基于聚類的熱詞發現與關聯分析
2016-06-22 09:18:02羅旭歐陽純萍劉志明南華大學計算機科學與技術學院衡陽421000
現代計算機 2016年14期
羅旭,歐陽純萍,劉志明(南華大學計算機科學與技術學院,衡陽 421000)
?
基于聚類的熱詞發現與關聯分析
羅旭,歐陽純萍,劉志明
(南華大學計算機科學與技術學院,衡陽421000)
摘要:
關鍵詞:
0 引言
隨著互聯網的日益普及,網絡往往成為有影響力事件發布的第一平臺,然而網絡上產生新聞的速度遠遠超過人所接受的程度,如果采用人工分檢的方法,肯定不能達到快速得知當前互聯網的熱點信息。因此,對熱詞進行快速識別,并對我們想要了解的熱詞加以關注,迅速分類與這些熱詞相關的新聞,可以快速了解當前輿情,及時對熱點信息作出處理。
在新聞話題的發現技術中,聚類算法應用較廣。習婷等[1]將兩種聚類算法Single-Pass和K-means進行了比較,認為K-means雖然錯檢率和漏檢率較低,但具有需要預先制定聚類數目和隨機初始化的缺點。王偉等[2]通過對樣本網頁文本的特征提取,構建文本向量空間模型,使用OPT ICS聚類算法獲取網頁熱點簇,并且為了更加精確,還根據熱點簇特征向量對網頁進行二次聚類,從而獲取關于輿情的時間演變模式。袁方等[3]為了改善傳統K-means對初始聚類中心敏感,計算每個數據對象所在區域的密度,選擇相互距離最遠的k個處于高密度區域的點作為初始聚類中心,得到較好的聚類結果。
在如何得到熱詞關聯關系中,李渝勤等[4]采用命名實體識別技術和高頻串統計技術進行短語串的劃分,再進行熱度權值的計算,通過同現率的原則確定熱詞類之間的關聯計算。
僅僅依靠同現率來確定熱詞類之間的關聯度存在一定的局限性,熱詞的出現是成簇的出現的,因此本文將新聞話題與熱詞關聯結合起來,選擇K-means聚類算法得到話題,由話題得到相應的熱詞類簇,再由熱詞類簇計算熱詞關聯度。較為有效地展現當前的熱詞類的分布以及熱詞之間的關系。
1 熱詞發現系統功能及方案設計
以“南華大學”為新聞輿情監測目標,具體提供熱詞統計,展示熱詞關聯關系等功能。我們圍繞這些功能,主要完成以下工作:第一,將新聞從數據庫中提取并進行分詞,以及去除停用詞等預處理;第二,在熱詞發現模塊,進行tf-idf計算以構建VSM模型,然后使用K-means聚類算法對新聞進行聚類,得到熱詞類簇并進行相應處理;第三,計算熱詞關聯度,由聚類得到的熱詞類簇和新聞同現率等結合一塊得到熱詞關聯關系,最后進行展示。具體步驟之間的聯系如圖1所示:
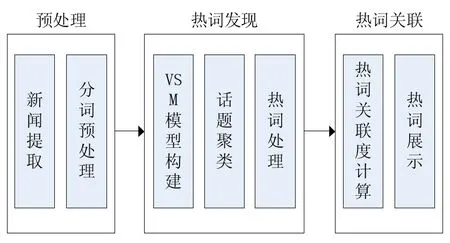
圖1 熱詞發現與關聯分析框圖
2 熱詞發現與關聯分析關鍵技術
2.1VSM模型構建
在最開始對新聞文本做分詞處理,采用開源的Hanlp漢語言處理包中基于條件隨機場的分詞方法。在熱詞中,往往新詞出現的頻率較高,采用CRF分詞較為合理。
要得到一篇文本的向量空間模型,首先得計算文本中每一個詞匯的權重大小。本文采用以TF-IDF值作為詞匯的權重值,首先計算加權詞頻因子tf,以計算詞匯在文本出現的頻率作為tf值。
IDF逆向文件頻率是一個詞語普遍重要性的度量。某一特定詞語的IDF,可以由總文件數目除以包含該詞語的文件的數目,再將得到的商取對數得到:
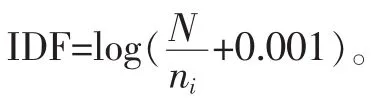
在此之上,結合了出現在文檔中不同位置的詞的特性[5],如meta中keyword、title和description等關鍵詞在文檔中的權重,因此tf值為
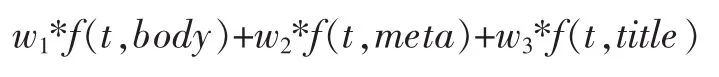
f(t,body)表示是詞匯在文本正文中出現,f(t,meta)則是在網頁的meta信息中出現,f函數對應各自詞匯的tf-idf值,w1,w2,w3是相應的權重系數。
在計算idf的過程,因為需要得到包含該當前詞匯的文件的數目,需要多次遍歷計算,本系統因此做相應的優化,預處理各個詞匯的idf值,使得計算速度大大加快,算法復雜度由O(n2)降到O(nlogn)。
接下來進行特征選取,如果抽取所有文本詞匯作為文本特征向量集合,因為分詞之后的詞匯量極大,因此有必要對文本特征向量集合做降維處理,根據詞權值篩選出部分詞匯作為全局文本特征向量。最后就是建立每一篇文本新聞的向量空間模型,對應每一篇文本新聞,將其自身的文本特種向量投影到全局文本特征向量,由此可得到向量空間模型。對于每個新聞文本i,設Ti為其特征向量,k(i,j)是全局特征向量中的詞,w (i,j)是其在當前文本i中詞匯j對應的特征權值,m為全局特征詞向量中的總個數,文本可表示為Ti=[(ki,1,wi,1),(ki,2,wi,2),(ki,3,wi,3),…,(ki,j,wi,j),…,(ki,m)]。
因為各個詞匯的特征權值因為新聞文本的差異,會導致某些值過于太大或太小以至于某一維或某幾維對數據影響過大,因此對向量進行歸一化處理,對于在特征向量中的每一個詞
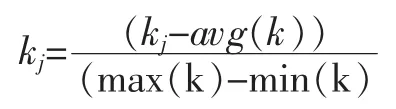
2.2話題聚類
聚類可以認為是非監督學習中最重要的問題。K-means算法基于目標的特征將目標分為K類,K為事先定義。基本思想就是定義K個中心,每一類簇都有一個中心,類簇里的物體是以計算相似度函數的大小為基準相對靠近而聚集。
算法步驟如下:預先定義K大小,隨機選擇K個文本向量作為中心,之后對于剩下的每一個文本,計算其到每一個類簇中心的歐幾里得距離,并將其劃分到最近的類簇中,遍歷分配完后,重新計算每個類簇的中心,不斷循環直到1.聚類中心不再移動或者2.迭代次數達到指定次數。算法時間復雜度是O(K*N*T),k是中心個數,N數據集的大小,T是迭代次數。
在選取初始中心時,算法對初始聚類中心敏感,從不同的初始聚類中心出發,得到的聚類結果也不一樣,并且一般不會得到全局最優解。本系統則采用取相互距離最遠的k個點作為初始中心,消除算法對初始聚類中心的敏感性,并能得到較好的聚類結果[3]。
對于文本相似度計算,采用了比較傳統的夾角余弦值計算各特征項之間的距離,并且同各個類簇中心的值作比較,歸類到一個和其相似度最大的類簇。向量A與向量B的夾角余弦值如下計算:
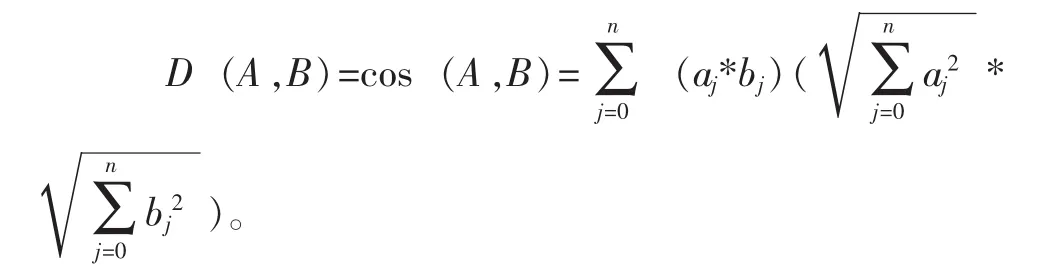
2.3熱詞關聯分析
熱詞與熱詞之間是有聯系的,這一塊將之前話題聚類得的話題進一步處理,得到詞與詞之間,詞群與詞群之間的聯系。
具體步驟如下:取SVM向量模型中的全局文本特征向量作為展示熱詞。聯系的表現形式為矩陣,兩兩之間有相應對應關系,關系權值即為熱詞的關聯度。矩陣由三個部分構成,新聞同現率矩陣,類別距離矩陣,熱詞同現矩陣。三個矩陣賦予相應的權重系數,進行累加既可得到最終的熱詞關聯矩陣。
(1)新聞同現率矩陣定義為任意兩個熱詞代表的新聞集合中重疊的大小。在之前的聚類模塊中,可以得到每個熱詞具有的新聞集合,遍歷兩者既可得到相應的重疊率。
(2)類別距離矩陣定義為由聚類得到不同的詞群,詞群內部的關聯度以及詞群與詞群的關聯度就是類別距離矩陣。遍歷每一個類簇中心,在這里稱為詞群,得到中心權重向量,為不保證權重太大或太小,進行歸一化處理。在這里,因為詞與詞互相都有關聯,矩陣將兩步處理,第一步,在同一個詞群里的詞匯,以權重最大的詞為中心點,其他詞只與這個中心點形成關聯,這樣形成一個星狀的發散結構,使得展示較為明晰。第二步,對于其它詞也就是其他詞群的詞,以較小權值向量作為關聯值。
(3)熱詞同現矩陣定義為兩個熱詞在同一文章中出現的幾率。因此遍歷所有新聞查看是否有同時出現即可。
最后,新聞同現率和熱詞同現矩陣都要進行矩陣歸一化處理,要保證矩陣最后均要大于零,

同時考慮到矩陣中大部分關聯值為零,歸一化反而使得這些值不為零,所以特殊化處理,不考慮這些零值。三者矩陣加權累加即可得到關聯矩陣。
3 系統實現
本系統以南華大學相關新聞為輿情監測目標,因此采集的新聞也以南華大學新聞為主,選擇2015-08-28到2015-10-04之間新浪、騰訊、紅網、鳳凰等有關南華大學的298篇新聞。因為新聞來源廣泛,內容復雜隨機,可能會引入不相干的數據。因此,在分詞階段還要進行相應的過濾,去除與南華大學不相關的“香港《南華早報》”新聞,“臺灣南華大學”等,以及去除相應的停留詞。
得到所有新聞分詞后的詞匯后,對這些進行tf-idf值計算,根據各個詞的tf-idf值進行排序,篩選出10%的詞匯,去重,作為全局文本特征向量。其次建立VSM模型,例如隨機抽取一篇來自新浪的新聞“南華大學分專業靠抓鬮招生后細化專業如何分流?”,其部分特征向量權重值如表1所示。
通過K-means獲得K個類簇中心,這里預先指定k=5,從而聚類獲得5個新聞熱點類簇。具體如表二所示:
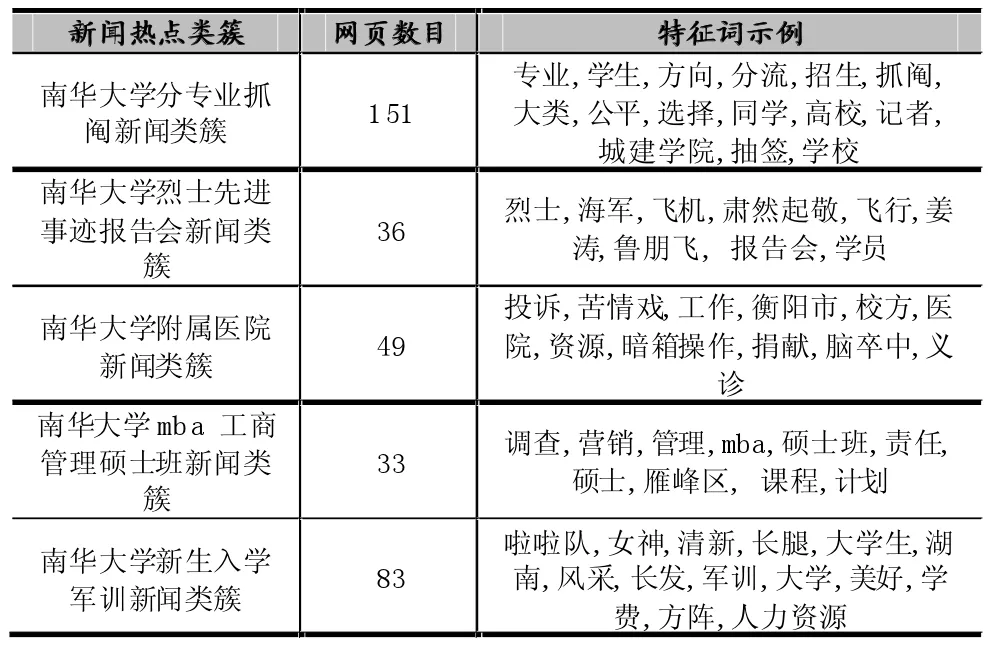
表2 新聞熱點類簇
可以看到雖然新聞的熱點信息多樣化,但是聚類還是能夠取得一個比較明顯的熱點區分。但是在各個熱點類簇下還存在著很多與此熱點不相干的新聞,精度還需要有所提高。

表1 新聞VSM模型
在得到熱點類簇后,要對熱詞進行處理,添加熱詞的情感的褒貶程度以及敏感程度,進而得到每個熱詞的熱度,并且根據類簇添加與之相關的新聞。因在展示時,熱詞不能太多,將全局特征詞按照熱詞熱度權值進行過濾,只獲取1.5%的熱詞。由熱詞關聯度模塊得到關聯矩陣。進行展示如圖2所示:

圖2 熱詞關聯展示
圖中關于“專業靠抓鬮”以及“海軍先進事跡報告”的新聞熱詞較為集中,清晰地展現了兩個事件具有很高的熱度。根據圖中節點的大小來展示不同的熱度值,熱度越高的詞所在的節點面積將越大。例如,“專業”在這些新聞里具有極高熱度因此也是最為明顯的。但是不少的雜詞的混入以及詞匯的相對松散,導致其余熱詞事件不夠明顯。
4 結語
熱詞發現及關聯分析已經被廣泛應用,能夠較為清晰地反映當前發生的新聞事件。本文提出把K-means聚類算法得到的話題運用到計算熱詞關聯度上,能夠有效地提供熱詞統計,展示熱詞關聯關系。然而K-means聚類算法具有必須預先指定K數目,才能進行聚類的缺陷。但在實際中,熱點數目往往是未知的,具有不確定性,因此可以考慮采用改進的Single-Pass增量聚類等算法替代K-means算法。另外,在熱詞選擇中,熱詞隨時間推移會出現突然的變化,即時間因子對于熱詞具有非常明顯的印象,因此下一步可以將時間因素考慮進去。
參考文獻:
[1]Ting,X.and L.Jufang,A Comparative Study between Single-Pass Algorithm and K-means Algorithm in Web Topic Detection.Atlantis Press,2014.
[2]Wei,W.,X.Xin.基于聚類的網絡輿情熱點發現及分析*.現代圖書情報技術,2009,3(3):74-79.
[3]袁方,周志勇,宋鑫,初始聚類中心優化的K-means算法[J].計算機工程,2007,33(3):65-66.
[4]李渝勤,孫麗華,面向互聯網輿情的熱詞分析技術.中文信息學報,2011,25(1):48-53.
[5]GESANG,D.,et al..基于Single-Pass的網絡輿情熱點發現算法.電子科技大學學報,2015(4).
Hot-Word Detection and Relations Analysis Based on Document Clustering
LUO Xu,OUYANG Chun-ping,LIU Zhi-ming
(School of Computer Science and Technology,University of South China,Hengyang 421000)
Abstract:
Proposes a method to discover hot-word relations based on topic clustering.For word discovering,vector space mode is built by extracting document features from news text,and the hot -spot cluster is achieved by K-means algorithm with ameliorated initial center.Up to the hot-word association,hot words relations are analyzed according to the weighted sum of three factors,which include the word category distance computed by the hot -spot cluster,the news co -occurrence rate and the hot words co-occurrence rate.This approach has been successfully applied to Public Opinion Monitoring System of University of South China and it obtains good results in practical operation.
Keywords:
提出一種將話題聚類算法應用到計算熱詞關聯度上的方法。在熱詞發現階段,通過對新聞文本的特征提取,構建向量空間模型,采用初始聚類中心優化的K-means算法,獲取熱點簇;在關聯分析階段,先通過熱點簇計算詞類別距離,再和新聞同現率,熱詞同現率加權累加,得到熱詞關聯度。該方法已成功應用到南華大學輿情監測系統中,并在實際運行中獲得較好的效果。
K-means;SVM;熱詞;詞群關系
基金項目:
湖南省哲學社會科學基金(No.14YBA335)
文章編號:1007-1423(2016)14-0056-05
DOI:10.3969/j.issn.1007-1423.2016.14.012
作者簡介:
羅旭(1993-),男,江蘇泰興人,本科,研究方向為自然語言處理、數據挖掘
歐陽純萍(1979-),女,湖南衡陽人,副教授,碩士生導師,研究方向為自然語言處理、語義網
劉志明(1972-),男,湖南瀏陽人,教授,碩士生導師,研究方向為大數據分析、知識工程
收稿日期:2016-03-25修稿日期:2016-04-30
K-means Algorithm;SVM;Hot Words;Words Relationship
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年15期)2019-09-02 01:52:00
電子制作(2018年18期)2018-11-14 01:48:06
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
