基于屬性值序列圖模型的deep Web新數據發現策略
2016-07-18 11:50:50鮮學豐崔志明趙朋朋方立剛楊元峰顧才東
通信學報 2016年3期
關鍵詞:模型
鮮學豐,崔志明,趙朋朋,方立剛,楊元峰,顧才東
?
基于屬性值序列圖模型的deep Web新數據發現策略
鮮學豐1,2,3,崔志明1,2,趙朋朋2,方立剛1,3,楊元峰1,3,顧才東1,3
(1. 江蘇省現代企業信息化應用支撐軟件工程技術研發中心,江蘇蘇州215104; 2. 蘇州大學智能信息處理及應用研究所,江蘇蘇州215006;3. 蘇州市職業大學計算機工程學院,江蘇蘇州 215104)
針對數據源新產生數據記錄的增量爬取問題,提出了一種deep Web新數據發現策略,該策略采用一種新的屬性值序列圖模型表示deep Web數據源,將新數據發現問題轉化為屬性值序列圖的遍歷問題,該模型僅與數據相關,與現有查詢關聯圖模型相比,具有更強的適應性和確定性,可適用于僅僅包含簡單查詢接口的deep Web數據源。在此模型的基礎上,發現增長節點并預測其新數據發現能力;利用互信息計算節點之間的依賴關系,查詢選擇時盡可能地降低查詢依賴帶來的負面影響。該策略提高了新數據爬取的效率,實驗結果表明,在相同資源約束前提下,該策略能使本地數據和遠程數據保持最大化同步。
deep Web;新數據發現;數據獲取
1 引言
目前,主流搜索引擎還只能搜索Internet表面可索引的信息,在Internet深處還隱含著大量通過主流搜索引擎無法涉及的海量信息,這些信息稱之為深層網頁(deep Web,又稱為invisible Web 或hidden Web)。根據Bright Planet研究表明,deep Web信息量非常龐大,是可索引Web信息的500倍,并且這些deep Web內容95%都是可以通過Internet無需付費注冊就可以公開訪問的。deep Web的信息一般存儲在服務端Web數據庫中,與靜態頁面相比通常信息量更大、主題更專一、信息質量和結構更好。為了方便用戶快捷高效地使用deep Web信息,國內外學者對deep Web數據集成進行了廣泛的研究。目前,deep Web信息集成主要有2種實現方案。一種方案是基于元搜索的方法,針對某個領域提供統一的查詢接口,將用戶查詢經過語義映射轉發到各個deep Web數據源上,返回的結果經過抽取、語義標注、去重合并呈現給用戶。該方案不需維護本地數據庫,但存在如下不足:用戶的查詢響應慢,響應時間不可控,由遠程數據源的服務質量決定;建立和維護統一查詢接口模式與各個數據源接口模式的語義映射代價高。另一種方案是deep Web數據本地化集成方案[1~4],該方案將deep Web數據庫中內容爬取出來,經過數據抽取、語義標注、實體識別和去重等處理后,使其以結構化的形式存儲于本地數據庫,它能在最短時間內響應用戶的查詢要求。Madhavan等[1]提出了一種新的基于DataSpace的數據集成框架PayGo,該集成框架具有Pay-As-You-Go和演化特性,具有構建成本低、領域獨立、演化等特點。目前,第2種方案正受到越來越多國內外研究學者的關注,將成為deep Web數據集成研究的主流。該方案中的關鍵問題是如何讓本地數據和遠程數據源中數據保持同步。本文將致力于該關鍵問題的研究,在相同更新資源條件下,使本地數據和遠程數據保持最大化同步。
由于deep Web是自治的、獨立更新的,其數據經常處于頻繁更新的狀態,而用戶總是希望能夠得到當前Web數據庫中最新的內容。因此需要定期地更新本地數據拷貝,以保持和遠程數據源同步。由于不同的deep Web數據源或同一個deep Web數據源中的數據記錄變化頻率是不一樣的,按統一頻率更新本地存儲的所有數據,這是非常耗費資源的(包括帶寬、遠程數據源服務器資源等)。deep Web處于快速動態更新的狀態,使增量維護變得更加復雜,因此亟需提出新的方法來自動增量更新本地deep Web數據,從而在相同資源約束前提下,提高本地數據的時新性和新數據的發現效率。deep Web數據增量爬取主要包含2部分內容:系統已集成的本地數據(消失和改變的記錄)的增量更新和新數據發現。目前,新數據的增量發現問題還有待進一步研究,因此本文將針對該問題開展研究,在相同資源約束前提下,獲得盡可能多的新數據,使本地數據和遠程數據保持最大化同步。
2 相關研究
互聯網中信息量的快速增長使增量信息爬取技術成為網上信息獲取的一種有效手段,針對淺層網頁(surface Web)的網頁變化和增量爬取技術已得到廣泛的關注和研究[5~7]。然而surface Web和deep Web存在較大的差異,數據增量爬取的最大區別為:surface Web頁面有固定的URL,更新一個本地網頁只需根據這個URL重新訪問。然而deep Web數據記錄無固定的URL,更新無法根據固定的URL來訪問。對于一個deep Web數據記錄,只能通過在deep Web數據源的查詢接口上提交與該數據記錄相關的查詢,才能更新該數據記錄。因此,不能直接應用surface Web的增量爬取技術來實現deep Web數據增量爬取,不得不研究新的方法解決deep Web數據增量爬取問題。
目前,國內外學者對deep Web數據增量爬取也開展了一些探索性研究,文獻[8]提出一種基于查詢關聯圖模型的增量數據爬取方法,該方法首先建立數據源的查詢關聯圖模型,從而將增量爬取任務轉化為圖遍歷過程,然后通過分析deep Web數據源的歷史版本選擇查詢來增量爬取新記錄。該圖模型的復雜性由數據源的數據記錄數和查詢接口查詢能力決定。文獻[9]同樣基于查詢關聯圖模型,但與文獻[8]的查詢選擇依據不同,文獻[9]通過分析deep Web數據源的樣本選擇查詢爬取新記錄。該圖模型與deep Web數據源提供的查詢接口能力密切相關,對于2個具有相同內容deep Web數據源,如果它們的查詢接口在查詢能力上不同,那么所產生的查詢關聯圖模型也不相同。因此,這種圖模型不能獨立表示deep Web數據源的內容,具有一定的不確定性;同時該圖模型不適用于僅僅包含簡單查詢接口的deep Web數據源。文獻[10]把deep Web數據爬取表示為集合覆蓋問題,通過機器學習方法獲得增量回報模型,然后根據增量回報模型自動選擇查詢爬取增量記錄。還有一些針對直接集成deep Web網頁集成系統的增量爬取的研究[11~13],文獻[11]提出一種基于URL分類的deep Web增量爬蟲,該爬蟲根據deep Web網頁的內容將其分為列表頁面和葉子頁面,所有URL也被分為列表URL和葉子URL,該爬蟲根據列表頁面的更新頻率和葉子頁面的變化頻率爬取最新的deep Web頁面。這類研究的deep Web集成方式與本文不同,它屬于deep Web數據集成研究的另一個分支。雖然國內外學者已對deep Web數據增量爬取問題進行了一定的研究,但這些研究的新數據發現效率還有待進一步提高。deep Web新數據發現問題研究目前仍處于探索階段,其中,許多問題仍需進一步深入研究。
本文提出了一種基于屬性值序列圖模型的deep Web新數據發現策略,該策略首先將deep Web數據源的本地數據表示為數據記錄屬性值序列圖,然后根據歷史數據產生增長節點,并設計了增長節點的新數據發現能力計算方法,最后基于增長節點的新數據發現效率進行選擇查詢節點以爬取新數據記錄。實驗結果表明基于屬性值序列圖模型的deep Web新數據發現策略在相同資源約束前提下,提高了新數據的發現效率,使本地數據和遠程數據保持最大化同步。
3 屬性值序列圖模型
3.1 屬性值序列圖模型定義
定義1 deep Web數據源的屬性值序列圖模型。結構化的deep Web數據源(WDB)可看作一張關系數據表DB,DB包含的數據記錄為{1,2,…,r},每條記錄包含個屬性{1,2,…,a},WDB中所有不相同的屬性值組成的集合為。在Deep Web數據增量爬取中,對于一個給定WDB,它的屬性值序列圖模型可定義為一種帶權的有向連通圖,表示為(,,,),其中是節點的集合,每一個節點v∈都與WDB中的屬性值av∈一一對應。(v)表示節點v∈的入度,(v)表示節點v∈的出度。每個節點附帶一個權值表示該節點對應屬性值在WDB的數據記錄集合出現的次數,如果不考慮同一個屬性值在一個數據記錄中出現多次的情況,則節點v∈的權值(v)為在WDB中出現屬性值av∈的數據記錄數。、分別為出現在單條數據記錄中的起點屬性值和終點屬性值的集合,為有向邊的集合,中的元素表示數據記錄中屬性值的接續關系,一個有向邊(v,v)∈當且僅當av和av接續出現在一個數據記錄r∈中(如圖1所示)。每條邊也附帶一個權值表示該邊所關聯的節點間的關聯度,邊(v,v)∈的權值(v,v)為包含有向邊(v,v)∈的數據記錄數。
屬性值序列圖模型具有如下特點。
2) 對于屬性值序列圖任意一個節點,有()(v)≥1。
3) 每條數據記錄在屬性值序列圖中被表示為一個有序閉環。
4) 對于屬性值序列圖中的任意一個節點v,根據、、數據記錄的長度以及與v相關聯的有向邊,可以確定屬性值序列圖中包含節點v的所有數據記錄。
5) 邊(v,v)∈和(v,v)∈屬于不同的邊,(v,v)∈≠(v,v)∈。
3.2 圖模型的構建
對一個給定的結構化的deep Web數據源,假設在前期的數據爬取中已獲得了該WDB的全部數據記錄,獲得的數據記錄集為{1,2,…,r}。首先基于中一條數據記錄生成初始屬性值序列圖(如圖1所示),然后依次從中提取各數據記錄,不斷向中的添加節點和邊,同時也更新節點和邊的權值,直到中所有數據記錄都已添加到,最終得到WDB的屬性值序列圖。屬性值序列圖構建示意如圖1和圖2所示。
圖1(a)為一個數據記錄r,包含4個屬性值。圖1(b)為圖1(a)數據記錄對應的屬性值序列圖,1為起始節點1為終止節點。有向邊(v,v)∈當且僅當av和av接續出現于一個數據記錄r∈中,數據記錄r在屬性值序列圖中被表示為一個有序閉環。在圖1(b)中所有節點和邊的權重都為1。
圖2顯示了一個結構化deep Web數據源(假定WDB包含4條記錄,每條記錄包含4個屬性值)和它所對應的屬性值序列圖。圖2(b)中節點1的權重=3,節點2、2、1的權重=2,其他所有節點的權重=1;圖2(b)中邊(1、1)∈和(2,2)∈的權重=2,其他邊的權重都=1。屬性值序列圖的節點和邊的權重記錄了它們在已構建的所有記錄中的統計信息,這些信息將便于deep Web數據的增量爬取。
對于一個給定的deep Web數據源,在第一次數據爬取結束后,通過上述圖模型的構建方法可以得到該WDB的屬性值序列圖。隨著時間的推移deep Web數據源會產生大量的新數據記錄,需要進行增量爬取。因此,本文以屬性值序列圖模型為基礎,研究新的方法來自動增量爬取新數據(新數據發現),以盡可能小的代價增量爬取deep Web數據源中新產生的數據記錄。從而在相同資源約束前提下,使本地數據與遠程數據保持最大化同步。
4 deep Web新數據發現策略
4.1 deep Web新數據發現的總體思路
事物發展的趨勢可以分為3種:遞增、遞減和平穩。趨勢的原因各式各樣,比如我國的人均收入、銀行的存款額每年隨著時間而增長,而我國貧困人口的數據趨勢逐年遞減,某地區的平均溫度以及平均降水量是基本平穩的。值得注意的是,幾乎所有的事物在不同的發展階段都要經過不同的趨勢,一般來說初期具有向上增長的趨勢,經過一段時間的成長達到成熟期,成熟期呈現平穩的趨勢,到了末期則有向下減少的趨勢。因此,可以通過分析事物過去的發展情況,來預測將來的發展趨勢。假定deep Web數據源中包含某個關鍵詞的數據記錄數的變化趨勢已符合事物發展的一般規律,基于這個假定本文提出一種deep Web新數據發現策略,該策略的基本思路為通過分析deep Web數據源在最近個歷史版本對應的屬性值序列圖,估計當前屬性值序列圖(t?1)中哪些節點(查詢關鍵詞)為增長節點,增長節點為目前在WDB中與該節點相匹配的數據記錄數處于遞增階段的節點,換句話說,WDB在時刻t?1到時刻t期間產生的新數據記錄較大可能包含的節點。然后,對增長節點的新數據發現能力進行評估,最后選擇Top個具有最高新數據發現效率的增長節點作為查詢節點,通過提交查詢節點對應的關鍵詞爬取新數據記錄。下面介紹基于屬性值序列圖模型的deep Web新數據發現策略。假定從本地數據庫獲得deep Web數據源的個歷史版本,deep Web新數據發現問題能被描述為:給定的(0),(1), …,(t1),如何盡可能多地爬取在△=t?t?1時間區間內產生的新數據記錄。新數據發現算法的具體描述如下。
算法1 基于屬性值序列圖模型的deep Web新數據發現算法
輸入:(t?L),(t?(L?1)), …,(t?1)//deep Web數據源最近個歷史版本
輸出:;//為爬取的新數據記錄的集合
Algorithm((t?L),(t?(L?1)),…,(t?1))
1) begin
2) 構建(t?L),(t?(L?1)),…,(t1)對應的屬性值序列圖(t),(t?(L?1)),…,(t?1)
3)=((t?L),(t?(L?1)),…,(t?1)) //增長節點選擇
4)=() //增長節點新數據發現能力估計
5) whiledo //停止條件
6)q=() //查詢節點選擇
7)(,q)=(q,) //在上執行查詢q
8)=((,q)) //抽取執行查詢q獲得的數據記錄
9)=(t?1) //查詢q爬取的新記錄
11)()()(q,)
12) end while
13) return
end
算法1為deep Web新數據發現算法,算法首先構建deep Web數據源最近個歷史版本的屬性值序列(2)行),然后根據這個歷史版本的信息從(t?1)中選擇增長節點并估計增長節點的新數據發現能力(3)~4)行),最后根據增長節點的新數據發現效率選擇查詢節點,并提交查詢節點對應的關鍵詞爬取新數據記錄(3)~5)行)。一次查詢的新數據爬取流程為:首先采用( )從增長節點中選擇一個節點作為查詢節點,提交該查詢節點對應的關鍵詞到當前的deep Web數據源,獲得返回結果頁面(6)~7)行)。然后從結果頁面中抽取該次查詢獲得的所有數據記錄,并篩選出新的數據記錄加入到中(8)~9)行),最后把該次數據爬取的代價(q,)計入爬取WDB已耗費的總代價()。算法不斷重復該新數據爬取過程直到滿足停止條件,完成該次新數據發現。
該算法主要由4個主要部分組成:( )、e ( )、( )和( )。
( ):通過分析Deep Web數據源的最近個歷史版本的屬性值序列圖,預測當前版本的屬性值圖(t?1)中節點的變化趨勢并選擇增長節點,增長節點為(t?1)中與WDB在時刻t?1到時刻t期間產生的新數據記錄具有最大可能性相匹配的節點。
e( ):估計增長節點可能產生新記錄的數量。
( ):從增長節點集合中選擇最高新數據發現效率的節點。
( ):從結果頁面中抽取數據記錄。
( )已經被廣泛研究,目前提出了許多解決方法,將不再討論數據記錄抽取問題。本文主要討論deep Web新數據發現的( )、e ( )和( )這3部分。
新數據發現的停止條件如下。
1) 如果系統分配給WDB的新數據爬取資源耗盡,即()≥c,c為分配給WDB的總資源,則結束WDB的數據爬取。
2) 對于數據源WDB,如果()最近連續選擇的個節點(查詢關鍵詞)發現新數據記錄的效率低于閾值。
3) 查詢節點集合為空,沒有可以提交的查詢節點。
接下來將詳細介紹增長節點選擇、增長節點新數據發現能力估計和查詢節點選擇這3個關鍵問題。
4.2 增長節點選擇
deep Web數據源當前本地版本(t?1)的屬性值圖為(t?1),deep Web新數據發現的關鍵問題為:在時刻t,如何從圖(t?1)中選擇一個節點,在WDB上提交該節點對應的查詢關鍵詞可以獲得盡可能多的新記錄。根據4.1節敘述的事物發展的趨勢的一般規律,(t?1)中的所有節點根據目前所處的發展階段可分為3種類:增長類、衰減類和平穩類。對于(t?1)中屬于這3類的節點分別稱為:增長節點、衰減節點和平穩節點。如果圖(t?1)中的一個節點的出度(入度)在deep Web數據源最近的個歷史版本中都非常穩定,根據事物發展的一般規律,那么該節點在(t)中存在大量新記錄與之相匹配的機會將很小,換句話說在時刻t?1到時刻t期間WDB不可能產生大量與該節點相匹配的數據記錄,這類節點即為“平穩節點”,如果節點的出度(入度)在deep Web數據源最近的個歷史版本中的度逐漸減小或節點在最近的個歷史版本中,度的平均值與第+1版本相比減小,則稱該類節點為“衰減節點”,如果節點的出度(入度)在deep Web數據源最近的個歷史版本中的度逐漸增加,或節點在最近的個歷史版本中度的平均值大于第+1版本,則稱該類節點為“增長節點”,顯然,在時刻t,WDB中與增長節點相匹配的數據記錄數最有可能增加,即(t?1)中的增長節點在WDB中更有可能與新產生的數據記錄相匹配。本文使用式(1)計算當前版本(t?1)中節點從時刻t?L到時刻t?1區間的增長度
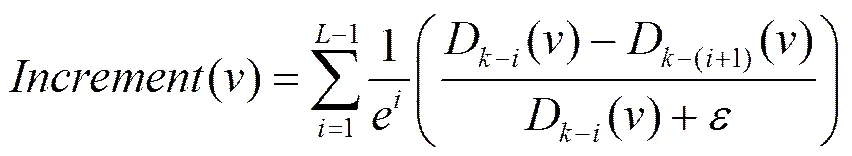
其中,D?i()為圖(t?i)中節點的入度(出度),即在(t?i)中與節點對應關鍵詞相匹配的數據記錄數;表示節點的增長度的權重,與當前版本越接近的版本之間的增長度越重要;表示(t?i)與(t?(i+1))2個版本之間的增長度;D?i()?D(?i+1)()為在(t?i)中與節點相匹配的新記錄數;對于,用一個例子說明,假定(t?i)中2個節點1和2,D?i(1)=6,D(?i+1)(1)=2,D?i(2)=12,D(?i+1)(2)=4,顯然應該優先選擇2,因為在deep Web數據源上提交2對應的關鍵詞能獲得比提交1對應的關鍵詞更多的新記錄,使(2)(1),同時避免當?(t?i),D?i()0時,公式除以0的情況。節點的增長度如果大于增長閾值,則認為節點為增長節點。增長節點產生算法的具體描述如下。
算法2 增長節點產生算法
輸入:(t?L),(t?(L?1)), …,(t?1),WDB的最近個歷史版本的屬性值圖
輸出://為增長節點集合
Algorithm((t?L),(t?(L?1)),…,(t?1))
1) begin
2) for each vertexin(t?1)do
3) Compute();
4) if() ≥then //為增長節點的閾值,如果() ≥,則為增長節點
5)∪添加節點到增長節點集合
6) end if
7) end for
8) return
end
在算法2中,首先輸入deep Web數據源最近個歷史版本的屬性值序列圖(t?L),(t?(L?1)),…,(t?1),計算deep Web 數據源當前版本屬性值序列圖(t?1)中每個節點的增長度,如果節點的增長度大于等于增長閾值,則將節點加入到增長節點集合中。通過上述算法得到當前版本屬性值序列圖(t?1)中與產生新記錄相匹配可能性較大的所有增長節點。通過增長度計算(t?1)中所有節點定性分為增長節點、衰減節點和穩定節點3類,在下一節中將預測增長節點的新數據發現能力,即在(t)中與增長節點相匹配的新數據記錄數量。
4.3 增長節點的新數據發現能力估計
目前,人們對事物發展趨勢(如價格、宏觀經濟等)的預測主要采用的預測模型有灰色系統預測模型、時間序列預測模型、回歸預測模型、神經網絡模型等[14]。由于在實際應用中常常存在序列相關性、異方差性、非線性等問題,不可避免地存在信息丟失。神經網絡預測模型由大量的處理單元以適當的方式互聯構成,能模擬人的大腦及其活動,具有非線性和自適應性的特點。在實際應用中神經網絡預測模型與其他預測模型相比通常具有較好的擬合效果和精度。同時,神經網絡預測模型具有如下優點:1)神經網絡預測模型預測精度較高,并可以實現并行計算;2) 神經網絡預測模型相當于一個黑盒,不要知道輸入和輸出變量之間的映射關系,只需對給定的訓練數據進行訓練,來自動建立輸入和輸出變量之間的映射關系,直到實際輸出值與期望值的誤差滿足所需的精度要求;3) 神經網絡預測模型在建模的過程中只需要選取適當的輸入變量和輸出變量以及相應的拓撲結構就能建立合適的模型,能減少人工干預,降低人為假設的可能。
由于deep Web數據變化的復雜性,本文采用BP神經網絡模型來預測增長節點的新數據發現能力。同時,針對那些結果頁面包含與查詢關鍵詞相匹配的數據記錄數的deep Web數據源,采用一種更簡潔的方法計算增長節點的新數據發現能力,即增長節點預提交方法。接下來將分別介紹這2種增長節點新數據發現能力計算方法。
4.3.1 基于BP神經網絡的增長節點新數據發現能力預測
對于中一個節點,預測其在(t)與之相關聯的數據記錄數,即在(t)中的度。假定節點在最近個歷史版本的屬性值圖中度為:{ D?L(), D?(L?1)(),…,D?1()}。使用BP神經網絡預測D()的步驟如下。
1) 利用歷史數據創建訓練樣本
用{ D?L(), D?(L?1)(),…,D()}作為建立BP神經網絡預測模型的訓練樣本,其中,將D?L()作為起始,每連續個度作為一個樣本的輸入向量,接下來的(≥1)個度作為相應的期望輸出向量,這樣的輸入向量和期望輸出向量組成一個樣本,然后起始位置向后退(≥1)個,即從D?L+h()作為起始,再用上述方法建立第2個樣本,依次類推,最終創建出所有的訓練樣本。
2) BP神經網絡結構確定
本文預測采用3層網絡結構:分別為輸入層、隱含層和輸出層。
輸入層:輸入層有個節點,對應訓練樣本的輸入向量。
隱含層:采用經驗式lb(為隱含節點數,為輸入層節點數)確定隱含層節點數。
輸出層:輸出層有個節點,對應訓練樣本的期望輸出向量。本文設置=1,僅僅預測D?L+h+1()的值,如果需要一次預測D?L+h+1()和D?L+h+2()的值,則可以設置2。
3) 訓練相關參數選取與新數據發現能力預測
選取對數型函數作為激勵函數,選取梯度下降BP訓練函數,最大迭代次數100,精度為0.000 1。由于BP神經網絡選取的型函數作為激勵函數,而型激勵函數的值域為[0,1],因此需要采用歸一法將樣本的輸入和輸出向量規范到[0,1]區間。然后利用處理好的樣本對神經網絡進行訓練,得到訓練好的神經網絡,再利用訓練好的神經網絡進行預測,得出D?L+h+1()的預測值。在時刻t,對于IncrementV中的每一個增長節點,可以通過BP神經網絡得到D()的預測值,因此,增長節點的新數據發現能力為:D()?D?1()。
使用基于BP神經網絡的增長節點新數據發現能力預測方法,需要對每一個增長節點訓練神經網絡,當增長節點數量較大時,雖然BP神經網絡訓練可以離線進行,但仍然將十分耗時。因此,針對那些結果頁面包含與查詢關鍵詞相匹配的數據記錄數的deep Web數據源,本文采用一種更簡潔的方法計算增長節點的新數據發現能力,即增長節點預提交方法。
4.3.2 增長節點預提交的方法
對于一個deep Web數據源,當查詢關鍵詞提交到WDB,WDB將返回與該查詢關鍵詞相匹配的數據記錄組成的結果頁面,據觀察,大多數結果頁除了包含與查詢關鍵詞相關的數據記錄外,還包含WDB中與該查詢關鍵詞相匹配的數據記錄總數。圖3為在互動出版網(www.china-pub.com)的查詢接口提交查詢關鍵詞“java”后,互動出版網返回的結果頁面(互動出版網是一個圖書類電子商務網站)。如圖3所示,在結果頁面中除了顯示部分數據記錄外,還包含在互動出版網中與查詢關鍵詞“java”匹配的記錄總數(見粗線方框“使用java搜索,共有3 413種商品”)。通過統計分析發現,現實世界中大多數的deep Web數據源的結果頁面中包含與提交到它的查詢關鍵詞相匹配的數據記錄總數,記為。
為了進行高效的新數據發現,需要獲得在時刻t,(t)中與增長節點相匹配的數據記錄數,即在(t)中增長節點的度D()。因此,本文利用deep Web數據源的結果頁面中包含與提交到它的查詢關鍵詞相匹配的數據記錄總數的特點,在時刻t,對于IncrementV中的每一個增長節點,進行一次查詢提交,獲得該節點查詢提交的一個結果頁面,然后從結果頁面中抽取(t)中與增長節點相匹配的數據記錄數,等價于(t)中增長節點的度D()。因此,在時刻t,增長節點的新數據發現能力為:- D?1()。
與基于BP神經網絡的增長節點新數據發現能力預測方法相比較,增長節點預提交方法不需要通過歷史數據訓練預測模型,只需要對所有增長節點進行一次查詢提交,爬取一個結果頁面即可獲得時刻t在WDB中與增長節點相匹配數據記錄的準確數量。因此,增長節點預提交方法與基于BP神經網絡的增長節點新數據發現能力預測方法相比較, 增長節點預提交方法使用更加簡單方便,同時代價較低。更重要的是基于預測的方法存在一定的誤差,而增長節點預提交方法則更為準確。因此,對那些結果頁面包含與查詢關鍵詞相匹配的數據記錄數的deep Web數據源,本文使用增長節點預提交方法獲得增長節點的新數據發現能力,否則,使用基于BP神經網絡的方法預測增長節點的新數據發現能力。
4.4 查詢節點選擇
通過預測或預提交得到中每個節點在(t)中可能的入度(出度)后,可以通過D()?D?1()得到每個增長節點的新數據發現能力,即時刻t,在(t)上提交節點能獲得新數據記錄數量。根據deep Web新數據發現策略的爬取代價,查詢節點(關鍵詞)選擇的目標為:每次在中選擇具有最高新數據發現效率的節點,節點的新數據發現效率為爬取最少的總數據記錄,獲得最多的新數據記錄,即對于(t?i)中2個節點1和2,如果1和2爬取相同數量的新數據記錄,1爬取的總數據記錄數小于2,則認為1的新數據發現效率高于2。顯然,應該優先選擇1。節點的新數據發現效率定義為

其中,D?1()為在時刻t?1圖(t?1)中增長節點的入度(出度),D()為在時刻t在deep Web數據源上提交與增長節點相對應的查詢關鍵詞所返回的總記錄數。D()可由4.3節得到。D()?D?1()為時刻t在(t)上提交節點能獲得新數據記錄數量。
在理論上,只需按照中每個增長節點的新數據發現效率從大到小選擇節點,在deep Web數據源上提交與該節點對應的查詢關鍵詞,爬取新記錄。不斷重復該過程,直到滿足停止條件。然而,上述新數據爬取的查詢選擇方法在進行查詢選擇時沒有考慮選擇提交的下一個查詢節點(關鍵詞)與已經選擇提交的查詢節點之間的依賴關系。根據文獻[15],在實際應用中,屬性值之間的依賴關系十分普遍,例如:許多作者通常一起發表論文,當一個作者名字被提交查詢后,其他的作者名字即便是具有較高新數據爬取效率,也不是一個好的選擇。提交它們作為查詢不但不能爬取更多的新數據,反而需要系統處理大量重復數據。因此,在進行查詢節點選擇時,必須要考慮查詢節點與其他已提交查詢節點之間的依賴關系,降低查詢依賴帶來的負面影響。
本文使用Mutual Information計算2個查詢節點(關鍵詞)之間的依賴性,2個查詢節點1和2的依賴度可由它們共同出現在(t?1)中一個有序圈(一條數據記錄)中的概率決定。對于IncrementV中的每個節點v與所有已提交的節點之間的依賴關系(v,IncrementV[1,2,…,m])可由式(3)計算得到
(v,IncrementV[1, 2,…,m])
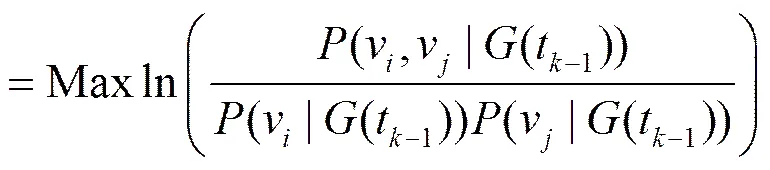
其中,IncrementV為中還沒有被選擇提交的增長節點集合,IncrementV[1,2,…,m]為所有已提交的個查詢節點集合,v∈(v,IncrementV[1,2,…,m]),(v|G(t?1))和(v|G(t?1))分別為v和v在(t?1)中出現的概率,(v,v,(t?1))為v和v在(t?1)中同時出現在一個有序圈(一條數據記錄)中的概率。IncrementV中所有節點的依賴度都基于(t?1)計算得到。
本文在進行查詢選擇時需要懲罰那些具有較強依賴關系的節點,因此,對于IncrementV中的每個節點賦予它一個優先級分數(,IncrementV[1,2,…,m]),IncrementV中的所有節點按照(,IncrementV[1,2,…,m])降序排列,deep Web數據增量爬蟲每次從IncrementV中選擇(,IncrementV[1,2,…,m])最大的節點作為查詢節點。(, IncrementV[1,2,…,m])的計算式為
(,IncrementV[1,2,…,m])
=()(1?(v,IncrementV[1,2,…,m])) (4)
該方法從IncrementV中每次選擇具有最大值的節點作為查詢節點提交后,需要重新計算IncrementV中所有節點的值,以便選擇下一個節點,這樣計算量將非常大,因此,在具體應用中設置一個重計算節點值的步長,即提交次查詢節點后,再重新計算IncrementV中所有節點的值。該方法在適當犧牲系統效率的情況下,大幅降低系統的計算代價。在新數據爬取過程中步長的值可以動態調整,以提高新數據爬取的效率。
5 實驗
為了對本文提出的基于屬性值序列圖模型的deep Web新數據發現策略的性能進行評估,主要從以下3個方面進行實驗測試:1)算法關鍵參數(和)分析;2)新數據發現策略的性能分析;3)AVM與HVMIHM算法的同步率比較。本節首先介紹實驗所使用的數據集,然后給出各項實驗以及實驗結果分析。
5.1 數據準備
為了評估本文提出方法的性能,本文采用專利領域和鞋類電子商務領域的5個真實deep Web數據源的歷史版本數據,這些歷史版本數據來至搜鞋客(www.soxieke.com)和明智慧——生物醫藥科技信息服務平臺(www. Mingzh.com)2個數據集成系統。鞋類電子商務領域選擇的Deep Web數據源為:好樂買(www.okbuy.com)、樂淘(www.letao.com)和搜鞋客(系統已集成的鞋類數據約95萬余條數據);專利領域選擇的deep Web數據源為:中國知識產權局專利數據源的生物醫藥類別(www.sipo.gov.cn/zljs)和明智慧(系統已集成的七國兩組織生物醫藥專利數據約369萬余條數據)。這些數據取于系統2013年5月1日往后的系統集成數據,對于專利領域,每間隔2個星期選擇一個時間點,獲得連續20個歷史版本數據;由于電子商務領域的數據變化快于專利領域,因此,對于鞋類電子商務領域,每間隔一個星期選擇一個時間點,獲得連續20個歷史版本數據。下面將基于以上數據集進行實驗,以驗證本文提出方法的有效性。
5.2 新數據發現的效率評估指標
deep Web新數據發現的主要目標為在盡可能小的代價下獲得盡可能多的新數據,為了評估新數據發現的效率,2個因素必須被考慮:覆蓋率和爬取代價。
新數據發現策略的覆蓋率為
=(5)
其中,N為增量爬蟲發現的新數據記錄數,N為時間到時間1期間實際產生的新數據記錄數。
新數據發現策略的爬取代價為
=(6)
其中,N為增量爬蟲發現的新數據記錄數,N為爬蟲發現N個新數據記錄總共爬取的數據記錄數。
顯然,如果給定一個值,越大,則爬蟲新數據發現的效率越高。
5.3 實驗結果
然后實驗分析不同值對覆蓋率的影響,如圖4所示,在相同值的情況下,值越小覆蓋率越高,其變化趨勢與值對覆蓋率的影響相似,當值到達一個臨界值后繼續減小值,對覆蓋率的影響變的非常小,因此,對于一個數據源值也有一個臨界值。與值對代價影響一致,隨著值的增加,尤其是值大于臨界之后,值的增加會使代價顯著增加。在5個不同的數據源上的實驗結果得到了基本一致的結論,因此,在后續的新數據發現算法效率比較時,選擇和的臨界值作為最理想取值。
5.3.2 新數據發現策略的性能分析
1) 新數據發現算法的有效性分析
首先比較本文提出的基于屬性值序列圖模型的deep Web新數據發現策略(AVM)與現有2種deep Web數據增量爬取方法HVM(model history version)[8],IHM(incremental harvest model)[10]的性能并分析其有效性。上述3種方法通過各自策略選擇下一個最可能發現新數據的關鍵詞,以發現新數據,反復執行該過程,直到滿足停止條件。該實驗的停止條件為實驗deep Web數據源的新數據覆蓋率達到95%,為了便于比較當某一種爬取方法的新數據覆蓋率達到停止條件時,同時已結束其他2種增量爬取方法的爬取。為了避免AVM滿足停止條件而過早停止,保證實驗在相同的停止條件下進行比較,在實驗中值設置為10,閾值設置為1%,重計算節點值的步長值設置為12。
圖5給出了3種方法在5個實驗數據源最近一個歷史版本上的實驗結果。從圖5可以得出基于屬性值序列圖模型的deep Web新數據發現策略在5個數據源上都最先獲得95%左右的新數據。在Sipo數據源上當其Sipo的新覆蓋率達到95%時,HVM達到83%,IHM為85.5%,在其他數據源上,基于屬性值序列圖模型的deep Web新數據發現策略已取得了與IHM數據源類似的結果。與HVM和IHM相比AVM的具有更好有效性和效率。
從Sipo數據源的實驗中可以看出當查詢提交900次左右時,Sipo的覆蓋率已達到90%以上,在這個查詢次數下取得這樣的新數據覆蓋率已經是非常理想的結果,而其他2種算法此時取得覆蓋率與AVM相差甚遠,甚至提交成倍的查詢次數也很難取得相同的覆蓋率。在其他數據源上,AVM算法都在較少的提交次數下獲得了90%以上的覆蓋率。因此說明本文提出的AVM算法能在較少查詢提交次數下獲得較高的覆蓋率,具有較強的有效性。
2) 在多個歷史版本上驗證新數據發現策略的效率
在以下2個實驗中根據5.3.1節的實驗結論,設置新數據發現算法的值為6,值為5%,重計算節點值的步長值為12。
在上述5個數據源上,利用新數據發現效率評估指標來評價本文提出的新數據發現策略的性能。該實驗使用(t?6),(t?5),(t?4),(t?3),(t?2)和(t?1)最近連續6個歷史版本數據作為統計信息來爬取(t)中新產生的數據記錄。在時刻7、10和15這3個時間點上進行實驗得到的結果如表1所示。本文提出的新數據發現策略在新數據發現策略的覆蓋率(NR_Coverage)和新數據發現策略的爬取代價(NR_Cost)2個方面都取得了非常高的效率。在這5個數據源上的所有實驗表明,本文提出新數據發現策略的覆蓋率NR_Coverage都超過了87%,最高為92.5%。新數據發現策略的爬取代價NR_Cost最高的僅為39.7%。
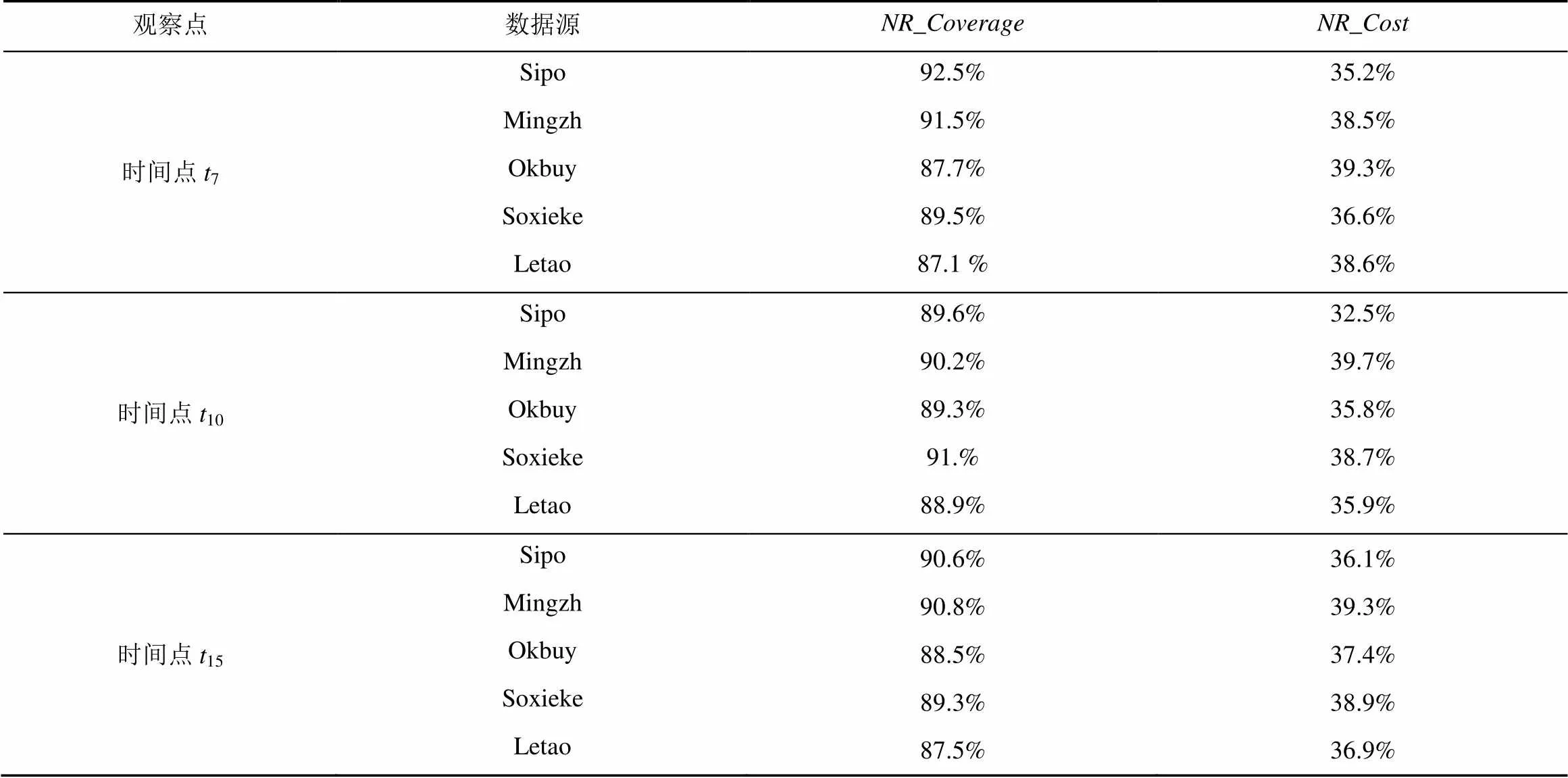
表1 新數據發現策略的性能
5.3.3 AVM與HVMIHM算法的同步率比較
在相同增量爬取資源約束下,分別在5個數據源上,比較本文提出AVM與現有2種deep Web數據增量爬取方法HVM和IHM的數據同步率。
定義2 本地數據與遠程數據的同步率。假定在時刻t,經過增量爬取后得到的本地數據為(t),而此時遠程數據源中的實際數據為(t)。則本地數據與遠程數據的同步率(t)可定義為
(t)(7)
其中,|(t)為在時刻t,的數據記錄總數;|(t)∩WDB(t)|為在時刻t,本地數據與遠程數據相同數據記錄總數。
在實驗中,對每個數據源設置增量更新資源為20萬條數據記錄,即在時刻t,增量爬蟲從(t)中爬取20萬條數據記錄更新(t?1),增量爬取后得到本地數據為WDB(t)。然后比較本地數據WDB(t)與遠程數據(t)的同步率。在實驗中,從(t)中爬取20萬條數據記錄可通過分析WDB的第個歷史版本獲得,并不需要真實的爬取過程。在9時刻獲得的實驗結果如圖6所示。
從圖6中可以看出,本文提出的AVM方法,在5個數據源上都取得了非常高的數據同步率,并都優于HVM和IHM。在Sipo數據源,AVM、HVM和IHM 3種增量爬取方法的同步率比較接近,AVM略優于IHM和HVM。但在Letao數據源的實驗結果與在Sipo數據源上存在較大的差異,在Letao數據源,AVM和IHM明顯優于HVM,在相同更新資源的約束下,HVM取得的數據同步率最低,僅為75.2%,AVM和IHM 分別為94.4%和82.7%。對于HVM方法,本文在這些數據源分別選擇不同的查詢接口進行實驗得到差異較大的實驗結果,究其原因HVM方法與查詢接口能力密切相關,不能獨立表示deep Web數據源的內容,具有一定的不確定性。在Mingzh數據源,AVM明顯優于HVM和IHM,但是與其他4個數據源比較,這3種方法的同步率都較低,究其原因為Mingzh的數據量遠遠大于其他數據源,在相同的更新資源下,取得的同步率應該低于其他數據源。從在Mingzh數據源上的實驗結果中可以看出,當數據量較大時,本文方法的效率優勢更加明顯,能較好地適應大數據量情況下的增量更新。在其他時間點上的實驗與在9時刻的實驗結果類似,本文將不再這里贅述。綜上所述,本文提出的新數據發現方法都取得了非常高的同步率。
6 結束語
由于deep Web是自治的、獨立更新的,其數據經常處于頻繁更新的狀態(不斷有新數據記錄產生),同時也有一些數據記錄消失或改變,而用戶總是希望能夠得到當前deep Web數據源中最新的內容。因此需要定期地爬取遠程數據源的數據,更新本地數據拷貝,以保持本地數據與遠程數據同步。deep Web數據增量爬取需要處理新產生的、消失的和改變的3類數據記錄。本文以屬性值序列圖模型為基礎,針對新產生記錄的爬取,提出了一種新數據發現策略,實驗表明在相同資源約束前提下,可有效提高本地數據的時新性和新數據的發現效率,使本地數據和遠程數據保持最大化同步。同時本文提出的屬性值序列圖模型僅與數據相關,可適用于僅僅包含簡單查詢接口的deep Web數據源,拓展了新數據發現的應用范圍。
[1] MADHAVAN J, COHEN S, DONG X L, et al . Web-scale data integration: you can afford to pay as you go[C]//The 3rd International Conference Innovative Data Systems Research. Asilomar, CA, c2007: 342-350.
[2] MADHAVAN J, KO D, KOT L, et al. Google's deep-Web crawl[C]//The 34th International Conference on Very Large Data Bases. Auckland, New Zealand, Springer, c2008: 1241-1252.
[3] PAVAI G, GEETHA T V. A unified architecture for surfacing the con-tents of deep Web databases[C]//International Conference on Advances in Communication. Network, and Computing, Chennai, India, c2013.
[4] ANDREA C, DAVIDE M, RICCARDO T. Keyword search in the deep Web[C]//AMW2015 Alberto Mendelzon International Workshop on Foundations of Data Management .Lima Peru, c2015: 205-208.
[5] EDWARDS J, MCCURLEY K, TOMLIN J. An adaptive model for optimizing performance of an incremental Web crawler[C]//The 10th Conference on World Wide Web. Hong Kong, China, c2001: 106-113.
[6] SINGHAL N, DIXIT A, SHARMA A K. Design of a priority based frequency regulated incremental crawler[J]. International Journal of Computer Applications, 2010, 1 (1): 42-47.
[7] JAGANATHAN P, KARTHIKEYAN T. Highly efficient architecture for scalable focused crawling using incremental parallel Web crawler[J]. Journal of Computer Science, 2015, 11 (1): 120-126.
[8] LIU W, XIAO J G, YANG J W. Incremental structured Web database crawling via history versions[C]//The 11th International Conference on Web Information Systems Engineering. c2010: 524-533.
[9] LIU W, XIAO J G, YANG J W. A sample-guided approach to incremental structured Web database crawling[C]//International Conference on Information and Automation ,Harbin, c2010: 890-895.
[10] HUANG Q Y, LI Q Z, LI H, et al. An approach to incremental deep Web crawling based on incremental harvest model[J]. Procedia Engineering, 2012, (29): 1081-1087.
[11] ZHANG Z X, DONG G Q, PENG Z H, et al. A framework for incremental deep Web crawler based on URL classification[J]. Lecture Notes in Computer Science, 2011, 6988: 302-310.
[12] 張志瀟.面向領域的Deep Web的增量爬取[D].濟南:山東大學,2012.
ZHANG Z X. Domain-specific deep Web incremental crawler[D]. JiNan: Shandong University,2012.
[13] YOGESH K, MANOJ K R, JITENDRA D. Novel approach for data source integration system update strategy in hidden Web[J]. International Journal of Engineering Universe for Scientific Research and Management.2015,2(7):1-5.
[14] 徐國強. 統計預測和決策[M]. 上海;上海財經大學出版社.2008.
XU G Q. Statistical forecasting and decision-making [M]. Shanghai: Shanghai University of Finance and Economics press, 2003.
[15] WU P, WEN J R, LIU H, et al. Query selection techniques for efficient crawling of structured Web sources[C]//The 22th International Conference on Data Engineering. Atlanta, GA, USA, c2006: 47-56.
Deep Web new data discovery strategy based on the graph model of data attribute value lists
XIAN Xue-feng1,2,3, CUI Zhi-ming1,2, ZHAO Peng-peng2, FANG Li-gang1,3, YANG Yuan-feng1,3, GU Cai-dong1,3
(1. Jiangsu Province Support Software Engineering R&D Center for Modern Information Technology Application in Enterprise, Suzhou 215104,China; 2. Institute of Intelligent Information Processing and Application, Soochow University, Suzhou 215006, China; 3. School of Computer Engineering, Suzhou Vocational University, Suzhou 215104, China)
A novel deep Web data discovery strategy was proposed for new generated data record in resources. In the approach, a new graph model of deep Web data attribute value lists was used to indicate the deep Web data source, an new data crawling task was transformed into a graph traversal process. This model was only related to the data, compared with the existing query-related graph model had better adaptability and certainty, applicable to contain only a simple query interface of deep Web data sources. Based on this model, which could discovery incremental nodes and predict new data mutual information was used to compute the dependencies between nodes. When the query selects, as much as possible to reduce the negative impact brought by the query-dependent. This strategy improves the data crawling efficiency. Experimental results show that this strategy could maximize the synchronization between local and remote data under the same restriction.
deep Web, new data discovery, data acquisition
TP392
A
10.11959/j.issn.1000-436x.2016049
2015-04-20;
2015-10-28
崔志明,CZM@jssvc.edu.cn
國家自然科學基金資助項目(No.61440053, No.61472268, No.41201338);江蘇省自然科學基金資助項目(No.BK2012164);蘇州市科技計劃基金資助項目(No.SYG201342, No.SYG201343, No.SS201344)
The National Natural Science Foundation of China (No.61440053, No.61472268, No.41201338), The Natural Science Foundation of Jiangsu Province (No.BK2012164), Suzhou Foundation for Development of Science and Technology (No.SYG201342, No.SYG201343, No.SS201344)
鮮學豐(1980-),男,四川南充人,博士,蘇州市職業大學副教授,主要研究方向為Web數據管理、數據挖掘和智能信息處理。
崔志明(1961-),男,上海人,蘇州大學教授、博士生導師,主要研究方向為智能信息處理和計算機網絡。
趙朋朋(1980-),男,江蘇南通人,博士,蘇州大學副教授,主要研究方向為deep Web和Web數據挖掘。
方立剛(1980-),男,安徽黃山人,博士,蘇州市職業大學副教授,主要研究方向為計算機網絡和Web GIS。
楊元峰(1973-),男,江蘇鹽城人,蘇州市職業大學副教授,主要研究方向為智能信息處理。
顧才東(1963-),男,寧夏吳忠人,蘇州市職業大學教授,主要研究方向為智能信息處理和物聯網。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
