優惠信息檢索與分析
2016-07-13 22:44:16屠燕萍俞雯琴
科技傳播 2016年8期
屠燕萍+俞雯琴
摘 要 處在一個信息時代,越來越多復雜且紊亂的信息充斥著我們的生活。如何從繁多散亂的信息中找到顧客需要的、感興趣的優惠信息成為一個難點。我們的課題致力于尋找局部地區的優惠信息并將其匯總在一個平臺上,通過顧客的點擊率等方式挖掘數據分析顧客偏好。
關鍵詞 優惠信息;搜索;關聯規則;平臺
中圖分類號 TP39 文獻標識碼 A 文章編號 1674-6708(2016)161-0099-02
在如今的信息時代,隨著internet網絡的迅速發展以及信息化水平不斷的提高,網絡上產生了許多關于打折優惠的信息。越來越多的復雜且紊亂的優惠信息充斥著我們的生活。大部分人需要并且對優惠信息感興趣,然而目前優惠信息是零散分布在各個地方,沒有集中在一個地方發表。這既沒有最大化商家的利益,也沒有造福于顧客。如今如何更好地利用和挖掘出有價值的優惠信息從而更好地服務于顧客,是它要急需解決的問題。
1 優惠信息需求分析
優惠信息依靠不同的介質大面積存在,而顧客針對優惠信息有不同的需求和偏好,我們通過生活的一些現象,發現需要將受顧客歡迎的優惠信息收集起來,便于顧客查看和選擇。網上和現實同時進行了一次簡單的問卷調查,問卷調查范圍主要是青年人,采用不同的統計表達形式,分析數據后得到以下信息。65%的人會主動尋求優惠信息,而且大部分人會知曉優惠信息后主要去嘗試,由此可以看出青年人尤其是大學生財力不夠,沒有自己的收入或者工資不高。他們出于這些原因會希望獲得優惠信息,不僅是節省而且可以以有限的財力來體驗更多的生活。其中美食類的優惠信息更得大眾歡迎,休閑娛樂類第二,購物類第三。大家更多關注的還是豐富自己的精神生活,提升生活檔次,享受生活。當然這也與年輕人自身的偏好有關。他們生長于物質和精神都更為豐富的社會,比之年長者更容易接受新事物。
就目前優惠信息分布情況來看,基本沒有人或極少數人認為其分布是集中的。大家感受到生活中的優惠信息是零散的。而大眾獲取優惠信息的渠道多種多樣,最廣泛使用的是通過微信等App發現,其次為朋友告知。調查發現微信對大家的影響越來越深,在生活中的應用愈加廣泛。
2 平臺建立
通過日常觀察和問卷調查,很多用戶常用微信最為日常工具,因此,建立一個微信平臺來發布我們的優惠信息在一定程度上是可行的。
將收集的優惠信息分類,歸為美食、休閑娛樂、購物等多種類別,類別名稱由編碼代替并定時發布在微信平臺上。有目的性查找優惠信息的顧客可以通過選擇不同編碼,進入到不同類別的優惠信息頁面中去,再可以點擊相關的推送來查看具體的優惠信息內容。平臺上每天會發送新的優惠信息,可以方便關注我們平臺的顧客隨意點擊。在發布信息的同時,定時刪除過時的優惠信息,不浪費顧客時間。
在顧客使用我們平臺的時候,我們將采用數據挖掘等方式來發現顧客的偏好,之后,我們將在顧客偏好的優惠信息上加大收集力度。
3 信息收集
3.1 優惠信息要求
通過查找感興趣的優惠信息這一途徑,顧客能利用相同的價值去體驗更多的生活感受。為了確保這些優惠信息的實用性,收集到的信息必須具備以下要求。
3.1.1 時效性
很多優惠信息都是伴隨著某種活動產生的,例如節日、店慶等較為隆重的日期,可想而知,這類優惠信息必定存在一定的期限,或長或短,時間不定。而分享給顧客的時候必須保證優惠信息不過時,在提早發送消息的同時還要定期處理過期的優惠信息。
3.1.2 真實性
有些商家為了得到更多顧客的關注,會編造一些虛假優惠信息,需要運氣才能獲得,但前提是顧客關注或者轉發,事實卻是完全沒有這個活動。有些優惠信息又存在于宣傳的有差距的詐騙。這些現象明顯屬于欺騙消費者行為。所以信息的真實性是必備因素。
3.2 優惠信息收集途經
3.2.1 走訪商家
作為一種存在時間最長的收集方式,也是最基礎和保險的收集方式,與商家面對面的洽談存在其優點和缺點。走訪地區內各戶商家,與商家進行協議,體現誠意,便于建立長期合作。但是過程費時費勁,因此我們并不主要依靠這個方法來收集信息。
3.2.2 網絡收集
處在一個互聯網高速發展的時代,互聯網提供給用戶極大的便利。網絡信息便是其中占據大比例的存在。通過網絡收集各類優惠信息是一個更為方便簡單的方法。其中主要由搜索引擎查找、微信等平臺查找構成。
1)搜索引擎。觀察互聯網用戶使用較多的搜索引擎,百度、Google、雅虎等,嘗試在不同的搜索引擎中打入相同的關鍵詞,例如:“優惠信息 松江大學城”,可以看到,不同的引擎產生的網頁是完全不同的。在百度的搜索引擎中出現在首頁的是多為松江大學城團購,且存在少量獨立商家的優惠信息。而通過谷歌,可以看到大部分為松江大學城租房或買房的優惠。兩個搜索引擎,相同的關鍵詞產生了差異較大的結果,這取決于網頁排序的規則。
網頁多采用鏈接分析的算法,鏈接分析排序原理啟發與文獻引文索引機制,分析網頁之間的鏈接結構,若一個網頁被引用的次數越多,表示該網頁越受大眾的歡迎;被越權威的網頁引用,表示該網頁質量越高。這么看來,從這兩方面來說,這個網頁的價值越高。常見的算法有PageRank算法、HillTop算法、HITS算法等。根據不同的算法,會導致網頁結果的排序不同[ 1 ]。
例如,Google搜索引擎的最主要網頁排序算法就是PR算法,計算網頁的PR值,判斷網頁的重要性。若A網頁有個鏈接指向B網頁,那么B網頁將得到A貢獻給它的分值,值的大小取決于A的重要性。引用的網頁數量越多,質量越高,排序越前面。
通過對算法原理的簡單認識,我們可以分析得到,之所以百度的搜索引擎查到的信息更豐富,這歸結于在這個搜索引擎中,這些網頁的價值較高,從總的基數來看,被引用的次數較多,鏈接的網頁價值也不錯。而在谷歌這個全球常用的搜索引擎上來看,同樣的網頁被引用的次數太少,而且相關鏈接的網頁價值不高。因此,在用搜索引擎來查詢優惠信息時,要注意使用的搜索引擎和關鍵詞的使用。其中,關鍵詞的使用需格外注意,指明針對性。
一般以“優惠信息 松江大學城”為關鍵詞的搜索結果范圍仍舊極大,這不利于我們仔細排查一些小商家的信息。我們嘗試先利用百度地圖尋找松江大學城附近的商家信息,努力收集各個商家的官方公眾網絡。隨時關注商家的動態信息變化,收集商家的優惠活動,判斷商家活動的真實性,匯總在我們平臺上。如果能在發現商家的官方網頁的同時取得商家的聯系方式,可以與之線上商談,爭取成為長期合作伙伴。
2)微信等平臺搜索。有些小眾的網絡平臺同樣收集著一些值得嘗試的優惠信息。而這些信息存在于不同的平臺上,顧客看到的較少。我們提供相關的鏈接,與那些小眾優惠信息搭建一個橋梁,方便顧客查看。許多商家的微信公眾平臺同樣發布著一些消息,有時候會在朋友圈大范圍傳播,這個途徑收集起來的信息雖然不全面,但是也是一種較為常見的方式。
4 顧客行為信息分析
隨著平臺的不斷推廣,顧客涌入。在微信公眾號后臺,可以用直觀看到訂閱人數,每條推送消息的點擊數。因此可以獲取大量的顧客消費行為數據。利用數據挖掘技術可以分析大量的數據,對顧客進行細分,還可以從已有的歷史數據中發現有價值的潛在的知識,為顧客提供個性化的商品信息推薦。
建立模型以及分析:
經過對數據的預處理,我們發現利用關聯規則挖掘來對數據進行處理比較好。關聯規則可以發現不同事務之間隱藏的聯系。我們在進行關聯規則挖掘時,主要做了兩步,第一找出頻繁項目集,然后根據頻繁項集產生滿足最小可信度的關聯規則。
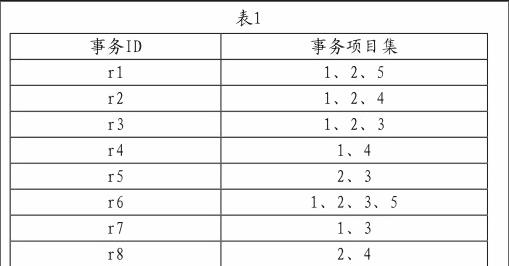
從微信公眾平臺獲得的數據,我們對其進行整理。在事務數據庫中,事務的項目集為人們檢索的優惠信息類別編號,事務ID為人的編號。由此我們得到了事務數據庫D。
表1為事務數據庫中的一部分。
在挖掘關聯規則時我們運用了Apriori算法,使用“K?項集”產生“1K +?項集”的迭代方法[3]。掃描所有的事務,對每種優惠信息類別出現次數計數。這里,假定最小事務支持計數為20,由此我們可以確定頻繁1-項集的集合。使用來產生候選集,再次掃描數據庫中事務,計算中每一個候選集的支持度計數。具有最小支持度的里面的候選2?項集組成了頻繁2?項集的集合。反復進行上述步驟,由于Apriori算法性質,頻繁項集的所有子集必須是頻繁的,因此我們計算過程中會剪去一些項集。一直反復進行下去,直至1K +?項集為空集,我們得到K?項集為最大的頻繁項集{1、2、5},也就是為{美食、休閑娛樂、購物}。
對于每個頻繁項集L,我們列出所有它的非空子集,對每一個非空子集X,計算它的可信度。在這里,我們假設最小可信度(min_conf)為60%,最終得到了4條關聯規則。在進行數據整理時,我們發現在每日推送的各種優惠信息中,美食類的點擊量一直居高不下。這完全符合我們問卷調查的結果。
通過關聯規則等對顧客的行為數據進行分析,我們發現人們往往會希望在休息娛樂比如看電影和購物之后享受一頓美味大餐。在享受的同時也希望獲得優惠信息,以較小的代價獲得高品質生活。
參考文獻
[1]鄧維婕.網絡搜索引擎的原理、技術和發展[J].電腦與電信,2008(5):12-14.
[2]姚明.淺談網絡搜索引擎的研究[J].電腦知識與技術:學術交流,2007,4(19):83-84.
[3]陳安,陳寧,數據挖掘技術及應用[M].北京:科學出版社,2006.
