分類變量缺失數據處理方法有效性的比較研究*
2016-06-24 02:48:03哈爾濱醫科大學衛生統計教研室150086肖亞明陳永杰王玉鵬劉美娜
中國衛生統計 2016年2期
哈爾濱醫科大學衛生統計教研室(150086) 肖亞明 陳永杰 王玉鵬 劉美娜
?
分類變量缺失數據處理方法有效性的比較研究*
哈爾濱醫科大學衛生統計教研室(150086) 肖亞明 陳永杰 王玉鵬 劉美娜△
【提 要】 目的 比較刪除法(deletion methods,DM)、基于對數線性模型的多重填補法(multiple imputation of category variables using log-linear model,MILL)及基于潛在類別模型的多重填補法(multiple imputation based on latent class model,MILC)處理分類變量缺失數據的效果,并將MILC應用于實例數據的分析。方法 利用R語言產生不同缺失機制、缺失率和樣本含量的多變量缺失模擬數據,運用DM、MILL和MILC處理形成完整數據集并進行logistic回歸分析,通過回歸系數的偏倚、均方根誤差、穩定度和標準誤偏倚評價各方法的處理效果。結果 模擬實驗表明當缺失率為5%時,三種方法處理效果均較好;隨著缺失率的增大,MILL和MILC的各項評價指標均優于DM,且MILC的準確度高于MILL。三種方法處理效果均表現為完全隨機缺失優于隨機缺失、樣本含量1000優于樣本含量500。應用MILC對實例數據填補后標準誤減小,回歸系數估計更準確。結論 本文應用MILL和MILC兩種多重填補方法處理分類變量缺失數據均可減少缺失導致的參數估計偏倚。當缺失率>5%、樣本含量1000時,建議應用MILC處理分類變量缺失數據。
【關鍵詞】分類變量 缺失數據 多重填補 潛在類別模型 對數線性模型
缺失數據問題普遍存在于橫斷面研究、隊列研究和實驗性研究[1],尤其在問卷調查中,即使對調查設計和問卷進行了嚴謹的科研設計,被調查者仍易忽略題目或不作答而導致數據缺失,這對統計分析中的參數估計、檢驗效能有不同程度的影響[2]。刪除法(deletion method,DM)直接刪除含缺失值的個體以期得到完整數據集,是應用最廣且簡單易行的缺失數據處理方法,也是幾乎所有統計軟件默認的方法。隨著人們對缺失數據的認識加深,缺失數據處理方法的策略不斷推新,Rubin[3]首次提出多重填補(multiple imputation),經過Schafer,Meng等人完善并綜合形成系統理論,成為目前處理缺失數據的基本思想。基于對數線性模型的多重填補法(multiple imputation of category variables using log-linear model,MILL)[4]以飽和對數線性模型作為填補模型,易于理解和實現;基于潛在類別模型的多重填補法[5](multiple imputation based on latent class model,MILC)結合潛在類別模型和多重填補的思想對數據進行填補,參數估計較飽和對數線性模型簡單且靈活。目前國內沒有MILL和MILC的比較研究,本文擬針對刪除法、MILL及MILC進行數據模擬和處理效果評價,為分類變量缺失數據的處理提供相應依據,并將MILC應用于慢性心力衰竭的院內死亡影響因素的研究。
原理與方法
多重填補法的基本思想:通過填補模型為每個缺失值產生M個可能的填補值,形成M個完整數據集,通過分析模型對每個完整數據集進行分析得到參數集,綜合M個參數集[3]進行最終的統計推斷。
1.基于對數線性模型的多重填補法
對數線性模型主要通過對列聯表單元格的頻數取對數分析變量間的關系,這些關系可包含變量的高階交互項,當模型中涵蓋變量間所有高階交互項時稱該模型為飽和模型。MILL處理缺失數據時首先對不含缺失的完整數據集進行對數線性模型分析得到原始各響應變量的類別概率(response category probability),應用貝葉斯原理從這一參數的后驗分布中獲取M個參數;分別根據每個參數對含缺失的個體進行填補值的抽取。
2.基于潛在類別模型的多重填補法
潛在類別模型(latent class model,LCM)是利用潛在類別解釋外顯變量之間復雜關聯性分析方法,屬于潛變量分析的一種。Vermunt首次將LCM作為填補模型對分類變量缺失數據進行多重填補,填補模型中加入指示變量rij表示數據缺失情況,rij=1表示yij有觀測值,rij=0表示觀測值缺失,MILC模型見公式(1)。

MILC填補步驟[5-6]:首先對含缺失的數據集進行非參bootstrap抽樣獲得M個數據集;每一數據集經過LCM分析計算潛在類別概率和外顯變量的條件概率;觀測根據后驗類別屬性概率(posterior class membership probabilities)分類到適當的潛在類別中,計算公式見公式(2);含缺失的觀測根據所在潛在類別中變量的多項分布概率為缺失值選取填補值。
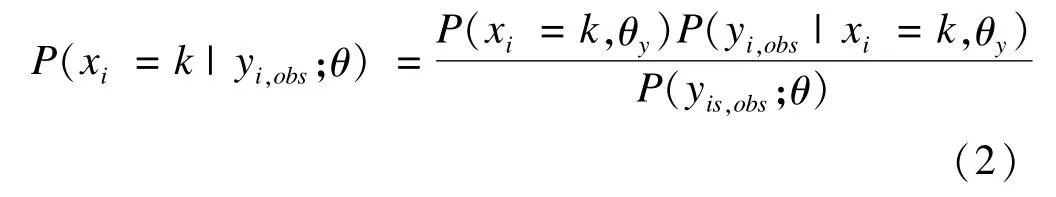
模擬實驗
1.參數設置
(1)原始數據
因變量y和五個自變量x1~x5均為二分類變量,取值為0、1;自變量x1~x5間相關關系滿足對數線性模型,見公式(3);因變量由logistic回歸模型產生,見公式(4)。
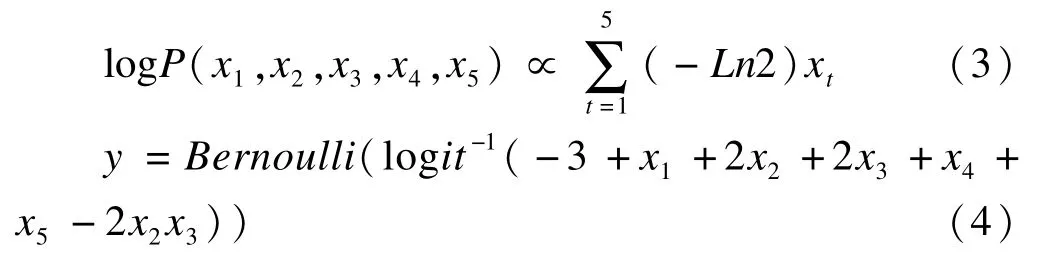
(2)缺失數據
自變量x1和x2設置為缺失變量。缺失機制為MAR時,x1的缺失與x3及x4相關,x2的缺失與x5及y相關,參數設置見公式(5)和(6)。

(3)樣本含量設置為500、1000;缺失機制設置為MAR、MCAR;單變量缺失率設置為5%、20%、40%;填補次數M =5次;MILC中潛在類別個數K =5;各參數組合均重復模擬500次。
2.評價指標
評價指標包括參數偏倚,穩定度,均方根誤差和標準誤偏倚。
3.軟件實現
模擬實驗MILL選擇飽和模型,使用R語言“cat”軟件包[7]實現。MILC實現的軟件很多,如Latent GOLD 4.0/4.5[3],LEM,Mplus及R語言“poLCA”軟件包[8],本文模擬實驗采用Latent GOLD 4.5。
4.模擬實驗結果
表1可見三種方法處理數據的偏倚隨著缺失率的增大而增大,樣本含量大時偏倚減小,缺失機制為MAR的偏倚比MCAR大,總體上βa的偏倚小于βb及βbc。當缺失率為5%時,DM與兩種多重填補法相比參數估計的偏倚較小,處理效果較佳;隨著缺失率的增大,DM法偏倚明顯增大,MILL和MILC的偏倚也隨之增大,但均優于DM。
隨著缺失率的增大,三種方法處理后參數的準確度下降,缺失機制MCAR比MAR的參數準確度高;樣本含量1000的RMSE比樣本含量500小;MILC和MILL處理后的βb和βbc估計準確度明顯優于DM,見表2。
表3可見隨著缺失率的增大,三種方法處理后的參數穩定性變差;樣本含量1000比樣本含量500的參數更穩定;缺失機制MAR和MCAR的穩定度相近;樣本含量500、缺失率為40%時,DM的參數穩定性極差,MILC和MILL保持了β系數的穩定估計。
樣本含量為500時,MILL和MILC標準誤偏倚明顯小于DM,MILL處理效果稍優于MILC;樣本含量為1000時,三種方法的標準誤偏倚均減小,MILC小于MILL;三種方法處理后的標準誤偏倚均隨缺失率的增大而增大,MCAR條件下標準誤偏倚整體上小于MAR,見表4。

表1 不同缺失數據處理方法各參數條件下logistic回歸系數的Bias結果

表2 不同缺失數據處理方法各參數條件下logistic回歸系數的RMSE結果

表3 不同缺失數據處理方法各參數條件下logistic回歸系數的sd結果

表4 不同缺失數據處理方法各參數條件下logistic回歸系數的bse結果
實例應用
本文實例數據來自20家三甲醫院中診斷為慢性心力衰竭(chronic heart failure,CHF)的病歷資料,共收集1896例,其中心功分級缺失833例,缺失率為43.9%,入院時病情缺失34例,缺失率為1.8%。本文應用MILC處理含缺失值的實例數據,填補前后的兩水平邏輯回歸分析慢性心力衰竭發生院內死亡的影響因素結果見表5:填補后各回歸系數標準誤較填補前低,非高血壓CHF患者院內死亡率高,具有統計學意義。

表5 DM和MILC實例數據分析結果
討 論
刪除法是一種最簡單最常見的分類變量缺失數據處理方法。當樣本量大、缺失率低且缺失機制為完全隨機缺失時,缺失的數據相當于原始數據集的一個隨機子集,數據缺失對結果造成的影響小,但在不同程度上會增大參數的標準誤;當缺失機制為隨機缺失時刪除數據后參數估計值可發生明顯的變化,因此在處理分類變量缺失數據時應避免直接刪除含缺失的個體數據。
多重填補是處理缺失數據的重要思想,能保留觀測到的所以數據,同時考慮到填補值的不確定性,是目前處理缺失數據的首選方法。本文比較基于兩種填補模型的分類變量多重填補法:基于對數線性模型的多重填補法指定填補模型為飽和對數線性模型時涵蓋所有變量間的關聯,減小了由于缺失數據所導致的結果偏倚,但對數線性模型為全面估計高階交互效應所需樣本含量隨變量數及變量類別數的增大迅速增大,模型復雜且計算量大,在實際應用中缺少靈活性;基于潛在類別模型的多重填補法中填補模型結合對數線性模型、因子分析和結構方程模型的思想而形成,用潛在類別數解釋外顯變量之間的關聯,減少了高階交互多所需的估計參數量,對樣本含量的要求比MILL低,在實際應用中具有獨特的優勢[9]。尤其值得注意的是當樣本量小而缺失率較大時,多重填補后參數保持一定的精度及穩定度,證實了多重填補的準確性和穩健性。
本文模擬實驗以logistic模型為分析模型,評價基于不同模型多重填補法的處理效果。總體上MILL和MILC在處理缺失數據中效果均可接受,而DM在缺失率大的條件下效果極差,因而在實際使用時不建議直接刪除觀測。MILL與MILC相比較,當缺失率大于5%,MILC在樣本量500時穩定度和標準誤偏倚稍差,準確度均優于MILL和DM,樣本量1000時則處理效果均優于MILL和DM。MILC中潛在類別數目的設定可能影響其填補效果[10],這將在后續研究中進一步探索。實例數據應用MILC進行填補后參數估計更準確,結果更可靠,為研究者在選擇分類變量缺失數據處理方法時提供可靠參考。
參考文獻
[1]徐勇勇.醫學統計學.高等教育出版社,2004.
[2]張耀,陳培翠,張翠仙,等.二分類數據缺失多重填補分析及應用.中國衛生統計,2014(3):370-373.
[3]Schafer JL.Multiple imputation:a primer.Statistical Methods in Medical Research,1999,8(1):3-15.
[4]Shafer JL.Analysis of incomplete multivariate data.Monographs on Statistics and Applied Probability 7,1997,41(2):505-514.
[5]Vermunt JK,Van ginkel JR,Van der ark LA,et al.Multiple imputation of incomplete categorical data using latent class analysis.Sociological Methodology,2008,38(1):369-397.
[6]Sulis I.A further proposal to perform multiple imputation on a bunch of polytomous items based on latent class analysis.Statistical Models for Data Analysis:Springer,2013:361-369.
[7]Ted H,Fernando T.Analysis of categorical-variable datasets with missing values.2012:1-23.
[8]Linzer DA,Lewis JB.Polca:an R package for polytomous variable latent class analysis.Journal of Statistical Software,2011,42(10):1-29.
[9]張巖波.潛變量分析.北京:張巖波,2009:220-247.
[10]Van DD,Van der ark LA,Vermunt JK.A comparison of incompletedata methods for categorical data.Statistical Methods in Medical Research,2012:1-21.
(責任編輯:劉 壯)
Comparison of Methods Dealing with Category Variables with Missing Data
Xiao Yaming,Chen Yongjie,Wang Yupeng,et al.(Department of Biostatistics,Harbin Medical University(150081),Harbin)
【Abstract】Objective To compare the performance of deletion method(DM),multiple imputation using log-linear model(MILL)and multiple imputation based on latent class model(MILC)dealing with category variables with missing data,and applying MILC to practical data analysis.Methods Simulated data containing multiple variables missing data with different missing mechanism,missing rate and sample size was produced using R.DM,MILL and MILC were employed to obtain the complete dataset,which would be analyzed using logistic regression model.The performance of each method was evaluated by bias of regression coefficient root mean square error,stability and the bias in standard error.Results Simulation experiments showed that when missing rate was 5%,DM、MILL and MILC all performed well.With the missing rate increasing,MILL and MILC were better than DM for all evaluated indicator,and MILC was superior to MILL.The performance of each method was better for completely missing at random mechanism rather than missing at random mechanism,and for sample size of 1000 rather than 500.Practical data analysis showed that the standard error of the coefficient was reduced,and the regression coefficient were more accurate.Conclusion In this paper,two multiple imputation methods,MILL and MILC,are used to deal with category variables missing data and may reduce parameters estimation bias.When missing rate is 5%and sample size is 1000,MILC is recommended for category variables with missing data.
【Key words】Category variable;Missing data;Multiple imputation;Latent class model;Log-linear model
*基金資助:本研究獲國家自然科學基金資助(81273183)
通信作者:△劉美娜,E-mail:liumeina369@163.com
