基于無監督學習算法的推特文本規范化
2016-07-19 19:39:43鄧加原姬東鴻費超群任亞峰
計算機應用 2016年7期
鄧加原 姬東鴻 費超群 任亞峰

摘要:推特文本中包含著大量的非標準詞,這些非標準詞是由人們有意或無意而創造的。對很多自然語言處理的任務而言,預先對推特文本進行規范化處理是很有必要的。針對已有的規范化系統性能較差的問題,提出一種創新的無監督文本規范化系統。首先,使用構造的標準詞典來判斷當前的推特是否需要標準化。然后,對推特中的非標準詞會根據其特征來考慮進行一對一還是一對多規范化;對于需要一對多的非標準詞,通過前向和后向搜索算法,計算出所有可能的多詞組合。其次,對于多詞組合中的非規范化詞,基于二部圖隨機游走和誤拼檢查,來產生合適的候選。最后,使用基于上下文的語言模型來得到最合適的標準詞。所提算法在數據集上獲得86.4%的F值,超過當前最好的基于圖的隨機游走算法10個百分點。
關鍵詞:
規范化;無監督學習;二部圖;隨機游走;拼寫檢查
中圖分類號: TP391; TP18 文獻標志碼:A
0引言
近年來,由于微博的快速發展,用戶生成內容的數量大幅度增加。推特作為最流行的微博服務之一,它擁有10億個活躍用戶,每天產生5億條微博(http://expandedrambling.com)。然而,由于其快速發布的性質,推特文本中包含了大量由用戶有意或無意中創造的非標準詞。比如:用數字替換字母2gether(together)和2morrow(tomorrow);重復字母來強調要表達的內容coollll(cool)和birthdayyyy(birthday);省略元音字母ppl(people);用發音相似的字母來替換fon(phone)。除此之外,還有另外一種類型的非標準詞,主要包括多個連續的標準詞之間省略了空格、標點和字母,例如:theres(there is)、loveyousomuch(love you so much)、ndyou(and you)和untiltheend(until the end)等。根據對1000條推特進行統計,發現其中包括了1329個非標準詞,其中大約22%的比例(294個)需要規范化為兩個或者更多的標準詞。
推特作為極有價值的信息源,引起來了眾多自然語言處理任務和應用的關注。比如信息抽取[1]、自動摘要[2]、情感分析[3-4]、災難檢測[5]和事件發現[6-7]等。然而,推特文本中的非標準詞嚴重限制了這些任務和應用的性能[1,8]。比如:對于標準的自然語言處理工具來說,命名實體識別在推特文本中從90.8%驟降到45.8%[9];詞性標注和依存句法分析分別下降了12.2%和20.65%[10]。基于此,為了使得推特文本能有效被用于標準的自然語言處理任務,設計合理的文本規范化算法至關重要。
近年來,涌現了一批文本規范化系統來將非標準詞規范化為標準詞[8,11-15],但是,這些工作假設一個非標準詞對應于一個標準詞。比如hiiiii規范化為hi,值得注意的是,在先前的系統中,theyre規范化為they,itmay規范化為it,這些系統會丟失一些關鍵的信息,這顯然是不夠合理的。
本文主要集中于推特文本的規范化處理工作,其主要面臨以下兩個挑戰:
1)對一個非標準詞,它應該被規范化為一個還是多個標準詞?
2)推特文本的規范化系統應該具有很高的準確率和召回率,才能使得其作為標準自然語言處理工具的預處理步驟中產生較好的作用。
本文提出了一個創新的無監督文本規范化系統來解決應對上述兩個挑戰。首先,根據非標準詞的特性,基于前向和后向搜索將一個非標準詞轉化成所有可能的多詞組合(由標準詞和非規范化詞構成);然后,整合二部圖的隨機游走算法和誤拼檢測算法,為非規范化詞產生候選列表;最后,根據基于上下文的語言模型來確定最合適的解。
1相關研究
近年來,隨著社交網絡的快速發展,文本規范化吸引了眾多研究者的關注。最近的工作主要集中于推特文本的規范化,把非標準詞轉化為其標準形式。
Han等[8]基于詞的形態和音位的相似性構造分類器來規范化非標準詞。Gouws等[16]提出了基于字符串和分布相似性的方法構造標準詞典,來檢測非標準詞。基于分布和字符串的相似性,Han等[12]提出了一個相似的方法,來為一個非標準詞產生多個標準的候選。
更近的,Hassan等[13]首次提出了基于二部圖來發現候選詞,然后使用N元語法模型選出最較好的規范化詞。Wang等[14]提出了集束搜索(beam search)解碼器有效地結合了不同的規范化操作,并將其規范化系統有效地應用到中英文翻譯系統。Li等[15]提出整合各種不同的規范化系統的候選結果,基于詞向量的語義相似性和其他基于距離的相似性策略對候選結果進行重排序,以此來提高候選集合的質量。
上述的已有方法無法獲得能滿足實際應用的效果。主要原因歸結于這些方法都假設非標準詞到標準詞的關系是一對一的關系。然而,現實中有很多非標準詞(例如howyou和havent)應該被規范化為多個標準詞,如果把這些詞規范化為單個標準詞,會損失很多重要的信息。在本文提出的系統中,一個標準詞將根據其特性被規范化為一個或多個標準詞,使得規范化系統在自然語言處理任務中能夠取得更好的結果。
2推特文本規范化系統
本文旨在將非規范化的推特文本作為輸入,輸出其對應的標準化文本。所提出的主要框架如圖1所示。對于一個推特文本,標準詞典被用于檢測該推特是否需要進行規范化。然后,推特中的非標準詞,將會被根據其特征來考慮進行一對一(11)還是一對多(1N)規范化。對于需要一對多的非標準詞,通過前向搜索和后向搜索算法,計算出所有可能的多詞組合。對于多詞組合中的非規范化詞,基于二部圖隨機游走算法和誤拼檢查,產生合適的候選。最后使用基于上下文的語言模型來得到最合適的標準詞。接下來詳細介紹本文提出的系統。
2.1預處理和標準詞典
所提系統的第一步是判斷一條推特文本是否需要規范化。根據推特文本本身的特性,在判斷是否需要規范化之需要一些預處理,下述幾種類型的詞不需要作規范化處理:
1)以#或@開頭所構成的詞(例如:#kingJames,@michael);
2)由純數字所構成的單詞(例如:2014);
3)表情符和URL(Uniform Resource Locator)。
在推特文本中,還有很多表示人名或者地名的命名實體不需要規范化,因此,使用的標準詞典必須足夠廣闊以至于能夠盡可能地包含這些命名實體。為了獲得較合適的標準詞典,基于一個大規模的語料LDC(Linguistic Data Consortium)統計了所有單詞的出現頻率,并且刪除所有頻率低于5的單詞。然后,使用GNU ASpell詞典(v0.60.6)過濾掉一些單詞。剩下大約68000個單詞構成本文使用的標準詞典。自然而然地,本文認為,凡是沒有出現在這個標準詞典中的詞都應該是需要規范化的非標準詞。
2.2統計規則
2.1節中討論了哪些詞需要規范化。接下來,一個重要的挑戰就是判斷一個非標準詞應該被規范化為一個還是多個標準詞。通過觀察和分析大量的非標準詞,對其特性進行了總結。對符合以下特性的非標準詞進行11規范化:
1)如果某個非標準詞所所包含的字符總數少于4個,則直接將其規范化為一個標準詞,例如,u(you)和r(are);
2)如果某個非標準詞是字母和數字的組合,則將其直接規范化為一個標準詞,例如,be4(before)和2day(today)。
在本文提出的系統中,符合以上特性的非標準詞,將直接進行11規范化;否則,該非標準詞將會被考慮有可能規范化為多個標準詞。當然,上述兩條規則沒有捕獲所有的情況,比如ur可能需要規范化為you are,也有可能需要規范化為your或者our。這類非標準詞由于長度太短,本身具有太大的歧義,需要依靠特定的上下文,但是符合上述特性的非標準詞絕大多數情況是屬于11規范化的。
本文也分析和總結了另一類非標準詞,這類非標準詞應該被規范化為兩個或者更多的標準詞。這類非標準詞主要包括以下3種類型。
類型1非標準詞主要由兩個或更多的標準詞構成,標準詞之間的空格被用戶有意識或無意識地省略。例如,iloveyou(i love you)和rememberwith(remember with)。
類型2非標準詞由一個或多個標準詞,連同一個非規范化詞構成。例如,wasnt(was not)和ndyou(and you)。
類型3非標準詞由兩個或者更多的標準詞的單個字母縮略構成。例如,ur(you are)和sm(so much)。
類型3的非標準詞是非常有限的,這種類型的非標準詞本身也具有很大的歧義性。本文提出的系統將整合互聯網用戶整理的俚語表(slang dictionary(http://www.noslang.com/dictionary)),連同算法所計算出的候選集合。最終根據語言模型來計算出最合適的標準詞。
2.3前向搜索和后向搜索
對于一個非標準詞,本研究提出使用前向搜索和后向搜索算法,為其找出所有可能的多詞組合。前向搜索能夠解決兩種類型的非標準詞:第1種類型是非標準詞由一個或多個標準詞和一個非標準詞按順序組成,例如,theyre(they are)和wouldnt(would not)。第2種類型是由兩個或者多個標準詞組成,例如,aboutthem(about them)和iloveyou(I love you)。具體的前向搜索如算法1所示。
算法1前向搜索ForwardSearch。
有序號的程序——————————Shift+Alt+Y
程序前
輸入:單詞查找樹的當前節點node,存儲組合的列表(Set),將要匹配的字符串word,已經匹配到的字符串matchedWord。
輸出:所有可能的多詞組合。
1)
If(node.state==1)
2)
{
3)
Set
4)
matchedLength=len(matchedWord)
5)
word=word.subString(matchedLength)
6)
matchedWord=′ ′;
7)
ForwardSearch(Trie.root,set2,word,matchedWord)
8)
For(String str:set2)
9)
{ set.add(matchedWord+″ ″+str);}
10)
}
11)
If(len(word)!=0)
12)
{
13)
char c=word.charAt(0);
14)
int index=c-′a′;
15)
if(node.next[index]!=null)
16)
{
17)
word=word.subString(1)
18)
matchedWord+=c;
19)
ForwardSearch(node.next[index],set,word,matchedWord);
20)
}
21)
}
程序后
需要指出的是,算法1中,Trie是由標準詞典構造的單詞查找樹,可方便用于快速查找一個非標準詞中所包含的標準詞。
類似于前向搜索,后向搜索算法也能解決兩種類型的非標準詞:第1種類型是非標準詞由一個非標準和一個或多個標準詞按順序組成,例如,ndyou(and you)和looveyou(love you)。第2種類型是由兩個或者多個標準詞組成。后向搜索算法的過程與前向搜索類型,唯一不同的是單詞查找的構造和搜索的順序都是逆序的。
對于一個非標準詞,基于前向搜索和后向搜索后,可以找到非標準詞所有可能的多詞組合。例如,theyre的前向搜索有“the yre”和“they re”兩種組合結果。然后將所有組合中的非規范詞(yre和re)進行11規范化。與此同時,非標準詞本身(theyre)也要進行11規范化,確保不會遺漏任何可能存在的情況。在后面的章節,將討論如何對非規范詞進行11規范化。
2.4隨機游走和誤拼檢查
非規范化詞有很多類型,例如,重復字母用來強調、字母替換、字母到數字的替換、字母發音替換等。一個很自然的想法就是通過誤拼檢查來將非規范化詞進行規范化,但是,誤拼檢查僅僅能還原用戶無意的漏掉個別字符的非規范化詞。同時,為了能為用戶刻意創造的非規范化詞找到合適的候選,本研究使用基于二部圖的隨機游走算法來找到候選集,因此,對于一個非規范化詞,為了進行11規范化,本文整合基于二部圖的隨機游走算法和誤拼檢查來產生候選集合。
本文提出使用上下文的相似性來為非標準詞找到其可能的標準詞的候選集合。比如任意5元語法序列,如果兩個中心詞的前后兩個詞完全一樣,那么這兩個中心詞可能就是同一個詞或者語義相關的詞。例如,非規范詞be4和標準詞before,由于其共享上下文“the day * the day”和“dress yourself * contract me”,因此,可以認為這兩個詞是同一個詞或者語義相關的詞。最終通過基于字符串的相似度和基于上下文的語言模型可以判定,“before”就是“be4”的規范化結果。上述分析證明了非規范詞和標準詞可以通過大規模的推特語料來獲取,基于此,本文提出使用基于二部圖的隨機游走算法,來為一個非規范詞,通過上下文相似性,找到其對應的標準詞候選集合。首先介紹二部圖的構造。
2.4.1構造二部圖
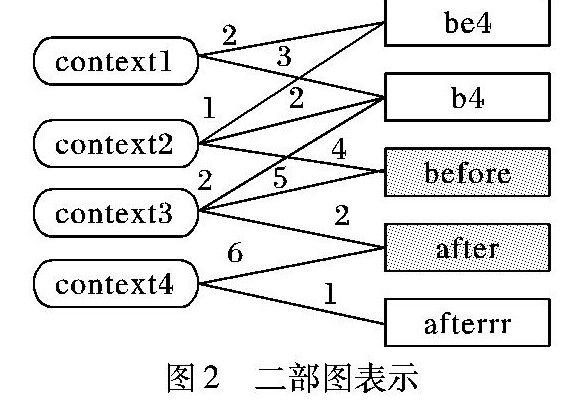
上下文的相似性可以用二部圖來表示:第1種類型的節點代表詞;第2種類型的節點代表可能被詞共享的上下文。詞節點的類型可能是非規范詞,也可能是標準詞。圖2顯示了二部圖G(W,C,E)的一個樣例,其中藍色灰色這樣描述是否符合要求?請明確。的節點表示標準詞。
二部圖G(W,C,E)中,W表示非規范詞或者標準詞,C表示所有的上下文,E表示連接詞節點和上下文節點的邊,邊的權重是詞節點和上下文節點共現的次數。二部圖的構造如算法2所示。
算法2構造二部圖。
有序號的程序——————————Shift+Alt+Y
程序前
輸入:推特語料。
輸出:二部圖G(W,C,E)。
1)
Extract all 5gram sequences from corpus;
2)
Store all sequences into NgramTable;
3)
For each sequence NgramTable;
4)
W*Add(CenterWord);
5)
C*Add(Context);
6)
E*Add(Context,CenterWord,Count)
程序后
2.4.2隨機游走產生候選集
基于二部圖的隨機游走算法首先被Norris所定義[17],然后被廣泛應用于各種自然語言處理任務中。例如,Hughes等[18]提出在WordNet圖上使用隨機游走算法來檢測詞語的語義相關性;Das等[19]提出在兩種語言上使用圖模型的標簽傳播來進行跨語言的知識轉移;Minkov等[20]提出一種基于受限路徑圖的隨機游走算法來計算圖中節點的相關性;Hassan等[13]提出使用Twitter和LDC語料構造的二部圖來考慮詞語規范化。不同于上述算法,本文僅僅使用大規模的推特語料,使用二部圖的隨機游走算法來為非規范詞找到合適的候選集合。
對于一個非規范詞,隨機游走算法使用輪盤賭的方式隨機游走4步來遍歷二部圖。算法從非規范詞節點開始,到標準詞節點或者走完最大步數結束。在本文提出的框架中,對于每個非標準詞,其隨機游走的過程都迭代100次。
考慮一個二部圖隨機游走過程,以圖2中的二部圖為例,假設隨機游走算法從非規范詞節點be4出發,通過輪盤賭隨機移動到上下文節點context2,然后再移動到標準詞節點before,本次隨機游走結束,這次的隨機游走將be4和before聯系起來。同時,在下次的隨機游走過程中,非規范詞節點be4可以通過隨機游走將將非規范詞節點be4同after聯系起來:
be4 → context1 → b4 → context3 → after
那么對于非規范詞be4,如何判斷候選詞的好壞,即對于be4來說,after和before,哪個是更好的候選。
本文中,對于一個非標準詞,通過計算置信度ConValue(N,S)對其隨機游走的候選結果進行排序,其中N表示非規范詞,S表示標準詞,ConValue(N,S)的計算如下:
ConValue(N,S)=α*F(S)+β*Sim(N,S)(1)
其中α和β是權重,這里使用均勻插值,即設置α=β=0.5。F(S)的計算如下:
F(S)=S_frequency/total_frequency(2)
其中:S_frequency表示標準詞S在100次隨機游走中最終被識別的次數,total_frequency表示在100次隨機游走中找到的標準詞個數。Sim(N,S)是基于最長公共子序列比率的字符串相似度函數[21-22],其計算方式如下:
Sim(N,S)=LCS(N,S)/MaxLength(N,S)ED(N,S)(3)
其中:LCS(N,S)表示N和S的最長公共子序列,ED(N,S)表示N和S的編輯距離。
對于一個非規范詞,可以使用隨機游走算法為其計算出可能的候選集合,并通過ConValue(N,S)值選取Top5對候選集合進行修剪。隨機游走算法的優點是可以為絕大多數非規范詞找到合適的候選詞。然而,由于數據集的規模限制,基于二部圖的隨機游走算法不可能為所有的非規范化詞找到候選集合,因此必須同時結合其他方法,為一個非規范詞產生一定的候選集合。本文采用經典的誤拼檢查算法來產生候選,將其結果同隨機游走算法產生的候選整合到一起作為整個候選集合。
2.4.3誤拼檢查
對于誤拼寫錯的非規范詞,誤拼檢查算法是個簡單并且有效的規范化方法。本文中采用Jazzy spell checker(http://jazzy.sourceforge.net/),并且同時整合DoubleMetaphone聲音匹配算法,來考慮單詞之間的字符的取代、插入、刪除和交換等操作。本文設置編輯距離為2之內的所有標準詞來作為一個非規范詞的候選集合。
2.4.4產生Topn候選集
對于一個非標準詞N,通過隨機游走算法和誤拼檢查為其產生了一定數量的候選,需要對這些候選進行排序,除了比較字符串的相似性外,還考慮了其語義相似性,對于非標準詞N,其所有候選的得分通過式(4)來計算:
S(N,S)=Sim(N,S)+Cos(vec(N),vec(S))(4)
Sim(N,S)的計算方法已在前面介紹過,函數Cos(vec(N),vec(S))表示非標準詞N和標準詞S的詞向量之間的余弦相似度,為了計算詞N和詞S的詞向量,本文使用了谷歌的開源工具word2vec(http://code.google.com/p/word2vec/),基于800萬條推特語料來訓練,詞向量的維度被設置為200。基于S(N,S),最終為每個非標準詞選取Topn個候選詞(n=1,3,5)。
2.4.5基于語言模型來規范化推特
對于一個非標準詞,整合隨機游走和誤拼檢查為其產生Topn個候選詞。為了確定該非標準詞的最佳候選,需要考慮該非標準詞的上下文信息。基于大規模的文本數據,通過使用3元和4元語法模型來對維特比(Viterbi)路徑進行打分,基于此來選擇最合適的候選,進行規范化。本文在使用基于上下文的語法模型時,分別考慮了3種不同類型的數據。
3實驗
3.1實驗設置
實驗中使用了5個數據集,數據集(1)和數據集(2)將用于詞級別(wordlevel)的評估;數據集(3)不僅用于詞級別的評估,還用于句子級別(messagelevel)的評估。值得注意的是,數據集(1)和數據集(2)的非標準詞,僅僅需要被規范化為一個標準詞。5個數據集的介紹如下。
數據集(1)3802個非標準詞及其對應的人工標注的標準詞。這些非標準詞來自于2009年到2010年之間的6150條推特文本[11]。
數據集(2)2333個非標準詞及其對應的人工標注的標注詞,這些非標準詞來自于2577條推文本[15,23]。
數據集(3)邀請了3個母語為英語的學生標注的1000條推特文本。其中有850條推特需要進行規范化的,另外150條不需要規范化。該數據集中總共包含1345個非標準詞,其中297個非標準詞需要被規范化為兩個或更多的標準詞。
數據集(4)通過推特流API(http://dev.twitter.com/docs/streamingapis)獲取的800萬條推特文本數據,這些推特來自于2014年10月到12月。該數據被用于構建隨機游走的二部圖。
數據集(5)來自英文LDC Gigaword(http://www.ldc.upenn.edu/Catalog/LDC2011T07),該語料被用于構建標準詞典。
詞級別(wordlevel)的規范化旨在判斷非標準詞對應的標準詞是否在所產生的候選集合中,因此,對于一個非標準詞,系統通過其候選集Topn中是否包含其標準詞來判定它是否被正確地規范化。為了同已有算法相比較,分別計算了在不同Topn設置下的準確率。對于文本級別(messagelevel)的評價,基于不同類型的大規模文本數據,分別構造語言模型來計算準確率、召回率和F值來評估Top1、Top3和Top5設置下的系統性能。
3.2詞級別實驗結果
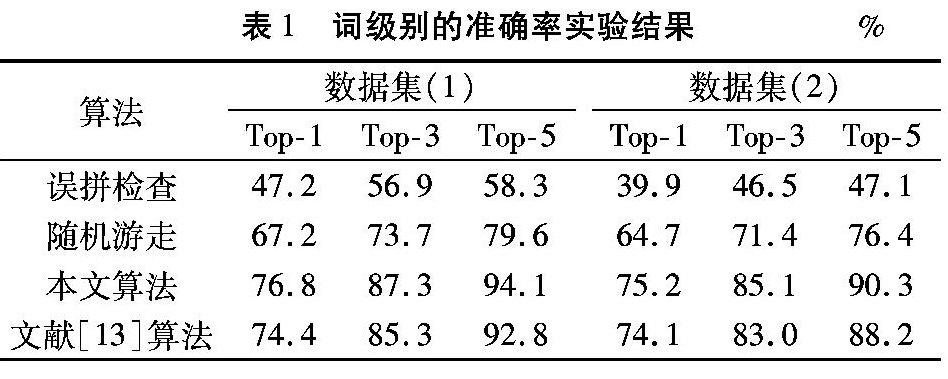
詞級別的結果呈現在表1中,本文分別在數據集(1)和數據集(2)中進行評估,分別展示了Top1、Top3和Top5的準確率。
從表1中可知,僅僅使用誤拼檢查,數據集(1)和(2)上的準確率為40%到60%,這說明僅僅通過比較詞的相似性無法有效規范化用戶有意識創造和使用的非標準詞。同時,隨機游走算法取得了相對較好的結果,在兩個數據集中獲得了65%到80%的準確率,比起誤拼檢查,隨機游走能夠有效地捕獲人們有意創造的非標準詞。最后,本文提出的系統,通過整合誤拼檢查和隨機游走作為整個候選集,在Top5混合系統中獲得了90%到94%的準確率,這證實本文算法的有效性。
比起當前的算法最好的算法文獻[13]算法,本文提出的無監督文本規范化系統能獲得更高的準確率,主要原因歸結于本文的系統所產生的候選集,整合了隨機游走算法和誤拼檢查的結果,能更好地覆蓋到人們有意或者無意創造的非標準詞。
3.3文本級別實驗結果
文本級別的規范化旨在為推特文本的每個非標準詞找到最符合上下文的候選。基于數據集(3),表2中呈現了文本級別的規范化結果。
在表2中,“w/o context”表示的是Top1詞級別的系統設置下的規范化結果。值得注意的是,盡管Top1僅有一個候選詞,但由于本文所提出的系統的高效性,最終獲得了84%的F值。為了計算Top3和Top5設置下的實驗結果,使用3種不同類型的文本數據,基于語言模型(LM),采用維特比算法來解碼。在使用推特文本(Twitter)的語言模型中,能夠看到準確率和召回率隨著候選集合大小n(1,3,5)的增大而增大,在n=5時,獲得本文所提出的系統可獲得高達86.4%的F值。同時,從表2可以看到混合文本語言模型(Mixed LM)和推特文本語言模型(Twitter LM)超過了當前算法的性能。
需要指出的是,基于LDC語料的語言模型(LDC LM),其結果隨著候選集合大小n的增大而變差,其主要原因有推特文本的性能所決定,對推特文本來說,即使非標準詞被規范化后仍然會存在一些語法上的錯誤。這不難解釋單純使用推特文本的語言模型(Twitter LM)會比混合語言模型(Mixed LM)有更好的結果。
同時,從表2中可以看出,比起當前的系統[13,15],本文提出的系統在F值上有超過10%的提高了10個百分點以上,主要原因在于提出的系統考慮了非標準詞一對多的規范化,而之前的工作全都集中在一對一的情況,限制了該任務的性能。
3.4結果分析
圖3呈現了數據集(3)的3個原始推特,經過不同系統規范化后的結果。在圖3中,S表示原始推特,B表示當前的方法[15],O表示本文提出的系統。在第一條推特文本中,所有的非標準詞都能被正確規范化,但是,對于后兩條推特,現有的系統使用一對一的規范化損失了一些關鍵的信息,使得規范化的結果出現一定的錯誤。而在本文提出的無監督文本規范化系統中,根據非標準詞的特性,為其產生一個或多個標準詞,來作為規范化的結果,更能滿足實際應用。基于上述分析,可以證實本文提出系統的有效性。
4結語
本文提出了一個無監督的推特文本規范化系統。對于一個非標準詞,根據其特性,基于前向搜索和后向搜索將其劃分為可能的多詞組合。然后,整合隨機游走算法和誤拼檢查為非規范詞產生可能的多個候選。最后,使用基于上下文的語言模型來為非標準詞計算出最合適的候選。實驗結果證實本文所提算法的有效性,比起當前算法,本文提出的算法在F值獲得超過10%的上提高了10個百分點以上。本文提出的無監督文本規范化系統能夠有效用于自然語言處理任務的預處理。
參考文獻:
[1]
RITTER A, CLARK S, MAUSAM M, et al. Named entity recognition in tweets: an experimental study [C]// Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2011: 1524-1534.
[2]
LIU F, LIU Y, WENG F. Why is “SXSW” trending? Exploring multiple text sources for twitter topic summarization [C]// Proceedings of the 2011 ACL Workshop on Language in Social Media. Stroudsburg, PA: Association for Computational Linguistics, 2011: 66-75.
[3]
MUKHERJEE S, BHANACHARYYA P. Sentiment analysis in twitter with lightweight discourse analysis [C]// Proceedings of the 26th International Conference on Computational Linguistics. New York: ACM, 2012: 1847-1864.
[4]
TANG D, WEI F, YANG N, et al. Learning sentimentspecific word embedding for Twitter sentiment classification [C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1555-1565.
[5]
SAKAKI T, OKAZAKI M, MATSUO Y. Earthquake shakes Twitter users: realtime event detection by social sensors [C]// Proceedings of the 19th International Conference on the World Wide Web. New York: ACM, 2010: 851-860.
[6]
WENG J, LEE BS. Event detection in Twitter [C]// Proceedings of the 5th International Conference on Weblogs and Social Media. Menlo Park, CA: AAAI Press, 2011: 401-408.
[7]
BENSON E, HAGHIGHI A, BARZILAY R. Event discovery in social media feeds [C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 389-398.
[8]
HAN B, BALDWIN T. Lexical normalisation of short text messages: mken sens a #twitter [C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 368-378.
[9]
LIU X, ZHANG S, WEI F, et al. Recognizing named entities in tweets [C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 359-367.
[10]
FOSTER J, CETINOGLU O, WAGNER J, et al. #hardtoparse: POS tagging and parsing the twitter verse [C]// Proceedings of the AAAI Workshop on Analyzing Microtext. Menlo Park, CA: AAAI Press, 2011: 20-25.
[11]
LIU F, WENG F, WANG B, et al. Insertion, deletion, or substitution? normalization text messages without precategorization nor supervision [C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 19-24.
[12]
HAN B, COOK P, BALDWIN T. Automatically constructing a normalization dictionary for microblogs [C]// Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Learning. Stroudsburg, PA: Association for Computational Linguistics, 2012: 421-432.
[13]
HASSAN H, MENEZES A. Social text normalization using contextual graph random walks [C]// Proceedings of the 51st Annual Meeting of the Association for Computation Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2013: 1577-1586.
[14]
WANG P, NG H T. A beam search decoder for normalization of social media text with application to machine translation [C]// Proceedings of the 2013 Conference of the North American Chapter of the Association for Computation Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2013: 471-481.
[15]
LI C, LIU Y. Improving text normalization via unsupervised model and discriminative reranking [C]// Proceedings of the ACL 2014 Student Research Workshop. Stroudsburg, PA: Association for Computational Linguistics, 2014: 86-93.
[16]
GOUWS S, HOVY D, METZLER D. Unsupervised mining of lexical variants from noisy text [C]// Proceedings of the First workshop on Unsupervised Learning in NLP. Stroudsburg, PA: Association for Computational Linguistics, 2011: 82-90.
[17]
NORRIS J R. Markov Chains [M]. Cambridge, UK: Cambridge University Press, 1997: 35-38.
[18]
HUGHES T, RAMAGE D. Lexical semantic relatedness with random graph walks [C]// Proceedings of the 2007 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2007: 581-589.
[19]
DAS D, PETROV S. Unsupervised partofspeech tagging with bilingual graphbased projections [C]// Proceedings of the 49th Annual Meeting of the Association for Computation Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 600-609.
[20]
MINKOV E, COHEN W W. Graph based similarity measures for synonym extraction from parsed text [C]// TextGraphs712: Workshop Proceedings of TextGraphs7 on Graphbased Methods for Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2011: 20-24.
[21]
MELAMED I D. Bitext maps and alignment via pattern recognition [J]. Computational Linguistics, 1999, 25(1): 107-130.
[22]
CONTRACTOR D, FARUQUIE T, SUBRAMANIAM V. Unsupervised cleaning of noisy text [C]// Proceedings of the 23rd International Conference on Computation Linguistics. New York: ACM, 2010: 189-196.
[23]
PENNELL D, LIU Y. A characterlevel machine translation approach for normalization of SMS abbreviations [C]// Proceedings of the 5th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2011: 974-982.
本文的主要貢獻如下:
1)本文提出的文本規范化系統中,一個非標注詞可以轉化為一個或多個標準詞。這種一對多的推特文本正規化是被首次提出的,更能滿足實際的應用。
2)實驗結果表明本文提出的系統取得了最較好的性能,比起之前最好的系統,本文所提方法在F值上提高了10%,這樣的結果可以使得提出的系統作為推特文本自然語言處理任務的預處理步驟。
猜你喜歡
北部灣大學學報(2022年1期)2022-06-22 04:58:38
北部灣大學學報(2022年2期)2022-06-21 11:44:36
現代儀器與醫療(2021年4期)2021-11-05 08:25:08
北部灣大學學報(2021年4期)2021-04-28 08:01:04
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
商周刊(2017年23期)2017-11-24 03:24:09
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生產業(2015年10期)2015-03-11 18:58:41
中國當代醫藥(2015年9期)2015-03-01 02:02:15
