基于SVM的腫瘤特征基因提取與基因表達數據分析
2016-07-15 03:51:19王琦然王學敏邱文瑩
重慶理工大學學報(自然科學) 2016年6期
譚 云,于 彬,王琦然,王學敏,李 珊,邱文瑩
(1.青島職業技術學院 生物與化工學院,青島 266555;2.青島科技大學 數理學院,青島 266061)
?
基于SVM的腫瘤特征基因提取與基因表達數據分析
譚云1,于彬2,王琦然2,王學敏2,李珊2,邱文瑩2
(1.青島職業技術學院 生物與化工學院,青島266555;2.青島科技大學 數理學院,青島266061)
摘要:提出一種基于支持向量機的腫瘤基因表達譜數據挖掘方法。首先采用信噪比方法對白血病、結腸癌、肺癌數據提取特征基因,生成特征基因子集。然后通過支持向量機分類模型對特征基因子集進行機器學習訓練分類。實驗結果表明:急性白血病、結腸癌只需4個特征基因,均獲得100%的10折交叉驗證分類準確率。最后為了有效地排除噪聲基因進而挑選出精確度更高的分類特征基因,采用多尺度小波閾值法對肺癌數據進行降噪處理,降噪后僅需5個特征基因獲得96.61%的分類準確率。
關鍵詞:基因表達譜;腫瘤分類;特征基因;信噪比;支持向量機
DNA微陣列技術的出現和發展使腫瘤在分子水平上的研究獲得巨大飛躍。研究腫瘤基因表達譜,選取特征基因是從生物信息學角度出發以尋找腫瘤特異基因,在分子水平上準確利用基因表達圖譜進行腫瘤亞型識別,對腫瘤的早期診斷和治療具有重要的實際意義[1-3]。如何對腫瘤基因表達譜進行有效分析、挖掘和發現蘊含的重要信息,已成為近年來生物信息學與系統生物學研究的熱點。
自1999年Golub等[4]首次在白血病基因表達譜數據上進行基因識別和腫瘤分類以來,研究者提出多種腫瘤數據挖掘方法。主要有:聚類分析[5]、主成分分析 (PCA)[6]、獨立分量分析 (ICA)[7]、k-近鄰 (k-NN)[8]、非負矩陣分解 (NMF)[9]、自組織映射 (SOM)[10]、支持向量機 (SVM)[11-13]、人工神經網絡 (ANN)[14]、概率神經網絡 (PNN)[3]、貝葉斯[15]等經典常用的分類方法。實驗表明:分類器的性能對于腫瘤的分類結果至關重要。近年來,基于高效的機器學習方法SVM是該領域最常使用的分類器,對于超高維、小樣本特點的腫瘤基因表達譜數據集具有良好的分類效果[16-18]。
本文從腫瘤基因表達譜數據中挖掘有效信息作為分類依據,研究特征基因的選取問題。采用信噪比方法對急性白血病、結腸癌、肺癌基因表達譜數據提取特征基因,利用SVM對3類腫瘤基因樣本數據進行訓練建立腫瘤分類模型。實驗表明:只需4個特征基因急性白血病、結腸癌均獲得100%的10折交叉驗證分類準確率。最后采用多尺度小波閾值法對肺癌基因表達譜數據進行降噪處理,降噪后只需5個特征基因以96.61%精確度識別肺癌。
1材料與方法
1.1實驗數據
使用3類腫瘤數據集:Leukemia、Colon Cancer及Lung Cancer。數據來自哈佛-麻省理工的博德研究所網站http://www.broadinstitute.org/cgi-bin/cancer/datasets.cgi及普林斯頓大學網站http://genomics-pubs.princeton.edu/oncology/。
Leukemia數據集由Golub等收集[4]。它含有72個急性白血病個樣本,每個樣本含7 129個基因。其中,47個樣本為ALL (急性淋巴白血病),25個為AML (急性髓細胞白血病)。選取38個樣本作為訓練集 (27個ALL,11個AML),34個樣本作為測試集 (20個ALL,14個AML)。
Colon Cancer數據集由Alon等收集[19]。它含有62個樣本,每個樣本含2 000個基因。其中,40個樣本為結腸癌,22個為正常組織。隨機選取48個樣本為訓練集 (30個結腸癌,18個正常組織),14個樣本為測試集 (10個結腸癌,4個正常組織)。
Lung Cancer數據集由Beer等收集[20]。它含有86個樣本,每個樣本含7 129個基因。其中,24個樣本為肺癌,62個為正常組織。隨機選取58個樣本為訓練集 (16個肺癌,42個正常組織),28個樣本為測試集 (8個肺癌,20個正常組織)。
1.2方法
1.2.1信噪比方法
對于腫瘤樣本兩類別分類問題,信噪比是有效的特征選擇方法[4]。公式如下:
其中,u+(j)和u-(j)分別是+1類和-1類樣本第j個基因的平均值。類似的,σ+(j)和σ-(j)分別是+1類和-1類樣本第j個基因的標準差。
1.2.2支持向量機
SVM是由Vapnik等[21]提出的一種新機器學習方法,它以統計學習理論為基礎,基于結構風險最小化原則,在數據小樣本條件下具有較好的推廣能力。近年來, SVM方法已經成功運用到腫瘤基因表達譜樣本數據的挖掘分析之中[12-13]。
支持向量機的具體求解過程如下:
1) 設已知樣本訓練集:
其中:xi∈X=Rn;yi∈Y={-1,+1}(i=1,2,…,n);xi為特征向量。
2) 選取適當的核函數K(xi,xj),參數C,求解優化問題:
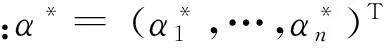
3) 選取α*的正分量,計算樣本分類閾值:
4) 構造最優判別函數:
實驗采用了Chang等[22]開發的軟件包LIBSVM,該軟件可通過網址http://www.csie.ntu.etu.tw/~cjlin/libsvm/下載。由于腫瘤樣本集非線性的特點,采用基于RBF的SVM分類器對腫瘤樣本進行分類。RBF核函數形式為K(xi,xj)=exp(-γ‖xi-xj‖2)。仿真實驗環境:Intel(R) Core(TM) i7-4510 CPU @ 2.00GHZ 2.60GHZ 8.00GB的內存,MATLAB R2014a編程實現。
2結果與討論
本文首先采用信噪比方法對3類腫瘤微陣列數據提取特征基因,然后對提取出的特征基因子集進行歸一化,最后以徑向基支持向量機作為分類器,利用訓練集進行K-折交叉驗證,對樣本測試集進行基因表達譜數據識別,得到3類腫瘤樣本Leukemia、Colon Tumor及Lung Tumor的分類精度。經過多次數值實驗,發現白血病數據集提取特征基因最少時僅需要4個 (如表1所示),結腸癌基因表達譜數據集提取征基因最少時僅需要4個 (如表2所示),肺癌數據集提取征基因最少時僅需要5個 (如表3所示),3類腫瘤樣本能獲得較高的分類精度。

表1 急性白血病特征基因及其生物屬性描述
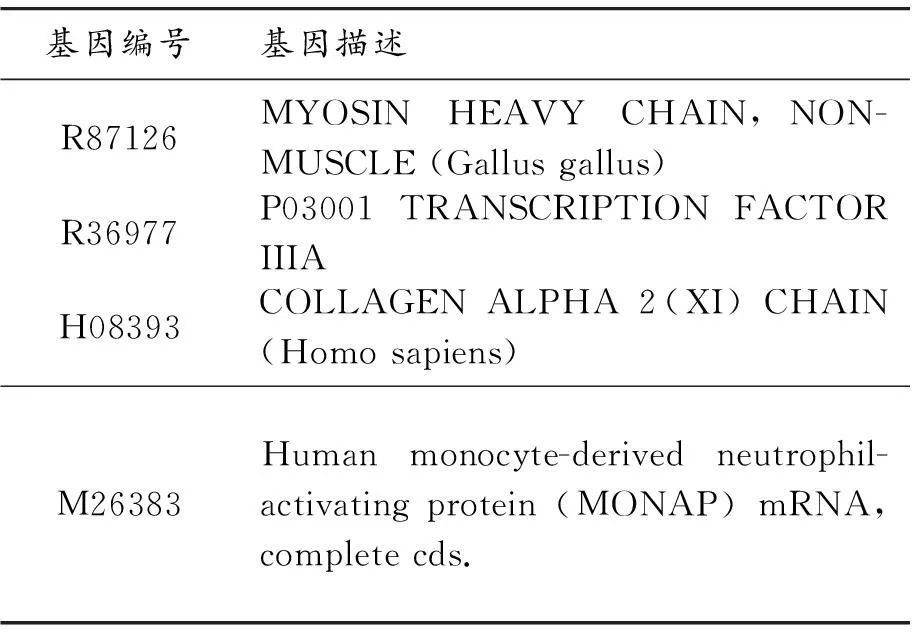
表2 結腸癌特征基因及其生物屬性描述

表3 肺癌特征基因及其生物屬性描述
在參數選取方面,利用基于SVM腫瘤基因表達譜數據分類模型,結合K-折交叉驗證方法,使用LIBSVM軟件包中的SVMcgForClass函數對參數進行自動化最優選取。在不同折數選取的最優參數下,急性白血病、結腸癌、肺癌3種癌癥的測試集分類準確率如表4所示。

表4 3種癌癥分類準確率 %
從表4可以看到:使用不同折數選取的最優參數,對提高癌癥分類的準確率具有較大影響。急性白血病的分類在4,5,7,8,10折下均達到100%;結腸癌的分類在4,5,7,8,10折下均達到100%;肺癌的分類精度在3,5折下達到較高的分類精度83.05%。這說明本文提出的方法在K-折交叉驗證下,參數自動化最優選取對提高腫瘤的分類準確率具有較大的幫助。
針對肺癌數據集的分類精度不太理想,猜測可能由于基因表達譜中存在噪聲,有的噪聲強度甚至較大,對含有噪聲的基因表達譜提取特征基因時會產生偏差。本研究使用多尺度小波閾值法進行降噪,采用了常用的Daubechies (dbN) 小波系作為母小波,并且在5個不同尺度水平下進行小波重構。分別采用penalty閾值、Birge-Massart閾值、缺省閾值對樣本數據進行降噪。通過對肺癌訓練集中數據的分析,結果表明:penalty閾值函數的均方根最大,誤差最小,分解層數為4時消噪效果最好,采用db4為最佳小波基。將降噪后的微陣列數據采用信噪比方法提取特征基因,最終得到最少時5個特征基因,此時肺癌測試集在3,4,5,7,8,10折下均達到96.61%的分類精確度。降噪后提取的特征基因以及其生物屬性描述如表5所示。

表5 肺癌降噪后提取的特征基因
通過對3類腫瘤基因表達譜的研究,可以發現3類數據在10折交叉驗證的情況下均達到了最優分類效果,以下研究都采用10折交叉驗證選取最優參數。3種腫瘤樣本在10折交叉驗證下的分類準確率及相應參數如表6所示。

表6 3種腫瘤的分類準確率及相應參數
以結腸癌為例,該數據是一個較難分析的數據集,分別提取了1,2,3,…,10個特征基因做分類研究,研究結果如表7所示。根據不同特征基因個數繪制了分類準確率的折線圖,如圖1所示。從表7和圖1中可以看出:當提取4,6,7,8,10個特征基因時,測試集樣本的10折交叉驗證分類準確率均達到100%。
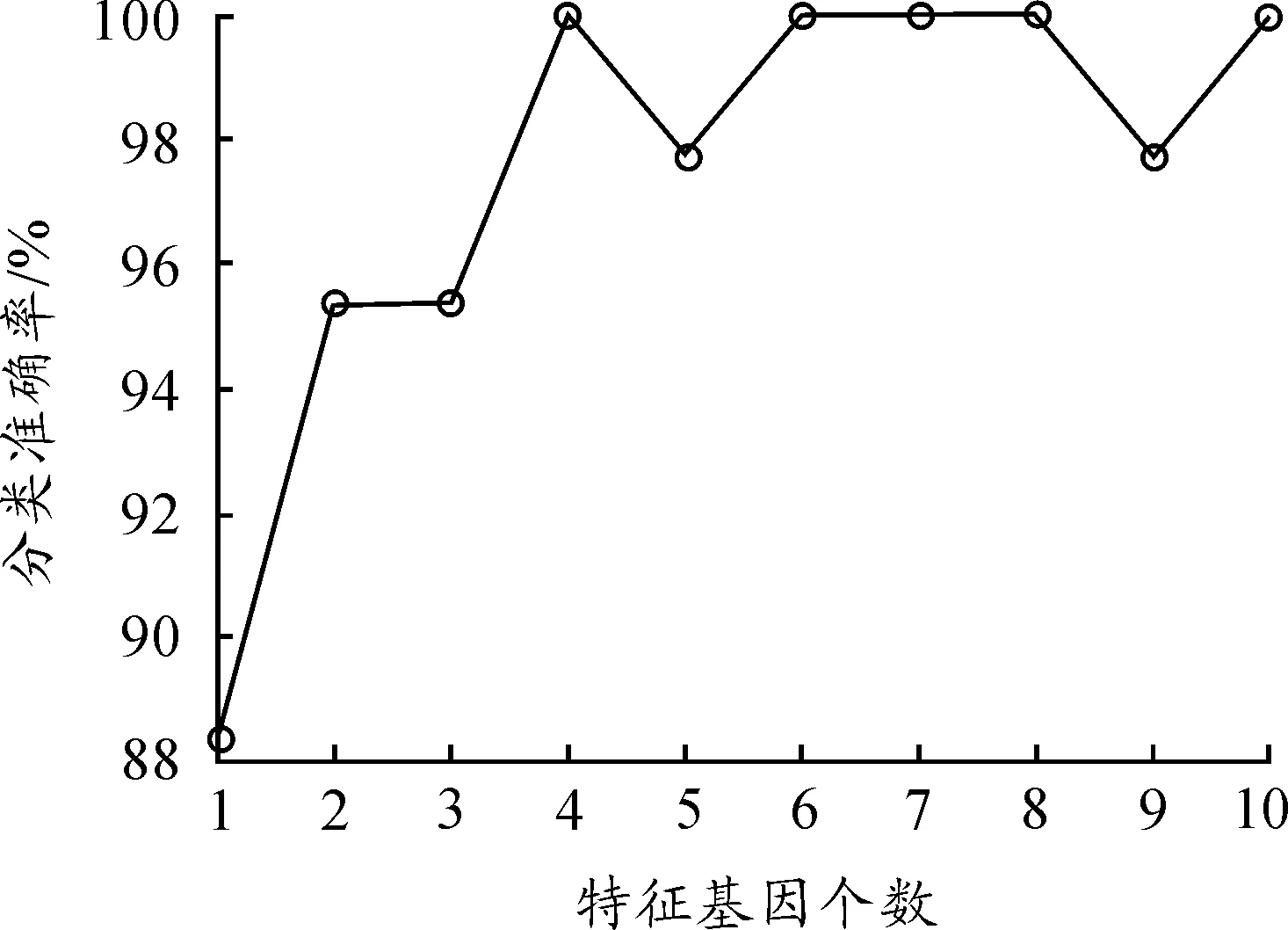
圖1 結腸癌的分類準確率
在3種不同腫瘤提取出的特征基因中,對每類腫瘤隨機選取3個特征基因繪制三維散點圖。圖2繪制了急性白血病從特征基因中抽取3基因子集{X95735,M84526,M23197}的三維散點圖。圖3繪制了結腸癌從特征基因中抽取3基因子集{R87126,R36977,H08393}的三維散點圖。圖4繪制了肺癌從特征基因中抽取3基因子集{U22816,X04706_s,L43631}的三維散點圖。可以看出:圖2、3、4中3類腫瘤的樣本劃分邊界都比較清晰,說明該方法提取的特征基因可以將腫瘤較好地區分開。
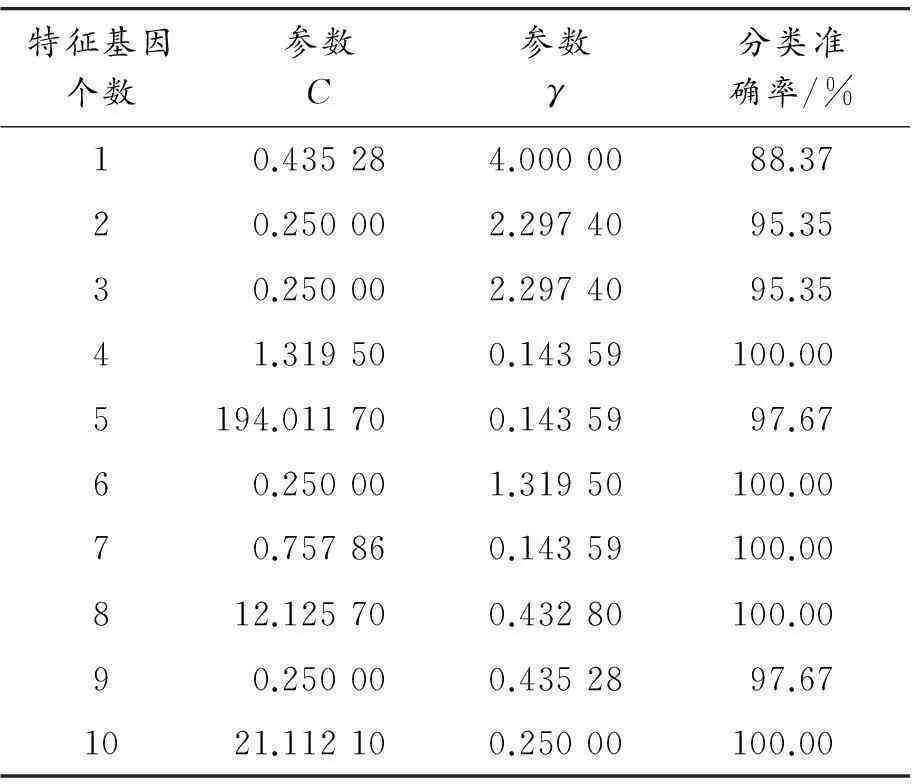
表7 結腸癌選取不同特征基因的分類準確率

圖3 結腸癌的3個基因{R87126,R36977,

圖4 肺癌數據集的3個基因{U22816,X04706_s,
為便于比較,本文列出了急性白血病、結腸癌、肺癌3類腫瘤樣本集采取不同的特征基因提取方法及不同分類器的實驗結果,這些都是目前腫瘤分類問題研究中獲得的非常好的實驗結果,如表8所示。通過比較,可以發現本文提出的方法對兩類腫瘤樣本的分類準確率均達到較高的水平,相對其他方法實現該方法以最少的特征基因數目達到最高的分類準確率。說明使用RBF核函數的支持向量機作為分類器,采用最優參數選擇方法能顯著提高樣本的分類準確率。

表8 3類腫瘤數據集的不同分類方法獲得的分類結果比較
3結束語
腫瘤大數據可以使人們深入了解疾病的病因和結局,為精準醫學尋找更好的藥物靶點,并且提高疾病的早期預測和預防能力。本文提出一種基于支持向量機的腫瘤基因樣本分類模型,針對3類腫瘤基因樣本數據集具有樣本小、維數高、非線性等特點,利用信噪比和小波降噪等方法對基因表達譜進行降維,提取特征基因子集,運用基于RBF核函數的支持向量機作為分類器。實驗結果表明:3類腫瘤樣本均獲得了較高的分類精確度。不過本文提出的方法適于腫瘤基因表達樣本數據的兩類別分類,如何利用基于統計學習理論的支持向量機及貝葉斯統計方法建立腫瘤多類別分類模型,并且融入臨床生物學信息是下一步的研究方向。
參考文獻:
[1]NGUYEN D V,ROCKE D M.Tumor classification by partial least squares using microarray expression data [J].Bioinformatics,2002,18(1):39-50.
[2]YU B,ZHANG Y.The analysis of colon cancer gene expression profiles and the extraction of informative genes [J].J Comput Theor Nanosci,2013,10(5):1097-1103.
[3]WANG S L,LI X L,ZHANG S W,et al.Tumor classification by combining PNN classifier ensemble with neighborhood rough set based gene reduction [J].Computers in Biology and Medicine,2010,40:179-189.
[4]GOLUB T R,SLONIM D K,TAMAYO P,et al.Molecular classification of cancer:class discovery and class prediction by gene expression monitoring [J].Science,1999,5439 (286):531-537.
[5]ZHANG H P,YU C Y,SINGER B,et al.Recursive partitioning for tumor classification with gene expression microarray data [J].Proc.Natl Acad.Sci.,USA,2001,98:6730-6735.
[6]PINTO DA COSTA J F,ALONSO H,ROQUE L.A weighted principal component analysis and its application to gene expression data [J].IEEE/ACM Transactions on Computational Biology and Bioinformatics,2011,8(1):246-252.
[7]HUANG D S,ZHENG C H.Independent component analysis based penalized discriminant method for tumor classification using gene expression data [J].Bioinformatics,2006,22(15):1855-1862.
[8]CHENG X P,CAI H M,ZHANG Y,et al.Optimal combination of feature selection and classification via local hyperplane based learning strategy [J].BMC Bioinformatics,2015,16:219.
[9]ZHENG C H,HUANG D S,ZHANG L,et al.Tumor clustering using non-negative matrix factorizatiowith gene selection [J].IEEE Transactionson Information Technology in Biomedicine,2009,13(4):599-607.
[10]TORONEN P,KOLEHMAINEN M,WONG G,et al.Analysis of gene expression data using self-organizing maps [J].FEBS Letter,1999,451:142-146.
[11]FUREY T S,CRISTIANINI N,DUFFY N,et al.Support vector machine classification and validation of cancer tissue samples using microarray expression data [J].Bioinformatics,2000,16(10):906-914.
[12]PENG S,XU Q,LING X B,et al.Molecular classification of cancer types from microarray data using the combination of genetic algorithms and support vector machines [J].FEBS Letter,2003,555(2):358-362.
[13]YU B,ZHANG Y,ZHAO L K.Cancer classification by a hybrid method using microarray gene expression data [J].J.Comput.Theor.Nanosci.,2015,12(10):3194-3200.
[14]KHAN J,WEI J S,RINGNER M,et al.Classification and diagnostic prediction of cancers using gene expression profiling and artificial neural networks [J].Nature Medicine,2001,7:673-679.
[15]WANG Y,MAKEDON F,FORD J C,et al.Hykgene:a hybrid approach for selecting marker genes for phenotype classification using microarray gene expression data [J].Bioinformatics,2005,21(8):1530-1537.
[16]YU B,LI S,LIU H J.A hybrid gene selection method for tumor classification based on genetic algorithm and support vector machine [J].J.Comput.Theor.Nanosci.,2015,12(11):4730-4735.
[17]SUN S,PENG Q,SHAKOOR A.A kernel-based multivariate feature selection method for microarray data classification [J].PLoS ONE,2014,9(7):e102541.
[18]SHI P,RAY S,ZHU Q F,et al.Top scoring pairs for feature selection in machine learning and applications to cancer outcome prediction [J].BMC Bioinformatics,2011,12:375.
[19]ALON U,BARKAI N,NOTTERMAN D A,et al.Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays [J].Proc.Natl.Acad.Sci.USA,1999,96:6745-6750.
[20]BEER D G,KARDIA S L R,HUANG C C,et al.Gene expression profile predicts survival of patients with lung adenocarcinoma [J].Nature Medicine,2002,8:816-824.
[21]VAPNIK V N.The nature of statistical learning theory [M].New York:Springer-Verlag New York Inc,1995.
[22]CHANG C C,LIN C J.LIBSVM:a library for support vector machines [J].ACM Transactions on Intelligent Systems and Technology,2011; 2(3):1-27.
[23]ANTONIADIS A,LAMBERT-LACROIX S,LEBLANC F.Effective dimension reduction methods for tumor classification using gene expression data [J].Bioinformatics,2003,19(5):563-570.
(責任編輯何杰玲)
Extraction of Cancer Informative Genes and Gene Expression Data Analysis Based on Support Vector Machine
TAN Yun1, YU Bin2, WANG Qi-ran2, WANG Xue-min2, LI Shan2, QIU Wen-ying2
(1.School of Biological & Chemical Engineering, Qingdao Technical College,Qingdao 266555, China; 2.College of Mathematics & Physics,Qingdao University of Science & Technology, Qingdao 266061, China)
Abstract:This paper put forward cancer gene expression profile data mining methods based on support vector machine (SVM). Firstly, informative genes were extracted from leukemia, colon cancer and lung cancer data by signal-to-noise ratio method, thus generating informative genes subsets. Then informative genes subsets were classified by machine learning and training through support vector machine (SVM) classification model. The experimental results show that only four informative genes are needed for acute leukemia and colon cancer to get 100% classification accuracy by 10 fold cross-validation. Finally, multi-scale wavelet threshold denoising method was established to reduce the noise of the data in lung cancer gene expression profiles for getting higher classification accuracy. After noise reduction, only five informative genes are needed to get 96.61% classification accuracy.
Key words:gene expression profile; cancer classification; informative gene; signal to noise ratio; support vector machine
收稿日期:2016-02-24
基金項目:國家自然科學基金資助項目(41204115); 山東省自然科學基金資助項目(ZR2013AM007, ZR2014FL021); 山東省高等學校科技計劃項目(J13LI54)
作者簡介:譚云(1979—),女,講師,主要從事生物信息學的研究;通訊作者 于彬(1976—),男,副教授,碩士生導師,主要從事生物信息學、系統生物學及計算智能的研究。
doi:10.3969/j.issn.1674-8425(z).2016.06.017
中圖分類號:Q811.4
文獻標識碼:A
文章編號:1674-8425(2016)06-0102-07
引用格式:譚云,于彬,王琦然,等.基于SVM的腫瘤特征基因提取與基因表達數據分析[J].重慶理工大學學報(自然科學),2016(6):102-108.
Citation format:TAN Yun, YU Bin, WANG Qi-ran,et al.Extraction of Cancer Informative Genes and Gene Expression Data Analysis Based on Support Vector Machine[J].Journal of Chongqing University of Technology(Natural Science),2016(6):102-108.
