基于組合核函數SVM的文本主題識別
2016-07-07 10:00:36呂洪艷劉芳
微型電腦應用 2016年5期
呂洪艷,劉芳
?
基于組合核函數SVM的文本主題識別
呂洪艷,劉芳
摘 要:文本內容主題識別的實際應用中,大量文本之間彼此摻雜,使其無法線性表述,應用SVM可以有效地解決這種非線性不可分問題,而核函數的選擇是SVM的關鍵。鑒于單核無法兼顧識別準確率與召回率,針對文本主題識別的特定應用,將多項式核函數和徑向基核函數進行線性加權組合,構建兼具全局核函數的泛化能力及局部核函數的學習能力的組合核函數,并通過網格搜索法確定最優參數。在仿真實驗中評估了線性核、多項式核、徑向基核以及組合核函數,實驗結果表明,組合核函數SVM的識別性能明顯優于其它3單核函數,識別準確率與召回率都比較理想。
關鍵詞:SVM;組合核函數;文本識別;召回率;文本主題
章編號:1007-757X(2016)05-0073-04
基金來源:黑龍江省教育科學規劃重點課題(GJB1215019);教育部人文社會科學研究項目(15YJA630074)。
0 引言
隨著信息技術的迅猛發展, 網絡文本信息也不斷膨脹,文本內容識別作為確定文章類別的分析方法,是組織、管理文本信息的有效手段,可以有效地解決信息雜亂無章的問題,使用戶從大量雜亂的信息中定位到所需的信息。文本分類廣泛地應用于信息檢索、信息過濾、電子郵件、搜索引擎、數字圖書館等各方面,在多種領域都起著至關重要的作用。隨著人們對信息分類需求的日益增長,如何提高分類性能是目前亟待解決的問題。
目前基于文本內容過濾的模型主要有貝葉斯決策模型、向量空間模型(VSM)、神經網絡模型、和支持向量機模型(SVM)等。貝葉斯決策模型能夠解決多語種兼容性問題,而且算法邏輯簡單、比較穩定,適用于垃圾郵件過濾領域,但模型中特征項是在獨立性假設的基礎上建立的,所以準確率較低[1]。VSM模型把文本信息過濾過程簡化為空間向量的運算,可操作性好,但是無法區分特征項出現在不同位置對表達文檔主題性質能力的差異,無法充分反映文本全貌,且特征項權重難以確定[2]。神經網絡模型具有很強的自適應能力,能夠實現自我更新和完善,但算法復雜、不支持部分匹配,而且執行速度慢[3]。SVM主要優勢體現在解決高緯度、小樣本以及線性不可分問題上。目前已有學者將SVM應用到文本分類領域,并取得了一定的進展,但識別準確率與文本判定的召回率往往無法兼顧。本文針對這個問題,將多項式核函數與徑向基核函數進行組合,以期提高文本主題識別性能。
1 SVM原理
SVM是由Vapnik 等人在1996 年提出的基于結構風險最小化原理的一種機器學習方法。基本思想是尋找一個最優分離超平面,把兩類樣本正確分開,使錯誤概率最小,分類間隔最大[4]。
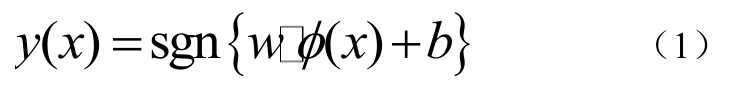
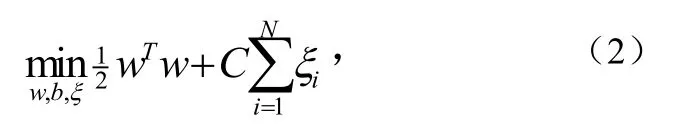
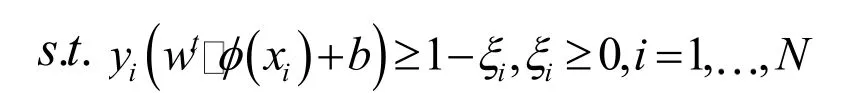
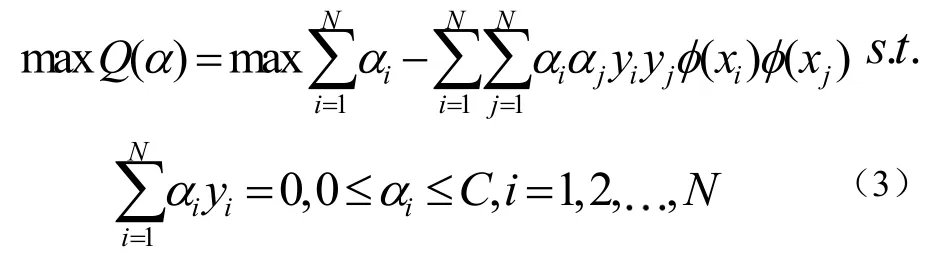

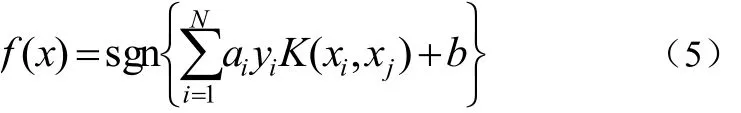
在文本識別的實際應用中,大量文本之間總有交界甚至彼此摻雜,使其無法線性表述,核函數的引入可以使高維空間的內積運算轉化為原空間一個內積核函數的計算[6],在不增加算法復雜度的同時實現了非線性算法,這就是SVM。
2 SVM核函數
2.1 常用核函數
在SVM中,常見的核函數有以下4種。
①線性內積核函數如公式(6):
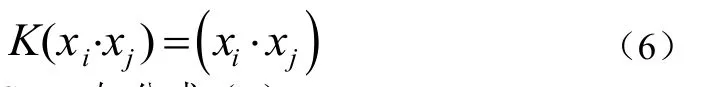
②多項式核SVM如公式(7):
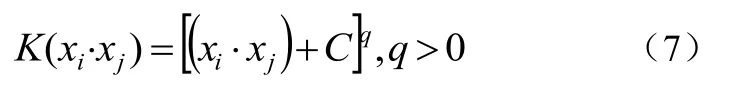
③徑向基核SVM如公式(8):
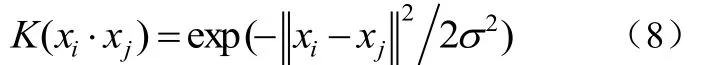
④兩層神經網絡SVM(Sigmoid核)如公式(9):
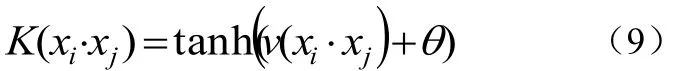
2.2 局部核函數和全局核函數
不同類型的核函數表現出不同的特性,根據核函數的特性不同,常分為局部性核函數和全局性核函數。其中多項式核函數具有良好的全局性質,而徑向基核函數是局部性很強的核函數[6]。
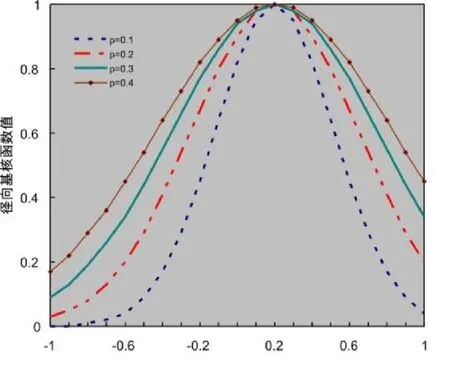
圖1 徑向基核函數特征曲線圖
由圖1可知,在測試點附近,核函數值較大,當距離較遠時,核函數值顯著下降,而且當2越小時,核函數值下降的速度越快,局部性越強,泛化能力越弱。
根據多項式核函數的表達式,當q分別取1,2,3,4,測試點取0.2時,可得到多項式核函數特征曲線圖,如圖2所示:
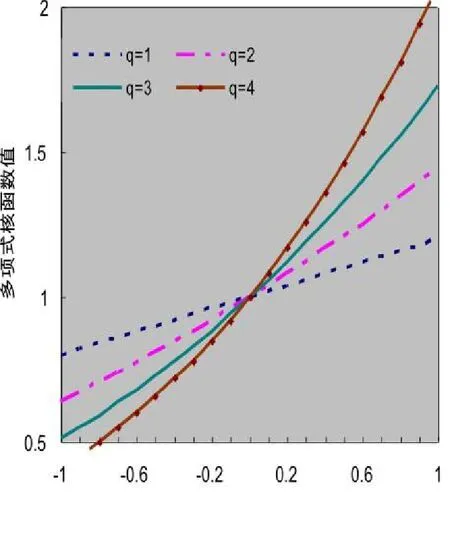
圖2 多項式核函數特征曲線圖
由圖2可知在輸入數據與測試數據距離不斷加大的情況下,多項式核函數值變化不大,而且對于離測試點較遠的數據仍然有較強的影響,具有很強的泛化能力。
綜合以上分析可得,全局性核函數作用范圍比較廣,甚至對整個數據點都有影響,泛化能力較強,但局部學習能力較弱。而局部性核函數作用范圍較小,僅對測試點周圍的數據有作用,學習能力較強,泛化性能較弱。
2.3 組合核函數構建
核函數的選擇對SVM的識別性能有重要的影響,因為不同的核函數具有不同的特性,使其在解決具體問題時表現差別很大。目前,關于單核的構造、改進及其參數優化的研究較多,但采用單核SVM的識別效果并不理想。由上可知,全局核函數泛化能力較強,而局部核函數學習能力較強。因此,可以將這兩種核函數進行組合,充分發揮它們各自的優點,使組合核函數兼具良好泛化能力與良好學習能力,以提高識別性能。
2.3.1 組合核函數形式
根據核函數的構成條件,兩個核函數之和仍然滿足Mercer條件,因此這里對多項式核函數和徑向基核函數進行線性組合,即公式(10):
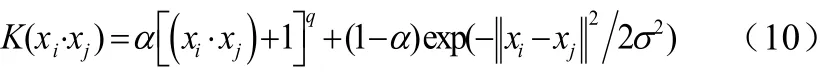
2.3.2 組合核函數SVM參數優化方法
構造的組合核函數中共有懲罰因σ子C、多項式核α函數的冪指數q、徑向基核函數的寬度系數、及比例系數四個參數。關于SVM最優參數選取, 常用的方法網格搜索法,此方法可以同時搜索多個參數值,但當參數較多時,訓練時間較長。主要思路是首先選取合適的搜索范圍,然后確定搜索的步長,以固定的步長沿著各個參數方向生成網格,網格中的節點就是初始給定范圍內的所有可能的參數組合。多重網格搜索法從上一次網格尋優確定的最優點開始,再次進行網格尋優,減小搜索步長,以此類推。綜合考慮參數優選的準確度與訓練時間,這里采用二次網格搜索法確定組合核函數參數。
3 組合核函數SVM在文本主題識別中的應用
3.1 基于SVM的文本信息過濾的流程
基于SVM的文本信息過濾過程共分為兩個階段,即訓練階段和分類階段。由于多數Web網頁中包含廣告、注釋、HTML標簽及版權聲明等與內容無關的信息,為了方便后續處理,需將這些無關信息去除,這個過程就是預處理。在訓練階段,對經過預處理后的訓練樣本集中的文本進行分詞處理,將結果存入特征庫,根據特征庫中的分詞結果進行特征提取,通過統計出每個特征項出現的次數計算出特征權重,并表示成向量形式,在此基礎上訓練SVM分類器。在分類階段,對待測樣本進行預處理、分詞處理后,根據生成的文本特征庫對分詞結果進行特征提取,計算出特征權值,并表示成向量,再運用SVM進行分類,判定待測樣本的類別,具體流程如圖3所示:
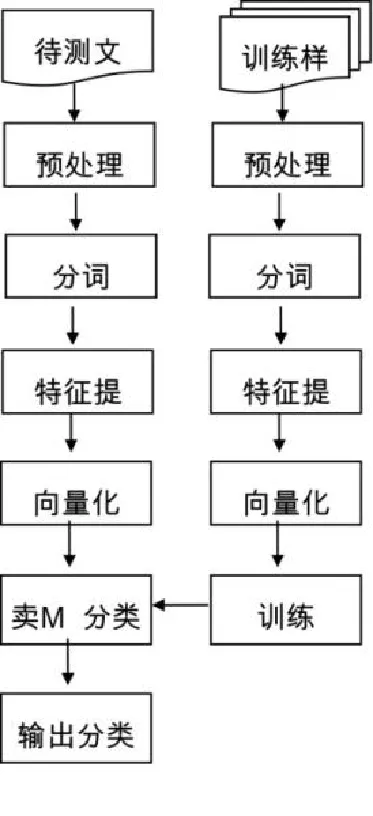
圖3 基于SVMMD文本信息過濾過程
3.2 實驗分析
3.2.1 數據來源與實驗方法
為了驗證本文算法的有效性,本文分別對傳統的線性核函數、多項式核函數、徑向基核函數和新提出的組合核函數進行了測試對比。
本文采用復旦大學計算機信息與技術系國際數據庫中心自然語言處理小組提供的文本分類語料庫。該預料庫共收集了19637篇文本,測試預料有9833篇,訓練語料有9804篇,均分20類。在本實驗中,抽取其中最大的8類,訓練數據在訓練語料庫的Economy、Computer、Environment、Sports 4類中每類隨機抽取1000篇,在Politics、Agriculture、Art、space 4類中每類隨機抽取500篇,共6000篇文本。測試數據在測試預料庫中隨機抽取,前面4類每類抽取300篇,后面4類中每類抽取150篇,共1800篇。實驗采用多分類的一對多算法,再將8類文本的識別結果取平均值,并在此基礎上采取多次實驗再次平均,以保證實驗結果的客觀性。
實驗使用詞根萃取與停用詞過濾的方法去除冗余特征,采用由中科院計算所開發的漢語詞法分析系統進行分詞,用兩步特征選擇方法得出特征集,用TFIDF函數計算訓練文本集中文本的特征項權值,并表示成向量模式。
3.2.2 最優參數確定
對于組合核函數,根據選定的二次網格搜索法,第一次搜索C、、、q的范圍分別是[1,500],[0,20],[0, 1],[1,20],步長分別是10,0.5,0.1,1,得到的最優參數為C=100,、、。在此基礎上進行二次優選,C、、、q的范圍分別是[80,140],[0,2],[0, 0.3],[1,10],步長分別是1,0. 05,0.01,1,得到的最優參數為C=125,、、q=3。便于比較實驗結果,需確定單核核函數參數,這里采用一次網格搜索法,確定如下最優參數:線性核參數C=128,多項式核參數q=3,C=2,徑向基核函數參數,C=2。
3.2.3 性能評價指標
評價標準采用Recall(查全率)、precision(準確率)以及F-value(標準測度),其中F-value是Recall、Precision兩個評價指標的綜合,見公式(11):
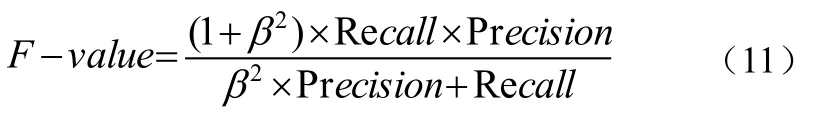
3.3 實驗結果與對比分析
在仿真實驗評估了線性核、多項式核、徑向基核以及本文提出的組合核函數,選擇不同的參數值進行實驗,以對比網格優選的參數及其它參數組合對文本識別性能的差異,實驗結果圖表1所示:
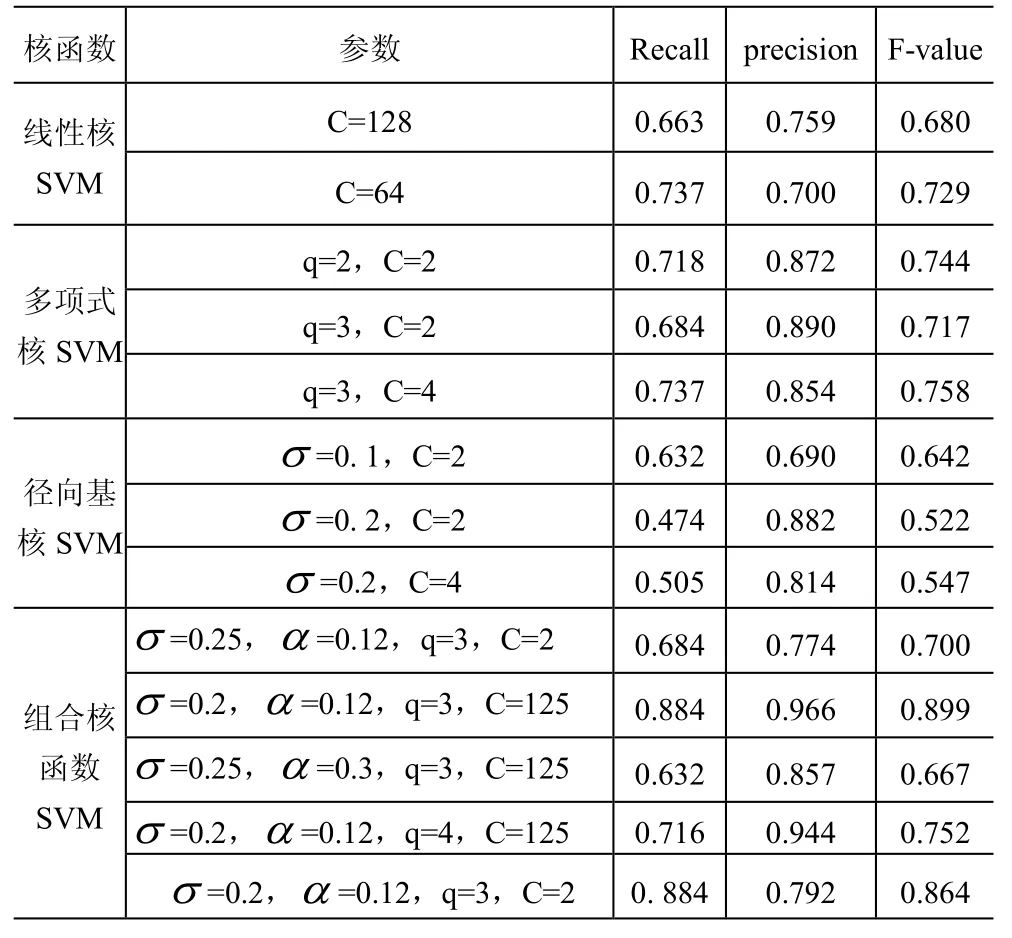
表1 不同SVM核函數識別效果
從線性核、多項式核和徑向基核函數SVM的實驗數據來看,準確率和召回率是成反比的,準確率越高,召回率則越低。結果顯示三者識別準確率較高,但召回率相對較低。這是由SVM本身的特點所決定的,因為SVM是以結構風險最小化原則為理論基礎的一種算法,目標就是保證識別準確率,從而無形中影響召回率。
在3個單核函數線性核、多項式核和徑向基核構建的SVM中,在選擇最優參數情況下,識別準確率分別為75.9%,89%和88.2%。線性核的識別性能最差,其它兩個準確率相差不多。同時它們的準確率都明顯高于其它的非最優的參數組合,而且多項式核函數由于參數變化引起的準確率變化最小,徑向基核函數的變化最大,這是由于多項式核函數是全局核函數,有很好的泛化能力,而徑向基核函數是局部核函數,泛化能力差。
在組合核函數中應用每個單核選出的最優參數構建的SVM,準確率僅為77.4%,甚至低于兩個單核的準確率。在最優參數的基礎上,分別改變,q和C的值,得到的結果也都不理想,這些都說明如果參數選擇不準確,組合核函數SVM也無法得出理想的結果。若選擇的參數正確,組合核函數SVM的準確率為96.6%,查全率為88.4%,標準測度為89.9%,三個性能評價指標均達到最佳。這是由于組合核函數兼顧了徑向基核函數較強的學習能力與多項式核函數較強的推廣能力,兼顧了文本分類的準確率和召回率。實驗結果說明以二次選優的網格搜索法確定的參數構建的組合核函數SVM確實能夠很好地進行擬合,能夠以較理想的性能實現文本識別。
4 總結
應用SVM進行文本主題識別時,選擇適合的核函數是最為關鍵的問題。本文基于單核函數的特點,依據Mercer規則對多項式核函數與徑向基核函數進行線性加權,構建具有良好的泛化能力與良好的學習能力的組合核函數。在文本識別的仿真實驗中,組合核函數表現出明顯優于其它單核SVM的良好性能。但語料庫的質量直接影響分類性能,如何減少分類的準確率對測試文本的依賴性是今后要探索的問題。
參考文獻
[1] Sergios Theodoridis,Konstantinos Koutroumbas 著,李晶皎等譯.模式識別.3rd ed.[M]北京:電子工業出版社,2006:45-48.
[2] 呂洪艷,杜娟.基于SVM的不良文本信息識別. [J]計算機系統應用,2015,24(6):183.
[3] 高會生,郭愛玲. 組合核函數SVM在網絡安全風險評估中的應用. [J]微計算機工程與應用,2009,45(11): 123-124.
[4] 張冰,孔銳.一種支持向量機的組合核函數. [J]計算機應用,2007,27(1):44-45.
[5] 葉志剛. SVM在文本分類中的應用.[D].哈爾濱:哈爾濱工程大學,2006.
[6] 劉志剛,杜娟,衣治安.一種改進的分類算法在不良信息過濾中的應用. [J]2011,32(2),11-12.
Text Topic Recognition Based on Combination Kernel Function of SVM
Lv Hongyan, Liu Fang
(Institute of Computer and Information Technology, Northeast Petroleum University, Daqing 163318 , China)
Abstract:In practical application of text information identification, most of the text always doped with each other, so that they are unable to linear expression. The nonlinear non-separable problem can be solved effectively by SVM. And the key of the SVM is to choose the appropriate kernel function. As the recognition accuracy rate of a single kernel function is not high and the recall value is not ideal, for the specific application of text topic identification, combining w ith homogeneous polynom ial kernel and radial basis kernel function by linear weighted method, it structured a new combination kernel function w ith the advantage of both homogeneous polynomial kernel and radial basis kernel function. That is the combination kernel function which has the generalization ability of global kernel function and the learning ability of local kernel function. And it determ ines the optimal parameters through the grid search method. Then it evaluates the linear kernel, homogeneous polynom ial kernel, radial basis kernel function and combination kernel function in the sample experiment. The experimental results show that the recognition accuracy rate and the recall value of combination kernel function of SVM are more ideal than other kernel functions.
Key words:SVM; Combination Kernel Function; Text Identification; Recall; Text Topic
中圖分類號:TP311
文獻標志碼:A
作者簡介:呂洪艷(1982-),女,五常市,東北石油大學,計算機與信息技術學院,講師,研究方向:人工智能與模式識別,大慶,163318 劉 芳(1983-),女,伊春市,東北石油大學,計算機與信息技術學院,講師,研究方向:人工智能與模式識別,大慶,163318
收稿日期:(2015.11.03)
