分布式數據質量管理系統在電力企業的實踐和應用
2016-06-13 10:44:00李遠寧劉森張詩軍陳豐王志英
電信科學 2016年4期
李遠寧,劉森,張詩軍,陳豐,王志英
(中國南方電網有限責任公司信息部,廣東 廣州 510623)
分布式數據質量管理系統在電力企業的實踐和應用
李遠寧,劉森,張詩軍,陳豐,王志英
(中國南方電網有限責任公司信息部,廣東 廣州 510623)
隨著企業信息化水平和企業精細化管理要求的不斷提高,企業對數據管理的需求也隨之增強,如何提高企業數據質量更是需要重點解決的問題。 針對電力企業數據質量管理面臨的挑戰,創新提出了分布式數據質量管理解決方案。 針對集中式數據質量系統的性能瓶頸,在研究數據質量系統特點并借鑒國內外對大數據的解決方案后,提出了基于 Hadoop 分布式處理框架的解決方案。 利用 Hadoop 集群,可以把缺陷數據從 Oracle中抽離,分散存儲在集群里多臺服務器上,以有效提高磁盤 I/O 性能和數據分析性能。
數據質量管理;分布式;Hadoop
1 引言
隨著企業信息化水平和精細化管理要求的不斷提高,數據已成為企業的重要資源和核心資產,深刻影響企業的業務管理模式。企業數據質量水平,將關系到企業數據化管理、決策的效率和成效。
為促進數據質量水平的提升,電力行業開展了數據質量管理工作,并完成了數據質量管理系統的建設與推廣,生產、營銷、財務、人力資源等業務域的數據質量得到了顯著提升,但也面臨如下一些挑戰:
· 涉及范圍廣,涉及各分省公司的營銷、生產、人力資源、財務等業務領域;
· 校驗規則繁多,各業務域都有相應的數據質量校驗規則,涵蓋非空、長度、格式、一致性、準確性等類型的 規 則 ,共 計 4 000 多 條 ;
· 數據量大,經統計,全網月增量數據為 8 億筆,問 題數 據 為 3 000 萬 筆 ;
· 數據校驗耗時長,以營銷域為例,當校驗數據量達到 10億筆或以上規模時,原基于集中式數據存儲和計算架構的數據質量管理系統由于數據讀寫和數據統計操作瓶頸,完成數據質量校驗和問題分析需 耗 費 70 h 以 上 的 系 統 運 行 時 間 ;
· 需要在短時間內執行大量的校驗規則,對磁盤讀寫性能、CPU 和內存性能要求較高。
2 傳統的數據質量管理模式
傳統集中式數據質量管理系統可以規范化管理校驗規則、調度規則的執行時間、統一管理數據質量報告,大大提高了數據質量校驗的效率,并規范了數據質量的管理。數據量在千萬級以內時,可以穩定高效地完成數據質量校驗。
集中式數據質量管理系統 (以下簡稱集中式系統)主要包括兩大模塊,如圖 1所示。
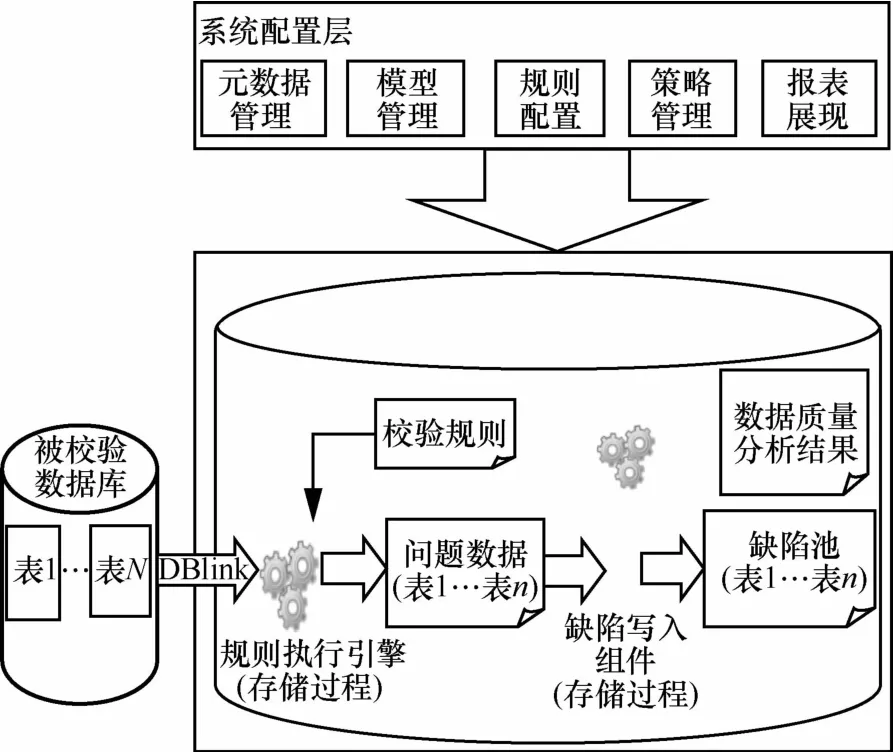
圖1 集中式數據質量管理系統架構
(1)系統配置層
用于配置校驗規則、執行策略、元數據等信息,查看數據質量分析結果。
(2)系統執行層
負責規則的執行和問題數據的存儲。質量校驗引擎采用 Oracle 存 儲 過 程 實 現 ,通 過 database link(DBlink)鏈 接 到“被校驗庫”執行預先配置好的校驗規則,統計并抽取查詢出來的問題數據。問題數據存儲在集中式系統數據庫里進行進一步的過濾、合并和分析,最終生成數據質量報告。
集中式系統使用關系型數據庫存儲和分析數據,當面對海量數據時數據庫服務器的性能往往會成為瓶頸。只 能 通 過 提 高 CPU 處 理 速 度 和 磁 盤 I/O 速 度 來 提 高 數據庫性能,但這意味著系統成本的增加,并且隨著數據的不斷增長,數據庫服務器很快又會成為性能瓶頸。圖 2展示了不使用索引和使用索引時,SQL 執行時間隨著數據 量 增 長 的 變 化 情 況 。可 以 看 出 ,數 據 量 在 500 GB 時 已出現瓶頸。
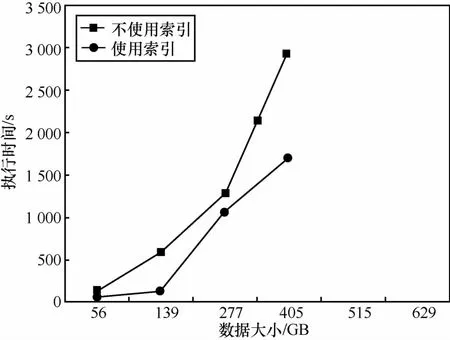
圖2 SQL 查詢性能
由此可見,傳統的集中式系統仍存在不足,需要引入新的解決方案,以提升企業在數據質量管理方面的能力。
3 數據質量管理的實踐
3.1 設計思路
針對集中式數據質量系統的性能瓶頸,本文在研究數據質量系統特點并借鑒國內外對大數據的解決方案后,提出 了 基 于 Hadoop 分 布 式 處 理 框 架 的 解 決 方 案 。 利 用Hadoop 集 群 ,可 以 把 缺 陷 數 據 從 Oracle 中 抽 離 ,分 散 存 儲在 集 群 里 的 多 臺 服 務 器 上 ,從 而 可 以 有 效 提 高 磁 盤 I/O 性能和數據分析性能。該方案具有以下優點:
· 基于 x86 服務器,可使用較廉價的服務器組建集群;
· 具有良好的可擴展性,當業務增長,需要處理更多的數據時,可以水平擴展和增加更多的節點;
· 集群的每個節點都可用于計算和存儲數據,可應對PB級別數據的存儲和分析。
3.2 分布式數據質量管理系統
分布式數據質量系統采用 J2EE 架構開發 ,可邏輯劃分為用戶交互層、數據處理層和數據存儲層,如圖 3 所示。
3.2.1 用戶交互層
用戶交互層即用戶界面,通過界面可以進行系統配置、規則管理、報告導出等操作。主要功能包括以下幾方面。
· 元數據管理:管理被校驗庫的元數據,包括表名、字段名、字段類型等信息。
· 模型管理:管理被校驗庫表之間的關聯關系。
· 規則配置:管理質量校驗規則,包括規則名稱、規則描述以及校驗腳本。
· 策略管理:管理校驗規則的執行時間和執行參數。
· 報表管理:管理數據質量報告,包括生成、上報、查看等功能。
· 平臺管理:管理組織機構、用戶信息、系統日志等。
用戶交互層是用戶與系統交互的界面,在進行系統設計時充分考慮了界面的可用性和 便 利性,結合 AJAX 技術降低系統的響應時間,提升了用戶使用體驗;為簡化校驗規則的配置工作,系統可根據元數據自動生成校驗規則的功 能 ,并 采 用 AJAX 技術 預 加 載 元 數 據 ,提 高 用 戶 操 作 流暢度,大大提高規則配置的效率;還提供規則參數的功能。利用該功能可以把規則中相似的部分抽取出來,配置成若干個規則參數,因此可以減少規則的數量,降低規則變更的響應時間。
3.2.2 數據處理層
數據處理層是整個系統的核心,負責規則執行、缺陷數據查詢分析等任務,主要功能包括以下幾方面。
·執行策略任務調度:負責控制執行策略的任務調度,按周期定時啟動執行策略。
· 缺陷數據分析:負責缺陷明細的分析,并生成數據質量報告。
· 規則執行引擎:負責執行規則腳本,記錄執行日志。
·缺陷明細查詢和導出:為用戶交互層提供從Hadoop 集群里查詢數據的接口。
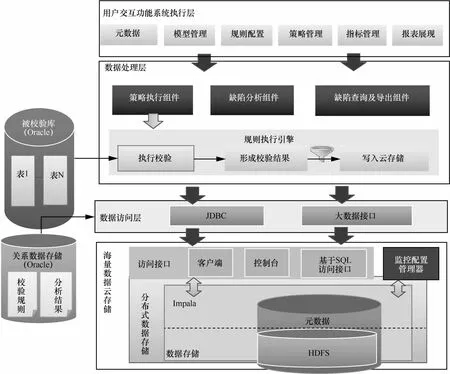
圖3 分布式數據質量技術架構
作為數據處理層的兩大核心組件之一,規則執行引擎是數據質量管理系統的關鍵所在,直接影響了校驗的效率。在設計規則執行引擎時主要考慮以下幾點因素。
性能是首先要考慮的問題。本系統的規則執行引擎采用 開 源 ETL 工 具 Kettle 作 為 缺 陷 數 據 抽 取 引 擎 ,Kettle 可以把一個表的數據“切片”進行多線程分段抽取,因此可以比較高效地把問題數據抽取到質量管理系統里。另外,執行引擎還采用緩存機制,執行規則時會優先從緩存中獲取結果以提高執行效率。
其次,穩定性是另一個重要因素。在數據質量管理系統里面,執行引擎里包含了大量的容錯處理機制。例如,在規則執行失敗后,執行引擎可以判斷失敗的原因并決定是否需要重試,如果遇到不可恢復的異常,則直接把規則標記為失敗并繼續執行下一條規則。
最后,還要考慮對數據源的適應性。為了擴大數據質量管理系統的使用范圍,執行引擎需要兼容多種主流的數據 庫 。目 前 已 兼 容 MySQL、SQL Server 和 Oracle,日 后 會 兼容更多類型的數據庫。
缺陷數據分析引擎是數據處理層的另一個核心組件。缺陷明細數據采集到 Hadoop 后 ,該引擎 對數據進行分析,生成并匯總結果,最終生成數據質量報告。為了加快數據分析的效率,系統把分析任務細分成多個更小規模的任務,當所有任務完成后再匯總生成最終的結果。
3.2.3 數據存儲層
數據存儲層由統一數據訪問接口以及數據存儲(含系統數據和缺陷明細數據)組成。其中,系統數據庫采用傳統的 關 系 型 數 據 庫 Oracle,用 于 存 放 系 統 配 置 、執 行 日 志 、規則信息和缺陷數據分析結果;而缺陷數據明細存儲采用Hadoop 分布式處理框架。
(1)統一數據訪問接口
系統使用 Hadoop 集群存儲缺陷 明細數據 ,為了能 更簡 單 、快 捷 地 分 析 數 據 ,基 于 Impala 框 架 封 裝 了 通 用 數 據訪 問 接 口 ,兼 容 Oracle 和 分 布 式 架 構 下 的 數 據 訪 問 ,能 在Hadoop 集 群 上 運 行 本 地 SQL, 可 以 為 存 儲 在 HDFS 或HBase 中 的 Hadoop 數 據 提 供 快 速 、交 互 式 的 SQL 查 詢 ,查詢 效 率 比 基 于 MapReduce 的 Hive 有 數 量 級 的 提 升 。
(2)資源監控
由于集群用到多臺服務器,因此如何便捷、直觀地監控每臺服務器當前的狀態,成為系統實施與維護首先要考慮 的 問 題 。數 據 質 量 管 理 系 統 使 用 Cloudera Manager(免 費版)作為 Hadoop 集群管理和監控的工具 ,并進行了適當優化 ,提 供 了 一 個 B/S 結 構 的 管 理 界面 ,用戶 可 以 實 時 查 看到集群里每一臺服務器的健康狀況、資源使用率、任務執行情況等信息。
3.3 主要創新點
(1)利用分布式技術解決傳統關系型數據庫的性能瓶頸
數據質量管理系統具有數據量大、數據增長快以及分析任務繁重等特點。傳統關系型數據庫在應對這樣的大數據量場景時,數據分析性能迅速下降,已難以滿足實際的應用需求。本研究提出使用 Hadoop 分布式架構重構系統中數據量較大的模塊,關系型數據庫只用于存儲分析結果。本系統采用了基于 Impala 框架封裝的數據分析引擎,開發人 員可以使 用熟悉的 SQL 語言進行數 據分 析 ,以降低 Hadoop集群的應用門檻。利用 Hadoop 集群可以輕易實現數據的水平分布,從而大大提高系統的可用性和數據分析性能。
(2)使用多線程并行技術提高數據質量校驗引擎的性能
為了能最大限度地利用分布式系統的硬件資源,提出了基于多線程的校驗規則執行引擎。執行引擎能根據規則數量和當前系統負載情況動態創建線程池,其中包括問題數據查找和問題數據寫入兩種。在進行數據質量校驗的過程中,系統根據問題數據寫入和問題數據查找的情況自動創建或銷毀線程,同時應用“數據切片”技術把數據按照線程的數量平均切分,配送到不同的線程以提升數據處理效率。利用多線程技術可以充分利用服務器的硬件資源,極大地提升性能。
(3)基于元數據自動生成數據質量校驗規則
數據質量管理系統需要管理成千上萬的校驗規則,在提高校驗性能的同時也需要提高校驗規則配置的效率。元數據描述了數據庫表關系以及數據表字段的詳細信息,如字段類型、長度、數據來源、加密等級、數據質量要求等。本文創新提出了基于元數據的數據質量校驗規則自動生成功能,用戶只需在界面選擇需要進行校驗的表和字段,系統即可根據元數據中的數據質量要求自動生成校驗規則,提高了規則配置的準確性,并且大大節省了人工成本,提高了規則配置效率。目前,營銷、生產、財務、人力資源等業務領域約 3 255 條 校 驗 規 則 均 通 過 此 方 法 生 成 。
4 系統實踐
4.1 性能對比測試
實際測試表明,分布式系統具有優秀的水平擴展性,隨著 數據量 的增長,Hadoop 集群的執 行時間 幾 乎 呈 線 性增 長 。 應 用 集 中 式 架 構 的 平 均 數 據 讀 取 速 度 為 150 MB/s,讀 取 1 TB 的 數 據 需 要 約 2 h;Oracle 的 處 理 時 間 則 呈 指 數級增加,如 圖 4 所 示 。可 以 看 出 ,當數據量達到 500 GB 時 ,在 Oracle 上執行 SQL 已出現性能瓶頸。
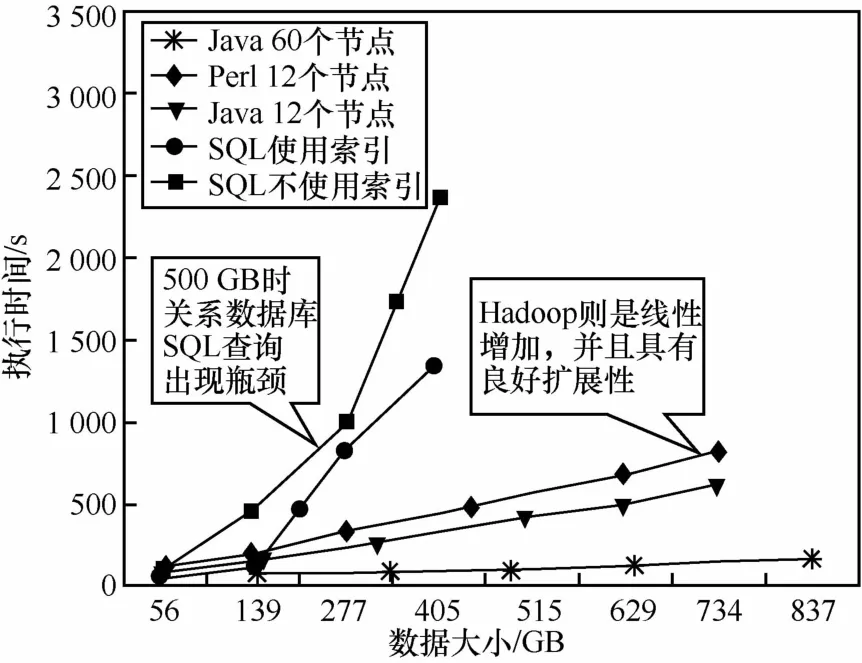
圖4 關 系型數據庫與 Hadoop 集群執行時間對比
4.2 應用情況
目前分布式數據質量管理系統已完成開發,并在廣西電網公司、廣東電網公司試運行,根據現場收集的運行數據,應用分布式數據質量管理系統,最高可實現數據質量校驗效率比原集中式系統提升 15倍左右。
服務器配置信息見表 1。

表1 服務器配置信息
數據質量校驗情況見表 2。

表2 數據質量校驗性能對比
從表 2可以看出,分布式系統的性能比集中式系統有數量級的提升。 由于客觀因素的限制,廣東電網公司的被校驗庫和 Hadoop 集群部署在 不同的子網絡,受到網絡和防火墻的影響,校驗時間要長于廣西電網公司。
5 結束語
本文針對電力企業數據質量管理工作的現狀和難點,提出了分布式數據質量管理系統解決方案,通過開展分布式存儲和計算關鍵技術研究,初步搭建大數據存儲及計算平臺,并針對數據質量管理子系統進行了技術架構升級和試 點 應 用 ,原 需 45 h 的 數 據 質 量 校 驗 工 作 時 間 縮 短 至 3 h以內,有效提升了系統處理和分析效率,同時為中國南方電網公司數據中心架構升級工作儲備了技術基礎。
[1] 田 秀 霞 , 周 耀 軍. 基 于 Hadoop 架 構 的 分 布 式 計 算 和 存 儲 技 術及其應用[J]. 上海電力學院學報,2011,27(1):70-75. TIAN X X,ZHOU Y J.The technology and application of distributed computing and storage based on Hadoop architecture[J]. Journal of Shanghai University of Electric Power,2011,27 (1):70-75.
[2] BIRMAN K P,GANESH L,RENESSE R.Running smart grid control software on cloud computing architectures[C]/Workshop on Computational Needs for the Next Generation Electric Grid,April 19-20,2011,Cornell University,Ithaca.[S.l.:s.n.],2011:1-28.
[3] 劉 鵬. 云 計 算 [M]. 北 京 :電 子 工 業 出 版 社 ,2010. LIU P.Cloud computing [M ].Beijing:Publishing House of Electronics Industry,2010.
[4] REESE G.Cloud application architectures:building applications and infrastructure in the cloud [M].New York:OˊReilly Media,2009.
[5] 辛 軍 ,陳 康 ,鄭 緯 民. 虛 擬 化 集 群 管 理 技 術 研 究 [J]. 計 算 機 科學與探索,2010(4):325-327. XIN J,CHEN K,ZHENG W M.Studies on virtualization of cluster resource management technology[J].Journal of Frontiers of Computer Science and Technology,2010(4):325-327.
[6] HDFS scalability with multiple NameSpaces [EB/OL].[2015-09-20].http:/issues.apache.org/jira/browse/HDFS-1052.
[7] WHITE T.Hadoop:the definitive gide[M].New York:OˊReilly Media,2009.
[8] Hadoop apache project [EB/OL]. [2015-09-20].http:/hadoop. apache.org.
[9] GHEMAWAT S,GOBIOFF H,LEUNG S T.The Google file system [C]/SOSP,October 19-22,2003,Bolton Landing,New York,USA.New York:ACM Press,2003.
[10]陳 遠 ,羅 琳. 信 息 系 統 中 的 數 據 質 量 問 題 研 究 [J]. 中 國 圖 書館學報,2004(1):48-50. CHEN Y,LUO L.Research on data quality in information system[J].Journal of Library Science in China,2004(1):48-50.
[11]胡 金林,梅士 員. 基 于 元 數 據 擴 展 的 空 間 數 據 質 量 管 理 方 法[J]. 現 代 測 繪 ,2004,27(3):21-24. HU J L,MEI S Y.The extended metadata method of spatial data quality management [J].Modern Surveying and Mapping,2004,27(3):21-24.
Practice and application of distributed data quality management system in power enterprise
LI Yuanning,LIU Sen,ZHANG Shijun,CHEN Feng,WANG Zhiying
Information Department of China Southern Power Grid Co.,Ltd.,Guangzhou 510623,China
As the improvement of the enterprise’s informationalization level and the increasing management requirement of enterprise refinement,the demand of data management of enterprise is becoming greater and greater,how to improve the data quality of the enterprise is the key problem needed to be solved.Aiming at the challenges of data quality management that the power enterprise faces,some solutions for distributed data quality management were proposed.After researching the system features of data quality,some foreign and domestic cases of big data were analyzed as reference,and a solution based on Hadoop distributed processing framework was given to solve the performance bottleneck of centralized data quality system.Hadoop clustering could dissociate defect data from Oracle and the data would be stored separately on multiple servers of the clustering,which could improve the I/O performance and data analysis performance of the magnetic disk effectively.
data quality management,distributed,Hadoop
TP391
:A
10.11959/j.issn.1000-0801.2016104

李遠寧(1981-),男,博士,中國南方電網有限責任公司信息部高級工程師,主要從事大數據分析及應用工作。

張詩軍(1973-),男,中國南方電網有限責任公司信息部高級工程師,主要從事數據管理、管理信息化工作。

陳豐(1973-),男,中國南方電網有限責任公司信息部工程師,主要從事管理信息化、架構設計工作。

劉森(1983-),男,博士,中國南方電網有限責任公司信息部工程師,主要從事大數據分析及應用工作。

王志英(1962-),男,中國南方電網有限責任公司信息部教授級高級工程師,主要從事管理信息化、架構設計工作。
2015-09-20;
2016-03-11
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
Coco薇(2017年11期)2018-01-03 20:59:57
商周刊(2017年22期)2017-11-09 05:08:31
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
汽車觀察(2016年3期)2016-02-28 13:16:26
河南電力(2015年5期)2015-06-08 06:01:46
