4)去除版權(quán)聲明信息。
經(jīng)過上述四種方法,基本上能夠去除掉廣告、導(dǎo)航信息、客戶端代碼等相對沒有value的信息,對于獲得比較好的網(wǎng)頁內(nèi)容具有極大的幫助。
4 Nutch的對比分析
通過搜索,我們將Nutch與時下比較好的開源搜索引擎進(jìn)行對比測評,分別有Heritris、WCT、以及Web-Harvest。Nutch提供網(wǎng)頁的抓取,分析了解網(wǎng)頁、建立連接數(shù)據(jù)庫、對網(wǎng)頁進(jìn)行評分、建立Lucene索引和提供檢索界面登陸等。Heritrix提供了豐富的抓取設(shè)置選項(xiàng),完善的、精確的站點(diǎn)內(nèi)容深度復(fù)制。WCT能獲得目標(biāo)站點(diǎn)的深度采集授權(quán)、采集調(diào)度、資源描述等信息。Web-Harvest能以用戶所指定的網(wǎng)頁為抓取起始頁,通過規(guī)則表達(dá)語法進(jìn)行多層抓取,形成XML文檔。
從圖2可以看出,Nutch具有很強(qiáng)的對比優(yōu)勢。Nutch在抓取過程中,對于需要存儲空間較大,但又value不高的信息就有較高的優(yōu)勢。
5 Nutch待改進(jìn)的方面
經(jīng)過團(tuán)隊(duì)的不斷研究與測試,發(fā)現(xiàn)Nutch主要存在以下問題,影響了其性能的進(jìn)一步提高:
5.1 等待時間僵化
Nutch抓取網(wǎng)頁上的內(nèi)容主要是利用protocol-http實(shí)現(xiàn)的。N每下載一個頁面等待時間都是Nutch-default.xml配置文件預(yù)設(shè)的固定值:http.max.delays和fetcher.server.delay,這在不同的網(wǎng)絡(luò)情況下會造成時間的巨大浪費(fèi)。
5.2 抓取失敗的鏈接網(wǎng)站管理不夠
Nutch對于抓取失敗的網(wǎng)頁鏈接沒有詳細(xì)的監(jiān)管。可能某個網(wǎng)站關(guān)閉了,或者更換域名,但依然在其他的站點(diǎn)存在鏈接,如果被Nutch發(fā)現(xiàn)而且還一個一個去實(shí)驗(yàn),將會浪費(fèi)大量的時間和網(wǎng)絡(luò)資源。
6 結(jié)束語
Nutch由于透明的查詢算法,其搜索結(jié)果對用戶而言是比較公平的。然而Nutch離谷歌和百度等這些商業(yè)引擎依舊存在較大的差距,希望開發(fā)者們一起為Nutch的發(fā)展與完善貢獻(xiàn)出自己的一份力量。
作者簡介
杜旭升(1995-),男,甘肅省慶陽市人。現(xiàn)為新疆大學(xué)大學(xué)本科在讀學(xué)生。軟件工程專業(yè)。
作者單位
新疆大學(xué) 新疆維吾爾自治區(qū)烏魯木齊市 830000
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛(wèi)生(2015年12期)2015-11-10 05:13:38
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
新疆大學(xué)學(xué)報(bào)(自然科學(xué)版)(中英文)(2014年2期)2014-11-06 07:49:12
技術(shù)經(jīng)濟(jì)與管理研究(2014年11期)2014-03-11 17:02:44
計(jì)算機(jī)應(yīng)用文摘(2009年17期)2009-04-29 00:44:03
