基于粗糙集的海量數據挖掘算法研究
2016-07-09 15:39:25牛詠梅
現代電子技術 2016年7期
關鍵詞:數據挖掘
牛詠梅
摘 要: 針對傳統數據挖掘算法在數據量級方面的局限性,提出在粗糙集理論的基礎上,采用類分布鏈表結構改進傳統的基于屬性重要性的數據離散化算法、屬性約簡算法以及基于啟發式的值約簡算法。討論了基于動態聚類的兩步離散化算法,當算法適應大數據處理之后,采用并行計算的方法提高算法的執行效率。算法測試結果表明,改進算法能有效地處理大數據量,同時并行計算解決了大數據量處理帶來的效率問題。
關鍵詞: 數據挖掘; 粗糙集; 大數據處理; 并行計算
中圖分類號: TN911?34; TQ028.1 文獻標識碼: A 文章編號: 1004?373X(2016)07?0115?05
Abstract: Since the traditional data mining algorithm has the limitation in the aspect of data magnitude, on the basis of rough set theory, the class distribution list structure is used to improve the traditional data discretization algorithm based on attribute importance, attribute reduction algorithm and heuristic?based value reduction algorithm. The two?step discrete algorithm based on dynamic clustering is discussed. When the algorithm adapts to the big data processing, the parallel computing method is used to improve the execution efficiency of the algorithm. The test results of the algorithm show that the improved algorithm can effectively process the big data size. The parallel computing can solve the efficiency problem causing by big data size processing.
Keywords: data mining; rough set; big data processing; parallel computing
0 引 言
信息時代,數據(尤其是海量數據)已被各企業、各研究機構當成重大的知識來源、決策的重要依據[1],對于數據的急速增長,如何有效地解決數據挖掘過程中空間和時間的可伸縮性已經成為數據挖掘領域中迫切需要解決的難題[2]。從知識發現的過程中可以看到,數據挖掘不僅面臨著數據庫中的龐大數據問題[3],而且這些數據有可能是不整齊的、不完全的、隨機的、有噪聲的、復雜的數據結構且維數大[4]。傳統的數據挖掘算法還限制于單機內存的容量[5],當一次性需要分析的數據不能全部進入內存時,算法的性能就會嚴重降低[6],甚至得不到預期的結果,使用基于粗糙集理論的算法策略將有效解決這個問題[7]。
本文針對傳統數據挖掘算法在數據量級方面的局限性,提出了結合類分布鏈表,把數據挖掘算法推廣到可以處理更高數據量級,最后采用并行計算的方法提高基于動態聚類的兩步離散化算法適應大數據處理之后的執行效率。
1 改進的Rough Set知識約簡算法
許多經典的Rough Set知識約簡算法都可以通過引進CDL(類分布鏈表)改進,CDL可以反映某個條件屬性組合對論域的分類情況。CDL分為不相容類分布鏈表(ICDL)和相容類分布鏈表(CCDL)兩部分,CCDL根據鏈表中每個分類的樣本數目又可分為單例相容類分布鏈表(SSCDL)和多例相容類分布鏈表(MSCDL)[7]。引進CDL后相對于原始的經典算法,改進后的算法將具有更好的可伸縮性,能夠更好地處理海量數據集。以下通過引入CDL對包括離散化、屬性約簡和值約簡的一組Rough Set知識約簡算法進行改進。
1.1 改進的離散化算法
數據離散化是Rough Set知識獲取方法中的重要組成部分。在此采用基于屬性重要性的離散化算法,在原算法的基礎上通過引入CDL,使得該算法能夠處理海量數據。
算法1.1 基于屬性重要性的離散化算法
算法輸入:一個完備的決策表信息系統DT
算法輸出:離散化后的決策表信息系統DT
算法步驟如下:
(1) 循環遍歷每一個連續的條件屬性,并且通過生成[ICDLai]計算屬性[ai]的條件信息熵。
(2) 根據條件信息熵降序排序,排列所有連續的條件屬性。
(3) 針對排序后的DT,循環遍歷每一個連續的條件屬性[ai,]生成[ICDLC\ai;]設置[Szone=null,]其中[Szone]是屬性[ai]的值域的一個子集。
(4) 循環遍歷區間[Sa,Sb]上的每一個斷點。其中[Sa]和[Sb]是屬性[ai]上兩個連續的屬性值;令[Szone=Szone+Sa。]
(5) 循環遍歷DT中滿足[SVjai=Sh]的每個樣本[SVj,]其中[Sh∈Szone。]
(6) 循環遍歷DT中滿足[SVkai=Sb]的每個樣本[SVk;]如果樣本[SVj]和[SVk]出現在[ICDLai]中的同一個條件分類中而且它們之間存在符號“@”,則選擇[Sa,Sb]的斷點,并把 [Szone]重新置為空。
1.2 改進的屬性約簡算法
使用基于信息熵的CEBARKNC算法。根據類分布鏈表求取條件信息熵的方法[8],通過某個條件屬性組合的ICDL很容易求得決策屬性相對于該條件屬性組合的條件信息熵。因此可以通過ICDL改進CEBARKNC算法的可伸縮性,改進的算法與原算法在計算信息熵的過程不一樣。
1.3 改進的值約簡算法
在此改進啟發式值約簡算法,該算法在原算法的基礎上加上CDL,使得該算法能夠處理海量數據。原算法在執行第一步的時候按照[CDL(a)]中的三部分更新決策表S。
(1) 把[SSCDL(a)]中的樣本在屬性[a]上的值標記為“?”;
(2) 把[MSCDL(a)]中的樣本在屬性[a]上的值標記為“*”;
(3) [ICDL(a)]中的樣本在屬性[a]上的值不變。
由(3)可知[ICDL(a)]中的樣本不需要處理,而在處理[SSCDL(a)]和[MSCDL(a)]的樣本時,不把生成實際的鏈表放在內存中處理而是直接在數據庫中進行處理。具體的算法描述如下:
算法1.2 改進啟發式值約簡算法
輸入:一個完備的離散的決策表信息系統DT
輸出:規則集RT
假設樣本標號為Index,決策屬性為DA,條件屬性集合[C,]則算法步驟如下:
(1) 把RT初始化為DT。
(2) 循環遍歷每一個條件屬性[ai,]把[SSCDL(ai)]中的所有樣本在[ai]上的屬性值標記為“?”。
(3) 把[MSCDL(ai)]中的所有樣本在[ai]上的屬性值標記為“*”。此外剩下的樣本都在[ICDL(ai)]中,它們在[ai]上的屬性值不需要改變。
(4) 接下的操作步驟與原始的值約簡算法相同。
2 基于動態聚類的兩步離散化算法的并行化
基于動態聚類的兩步離散化算法的第一步是利用動態聚類算法對決策表第一次進行離散化,然后利用斷點重要性離散化算法進行再次離散化,從而得到最終的斷點集。
算法2.1 基于動態聚類的離散化算法
輸入:決策表[S=
輸出:決策表[S]首次篩選后的斷點集[CUTfirst]循環遍歷[S]的每一個條件屬性[k,]執行以下步驟:
(1) 計算屬性[k]每一斷點的重要性,并按斷點值從小到大排序,計算結果保存在數組[Importantk[]]中,數組的索引[m]表示最重要的斷點在數組中的位置,即:
決策表經過上述的算法離散化之后,其效果僅相當于基于屬性重要性離散化算法的局部離散化效果。下面通過把斷點集[CUTfirst]輸入到斷點重要性算法中進行一次全局離散化便得到基于動態聚類的兩步離散化算法。
算法2.3對算法2.2進行了并行化處理,得到的離散化結果與算法2.2是一致的,但算法2.3帶來的好處是提高了離散化算法的運行效率。
3 算法測試
3.1 改進的Rough Set知識約簡算法測試
3.1.1 算法正確性測試
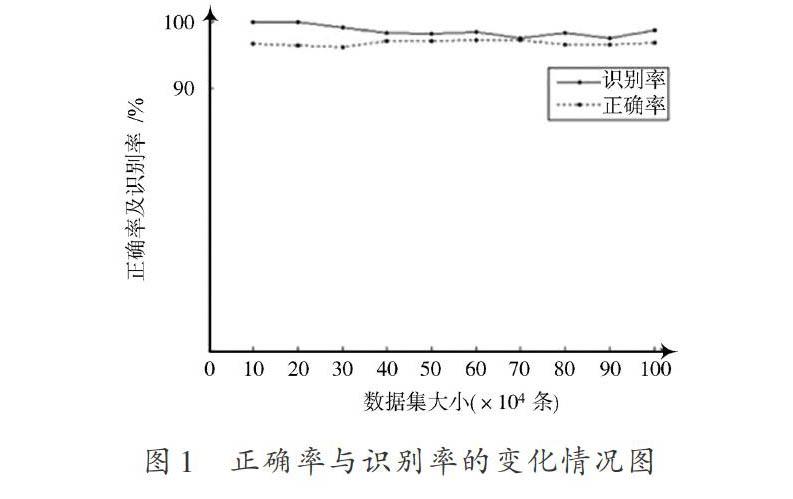
選擇UCI數據庫中的5個數據集(見表1)來比較經過CDL改進的知識約簡算法與原始經典Rough Set算法的正確性,雙方都應用了相同的算法組合。比較的結果見表2,從結果中可得出:使用經過CDL改造后的知識約簡算法不影響原始的經典Rough Set算法的正確率及識別率等性能。
3.2 基于動態聚類的兩步離散化算法的并行化處理算法測試
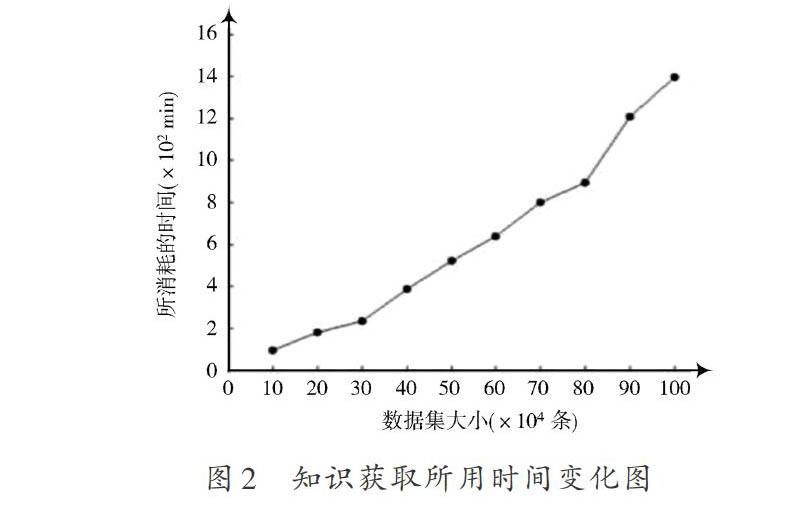
從UCI數據庫中選取6組數據集對算法2.2進行測試。表3是實驗使用的數據集。表4,表5展示了基于動態聚類的離散化算法、基于動態聚類的兩步離散化算法、貪心算法、基于斷點重要性的離散化算法等5種算法的運算對比結果。其中,算法的運行時間用符號[T]表示,規則集的正確識別率用符號[P]表示。
4 結 論
從目前常用的數據挖掘算法出發,采用類分布鏈表來改進傳統的數據挖掘算法,使該算法能直接處理海量數據集,實現處理超大規模數據集的目標。系統采用并行計算的核心思想,基于動態聚類的并行離散化算法,提出分布確定類分布鏈表的方法,有效解決了系統內存限制的問題。同時,提高了基于動態聚類的兩步離散化算法的運行效率。
參考文獻
[1] 黃朝輝.基于變精度粗糙集的數據挖掘方法研究[J].赤峰學院學報(自然科學版),2014(8):3?4.
[2] 要照華,閆宏印.基于粗糙集的海量數據挖掘[J].機械管理開發,2010,25(1):17?18.
[3] 石凱.基于粗糙集理論的屬性約簡與決策樹分類算法研究[D].大連:大連海事大學,2014:22?25.
[4] 劉華元,袁琴琴,王保保.并行數據挖掘算法綜述[J].電子科技,2006(1):65?68.
[5] 陳貞,邢笑雪.粗糙集連續屬性離散化的K均值方法[J].遼寧工程技術大學學報,2015(5):642?646.
[6] CORNELIS C, KRYSZKIEWICZ M, SLEZAK D, et al. Rough sets and current trends in soft computing [M]. Berlin: Springer, 2014: 11?15.
[7] 劉建.并行程序設計方法學[M].武漢:華中科技大學出版社,2000:11?13.
[8] 陳小燕.機器學習算法在數據挖掘中的應用[J].現代電子技術,2015,38(20):11?14.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
